drools规则引擎
drools规则引擎
规则引擎是什么
规则引擎由推理引擎发展而来,是一种嵌入在应用程序中的组件,实现了将业务决策从应用程序代码中分离出来,并使用预定义的语义模块编写业务决策。接受数据输入,解释业务规则,并根据业务规则做出业务决策。
Drools是一款基于java语言的开源规则引擎,基于RETE算法实现。
引入规则引擎后带来的好处
一.实现业务逻辑与业务规则的分离,实现业务规则的集中管理;
二.可以动态修改业务规则,从而快速响应需求变更;
三.使业务分析人员也可以参与编辑、维护系统的业务规则;
四.使用规则引擎提供的规则编辑工具,使复杂的业务规则实现变得的简单;
规则执行流程
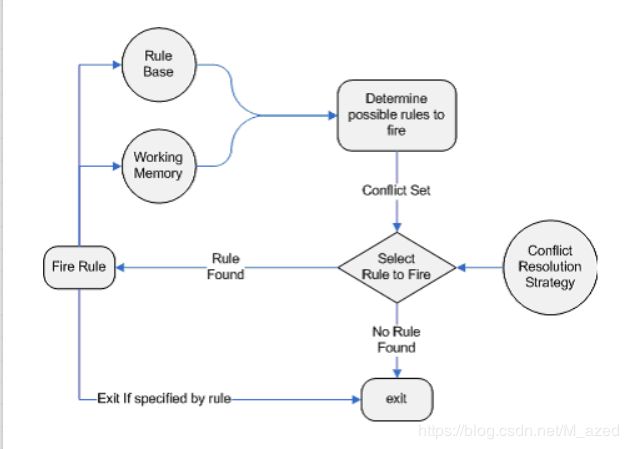
推理机拿到数据和规则后,进行匹配,然后把匹配的规则和数据传递给Agenda。
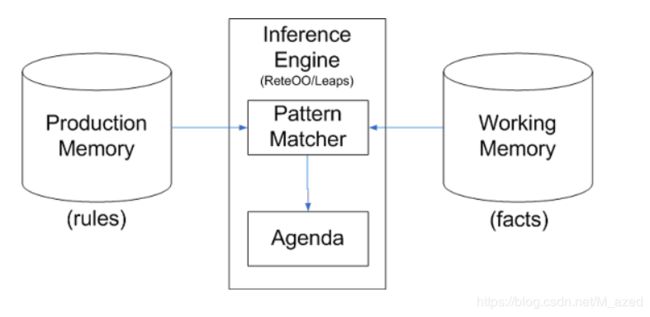
数据被 assert 进 WorkingMemory 后,和 RuleBase 中的 rule 进行匹配(确切的说应该是 rule 的 LHS ),如果匹配成功这条 rule 连同和它匹配的数据(此时就叫做 Activation )一起被放入 Agenda ,等待 Agenda 来负责安排激发 Activation (其实就是执行 rule 的 RHS ),图中的菱形部分就是在 Agenda 中来执行的, Agenda 就会根据冲突解决策略来安排 Activation 的执行顺序。
创建入门项目
1.项目依赖
org.drools
drools-core
7.14.0.Final
org.kie
kie-spring
7.14.0.Final
2.创建配置类
@Configuration
public class DroolsAutoConfiguration {
private static final String RULES_PATH = "rules/";
@Bean
@ConditionalOnMissingBean(KieFileSystem.class)
public KieFileSystem kieFileSystem() throws IOException {
KieFileSystem kieFileSystem = getKieServices().newKieFileSystem();
for (Resource file : getRuleFiles()) {
kieFileSystem.write(ResourceFactory.newClassPathResource(RULES_PATH + file.getFilename(), "UTF-8"));
}
return kieFileSystem;
}
private Resource[] getRuleFiles() throws IOException {
ResourcePatternResolver resourcePatternResolver = new PathMatchingResourcePatternResolver();
return resourcePatternResolver.getResources("classpath*:" + RULES_PATH + "**/*.*");
}
@Bean
@ConditionalOnMissingBean(KieContainer.class)
public KieContainer kieContainer() throws IOException {
final KieRepository kieRepository = getKieServices().getRepository();
kieRepository.addKieModule(new KieModule() {
public ReleaseId getReleaseId() {
return kieRepository.getDefaultReleaseId();
}
});
KieBuilder kieBuilder = getKieServices().newKieBuilder(kieFileSystem());
kieBuilder.buildAll();
return getKieServices().newKieContainer(kieRepository.getDefaultReleaseId());
}
@Bean
@ConditionalOnMissingBean(KieBase.class)
public KieBase kieBase() throws IOException {
return kieContainer().getKieBase();
}
@Bean
@ConditionalOnMissingBean(KieSession.class)
public KieSession kieSession() throws IOException {
KieSession kieSession = kieContainer().newKieSession();
return kieSession;
}
@Bean
@ConditionalOnMissingBean(KModuleBeanFactoryPostProcessor.class)
public KModuleBeanFactoryPostProcessor kiePostProcessor() {
return new KModuleBeanFactoryPostProcessor();
}
public KieServices getKieServices() {
System.setProperty("drools.dateformat","yyyy-MM-dd");
return KieServices.Factory.get();
}
}
3.创建drl文件
Drools的规则文件是以*.drl结尾的文件,我们来看一个最简单的规则文件中都是包含什么。
通常来说,我们会把规则文件放在resources资源文件夹下,这里呢我们在resources文件夹下新建一个rules文件夹,然后再新建一个HelloWord.drl文件
package rules;
import java.lang.String;
import java.util.List;
rule "hello,word"
when
eval(true)
then
System.err.println("hello,word!");
end
- 规则文件,就是我们新建的这个HelloWord.drl可以理解为一个Java类
- package,这个跟Java中的包名是差不多的
- import,此文件中需要的类。
- rule,可以理解为给这个规则起的一个名字,一个规则文件中可以包含多个rule。
- when,when下面可以放置一些条件判断的表达式以及定义一些变量什么的。如果里面内容为空的话则会默认添加一个eval(true)代表一个为true的表达式
- then,当when下面的表达式为true是then下方的代码才会执行,在这里可以直接编写Java代码(代码所需要的类通过import引入),当然也可以使用when模块定义的一些变量
- end 代表规则hello,word的结束。
4.Java调用
新建一个测试类
@SpringBootTest
@WebAppConfiguration
class DroolsApplicationTests {
@Autowired
KieSession kieSession;
}
测试方法
@Test
void contextLoads() {
kieSession.fireAllRules();
}
kieSession.fireAllRules方法是执行所有的规则,在运行了这个测试方法之后我们应该就可以看到控制台打印的一句hello,word!了
drools语法
1.关键字
- Hard keywords(Cannot use any):
true,false,null - Soft keywords(avoid use)
lock-on-active date-effective date-expires no-loop auto-focus activation-group agenda-group ruleflow-group entry-point duration package import dialect salience enabled attributes rule extend when then template query declare function global eval not in or and exists forall accumulate collect from action reverse result end over init
2.注释
- 单行注释
// this is a single line comment - 多行注释
/* this is a multi-line comment
in the left hand side of a rule */
3.Pakage
-
package
package表示一个命名空间.package是必须定义的,必须放在规则文件第一行. -
import
import语句的工作方式类似于Java中的import语句。您需要为要在规则中使用的任何对象指定完全限定路径和类型名称。 -
global
global用于定义全局变量。
Rules:global java.util.List myGlobalList; rule "Using a global" when eval( true ) then myGlobalList.add( "Hello World" ); end设置 global value:
List list = new ArrayList(); KieSession kieSession = kiebase.newKieSession(); kieSession.setGlobal( "myGlobalList", list );
4.Function
-
function
function是一种将语义代码放置在规则源文件中的方法,而不是普通的Java类function String hello(String name) { return "Hello "+name+"!"; } import function my.package.Foo.hello rule "using a static function" when eval( true ) then System.out.println( hello( "Bob" ) ); end
5.Query
-
query
query是一种搜索工作内存中与指定条件匹配的事实的简单方法.对所有30岁以上的人的简单查询 query "people over the age of 30" person : Person( age > 30 ) end 查询超过x岁的人,以及居住在y的人 query "people over the age of x" (int x, String y) person : Person( age > x, location == y ) end QueryResults results = ksession.getQueryResults( "people over the age of 30" ); System.out.println( "we have " + results.size() + " people over the age of 30" ); System.out.println( "These people are are over 30:" ); for ( QueryResultsRow row : results ) { Person person = ( Person ) row.get( "person" ); System.out.println( person.getName() + "\n" ); }
6.Rule
rule定义规则。rule “ruleName”。
一个规则可以包含三个部分:属性部分,条件部分:即LHS,结果部分:即RHS.
1.属性
定义当前规则执行的一些属性等,比如是否可被重复执行、过期时间、生效时间等。
activation-group agenda-group auto-focus date-effective date-expires dialect duration duration-value enabled lock-on-active no-loop ruleflow-group salience
-
no-loop
默认值:false类型:Boolean
在一个规则当中如果条件满足就对Working Memory当中的某个Fact对象进行了修改,比如使用update 将其更新到当前的Working Memory当中,这时引擎会再次检查所有的规则是否满足条件,如果满足会再次执行.
-
ruleflow-group
默认值:N/A类型:String
Ruleflow是一个Drools功能,可让您控制规则的触发。由相同的规则流组标识汇编的规则仅在其组处于活动状态时触发。将规则划分为一个个的组,然后在规则流当中通过使用ruleflow-group属性的值,从而使用对应的规则。
-
lock-on-active
默认值:false类型:Boolean
当在规则上使用ruleflow-group 属性或agenda-group 属性的时候,将lock-on-action 属性的值设置为true,可能避免因某些Fact 对象被修改而使已经执行过的规则再次被激活执行。可以看出该属性与no-loop 属性有相似之处,no-loop 属性是为了避免Fact 修改或调用了insert、retract、update 之类而导致规则再次激活执行,这里的lock-on-action 属性也是起这个作用,lock-on-active 是no-loop 的增强版属性,它主要作用在使用ruleflow-group 属性或agenda-group 属性的时候
-
salience
默认值:0类型:integer
设置规则执行的优先级,salience 属性的值是一个数字,数字越大执行优先级越高,同时它的值可以是一个负数.
规则的salience 默认值为0,所以如果我们不手动设置规则的salience 属性,那么它的执行顺序是随机的. -
agenda-group
默认值:MAIN类型:String
规则的调用与执行是通过StatelessSession 或StatefulSession 来实现的,一般的顺序是创建一个StatelessSession 或StatefulSession,将各种经过编译的规则的package 添加到session当中,接下来将规则当中可能用到的Global对象和Fact对象插入到Session 当中,最后调用fireAllRules 方法来触发、执行规则。在没有调用最后一步fireAllRules方法之前,所有的规则及插入的Fact对象都存放在一个名叫Agenda表的对象当中,这个Agenda表中每一个规则及与其匹配相关业务数据叫做Activation,在调用fireAllRules方法后,这些Activation 会依次执行,这些位于Agenda 表中的Activation 的执行顺序在没有设置相关用来控制顺序的属性时(比如salience 属性),它的执行顺序是随机的,不确定的。Agenda Group 是用来在Agenda 的基础之上,对现在的规则进行再次分组,具体的分组方法可以采用为规则添加agenda-group属性来实现。agenda-group 属性的值也是一个字符串,通过这个字符串,可以将规则分为若干个Agenda Group,默认情况下,引擎在调用这些设置了agenda-group 属性的规则的时候需要显示的指定某个Agenda Group 得到Focus(焦点),这样位于该Agenda Group 当中的规则才会触发执行,否则将不执行。
-
auto-focus
默认值:false类型:Boolean
用来在已设置了agenda-group的规则上设置该规则是否可以自动独取Focus,如果该属性设置为true,那么在引擎执行时,就不需要显示的为某个Agenda Group设置Focus,否则需要。对于规则的执行的控制,还可以使用Agenda Filter 来实现。在Drools 当中,提供了一个名为org.drools.runtime.rule.AgendaFilter 的Agenda Filter 接口,用户可以实现该接口,通过规则当中的某些属性来控制规则要不要执行。org.drools.runtime.rule.AgendaFilter 接口只有一个方法需要实现,方法体如下: public boolean accept(Activation activation); 在该方法当中提供了一个Activation 参数,通过该参数我们可以得到当前正在执行的规则对象或其它一些属性,该方法要返回一个布尔值,该布尔值就决定了要不要执行当前这个规则,返回true 就执行规则,否则就不执行。
-
activation-group
默认值:N/A类型:String
该属性的作用是将若干个规则划分成一个组,用一个字符串来给这个组命名,这样在执行的时候,具有相同activation-group属性的规则中只要有一个会被执行,其它的规则都将不再执行。也就是说,在一组具有相同activation-group属性的规则当中,只有一个规则会被执行,其它规则都将不会被执行。当然对于具有相同activation-group属性的规则当中究竟哪一个会先执行,则可以用类似salience之类属性来实现。
-
dialect
默认值: 根据package指定类型:String,”java” or “mvel”
dialect种类是用于LHS或RHS代码块中的任何代码表达式的语言。目前有两种dialect,Java和MVEL。虽然dialect可以在包级别指定,但此属性允许为规则覆盖包定义。
-
date-effective
默认值:N/A类型:字符串,包含日期和时间定义。格式:dd-MMM-yyyy(25-Sep-2009).
仅当当前日期和时间在日期有效属性后面时,才能激活规则。
-
date-expires
默认值:N/A类型:字符串,包含日期和时间定义。格式:dd-MMM-yyyy(25-Sep-2009).
如果当前日期和时间在date-expires属性之后,则无法激活规则.
-
enabled
默认值:false类型:String
表示规则是可用的,如果手工为一个规则添加一个enabled属性,并且设置其enabled属性值为false,那么引擎就不会执行该规则.
-
duration
默认值:无类型:long
持续时间指示规则将在指定的持续时间之后触发,如果它仍然是true.
2.条件LHS
定义当前规则的条件,如when Message(); 判断当前workingMemory中是否存在Message对象。
Left Hand Side(LHS)是规则的条件部分的公共名称。它由零个或多个条件元素组成。
如果LHS为空,它将被认为是一个条件元素,它总是为真,并且当创建一个新的WorkingMemory会话时,它将被激活一次。
“`
Conditions / LHS —匹配模式(Patterns)
没有字段约束的Pattern
Person()
有文本字段约束的Pattern
Person( name == “bob” )
字段绑定的Pattern
Person( $name : name == “bob” )
变量名称可以是任何合法的java变量,$是可选的,可由于区分字段和变量
Fact绑定的Pattern
$bob : Person( name == “bob” )字段绑定的Pattern
变量约束的Pattern
Person( name == $name )
Drools提供了十二种类型比较操作符:
> >= < <= == != contains not contains memberOf not memberOf matches not matches
-
contains / not contains
运算符contains用于检查作为Collection或elements的字段是否包含指定的值.Cheese( name contains “tilto” )
Person( fullName contains “Jr” )
String( this contains “foo” ) -
memberOf / not memberOf
运算符memberOf用于检查字段是否是集合的成员或元素;该集合必须是一个变量。CheeseCounter( cheese memberOf $matureCheeses )
-
matches / not matches
正则表达式匹配,与java不同的是,不用考虑’/’的转义问题Cheese( type matches “(Buffalo)?\S*Mozarella” )
-
exists
存在。检查Working Memory是否存在某物。使用模式exists,则规则将只激活最多一次,而不管在工作存储器中存在与存在模式中的条件匹配的数据量 -
not
不存在,检查工作存储器中是否存在某物。认为“not”意味着“there must be none of…”。
3.结果RHS
这里可以写普通java代码,即当前规则条件满足后执行的操作,可以直接调用Fact对象的方法来操作应用。
Right Hand Side(RHS)是规则的结果或动作部分的通用名称;此部分应包含要执行的操作的列表。在规则的RHS中使用命令式或条件式代码是不好的做法;作为一个规则应该是原子的性质 - “when this, then do this”,而不是“when this, maybe do this”。规则的RHS部分也应该保持较小,从而保持声明性和可读性。如果你发现你需要在RHS中的命令式和/或条件代码,那么也许你应该把这个规则分成多个规则。 RHS的主要目的是插入,删除或修改工作存储器数据。为了协助,有一些方便的方法可以用来修改工作记忆;而不必首先引用工作内存实例。
-
update
更新,告诉引擎对象已经改变(已经绑定到LHS上的某个东西),并且规则可能需要重新考虑。 -
insert(new Something())
插入,往当前workingMemory中插入一个新的Fact对象,会触发规则的再次执行,除非使用no-loop限定; -
insertLogical(new Something())
类似于insert,但是当没有更多的facts支持当前触发规则的真实性时,对象将被自动删除。 -
modify
修改,与update语法不同,结果都是更新操作。该语言扩展提供了一种结构化的方法来更新事实。它将更新操作与一些setter调用相结合来更改对象的字段。 -
retract
删除
系统内置method
- drools.halt()
调用drools.halt()立即终止规则执行。这是需要将控制权返回到当前会话使用fireUntilHalt()的点。 - drools.getWorkingMemory()
返回WorkingMemory对象. - drools.setFocus( String s)
将焦点设置为指定的agenda group. - drools.getRule().getName()
从规则的RHS调用,返回规则的名称。 - drools.getTuple()
返回与当前执行的规则匹配的Tuple,而drools.getActivation()传递相应的激活。