计算机组成原理学习笔记——高速缓冲存储器Cache
文章目录
- 1.0 概述
- 1.1 为什么用Cache?
- 1.2 Cache的工作原理
- 1.3 Cache的基本结构
- 1.4 Cache的读写操作
- 1.5 Cache的改进
- 2.0 Cache主存的地址映射
- (1) 直接映射方式
- (2) 全相联映射方式
- (3) 组相联映射方式
- 3.0 替换算法
- (1) 先进先出 FIFO算法
- (2)近期最少使用 LRU算法
- (3)LFU算法
1.0 概述
1.1 为什么用Cache?
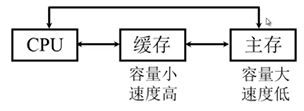
我在前面总结存储器的时候有写到过出现Cache的背景,因为CPU发展的速度比存储器更新迭代的速度快的多得多,为了避免CPU“空等”的现象,我们在CPU和内存之间加入一个容量小速度快的存储设备,这个存储设备就是cache,是由静态RAM组成
程序访问的局部性原理
程序局部性原理,是指程序在执行时呈现出局部性规律,即在一段时间内,整个程序的执行仅限于复程序中的某一部分。相应地,执行所访问的存储空间也局限于某个内存区域。
程序局部性制包括程序的时间局部性和程序的空间局部性。
- 程序的时间局部性: 是指程序即将用到的信息可能就是目前正在使用的信息。
- 程序的空间局部性: 是指程序即将用到的信息可能与目前正在使用的信息在空间上相邻或者临近。
cache和主存之间进行的数据交换是一个‘块’,这个‘块’中既包含了正在使用的指令和数据,也包括了相邻的指令和数据。
1.2 Cache的工作原理
(1)主存和缓存的编址及工作原理
下面这两个图,左侧是主存储器的结构,右侧是cache存储器的结构。
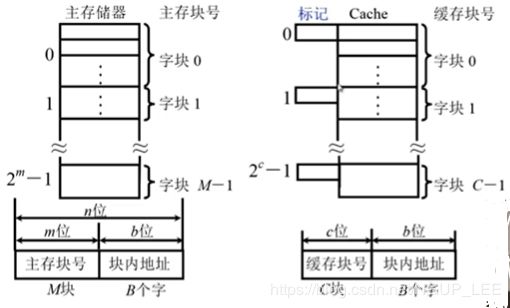
我们把主存储器和cache分成大小相等的’块‘,分别是M块和C块,cache的容量要远远小于主存的容量,M>>C。
实际应用当中cache地址的意义并不大,也不需要实际去形成cache的地址。
一个块在主存和cache之间进行传送的时候是整体进行传送的,块内字节的顺序不会发生任何变化,所以主存的块内地址部分和cache的块内地址部分的值是完全相同的。
cache结构上的标记部分,实际上标记的是对应关系,如果一个主存块要调入到cache当中,那就可以把主存块号写到标记当中,将来CPU给出一个内存的地址,希望可以在cache当中访问到这个地址那首相需要确定的是这个块是否已经被送到了cache当中,那么他就拿给出地址的主存块号和cache当中的标进行比较,如果和某一个标记正好相等,并且这个cache块是有效的,那么这个块内就保存了他要在内存中访问的信息,就可以直接从cache当中获取这些信息,那么它的速度就会得到很大的提高。
(2) 命中与未命中
上面我们写道,缓存共有C块,主存共有M块, M>>C
在CPU访问主存的时候,如果要访问的块已经放到了缓存当中,在缓存当中能够取到相应的数据或者指令,我们就成为命中。
命中: 主存块调入缓存,标记记录与某缓存块建立了对应关系的
主存块号
未命中:主存块未调入缓存,主存块与缓存为建立对应关系
如果命中了,就说明主存和缓存有某种对应关系,这个对应关系就可以用前面说到的标识符来表示
(3) Cache的命中率
CPU欲访问的信息在Cache的比率
命中率与Cache的容量和块长有关,一般每块可取4-8个字
块长取一个存取周期内从主存调出的信息长度
(4) Cache-主存系统的效率
Cache-主存系统的效率e 与命中率有关

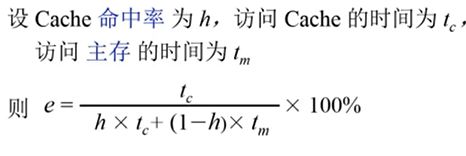
1.3 Cache的基本结构
全相联Cache
在全相联Cache中,存储的块与块之间,以及存储顺序或保存的存储器地址之间没有直接的关系。程序可以访问很多的子程序、堆栈和段,而它们是位于主存储器的不同部位上。
因此,Cache保存着很多互不相关的数据块,Cache必须对每个块和块自身的地址加以存储。当请求数据时,Cache控制器要把请求地址同所有地址加以比较,进行确认。 这种Cache结构的主要优点是,它能够在给定的时间内去存储主存器中的不同的块,命中率高;缺点是每一次请求数据同Cache中的地址进行比较需要相当的时间,速度较慢。
直接映像Cache
直接映像Cache不同于全相联Cache,地址仅需比较一次。
在直接映像Cache中,由于每个主存储器的块在Cache中仅存在一个位置,因而把地址的比较次数减少为一次。其做法是,为Cache中的每个块位置分配一个索引字段,用Tag字段区分存放在Cache位置上的不同的块。
单路直接映像把主存储器分成若干页,主存储器的每一页与Cache存储器的大小相同,匹配的主存储器的偏移量可以直接映像为Cache偏移量。Cache的Tag存储器(偏移量)保存着主存储器的页地址(页号)。
以上可以看出,直接映像Cache优于全相联Cache,能进行快速查找,其缺点是当主存储器的组之间做频繁调用时,Cache控制器必须做多次转换。
组相联Cache
组相联Cache是介于全相联Cache和直接映像Cache之间的一种结构。这种类型的Cache使用了几组直接映像的块,对于某一个给定的索引号,可以允许有几个块位置,因而可以增加命中率和系统效率。
1.4 Cache的读写操作
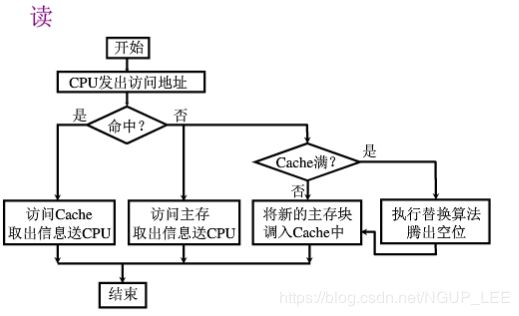
'读’操作不对Cache内存中的内容进行修改,Cache和主存块中的内容还是一致的,但是’写’操作就不一样了,'写’操作是可以造成主存和Cache的不一致。

1.5 Cache的改进
(1) 增加Cache的级数
比如片载Cache,片外Cache等
(2) 同意缓存和分立缓存
比如指令Cache,数据Cache等,与指令执行的控制方式有关
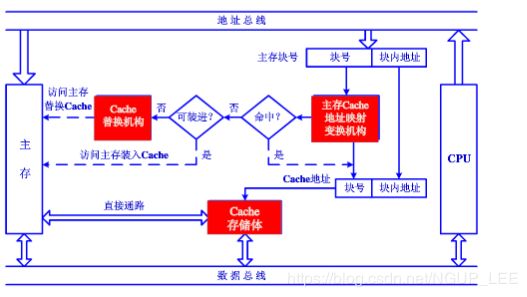
2.0 Cache主存的地址映射
“地址映射”就是指主存当中的任意一块如果要加载到Cache当中的话,可以加载到Cache当中的哪些块。
根据映射方式的不同,又可以分为三种地址映射方式。
(1) 直接映射方式
直接映射:就是指主存当中任意一个给定的块,只能映射到某一个指定的Cache块当中。
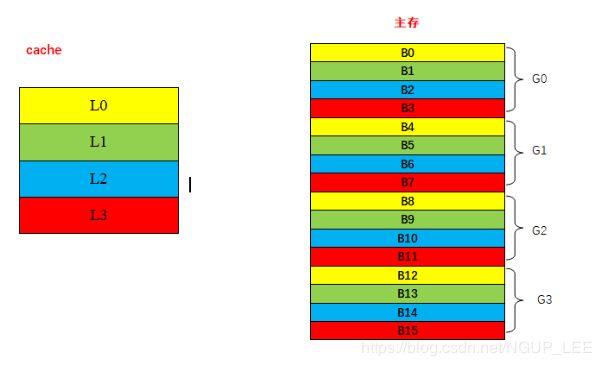
通俗理解:相当于将主存空间按cache的大小(行数)进行分区(说“分组”也可以),主存分区(组)后,每区(组)中的数据块数目与cache的行数一致。
-
首先将主存按照cache的大小进行分区(组):16/4=4(组),即将主存分为4组,编号分别为G0~G3,这样每组中拥有与cache行数相同的数据块。
-
对每组内的数据块进行“组内重新编号”,即B0变为G0的b0,B1变为G0的b1,B2变为G0的b2,B3变为G0的b3;B4变为G1中的b0,B5变为G1中的b1,B6变为G1中的b2,B7变为G1中的b3。依次类推。
-
这样,组内编号为b0的主存块如果需要拷贝至cache,只能放置到L0;b1只能拷贝到L1;b2只能拷贝到L2;b3只能拷贝到L3。如上图所示,相同颜色的说明可以进行拷贝。
优点:硬件简单,容易实现,成本低。
缺点:发生块冲突的概率较大,导致cache的命中率、效率下降。
适用情况:大容量的cache,更多的行数可以减小冲突发生的机会。
(2) 全相联映射方式
可以记为是直接映射的另一个极端
全相联映射:是指主存当中任何一个块可以被放入到Cache的任何一个块当中。
通俗理解:对于主存中的数据块可以拷贝到cache中的哪一行不做硬性规定。
-
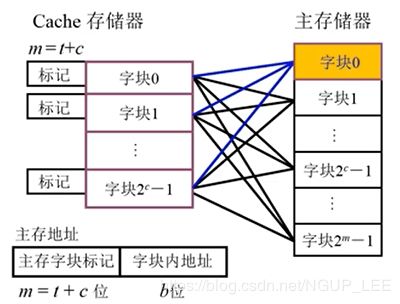
CPU提供一内存地址给cache,cache中的“控制逻辑”将“主存地址格式”中的“主存块号”与cache中所有行的标记tag进行同时比较。
-
如果存在相同的,即表示“命中”,根据“块内偏移地址”找到相应的字。
-
如果不存在相同的,即表示“未命中”,那么将会到主存中寻找。
优点:该映射方式下,块冲突的概率低,cache利用率高。
缺点:硬件控制复杂,尤其是用于比较“主存块号”与tag时的比较器电路难于设计与实现。
适用情况:小容量的cache
(3) 组相联映射方式
可以记为是直接相联映射和全相联映射的折中
理念:是直接映射方式与全相联映射方式的折衷方案,适度地兼顾了二者的优点又避免二者的缺点。
将cache的空间分为若干组,主存块与cache组之间直接映射,而组内各块之间全相联映射。
关键:cache的分组数=主存每一组的块数
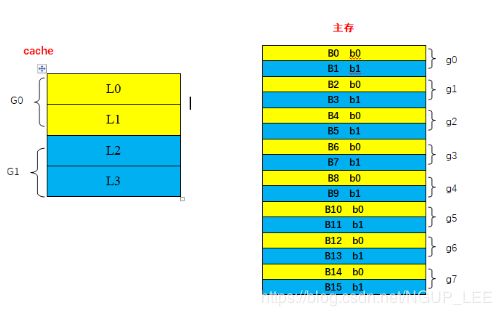
举例:假设有主存-cache体系,cache共4行,主存共16块。cache的4行编号为:L0L3,主存的16块编号为B0B15。采用2路组相联映射。如下图所示:
-
cache共4行,采用2路组相联映射,即将cache分为2组G0~G1,每组2行。
-
cache的分组数=主存每一组的块数,即将主存分为8组g0~g7,每组2块。
-
主存组内进行重新编号b0、b1,如上图所示
-
凡是组内编号为b0的主存块,可以拷贝至cache的G0组,至于是2行中的哪一行,是随机的无硬性规定的。依次类推,组内编号b1的主存块可以拷贝至G1组
该映射方式实现较为容易,块冲突概率比直接映射方式低,命中率介于直接映射方式与全相联映射方式之间。被普遍采用。
3.0 替换算法
为什么要用到替换算法?
Cache的映射给出了一个内存块放入到Cache当中可以放入到哪些位置,在放入过程当中如果我们发现发现,可以放入内存块的Cache的位置都被占用了,没有位置可以存放内存块了,这时就必须有一个Cache块被替换出来,我们需要这个内存块装入到Cache,这时就需要一个替换算法。
替换算法就是选择哪一个Cache块从Cache当中退出
(1) 先进先出 FIFO算法
这种方法认为,先进入Cache中的块他的内容CPU已经用完了,或者是在之后的一段时间CPU不会用的块中的内容,所以就可以将这个Cache块替换出去。
我们很容易就可以意识到这个算法是有问题的!
(2)近期最少使用 LRU算法
将最近最少使用的内容替换出Cache;
(3)LFU算法
将访问次数最少的内容替换出Cache
参考文章https://blog.csdn.net/qq_38768922/article/details/78737284?fps=1&locationNum=2