Java服务器性能监控(一) Metrics
引言
对于后台服务而言,我们除了需要保证其每个功能正常工作,我们还需要了解服务的运行情况,包括机器的物理性能(线程数,文件句柄数,内存占用大小,GC时间等)以及业务性能(关键流程的通过率、QPS以及响应时间等)。目前,常用的做法是通过定义、收集以及展示一系列的指标(metrics)来完成后台服务的监控。
监控其实可以分为四部分,首先我们需要定义监控数据的产生,然后我们需要定义监控数据收集的规则,再后则是数据监控数据的展现形式,最后则是根据监控数据进行报警。本文会从监控数据的产生写起,逐步为大家介绍,如何在Java服务中接入监控服务。本文主要基于目前较为流行的metrics框架,codahale的metrics,其maven依赖如下所示:
<dependencies>
<dependency>
<groupId>com.codahale.metricsgroupId>
<artifactId>metrics-coreartifactId>
<version>3.1.2version>
dependency>
dependencies>Metrics中的基础数据类型
说到监控数据如何产生,就必须先从其基础的数据类型说起。下面介绍三种最常用的数据类型,Counter, Gauge, 以及Histogram。一般的Java Metrics库都会有这三者的实现。
Counter(计数器)
跟字面意思一样,Counter就是一个只增不减的计数器,主要就是用于统计总量,它的常用用法如下所示:
统计Api访问中异常(400/500)的次数
统计Api的调用量
统计特定事件发生的次数。
那么,Counter的底层又是如何实现的呢?尤其是在高并发的访问情况下面,如何保证Counter的自增原子性以及发生竞争时保证性能?
在codahale的源码里面,设置了如下的机制来确保Counter自增的原子性以及高性能。
- 使用base与cells机制
在源码中,每个Counter都会由两部分组成,简化代码如下
public class Counter {
transient volatile int busy;
transient volatile long base;
transient volatile Cell[] cells;
public void inc(long n) {
long b;
if(cells == null || !casBase(b=base, b+n)) {
//使用cells进行计算
}
}
public long sum() {
long sum = base;
Cell[] as = cells;
if (as != null) {
int n = as.length;
for (int i = 0; i < n; ++i) {
Cell a = as[i];
if (a != null)
sum += a.value;
}
}
return sum;
}
}
而大致的执行流程图,则如下图所示:
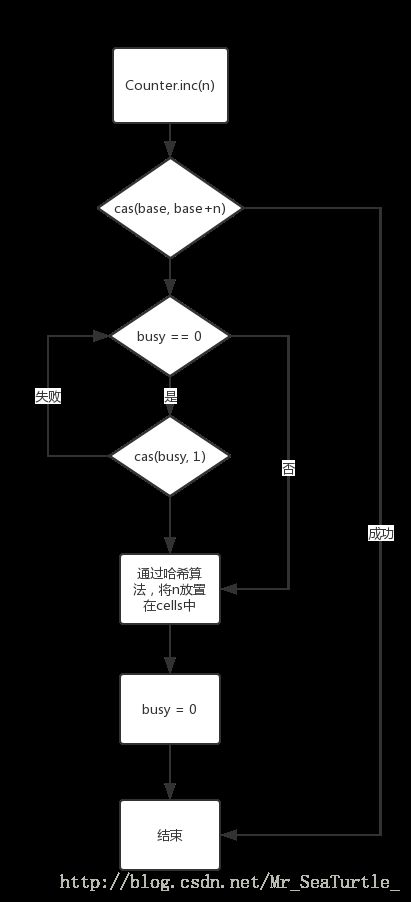
最后总结一下,Counter有以下几个特点:
使用base与cells进行数值存储,无竞争的时候,实际上只更新了base的值。而在有竞争的情况下,则通过cells来分散竞争,保证了Counter的高性能。
Counter在有竞争的情况下,使用的是自旋锁,实际上是通过消耗极小的CPU时间来节省了线程之间上下文切换的消耗
为了保证不过量使用内存,当cells的数量超过CPU的个数时,cells就不会再进行扩容
Gauge (度量器)
Gauge同样也是一个数字类型的指标,跟Counter不一样,它主要用于收集指标的瞬时值,因此它是可变的。它的常用用法如下所示:
统计Api的响应时间(响应时间并非固定值,可能时高时低,这个时候就应该用Gauge进行记录)
统计CPU的负载
统计CPU核心线程数、运行线程数
统计操作系统的文件句柄数
相对于Counter来说,因为Gauge记录的只是一个瞬时值,因此也不用考虑多线程下的竞争与冲突问题。它的Java结构如下(简化)
private final static class SimpleGauge {
private volatile double value;
private SimpleGauge(double value) {
this.value = value;
}
public Double getValue() {
return this.value;
}
public void setValue(double value) {
this.value = value;
}
}Histogram(直方图)
当我们不仅仅关注计数,或者是瞬时变量,而是需要知道最大值,最小值,中位数,平均值以及第99%的值时,我们就需要用到直方图这个统计类型了。Histogram主要的用途是表示分布情况。
考虑一个情况,你需要统计一个api的访问时间第99%的响应时间。一个简单的想法就是,将所有的响应时间记录下来,然后排序,再取出第99%个值就可以了。但是这个api的又是一直在被调用着的,因此会不断地有新的响应时间被记录,因此这样做是永远无法得到第99%的访问时间的。
为了解决这个问题,codehale中的histogram使用了Reservoir类来对响应时间这一类的数据进行收集。Reservoir,中文可以翻译为“蓄水池”,实际上它就是一个保存数据的池子,然后在我们需要统计的时候,取出Snapshot(快照)供我们获得统计数据。
了解了基本原理之后,我们来看一下histogram的源码。
public class Histogram implements Metric, Sampling, Counting {
private final Reservoir reservoir;
private final LongAdder count;
public Histogram(Reservoir reservoir) {
this.reservoir = reservoir;
this.count = new LongAdder();
}
//向histogram中增加新的数据,实际上就是向数据池中添加数据
public void update(int value) {
update((long) value);
}
public void update(long value) {
count.increment();
reservoir.update(value);
}
@Override
public long getCount() {
return count.sum();
}
//获取Snapshot,实际上也是通过数据池来获取
@Override
public Snapshot getSnapshot() {
return reservoir.getSnapshot();
}
}再来看看Snapshot的代码。
public class Snapshot {
//最核心的方法,用于获取第n%的值
public double getValue(double quantile);
private final long[] values;
public double getMedian() {
return getValue(0.5);
}
public double get75thPercentile() {
return getValue(0.75);
}
/*
省略部分getNthPercentile函数
*/
public long getMax();
public double getMean();
public long getMin();
/*
...
*/
}
所以,从Snapshot中,我们就基本能够得到我们想要的统计数据了。
然后,我们来简单地了解一下数据池。定义了数据池以后,我们就需要考虑更多的问题了,比如说,如何保证可以高性能地将数据写入数据池中,以及如何保证数据池中数据量不会过大而占用过多的内存,以及如何快速地取出快照。在Codahale metrics里面,主要定义了三种数据池。
UniformReservoir 默认保存1028条记录,每次进行update操作的时候,首先会依次地将值填入1028条记录中,当记录满了之后,就会使用随机替换0 - 1027中的一条。因为是随机替换,所以也不需要进行加锁和解锁。
SlidingWindowReservoir 固定大小的数据池,从0到n-1填入数据,不断循环。也不会进行加锁和解锁。
SlidingTimeWindowReservoir 非固定大小的数据池,但是只会存储过去N秒的数据。使用
ConcurrentSkipListMap进行存储。ExponentiallyDecayingReservoir 固定大小的数据池。首先会逐个数据填满数据池,随后会将老的数据替换为新的数据,使用
ConcurrentSkipListMap进行存储。可以说是SlidingWindowReservoir与SlidingTimeWindowReservoir的结合。
使用Registry对Metrics进行收集,输出
当我们在系统里面定义了多个Metrics的时候,如何准确高效地收集它们,并且将这些数据输出到分析系统中,就会成为我们要思考的问题。
Codahale使用了Registry的注册机制对Metrics进行收集(这也是大部分Metrics框架的做法),另外,它还使用了Reporter作为输出。
下面是一个简单的示例。
public class TestMain {
public static void main(String args[]) {
MetricRegistry registry = new MetricRegistry();
//声明Gauge
TestGauge responseTime = new TestGauge();
responseTime.setValue(20);
//将Gauge注册到registry中。
registry.register("testGauge", responseTime);
//使用ConsoleReporter,将metrics的值输出到System.out中
ConsoleReporter reporter = ConsoleReporter.forRegistry(registry)
.build();
//每隔一秒输出一次
reporter.start(1, TimeUnit.SECONDS);
//等待5秒再结束程序
Thread.sleep(5000);
}
//自定义的Gauge
public static class TestGauge<T> implements Gauge {
private T value;
public void setValue(T v) {
this.value = v;
}
@Override
public T getValue() {
return value;
}
}
} 输出结果如下所示:
17-7-27 23:36:57 ================================================================
– Gauges ———————————————————————-
testGauge
value = 20
在Spring项目中,MetricRegistry常常会被声明成一个Bean,然后在有需要的地方进行注入,最后就可以达到只通过一个MetricRegistry,就能够收集到所有指标的效果。
在这样声明完成后,我们就可以通过registry.getCounters/getHistograms/getGauges来获取我们所有注册过的metrics类型了。其实这里更重要的是MetricsRegistry,因为里面包含了所有Metrics的获取方法,至于获取方法之后如何进行输出,我们可以自行定义,也可以使用codahale中既有的Reporter。
小结
在这一篇文章中,我们主要介绍了在Java应用中是如何做一些性能指标的收集的。包括对Gauge,Counter,Histogram三种基础数据类型的介绍,以及收集机制的介绍。
在实现Metrics收集机制的时候,我们不得不去考虑几个问题。
我们需要收集的是瞬时值,计数,还是统计分布值?
在进行数据记录的时候,如何保证高性能地写入/更新?(尽可能少地使用锁)如何保证数据合理地被更新?
如何将metrics数据汇总到一个地方以便于后期处理?
示例代码也已经上传到github中。欢迎关注。