深度学习-->NLP-->RNNLM实现
本篇博文将详细总结 RNNLM 的原理以及如何在 tensorflow 上实现 RNNLM 。
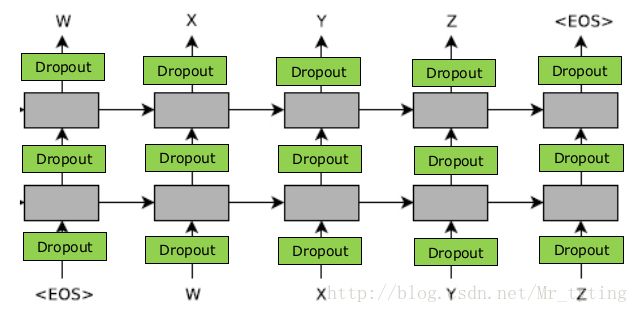
我们要实现的网络结构如下:
数据预处理
创建 vocab
分词:
将句子中的每个单词以空格,符号分开,形成一个单词列表
def blank_tokenizer(sentence):
##以空格对句子进行切分
return sentence.strip().split()
def basic_tokenizer(sentence):
'''
_WORD_SPLIT=re.compile(b"([.,!?\"':;)(])")
首先以空格对句子进行切分,然后再以标点符号切分,切分出一个个词,然后词列表
'''
words=[]
for space_separated_fragment in sentence.strip().split():
words.extend(_WORD_SPLIT.split(space_separated_fragment))
return [w for w in words if w]对单词列表添加特殊词汇:
- _PAD 填充词汇
- _GO 句子开始
- _EOS 句子结束
- _UNK 未知词(低频的词替换为UNK)
如 "i love you" 创建成 vocab 时,应为:
"_GO i love you _EOS
将单词替换成数字
对 vocab 内的单词按出现频率排序,用其索引代替单词。
如:1 3 102 3424 2
def create_vocabulary(vocabulary_path,data_paths,max_vocabulary_size,tokenizer=None,normalize_digits=False):
'''
读取data_paths路径下的文件,并且一行行的读取,对每句做分词处理,得到每个词的频率,然后存储频率最高的max_vocabulary_size的词,存入vocabulary_path
:param vocabulary_path: 新建的文件夹,将返回的结果写入
:param data_paths:存储原始文件的路径
:param max_vocabulary_size:最大存储的词的个数
:param tokenizer:对句子做分词处理
:param normalize_digits:是否对句子中的数字以0替换
:return:返回的vocabulary_path中一行一个词
'''
if not gfile.Exists(vocabulary_path):
print ("Create vocabulary %s from data %s" %(vocabulary_path,",".join(data_paths)))
vocab={}
for data_path in data_paths:
with gfile.GFile(data_path,mode='rb') as f:
print (data_path)
counter=0
for line in f:
counter+=1
if counter%100000==0:
print ("processing line %d" %counter)
#Converts either bytes or unicode to bytes, using utf-8 encoding for text.
line=tf.compat.as_bytes(line)
tokens=tokenizer(line) if tokenizer else blank_tokenizer(line)
for w in tokens:
#replace digit to 0
#_DIGIT_RE=re.compile(br"\d")
word=_DIGIT_RE.sub(b"0",w) if normalize_digits else w
if word in vocab:
vocab[word]+=1
else:
vocab[word]=1
print (len(vocab))
# _START_VOCAB=[_PAD,_GO,_EOS,_UNK]
# 按词频率降序排序
vocab_list=_START_VOCAB+sorted(vocab,key=vocab.get,reverse=True)
if len(vocab_list)>max_vocabulary_size:
vocab_list=vocab_list[:max_vocabulary_size]##只取出现频率最高的max_vocabulary_size
with gfile.GFile(vocabulary_path,mode='rb') as vocab_file:
for w in vocab_list:
vocab_file.write(w+b'\n')##注意将分出的单词一行一行的写入到vocabulary_path
def initialize_vocabulary(vocabulary_path):
'''
:param vocabulary_path:一行一个词
读取vocabulary_path文件内每行的每个单词到rev_vocab,然后枚举rev_vocab,然后字典列表[(word,index)]
:return:
'''
if gfile.Exists(vocabulary_path):
rev_vocab=[]
with gfile.GFile(vocabulary_path,mode='rb') as f:
rev_vocab.extend(f.readlines())
rev_vocab=[tf.compat.as_bytes(line.strip()) for line in rev_vocab]
vocab=dict([(x,y) for (y,x) in enumerate(rev_vocab)])
return vocab,rev_vocab
else:
raise ValueError("Vocabulary file % not found",vocabulary_path)
def sentence_to_token_ids(sentence,vocabulary,tokenizer=None,normalize_digits=False,with_start=True,with_end=True):
'''
对sentence句子进行分词处理,并且用其在vocabulary中的索引代替其词,并且加上GO_ID,EOS_ID,UNK等特殊数字,返回数字列表。
:param sentence:需要分词的句子
:param vocabulary:字典列表[(word,index)]
:param tokenizer:分词处理方法
:param normalize_digits:是否将句子中数字用0替换
:param with_start:是否在句头带上GO_ID
:param with_end:是否在句尾带上EOS_ID
:return:
'''
if tokenizer:
#对sentence进行分词处理
words=tokenizer(sentence)
else:
# 对sentence进行分词处理
words=basic_tokenizer(sentence)
if not normalize_digits:
#在vocabulary中找到Word,返回其index,否则以UNK_ID代替返回
#UNK_ID=3
ids=[vocabulary.get(w,UNK_ID) for w in words]
else:
#_DIGIT_RE=re.compile(br"\d")
ids=[vocabulary.get(_DIGIT_RE.sub(b"0",w),UNK_ID) for w in words]
if with_start:
ids=[GO_ID]+ids
if with_end:
ids=ids+[EOS_ID]
return ids
def data_to_token_ids(data_path,target_path,vocabulary_path,tokenizer=None,normalize_digits=False,with_go=True,with_end=True):
'''
读取data_path路径下的文件内容,读取其每一行,喂给sentence_to_token_ids方法处理,得到所有词的索引列表,然后存入到target_path
:param data_path:原文件
:param target_path:原文件处理完要存入的地址
:param vocabulary_path:一行一个词
:param tokenizer:
:param normalize_digits:
:param with_go:
:param with_end:
:return:
'''
if not gfile.Exists(target_path):
print ("Tokenizing data in %s" % data_path)
vocab,_=initialize_vocabulary(vocabulary_path)
#vocab是字典列表[(word,index)]
with gfile.GFile(data_path,mode='rb') as data_file:
with gfile.GFile(target_path,mode='w') as tokens_file:
counter=0
for line in data_file:
counter+=1
if counter%100000==0:
print ("tokenizing line %d" % counter)
token_ids=sentence_to_token_ids(tf.compat.as_bytes(line),vocab,tokenizer,normalize_digits)
tokens_file.write(" ".join([str(tok) for tok in token_ids])+'\n')#注意一行一句话训练RNN模型
Mini−batch Gradient Descent 梯度下降法
适当的条件更新 learning rate η ,直到收敛。
适当的条件:
每处理了一半的训练数据,就去验证集 计算 perplexity
- 如果 perplexity 比上次下降了,保持 learning rate 不变, 记录下现在最好的参数。
- 否则, learning rate∗=0.5 缩小一半。
如果连续10次 learning rate 没有变,就停止训练。
- 读取训练数据 train 和验证数据 dev
- 建立模型; patience=0
- while
从数据中随机取 m 个句子进行训练
到达半个 epoch ,计算 ppx(dev)
比之前降低:更新 best parameters , patience=0
比之前升高: learning rate 减半, patience+=1
if (patience>10):break
mini−batch 在 RNN 上问题
句子的长度不一样
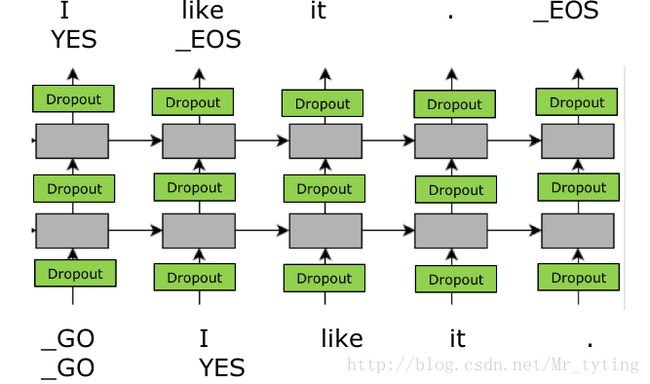
解决方法:句子的长度不一样: 增加 padding
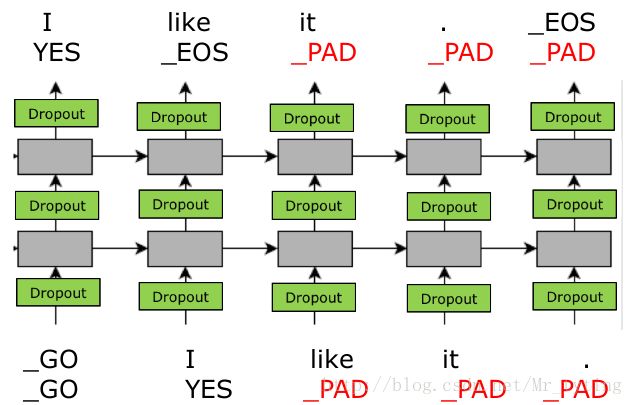
loss 增大了
解决方法:乘以一个0/1 mask矩阵
效率过低问题
随之而来另外一个问题,我们在增加 padding 填充时,以什么样的标准长度进行填充?以所有句子中最长长度进行填充?
例如:我们有长度为10的句子有1101句,长度为11的句子有1226句,长度为81的只有一句,长度为82的也只有1句,那么我们尝试将所有句子补齐到82个字。
- 实际计算了(1101++1226+1+1) * 82 = 190978 步
- 有效的步数:1101*10 +1226 * 11 + 1* 81+ 1*82 = 24659
- 利用率: 12.9% 浪费!
解决低效问题
将句子分成两组, 一组补齐到11,一组补齐到82,相当于建两个RNN,一个11步,另外一个82步。
- (1101+1226) * 11 + (1+1)*82 = 25761
- 利用率: 24659 / 25761 = 95.7%
当然也可以建四个RNN,分别为11步,10步,81步,82步,这样效率就到达100%了。但是显然四个RNN训练比较耗时耗存。
显然,这就有一个问题了,该如何决定分组个数?该如何决定每组的应补齐的步长。
best_buckets问题
这里采用一种贪心算法,贪心的最后结果可能不是全局最优,但肯定不会太差。
我们以下为例:
length_array :表示所有句子长度的列表。
length_array=[1,1,1,1,1,2,2,2,2,2,2,2,2,2,2,3,3,3,4,4]
max_buckets :表示计划分的组数
max_buckets=3
max_length :表示最长的句子长度
max_length=4
running_sum :元祖列表形式。表示长度小于等于1的有5句,长度小于等于有15句,….
running_sum=[(1,5),(2,15),(3,18),(4,20)]
下面是尝试分组:
①:不作分组,相当于只分一组。
running_sum=[(1,5),(2,15),(3,18),(4,20)]
灰色面积是 有效计算步数
空白面积是 无效计算步数
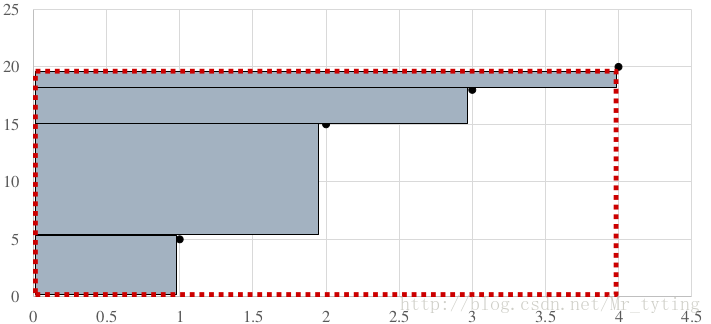
横坐标: running_sum 所有元组的第一个数。
纵坐标: running_sum 所有元组的第二个数。
由图可以看出这种分组方式效率较低。
②分为两组。
如果buckets = [2,4];
实际 = 红框 – 红色区域
红色区域:在当前这种分组下,可以去掉的无效计算。
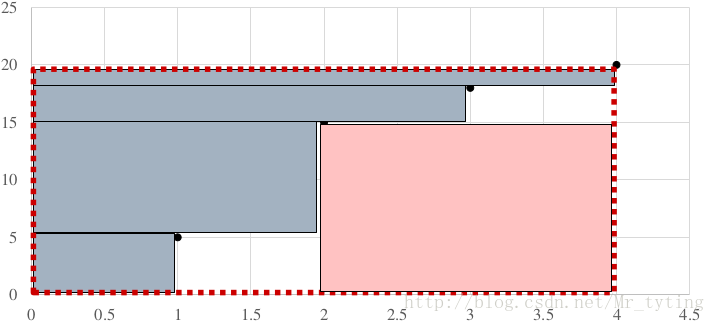
如果buckets = [3,4]
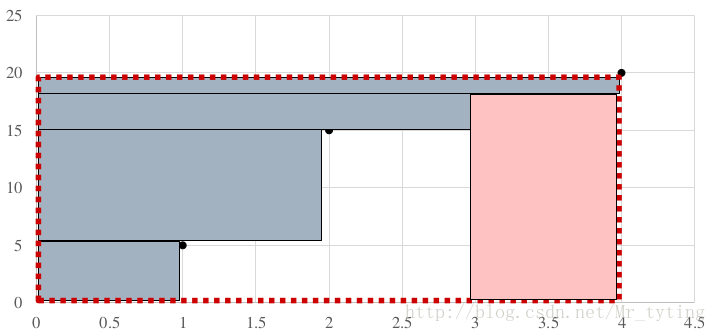
如果buckets = [1,4]
比较以上三种二分方式,得出以句子长度为2划分方式效率最高。然后我们再尝试在这中最优二分划分方式基础上再进行划分。
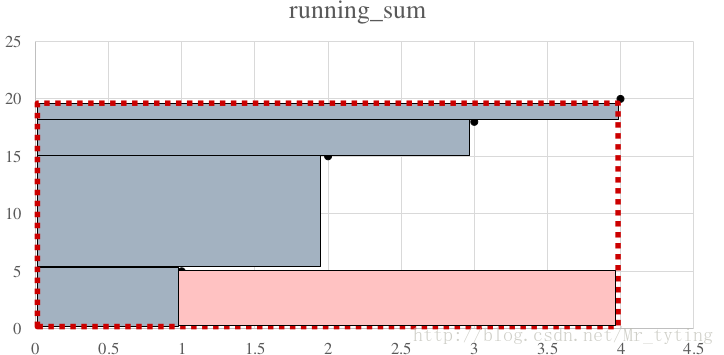
③分为三组。在buckets = [2,4]基础上载进行划分分组。
如果buckets = [2,4,3]
实际 = 红框 – 红色区域
红色区域:在当前这种分组下,可以去掉的无效计算。

buckets = [2,4,1]
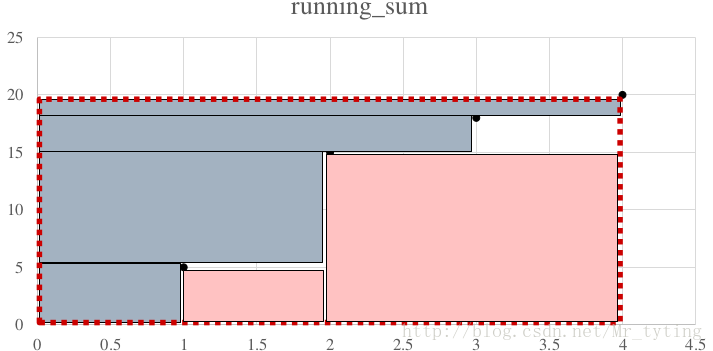
比较以上两种三分组划分方式,显然最好的buckets = [1,2,4]。
def calculate_buckets(length_array, max_length, max_buckets):
'''
:param length_array:所有句子的长度列表[1,1,1,1,1,2,2,2,2,2,2,2,2,2,2,3,3,3,4,4]
:param max_length:最长句子的长度4
:param max_buckets:分为几个组
:return:
'''
d = {}
for length in length_array:
if not length in d:
d[length] = 0
d[length] += 1
#dd:[(句子长度,该长度出现次数)]
dd = [(x, d[x]) for x in d]
dd = sorted(dd, key=lambda x: x[0])##以长度升序排序
#计算running_sum
running_sum = []
s = 0
for l, n in dd:
s += n
running_sum.append((l, s))#running_sum = [(1,5),(2,15),(3,18),(4,20)]
def best_point(ll):
## ll即running_sum:[(句子长度,小于等于该长度出现次数)]
#找出最大可以去掉的无效面积
index = 0
maxv = 0
base = ll[0][1]
for i in xrange(len(ll)):
l, n = ll[i]
v = (ll[-1][0] - l) * (n - base)
if v > maxv:
maxv = v
index = i
return index, maxv
def arg_max(array, key):
# 找出最大可以去掉的无效面积
maxv = -10000
index = -1
for i in xrange(len(array)):
item = array[i]
v = key(item)
if v > maxv:
maxv = v
index = i
return index
end_index = 0
for i in xrange(len(running_sum) - 1, -1, -1):
if running_sum[i][0] <= max_length:
end_index = i + 1
break
# print "running_sum [(length, count)] :"
# print running_sum
if end_index <= max_buckets:
buckets = [x[0] for x in running_sum[:end_index]]
else:
'''
不断递归的以可以去掉最大的无效面积为原则不断的划分
'''
buckets = []
# (array, maxv, index)
states = [(running_sum[:end_index], 0, end_index - 1)]#[([(1,5),(2,15),(3,18),(4,20)],0,end_index-1)],列表长度为1
while len(buckets) < max_buckets:
index = arg_max(states, lambda x: x[1])##最大可以去掉的无效面积对应的索引
state = states[index]
del states[index]
# split state
array = state[0]
split_index = state[2]
buckets.append(array[split_index][0])
array1 = array[:split_index + 1]
array2 = array[split_index + 1:]
if len(array1) > 0:
id1, maxv1 = best_point(array1)
states.append((array1, maxv1, id1))
if len(array2) > 0:
id2, maxv2 = best_point(array2)
states.append((array2, maxv2, id2))
return sorted(buckets)
def split_buckets(array, buckets, withOrder=False):
"""
:param array:句子的集合
:param buckets:上面计算出来的最优划分组
:param withOrder:
:return:d[buckets_id,属于该组的items];order((buckets_id,len(d[buckets_id]) - 1))
"""
order = []
d = [[] for i in xrange(len(buckets))]
for items in array:
index = get_buckets_id(len(items), buckets)
if index >= 0:
d[index].append(items)
order.append((index, len(d[index]) - 1))
return d, order
def get_buckets_id(l, buckets):
'''
将某句子长度划到对应的分组中,返回该句子的组号
:param l:
:param buckets:
:return:
'''
id = -1
for i in xrange(len(buckets)):
if l <= buckets[i]:
id = i
break
return id我们计算处buckets,需要对其中不同的bucket建立不同步长的RNN模型。并且在对不同模型的loss求和。
def model_with_buckets(self, inputs, targets, weights,
buckets, cell, dtype,
per_example_loss=False, name=None, devices=None):
all_inputs = inputs + targets + weights
losses = []
hts = []
logits = []
topk_values = []
topk_indexes = []
# initial state
with tf.device(devices[1]):
init_state = cell.zero_state(self.batch_size, dtype)
# softmax
with tf.device(devices[2]):
softmax_loss_function = lambda x, y: tf.nn.sparse_softmax_cross_entropy_with_logits(logits=x, labels=y)
with tf.name_scope(name, "model_with_buckets", all_inputs):
for j, bucket in enumerate(buckets):
with variable_scope.variable_scope(variable_scope.get_variable_scope(), reuse=True if j > 0 else None):
# ht
with tf.device(devices[1]):
_hts, _ = tf.contrib.rnn.static_rnn(cell, inputs[:bucket], initial_state=init_state)
hts.append(_hts)
# logits / loss / topk_values + topk_indexes
with tf.device(devices[2]):
_logits = [tf.add(tf.matmul(ht, tf.transpose(self.output_embedding)), self.output_bias) for ht
in _hts]
logits.append(_logits)
if per_example_loss:
losses.append(sequence_loss_by_example(
logits[-1], targets[:bucket], weights[:bucket],
softmax_loss_function=softmax_loss_function))
else:
losses.append(sequence_loss(
logits[-1], targets[:bucket], weights[:bucket],
softmax_loss_function=softmax_loss_function))
topk_value, topk_index = [], []
for _logits in logits[-1]:
value, index = tf.nn.top_k(tf.nn.softmax(_logits), self.topk_n, sorted=True)
topk_value.append(value)
topk_index.append(index)
topk_values.append(topk_value)
topk_indexes.append(topk_index)
self.losses = losses
self.hts = hts
self.logits = logits
self.topk_values = topk_values
self.topk_indexes = topk_indexes
如何随机选择m个数据?
inputs, outputs, weights, _ = self.model.get_batch(self.data_set, bucket_id)
- 先随机一个buckets
- 再随机取m个数据
- 将m个数据变成一个矩阵,加上padding
def get_batch(self, data_set, bucket_id, start_id=None):
'''
:param data_set:[ [ s1,s1,s1,s1,s1] , [s2,s2,s2,s2,s2,s2,s2,s2,s2,s2],
[s3,s3,s3,s4,s4] ],注意每个字母表示一个句子。
:param bucket_id:第几个分组
:param buckets:[1,2,4]
:param batch_size
:param start_id:
:return:
'''
length = self.buckets[bucket_id]##当前组的句子长度,即需要补齐的长度
input_ids, output_ids, weights = [], [], []
for i in xrange(self.batch_size):##获取batch_size个句子。
if start_id == None:
word_seq = random.choice(data_set[bucket_id])
else:
if start_id + i < len(data_set[bucket_id]):
word_seq = data_set[bucket_id][start_id + i]
else:
word_seq = []
word_input_seq = word_seq[:-1] # without _EOS
word_output_seq = word_seq[1:] # target without _GO
target_weight = [1.0] * len(word_output_seq) + [0.0] * (length - len(word_output_seq))
word_input_seq = word_input_seq + [self.PAD_ID] * (length - len(word_input_seq))
word_output_seq = word_output_seq + [self.PAD_ID] * (length - len(word_output_seq))
input_ids.append(word_input_seq)
output_ids.append(word_output_seq)
weights.append(target_weight)
# Now we create batch-major vectors from the data selected above.
def batch_major(l):
output = []
for i in xrange(len(l[0])):
temp = []
for j in xrange(self.batch_size):
temp.append(l[j][i])
output.append(temp)
return output
batch_input_ids = batch_major(input_ids)
batch_output_ids = batch_major(output_ids)
batch_weights = batch_major(weights)
finished = False
if start_id != None and start_id + self.batch_size >= len(data_set[bucket_id]):
finished = True
return batch_input_ids, batch_output_ids, batch_weights, finished模型训练
def step(self, session, inputs, targets, target_weights,
bucket_id, forward_only=False, dump_lstm=False):
length = self.buckets[bucket_id]
input_feed = {}
for l in xrange(length):
input_feed[self.inputs[l].name] = inputs[l]
input_feed[self.targets[l].name] = targets[l]
input_feed[self.target_weights[l].name] = target_weights[l]
# output_feed
if forward_only:
output_feed = [self.losses[bucket_id]]
if dump_lstm:
output_feed.append(self.states_to_dump[bucket_id])
else:
output_feed = [self.losses[bucket_id]]
output_feed += [self.updates[bucket_id], self.gradient_norms[bucket_id]]
outputs = session.run(output_feed, input_feed, options=self.run_options, run_metadata=self.run_metadata)
if forward_only and dump_lstm:
return outputs
else:
return outputs[0] # only return losses总结
分词
将所有句子按空格,符号切分成单词列表,转成数字,并添加上特殊数字。然后再按照已经获取的单词和其对应的数字元组列表,将指定的文件内容进行转换,以一句话作为单位进行转换,存到指定文件内,并且一行一句话。分组
计算获取 best_buckets ,然后还需要对上面获取的分词结果按照句子长度和 best_buckets 进行分组,如:[ [ s1,s1,s1,s1,s1] , [s2,s2,s2,s2,s2,s2,s2,s2,s2,s2],[s3,s3,s3,s4,s4] ],每一个字母表示一句话。随机选取m个样本
随机选择 bucket_id ,然后在该组内随机选取m个样本,即m个句子,得到每个句子对应的 Input 和 output ,并计算出该句对应的mask矩阵。如果分为n组,则需要训练n个RNN模型。将上面所得的训练样本丢进对应RNN模型中进行训练预测。并且计算loss之和。