自然语言处理(NLP)——LDA模型:对电商购物评论进行情感分析
目录
- 一、2020数学建模美赛C题简介
- 需求
- 评价内容
- 提供数据
- 二、解题思路
- 三、LDA简介
- 四、代码实现
- 1. 数据预处理
- 1.1剔除无用信息
- 1.1.1 剔除掉不需要的列
- 1.1.2 找出无效评论并剔除
- 1.2 抽取评论
- 1.3 词形还原
- 1.4 去除停用词
- 1.5 筛选词性
- 1.3~1.5代码
- 2. 使用LDA模型进行主题分析
- 完整代码
- 附录
一、2020数学建模美赛C题简介
从提供的亚马逊电商平台的商品评价数据中识别关键模式、关系、度量和参数。
需求
- 以此告知阳光公司在线销售策略
- 识别潜在的重要设计功能,以增强产品的满意度
- 阳光公司对数据基于时间的模式特别感兴趣
评价内容
- 个人评级,星级评价,1~5分
- 评论,文本信息
- 帮助评分, 其他用户对“评论”的作用的评价
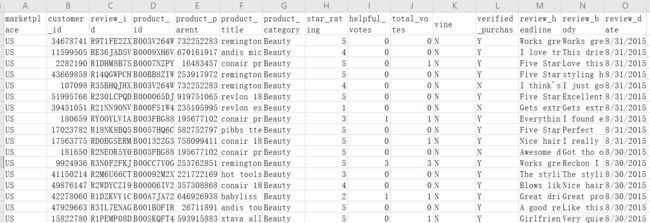
提供数据
tsv格式的数据, 如下图
二、解题思路
使用LDA模型量化评论,再结合其他数据进行下一步数据挖掘。这里主要讨论LDA。
三、LDA简介
LDA(Latent Dirichlet Allocation)是一种文档主题生成模型,也称为一个三层贝叶斯概率模型,包含词、主题和文档三层结构。所谓生成模型,就是说,我们认为:
- 一篇文章以一定概率选择了某个主题
- 这个主题以一定概率选择了某个词语得到。
- 文档到主题服从多项式分布,主题到词服从多项式分布。
- 每一篇文档代表了一些主题所构成的一个概率分布,而每一个主题又代表了很多单词所构成的一个概率分布。
应用
- LDA是一种非监督机器学习技术,可以用来识别大规模文档集(document collection)或语料库(corpus)中潜藏的主题信息。
使用了词袋(bag of words)方法
- 将每一篇文档视为一个词频向量,从而将文本信息转化为了易于建模的数字信息。
- 但是词袋方法没有考虑词与词之间的顺序,这简化了问题的复杂性,同时也为模型的改进提供了契机。
四、代码实现
代码头部全局变量,方便理解后续的代码:
import re
import nltk
import pandas as pd
from nltk.corpus import stopwords
from nltk.stem.wordnet import WordNetLemmatizer
from gensim import corpora, models
TOPIC_NUM = 1 # 主题数
lmtzr = WordNetLemmatizer()
m_files = [r"..\data\microwave.tsv",
r"..\data\microwave_lda_1rmv_cols.tsv",
r"..\data\microwave_lda_2dup_revs.tsv",
r"..\data\microwave_lda_3rmv_invds.tsv",
r"..\data\microwave_lda_4pos_revs.txt",
r"..\data\microwave_lda_5neg_revs.txt",
r"..\data\microwave_lda_6pos_rev_words.txt", # 文本进行了处理
r"..\data\microwave_lda_7neg_rev_words.txt",
r"..\data\microwave_lda_8pos_topic.tsv",
r"..\data\microwave_lda_9neg_topic.tsv",
r"..\data\microwave_lda_10pos_topic_words.txt",
r"..\data\microwave_lda_11neg_topic_words.txt",
r"..\data\microwave_lda_12rev_words.tsv",
r"..\data\microwave_lda_13rev_score.tsv"]
# 停用词集合
stop_words = set(stopwords.words('english'))
stop_words = [word for word in stop_words if word not in ['not']]
# print(stop_words)
# 自定义停用词
m_stop_words = ['would', 'br', 'microwave', 'use', 'get', 'old', 'new', 'look', 'work', 'could', 'oven',
'purchase', 'take', 'make', 'buy', 'go', 'come', 'say', 'not', 'bought', 'even', 'ge',
'also', 'ca', 'dry']
# 情感分析中重要的词性
m_tags = ['MD', 'UH', 'VB', 'VBD', 'VBG', 'VBN', 'VBP', 'VBZ', 'RP', 'RB', 'RBR', 'RBS', 'JJ', 'JJR', 'JJS']
# 正则表达式过滤特殊符号用空格符占位,双引号、单引号、句点、逗号
pat_letter = re.compile(r'[^a-zA-Z \']+')
# 还原常见缩写单词
pat_is = re.compile("(it|he|she|that|this|there|here)(\'s)", re.I)
pat_s = re.compile("(?<=[a-zA-Z])\'s") # 找出字母后面的字母
pat_s2 = re.compile("(?<=s)\'s?")
pat_not = re.compile("(?<=[a-zA-Z])n\'t") # not的缩写
pat_would = re.compile("(?<=[a-zA-Z])\'d") # would的缩写
pat_will = re.compile("(?<=[a-zA-Z])\'ll") # will的缩写
pat_am = re.compile("(?<=[I|i])\'m") # am的缩写
pat_are = re.compile("(?<=[a-zA-Z])\'re") # are的缩写
pat_ve = re.compile("(?<=[a-zA-Z])\'ve") # have的缩写
然后看下最后调用的函数代码,了解一下顺序:
# lda训练,得到主题词
def lda_step1():
remove_cols() # 剔除多余列 file[0]->file[1]
get_dup_revs() # 获取重复评论 file[1]->file[2]
def lda_step2(): # 需要查看step1中获取的重复评论的信息
invd_list = [1, 2] # 无效评论的行号
remvove_invds(*invd_list) # 剔除无效评论 file[1]->file[1],使用了file[2]
get_pos_neg_revs() # 获取消极、积极评论 file[1]->file[4,5]
def lda_step3(): # lda训练
write_selected_words() # 预处理文本(归一化,筛选词性,去停词表等) file[4]->file[6],file[5]->file[7]
get_topic_words() # file[6]->file[8]->file[10],file[7]->file[9]-file[11]
# lda_step1()
# lda_step2()
lda_step3()
1. 数据预处理
1.1剔除无用信息
1.1.1 剔除掉不需要的列
# 剔除冗余的列
def remove_cols():
data = pd.read_csv(m_files[0], sep='\t', encoding='utf-8')
data = data.drop(['marketplace', 'product_category', 'product_parent', 'product_title'], axis=1) # 剔除了多列
data.to_csv(m_files[1], sep='\t', encoding='utf-8')
1.1.2 找出无效评论并剔除
- 首先找到重复的评论
# 获取重复的评论
def get_dup_revs():
m_df = pd.read_csv(m_files[1], index_col=0, sep='\t', encoding='utf-8')
data_review = m_df['review_body'] # 获取评论这一列
# 计算数组有哪些不同的值,并计算每个值有多少个重复值,原值变成了行索引
dup_df = pd.DataFrame(data_review.value_counts())
m_review = dup_df.index.values.tolist() # 获取评论值列表
m_num = dup_df['review_body'].values.tolist() # 获取原来评论的重复值
# 新建一个df
m_review_num = pd.DataFrame([m_review, m_num])
m_review_num = pd.DataFrame(m_review_num.values.T) # 转置
m_review_num.columns = ['review_body', 'num']
# 筛选出重复的评论
m_review_num = m_review_num[m_review_num['num'] > 1]
m_review_num.to_csv(m_files[2], sep='\t', index=False, header=True, encoding='utf-8')
# print(m_review_num)
结果:
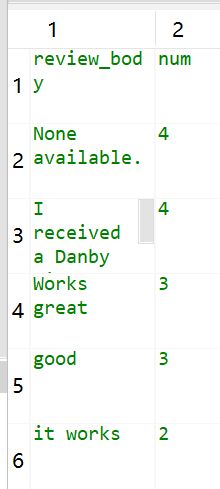
2. 重复率过高的可能是系统自动评论
第一条可能为恶意评论:
I received a Danby Microwave for Christmas 2011. Less than 4 months later it stop working I called the Danby 800# and was told what to do. I did this and have not heard anything back. I have attempted numerous times with no success on getting my refund. Loss to my family of $85.00
I will never buy another Danby product or recommend one.
第二条为系统标记无效评论
其他评论较为正常
3. 剔除掉被认定为无参考意义的评论
# 去除无效评论
def remvove_invds(*invd_list): # 参数为无效评论在“重复评论”中的行号
#print("remvove_invds", invd_list)
m_df = pd.read_csv(m_files[1], sep='\t', encoding='utf-8')
m_invds = pd.read_csv(m_files[2], sep='\t', encoding='utf-8')
#print("m_invds",m_invds)
m_invds = m_invds[m_invds.index.isin(invd_list)]
m_invd_revs = m_invds['review_body'].values.tolist()
# print("m_invd_revs:" + m_invd_revs)
# 筛选出不在无效评论中的
m_df = m_df[~m_df.review_body.isin(m_invd_revs)]
m_df.to_csv(m_files[3], sep='\t', index=False, header=True, encoding='utf-8')
1.2 抽取评论
抽取1,2星和4,5星的评论分别作为消极评论、积极评论的语料
# 抽取1、2,4、5星的评论
def get_pos_neg_revs():
m_df = pd.read_csv(m_files[3], sep='\t', encoding='utf-8')
m_neg_df = m_df[m_df.star_rating.isin([1, 2])]
m_pos_df = m_df[m_df.star_rating.isin([4, 5])]
m_neg_revs = m_neg_df['review_body']
m_pos_revs = m_pos_df['review_body']
m_neg_revs.to_csv(m_files[5], sep='\t', index=False, header=True, encoding='utf-8')
m_pos_revs.to_csv(m_files[4], sep='\t', index=False, header=True, encoding='utf-8')
1.3 词形还原
英语中同一个动词有多种形态,奖其还原成原形
1.4 去除停用词
去除无参考意义的词,如:
{'to', 'there', 'nor', 'wouldn', 'shouldn', 'i', 'then', 'you', 'ain', "hasn't", 'she', 'not', 'such', 'those', 'so', 'over', 'the', 'y', 'd', 'most', 'm', 'should', 'both', 'weren', 'from', 'until', 'an', 'my', 'yours', 'in', 'here', 'them', 'have', 'didn', 'against', 'myself', 'of', 'her', 'had', "couldn't", "didn't", 'when', "should've", 'is', 'very', "don't", 'has', 'these', 'will', 're', 'now', "hadn't", 'were', 'again', 'same', 'itself', 'his', 'what', 'him', 'don', "you'll", 'how', 'couldn', 'other', 'doesn', 'out', 'no', 'while', 'your', 'do', 'this', 'if', "shouldn't", 'just', 'aren', 'shan', 'himself', 'on', 'further', 'themselves', 've', 'hers', 't', 'me', 's', 'that', 'and', 'which', 'or', 'our', "won't", 'above', 'off', 'we', "wasn't", "needn't", 'ours', 'who', 'all', 'wasn', 'through', 'be', 'ourselves', 'by', 'during', 'about', "mightn't", 'was', 'yourselves', 'before', 'because', 'ma', 'being', 'more', 'it', 'any', 'll', "weren't", 'between', 'why', 'he', 'herself', 'whom', "wouldn't", 'o', "that'll", "you'd", 'few', 'won', 'once', 'some', 'doing', "aren't", "you've", 'with', 'under', "mustn't", 'too', 'needn', 'isn', 'yourself', "haven't", 'up', 'below', 'am', 'after', "it's", 'as', 'hadn', 'into', 'own', "you're", 'its', 'theirs', 'their', "isn't", "shan't", 'only', 'mightn', 'hasn', 'mustn', 'does', 'a', 'each', 'having', 'haven', 'they', "she's", 'at', 'can', 'but', 'been', 'did', "doesn't", 'down', 'than', 'are', 'for', 'where'}
1.5 筛选词性
去除掉情感分析中无参考意义的词性, 保留有参考意义的词性。
有参考意义的词性:
m_tags = ['MD', 'UH', 'VB', 'VBD', 'VBG', 'VBN', 'VBP', 'VBZ', 'RP', 'RB', 'RBR', 'RBS', 'JJ', 'JJR', 'JJS']
1.3~1.5代码
# 从文本抽取单词
def extract_words(text, debug=False):
text = replace_abbreviations(text)
if debug:
print('去除非字母符号:', text)
m_words = nltk.word_tokenize(text) # 分词
if debug:
print('分词:', m_words)
m_word_tags = nltk.pos_tag(m_words) # 获取单词词性
if debug:
print('获取词性:', m_word_tags)
m_words = [word for word, tag in m_word_tags if tag in m_tags] # 过滤词性
if debug:
print('过滤词性后:', m_words)
m_words = words_normalize(m_words) # 归一化
if debug:
print('归一化后:', m_words)
m_words = [word for word in m_words if word not in stop_words] # 过滤停词表
m_words = [word for word in m_words if word not in m_stop_words] # 过滤自定义停词表
if debug:
print('过滤停词表后:', m_words)
return m_words
2. 使用LDA模型进行主题分析
抽取1,2星和4,5星的评论分别作为消极评论、积极评论的语料
分别对两份语料进行LDA训练得到主题词。
get_topics.py:
# 获取文章主题, 使用预处理后的评论文本(已经进行了归一化,筛选词性,去停词表等操作)
def get_topics2(input_file):
fr = open(input_file, 'r', encoding='utf-8')
words_list = [] # 二维单词列表
for line in fr.readlines():
m_words = nltk.word_tokenize(line)
# m_words = [word for word in m_words if word not in m_stop_words]
words_list.append(m_words)
# """构建词频矩阵,训练LDA模型"""
dictionary = corpora.Dictionary(words_list)
# corpus[0]: [(0, 1), (1, 1), (2, 1), (3, 1), (4, 1),...]
# corpus是把每条新闻ID化后的结果,每个元素是新闻中的每个词语,在字典中的ID和频率
corpus = [dictionary.doc2bow(words) for words in words_list] # text单篇文章
lda = models.LdaModel(corpus=corpus, id2word=dictionary, num_topics=TOPIC_NUM) # lda训练
topic_list = lda.print_topics(TOPIC_NUM)
print(len(topic_list), "个主题的单词分布为:\n")
for topic in topic_list:
print(topic)
return topic_list
分析结果:
1 个主题的单词分布为:(积极)
(0, '0.022*"great" + 0.019*"well" + 0.015*"small" + 0.014*"good" + 0.013*"easy" + 0.011*"fit" + 0.010*"love" + 0.010*"need" + 0.009*"little" + 0.008*"much"')
1 个主题的单词分布为:(消极)
(0, '0.014*"replace" + 0.009*"last" + 0.008*"stop" + 0.008*"start" + 0.008*"back" + 0.008*"well" + 0.007*"never" + 0.007*"call" + 0.007*"turn" + 0.007*"open"')
['well', 'small', 'fit', 'good', 'great', 'easy', 'need', 'much', 'little', 'love']
['replace', 'well', 'turn', 'last', 'never', 'call', 'back', 'stop', 'open', 'start']
完整代码
gitee项目地址:https://gitee.com/Meloor/LDATest
文件目录:LDA/get_topics.py
附录
参考博客:https://www.jianshu.com/p/4a0bd8498561