计算机组成原理学习笔记(二)数据的表示和运算(学习王道)
书接上回,让我们开始继续学习第二章节的知识;这里,我们先放一放硬件的知识,来学一下有关数据的知识。虽然本蒟蒻见识比较少,但是还是感觉这一章节的内容实际上是与计算机网络的编码部分的内容有相似之处,我学起来倒是比较轻松,笔记可能不会十分详析,只会挑一点我觉得稍微有点意思的东西记录。而且王道里面许多的ppt是很详细易懂的,我就不会说是自己逞强来用自己不顺畅的语言来解释,能懂就行!
目录
一、进位计数制
真值和机器数
思维导图
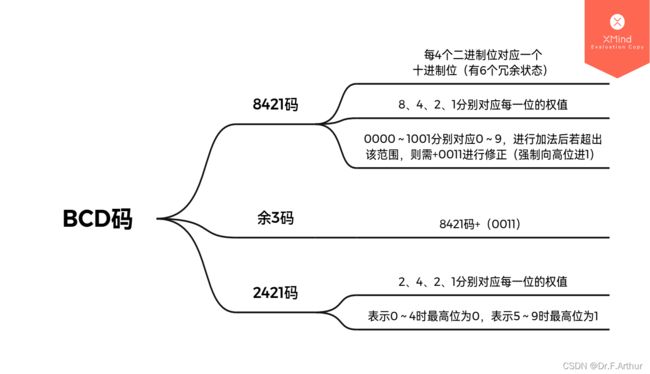
二、BCD码
1、8421码
2、余3码
3、2421码
4、思维导图
三、字符与字符串
1、英文字符
2、中文符号
3、字符串
4、思维导图
四、校验码
1.奇偶校验码
2.海明码
3、循环冗余码:CRC
五、定点数的表示与运算
1.定点数的表示
(一)无符号数
(二)有符号数
(三)原码
(四)反码
(五)补码
(六)移码
2.各种码的作用
3.移位运算
(i)算术移位
(ii)逻辑移位
(iii)循环移位
4.加减运算和溢出判断
5、原码的乘法运算
6、补码的乘法运算
7、原码的除法运算
(i)恢复余数法
(ii)不恢复余数法
8、补码的除法
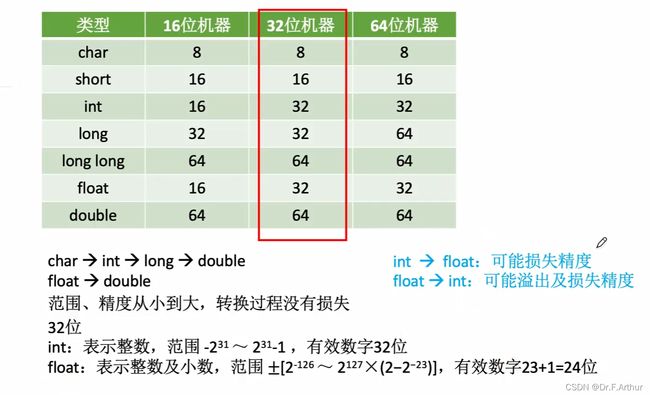
9、强制类型转换
10、数据的存储和排列
11、浮点数的表示
规格化
12、IEEE 754
13、浮点数的运算
(1)对阶
(2)尾数加减
(3)规格化
(4)舍入
(5)判溢出
!C强制类型转换!
14、电路的基本原理、加法器设计
15、加法器、ALU的改进
感想
一、进位计数制
显然,根据不同的实际需求,不同的进制有存在的意义与价值:十进制是常见的数学运算、二进制是计算机的电路中常见、八进制与十六进制也常见于计算机的程序概念中、六十进制是时间的进制标准。
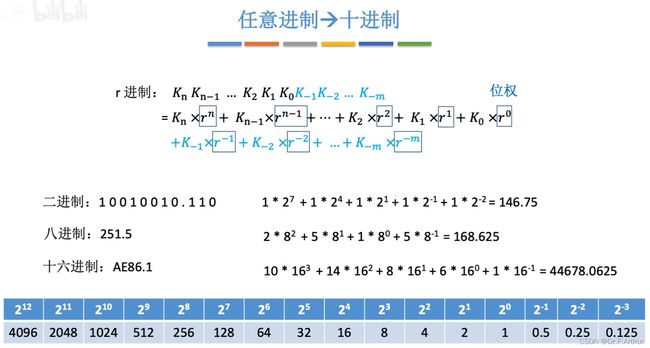
上图是显而易见的,也是容易理解的,但是这里还是要提一两个例子说明不同进制要小心的计算如下:
八进制:5.4+1.4=7.0(满八进一,小数点后一位4+4=8+0)
十六进制:5.8+0.9=6.1(满十六进一,小数点后一位9+8=17=16+1)

实际上,我是习惯于直接看,整数部分75是大于64却小于128,那么64所在的位数上放一个1,现在记为1000000;75-64=11,那么是小于32和16的,那两位取0不变;11却大于8,所以变为1001000;11-8=3小于4大于2,所以变为1001010;3-2=1结束,所以是1001011;但是小数部分有点问题在于,可能会无法准确表示,比如这个0.3。
真值和机器数
真值:符合人类习惯的数字,比如100,-13等等。
机器数:机器能够识别的的数据,其符号位用0、1表示正负;比如:0 1111表示15,而1 1000表示-8。
思维导图
二、BCD码
所谓的BCD码的意思是:用二进制表示的十进制,其种类有8421码、余3码、2421码。
1、8421码
众所周知,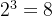 ,而
,而![]() ,所以想要表示十进制,至少要使用4位二进制数据才可以。而这四位分别是
,所以想要表示十进制,至少要使用4位二进制数据才可以。而这四位分别是![]() ,所以说8421。而且16-10=6,所以冗余了6个,也就是说有6种组合是用不着的。
,所以说8421。而且16-10=6,所以冗余了6个,也就是说有6种组合是用不着的。

那985用8421码表示就是 1001 1000 0101
8421码的加法运算是会考的可能性不大,考纲里面删了,但是至少应该会,万一面试问呢?这里的例子有两种解法,前一种比较取巧。
求解 5 + 8:
8421码:0101 1000
法一:先转换成十进制,得13,再转换成8421码:1 0011
法二:这是计算机的计算逻辑
0101 + 1000 = 1101(这样虽然转换成十进制是对的,但是之前给的那个标准表里面是没有这个的,所以不认可)
然后在运算结果的基础上再+6(也就是0110),结果就成了1 0011(注意进位)。
要注意的是,只要落在了范围10到16之间,也就是1010到1 0010,就得+6进位来修正。
再比如9+9=18,1001+1001=1 0010,然而这个并不是18,要+6(0110)修正,就变成了1 1000。
2、余3码
在8421码的基础上,再加3,也就是![]()

不同于8421码每一个位是固定数字的有权码,这余3码单纯就是符号的组合表示。下一个将要介绍的2421码就是一个改变了权值的有权码。
3、2421码

4、思维导图
三、字符与字符串
1、英文字符
ASCII码是很常见的一个概念:128( )个常用字符用七位数字来表示,但是存入计算机的时候,考虑到往往是8bit,所以会在最高位凑一个0满足1B来存储。
)个常用字符用七位数字来表示,但是存入计算机的时候,考虑到往往是8bit,所以会在最高位凑一个0满足1B来存储。
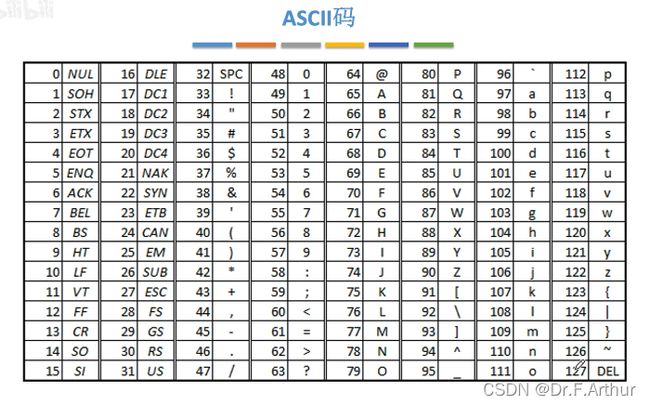
表格中的32到126都是可印刷字符。其他的是控制字符或通信字符。
当然了,其中的编码大小也是有根据的,值得了解一下。比如说,0~9(BCD码:0000~1001)的ASCII码是48~57(0011 0000~0011 1001),规律还是十分明显的。
出题的话,可能会出这样的题目:'A'的ASCII码是65,那么'H'的ASCII码换成二进制如何表示?
'H'-->72-->16*4......8-->0100 1000
2、中文符号
曾经有过GB 2312-80也就是1980年的国标,采用的是区、位的区位码表示(其实可以理解为二维数组),只有常见的7445个汉字。在实现的时候,要考虑到通信的时候不能和ASCII中的通信字符搞混,所以会加一个20H(也就是十进制的32)就是国标码,再然后又不能和英文的符号搞混,所以在国标码的基础上再加上80H,成为汉字机内码。
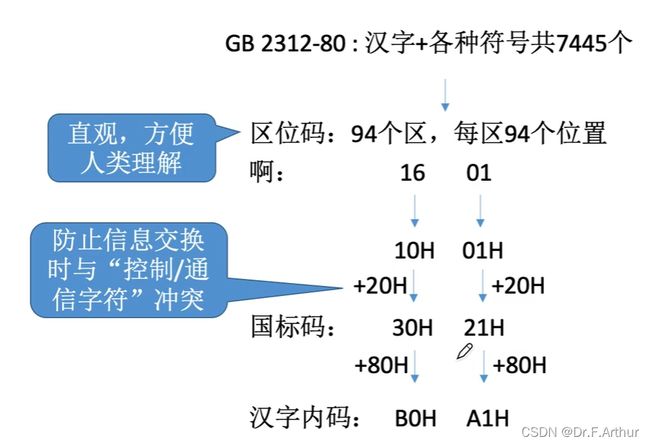
我们实际生活中,不会记忆这么复杂的东西,我们的使用实际上是分为输入的“输入编码”(比如拼音或五笔)、输出的汉字字形码。
3、字符串
看图就能懂,没什么好说的。
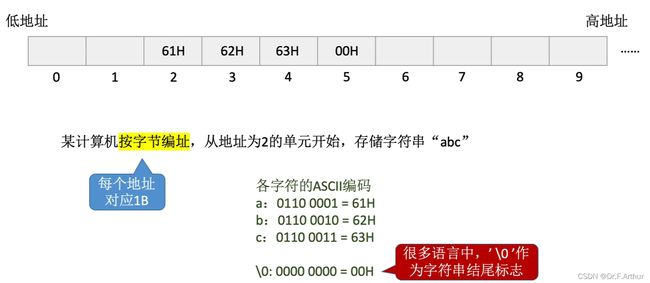
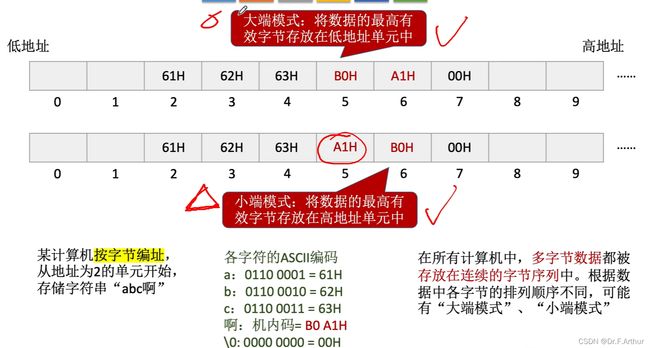
4、思维导图

四、校验码
又看到了一个老伙计了,之前在计算机网络那里可算是学过了,这里再温习一遍!
1.奇偶校验码
这个算是校验码里面简单的了,意思就是规定了若干位来编码表示一个意义,但是特别规定其中的1的个数是奇数或者偶数才是合法的表示方法。其组成是n位的有效信息位,和1位的校验位,校验位取0或1取决于这是奇校验码还是偶校验码还有信息位的1的个数。比如:

上图例中,如果奇校验码11001101跳变为11001100就不符合奇校验码的编码规则,可以查出错误,要求重传。
但是检错能力却对偶数数量的位错误跳变无法检测,比如奇校验码11001110就无法检测出来。
这里还需要弄明白几个术语的概念:
码字:由若干位代码组成的一个字
两个码字之间的距离d:将两个码字逐位对比,具有的不同的位的个数
码距:若干合法码字各自之间最小的距离
注意!如果d=1则无检错能力,d=2有检错能力,![]() 且设计合理则有检错甚至纠错能力!
且设计合理则有检错甚至纠错能力!
那么让我们接下来谈谈奇偶校验码是如何通过硬件来实现的,以偶校验码为例。计算机里面有元件进行异或运算(模二加法,同0异1)

2.海明码
最为强大难懂,好处是可以确定是否错误以及错误的位置,虽然只能纠错1位、检错2位。(比较难学,建议结合王道计网和计组的课程看,因为两边都讲,都讲的很好,我倾向于计网的讲解)
step1——确定位数:
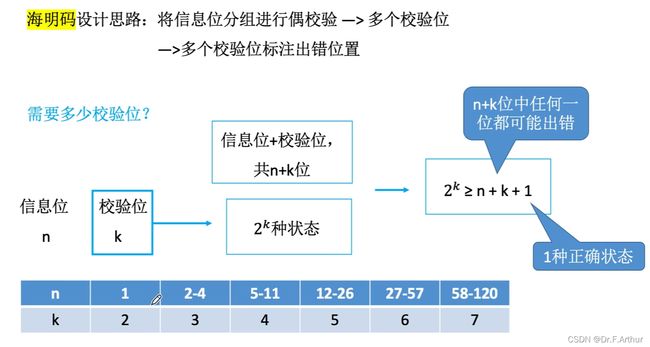
step2——确定校验码和数据的位置:
下面这张图,咸鱼学长的注释特别简单明了,直接上图,我解释没人家清楚!

咸鱼学长打叉的地方说明海明码的校验位和信息位的排布不同于之前学习的奇偶校验码!
step3——求出校验码的值:
这里我们举个例子,D=101101,按照step1和2可知:k=4,现列表如下:
| 二进制 | 0001 | 0010 | 0011 | 0100 | 0101 | 0110 | 0111 | 1000 | 1001 | 1010 |
| 数据位 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 代码 | 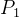 |
 |
 |
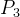 |
 |
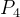 |
||||
| 实际值 | 1 | 0 | 1 | 1 | 0 | 1 |
首先,我们可以看出来的二进制位是0001,也就是说它校验的是最后一位,然后可以看出 、、![]() 、
、![]() 都是二进制末尾为1的。它们与进行异或运算最终结果为0则可!
都是二进制末尾为1的。它们与进行异或运算最终结果为0则可!
即:![]()
=> ![]()
=>![]()
=>![]()
=>![]()
=>![]()
同理,即可补全下表:
| 二进制 | 0001 | 0010 | 0011 | 0100 | 0101 | 0110 | 0111 | 1000 | 1001 | 1010 |
| 数据位 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 代码 | |
|
|
|
|
|
||||
| 实际值 | 0 | 0 | 1 | 0 | 0 | 1 | 1 | 1 | 0 | 1 |
这样就可以解出海明码的值为:0010011101
step4——检错与纠错:
上面的例子我们引申一下就可以用来讲解了。比如说,第五位跳变,收到的是:0010111101。那么令所有要校验的位进行异或运算,就可以得到错误的位置:
计算得:![]()
![]()
![]()
![]()
最后要从后往前写,0101就是5,所以检测出来了。
3、循环冗余码:CRC
事实上,前面的海明码功能更强,但是一般来说,CRC在一般大学里面的本科学生考试中考的多,比较简单。
首先我们要了解CRC的思想:数据收发双方需要约定一个共同的“除数”,K个信息位+R个校验位作为“被除数”,要保证除后的余数为0,收到数据后用约定的除数去除,余数不为0则传输出错。
然后,需要进一步看一看CRC的实例。

这样,我们就知道了除数。这是套路,记住就好。
至于校验位,其位数就是最高次幂的次数,上图例中校验位数应是3;加上题目中给的信息位是6位,那么总共是9位。
接下了因为我们要求那3位补上的校验位,所以不得不在低位补上0,即:
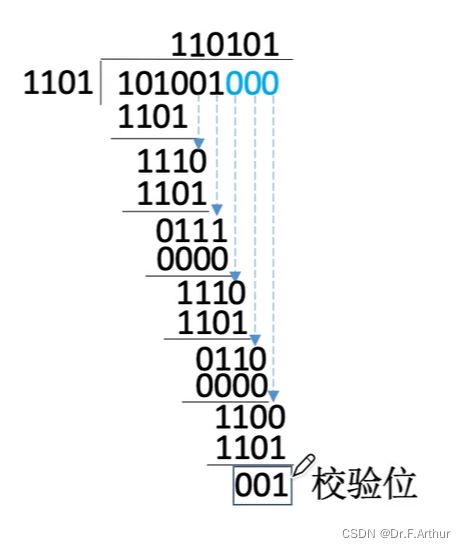
最终的CRC就是101001 001
五、定点数的表示与运算
1.定点数的表示
定点数(小数点位置固定)与浮点数(不固定)是对立的,举例理解如下:
定点数(常规计数):996.007
浮点数(科学计数):![]()
(一)无符号数
整个机器字长的二进制位全是数值位,相当于数的绝对值。
只需要知道n位无符号数的表示范围为:0~

另外,一般无符号数都是用于整数的概念,unsigned float会报错,unsigned int不会。
(二)有符号数
一个数如19.75整数和小数部分分别按照定点整数和定点分数表示。可以使用原码、反码、补码三种方式来表示定点整数和定点分数,用移码来表示定点整数。

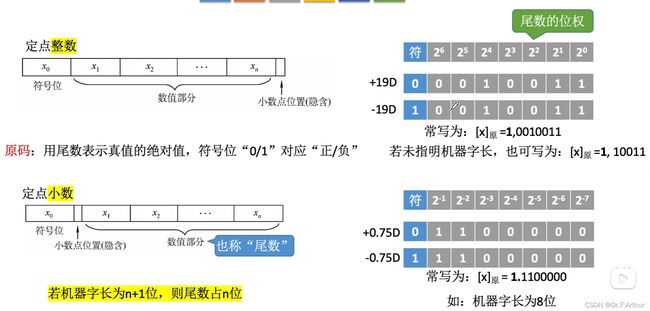
(三)原码
这个看图就可以懂,不废话(才不是因为有些符号体太难打的原因[doge])

(四)反码
这个东西然并卵,计算机不会用到,只是中间状态。

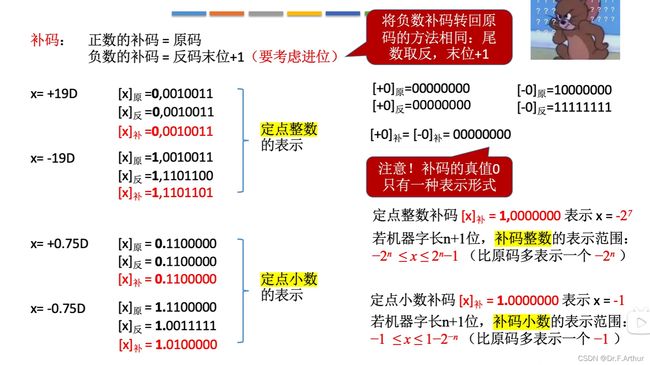
(五)补码
这个地方强烈建议自己动笔写一写,这样记忆深刻。
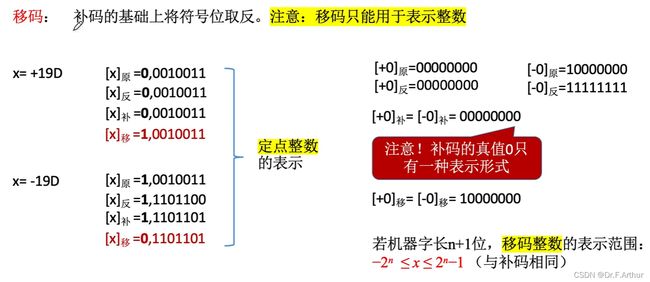
(六)移码
移码的好处就是方便计算机比较整数的大小。
2.各种码的作用
首先应该清楚的是,加减法运算对于无符号数是没有影响的,但是对于有符号数,就必须要求负数的符号位换为0,之前的加法变为减法。
例如:00001110
+10001110
也就是14+(-14)其实可以改写为14-14,也就是:
00001110
-00001110
——————————
00000000
就是很显然的结果了。
另外提前预告,补码的作用是使得用加法表示减法。毕竟电路上实现加法简单(加法器),如果再另外集成其他的功能(比如减法器)将会是非常的麻烦,所以考虑实现用加法表示其他的运算。
这个时候为了节省开支,人类就开始发挥聪明才智:计算机的特性就是它所能表示的数位是有限的,就好像钟表一圈是12个点,13点就是1点。所以如要使得时针从10点指到7点,有两种方法。一个就是逆时针从10到9到8再到7,这个就可以看作是一种减法;另一个就是从10越过12点再从1到7点,这就是一种顺时针的加法;但是从结果上看两者是完全等效的!
有同学问,这和计算机有什么关系呢?有呀!就拿大家最为习惯的例子就是,一个无符号数字用8bit表示,表示范围是0(00000000)~255(11111111),如果超出了范围,只会保留后八位的内容(1 01001000实际上保留为01001000)。这就有点像模运算了,或者说这就是计算机的模运算。
深究一些原理,就可以好好看一看数论的内容了,这里只做简单的阐述,方便考研学习使用。数论中对于余数的定义是:

例如:-3=(-1)*12+9 ,9=0*12+9
这里完全可以把-3和9看作是完全等价,因为10-3=7=(10+9)mod12
那么为什么不是-3和21=1*12+9一组呢?这是因为一组的两个数必须要求其绝对值相加和为模,这里|-3|+9=12。
所以有公式:模-x的绝对值=x的补数
注:这里补数就是补码
老例子,-14就可以表示为10001110,它的补码是先尾数部分全部取反:11110001,然后再加1,就变成了:11110010
所以14+(-14)其实可以改写为
00001110
+11110010
——————————
1 00000000
舍弃前面一位之后就是00000000,符合14-14=0。
3.移位运算
定义:移位就是使各个数码位和小数点的相对位置改变引发不同数码位位权的改变,来实现乘除的运算。

(i)算术移位
上图的例子很显然是十进制在我们生活中最常见的代表,我们也非常容易理解,那么问题就是计算机的二进制怎么表示呢?原码的位移运算见图如下:
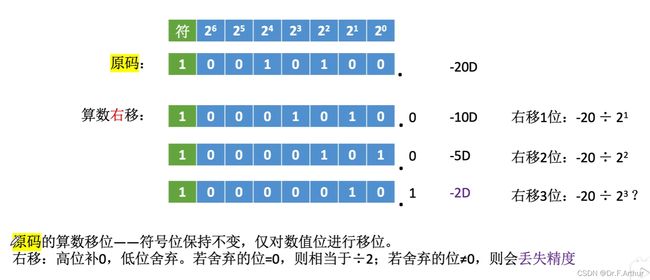
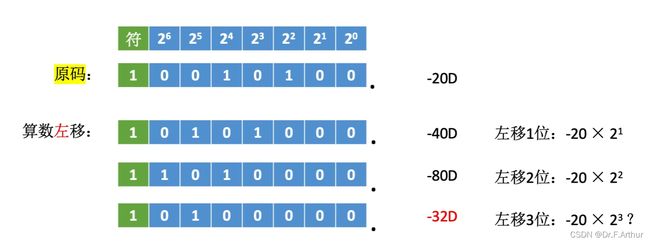
可以从第二张图中看出与第一张图不一样,那就是如果左边的1丢失就会造成严重误差,不是影响精度那么简单了。 但可以记住的是二者的位移都是依靠2的倍数变化的。
至于另一个定点小数部分也是同样的道理,不赘述了。
第二个需要认识的位移运算是反码的位移运算:
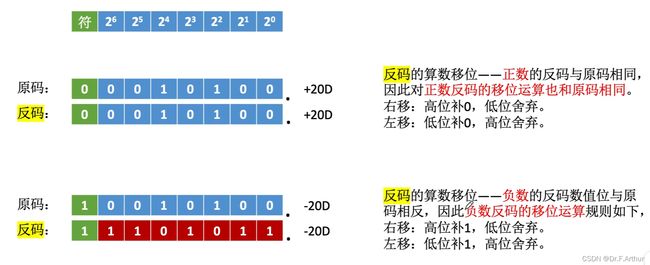
第三个需要认识的位移运算是补码的位移运算:
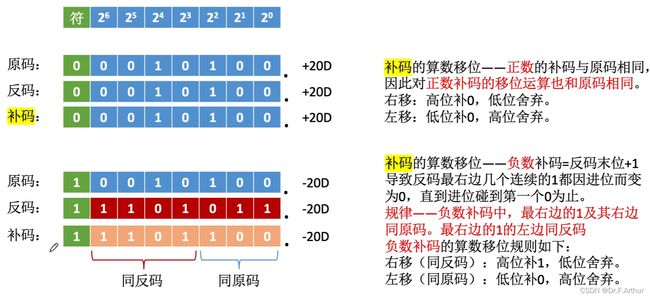
总结:
| 码制 | 添补代码 | |
| 正数 | 原码、反码、补码 | 0 |
| 负数 | 原码 | 0 |
| 补码 | 左移添0 | |
| 右移添1 | ||
| 反码 | 1 |
左移相当于*2,右移相当于/2。只是因为位数的限制,无法准确等效表示罢了。
实际使用中是这样的:

三个是否移位的结果相加后就是乘法结果。
(ii)逻辑移位

实际应用:
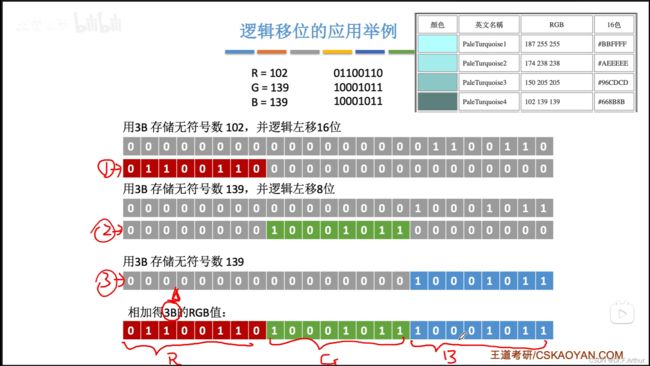
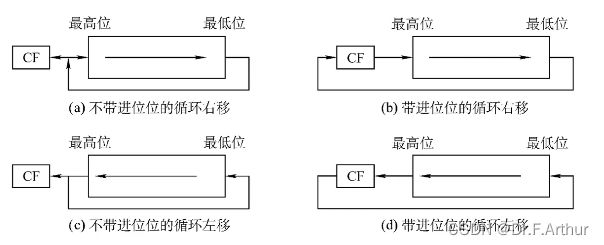
(iii)循环移位
比如说左移,移出来的那一位数字再补到右边缺失的数码位上去
4.加减运算和溢出判断

很显然最后两行的计算结果是不符合实际情况的,两个正数相加不应该为负,两个负数相加也不应该为正!这就是溢出了!
好了,既然我们明白什么是溢出了,那么我们开始了解溢出的判断吧!这是第一种判断方法:

第二种判断方法:

计算机只需要异或![]() 与
与 就可以了,结果为0则无溢出,1则是有溢出。
就可以了,结果为0则无溢出,1则是有溢出。
第三种判断方法:

值得注意的是,这里看到的双符号位在计算机取出来运算的时候才这样,存储的时候还是单符号位。取出来的时候复制一下 。比如说:A的补码是0,0001111这样存储的(逗号只是方便读者看我自己加的,计算机里面不存这个),然后运算时临时复制成00,0001111。
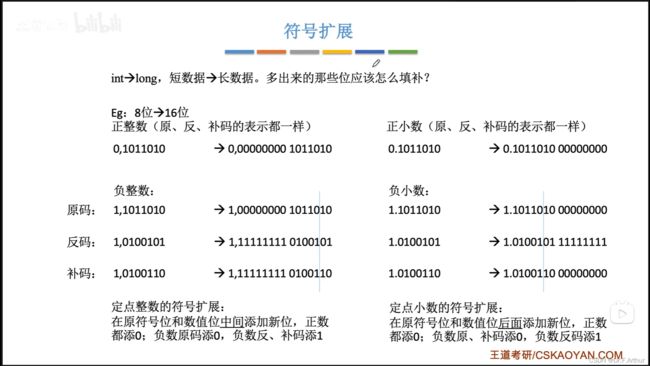
note:符号扩展!
5、原码的乘法运算
我们熟悉的十进制乘法该怎么列式计算就不多废话了,这里我们先以列式的方式展现二进制乘法的意思,然后我们再进一步理解计算机实现的需要改进的地方。

上图的算法在计算机当中实现时会遇到以下的问题:
1、实际的数字往往都是有正负的,计算机如何实现符号?
2、乘积的位数扩大一倍,字长已经不够表示了,那该怎么办?
3、多个位积都要保存下来,那么如何实现相加
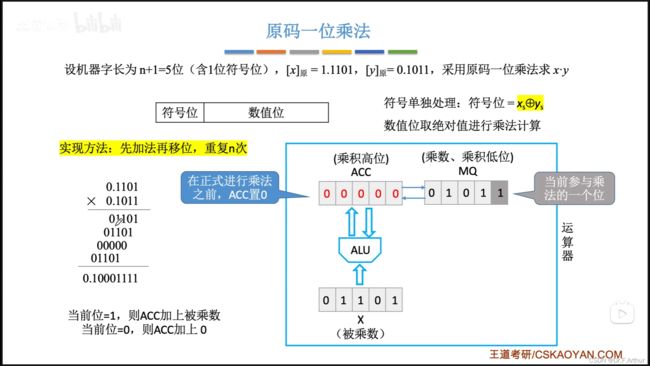
我们先认识一下原码一位乘法:

计算机的硬件实现如下:
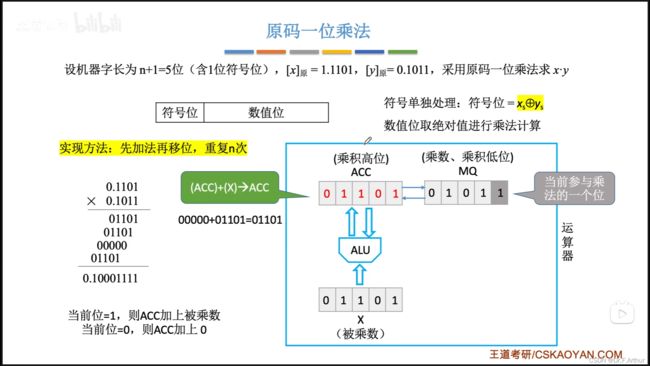

原先MQ末尾的那个1,将被丢弃,反正也被运算用过了。这样原先MQ的次低位就成了最低位,然后就是一个循环的过程。
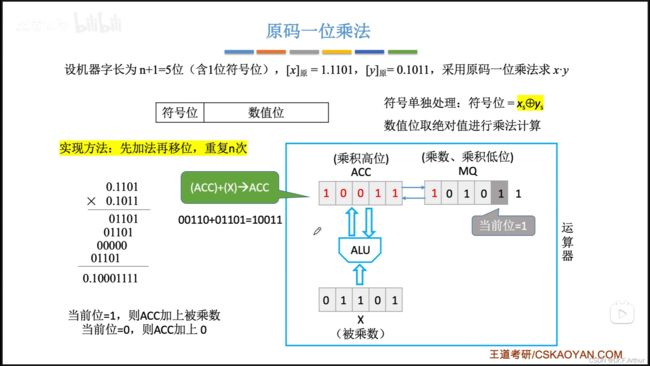 之后继续右移补0,红色的字称之为部分积;
之后继续右移补0,红色的字称之为部分积;
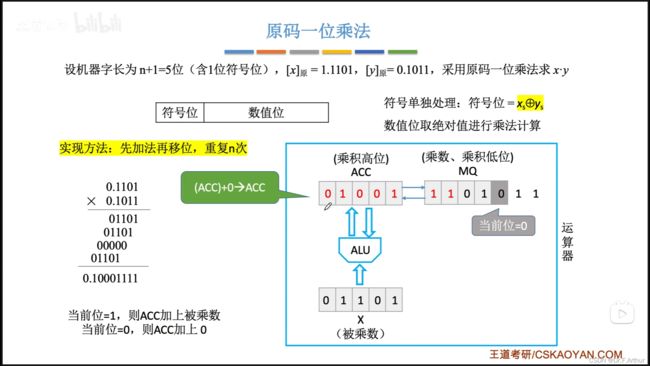
注意,加0是不变的,然后还有右移补0的步骤;
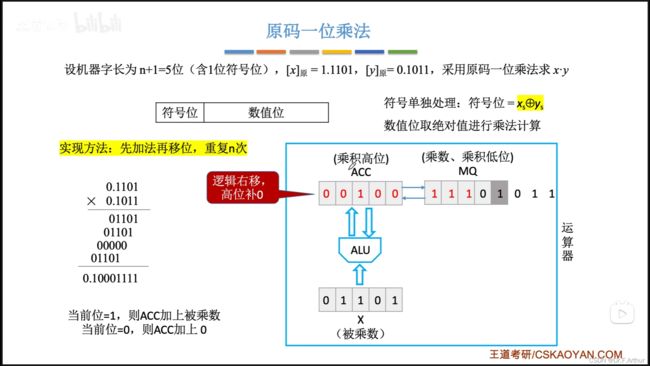
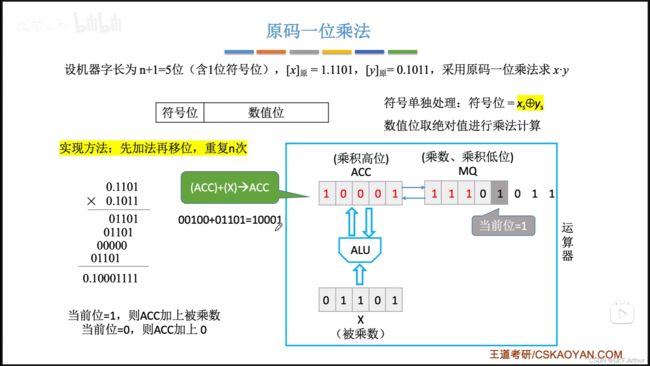

最后不能忘了符号位!
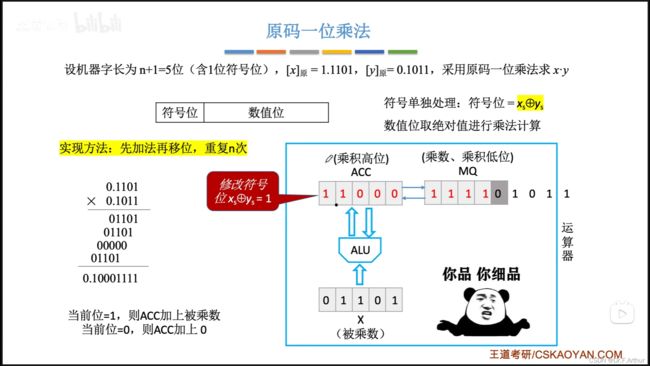
我们是人嘛,自己考试做题的时候肯定不可能那么繁,不会去画图;应该是依靠适当的方法来计算:
6、补码的乘法运算
下图是总览与对比
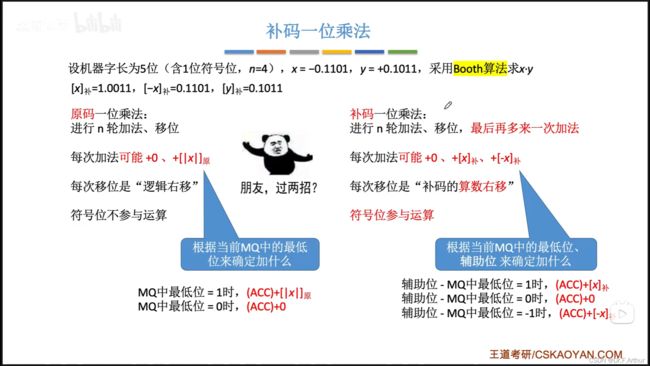
其中[-X]补就是[X]补码全部(包括符号位取反,然后加1)
运算器具体实现是这样:
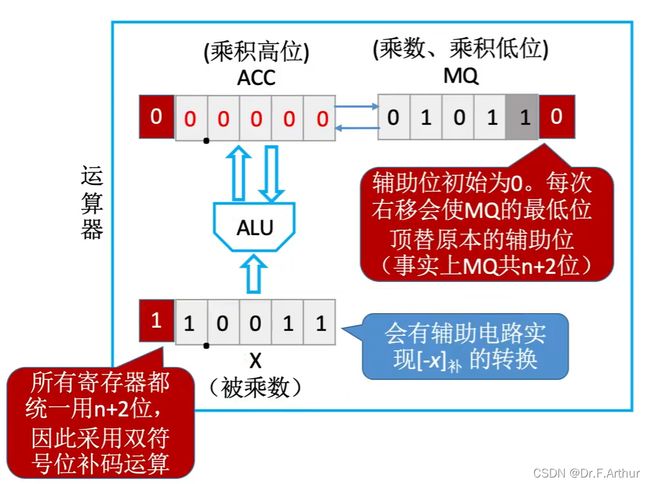
这个是应该如何手写的运算过程,考试就可以这么写:

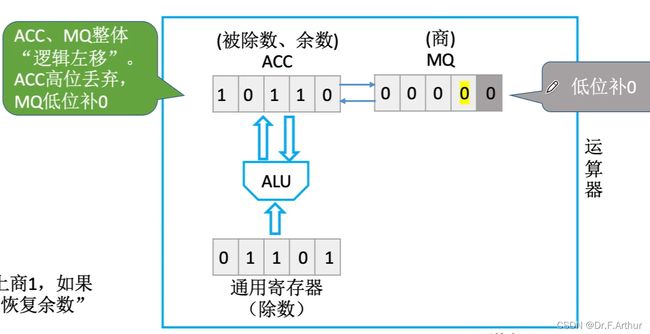
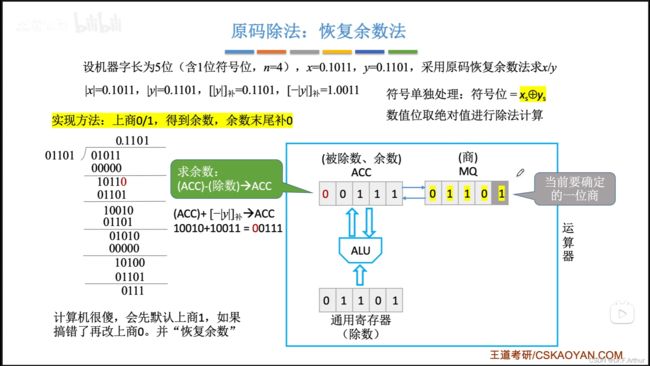
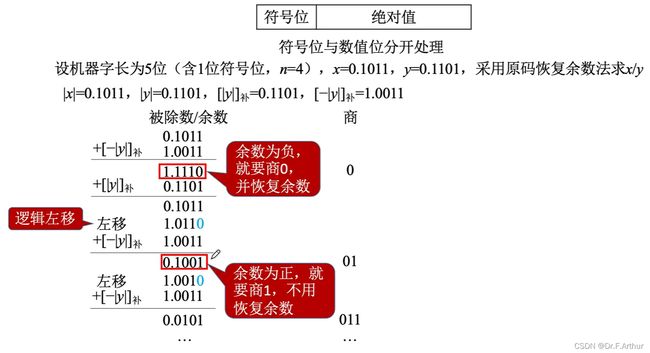
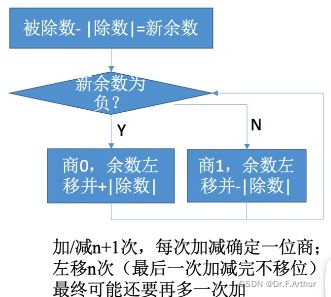
7、原码的除法运算
首先还是十进制来引入理解

那么接下来,我们就应该来看看二进制的手算是什么样的。
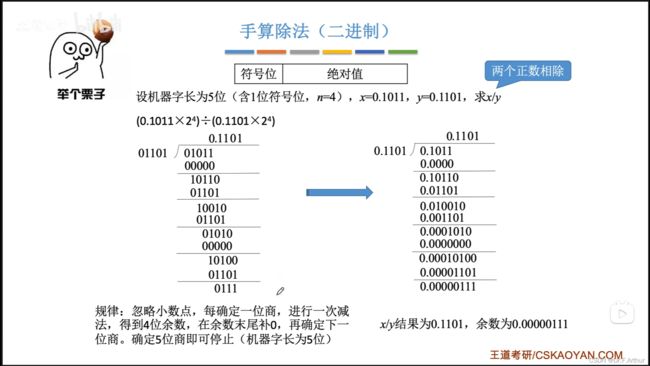 计算机的硬件实现显然是要通过运算器的各个组件来完成;
计算机的硬件实现显然是要通过运算器的各个组件来完成;
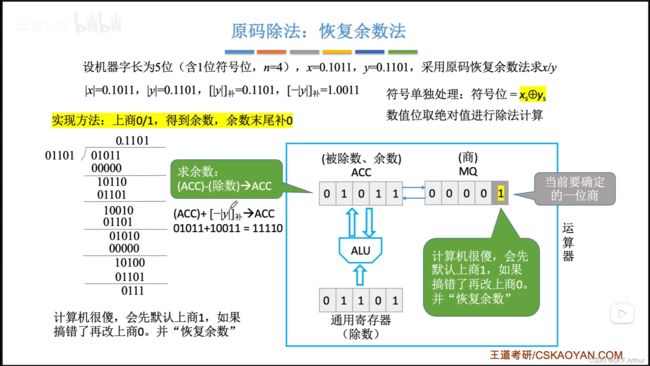
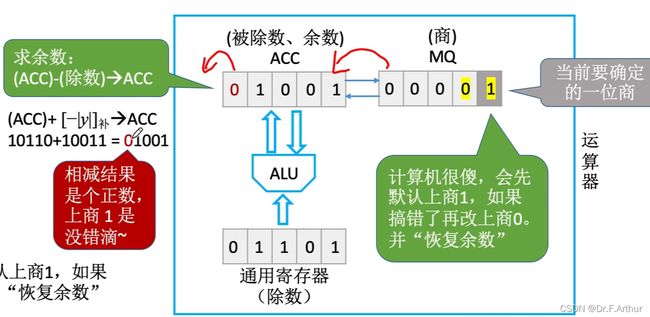
(i)恢复余数法
由于算出的结果是负数!这一点显而易见 !那么就说明了此处上1是大了!
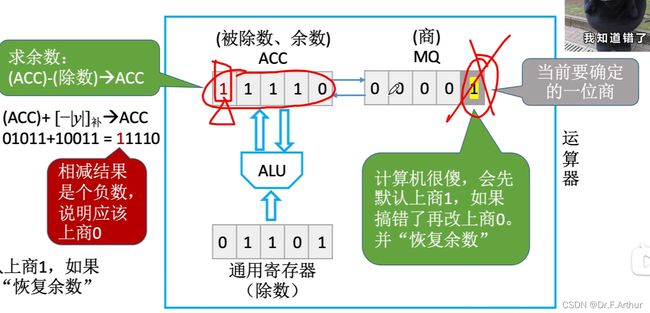
所以必须更改!
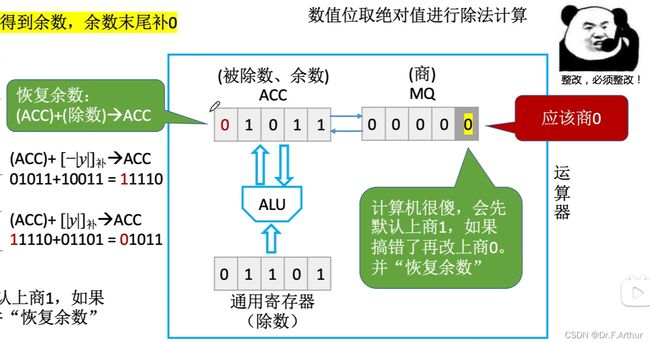
那么上0之后就必然要在对应的手算二进制除法式子当中下拖,即后位补上0,最前面的一位丢弃。
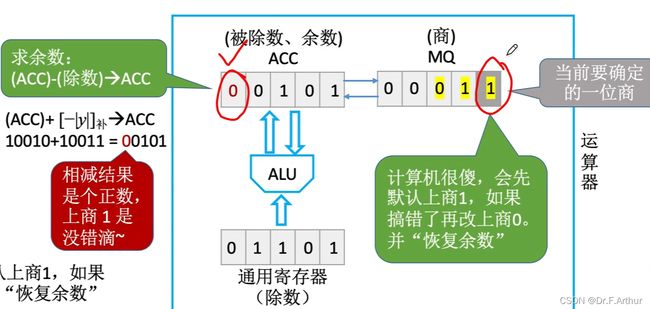
 到了下一位;
到了下一位;

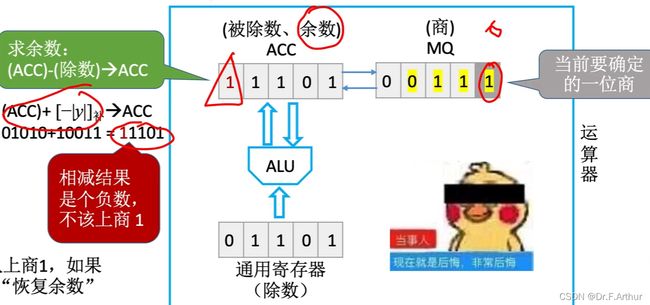
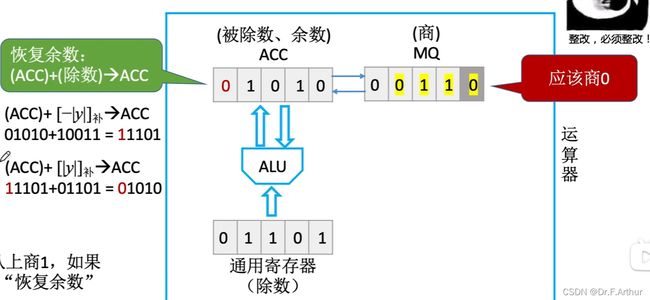
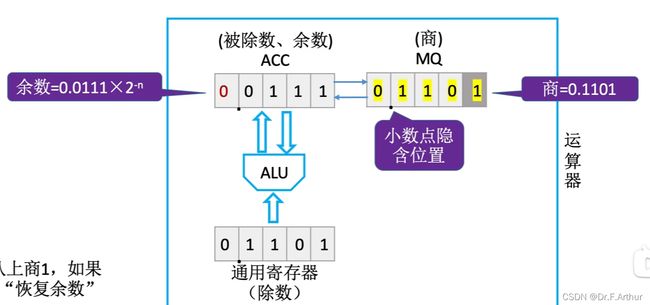
最后一步了,可以对比两边看一下,答案是正确的。
注意!如果其他题目最后一步不同于上图,结果算出来仍然是负数,那么就还是要还原上0来得到正确答案。
好!该到我们通过手算来模拟计算机的运算方法了

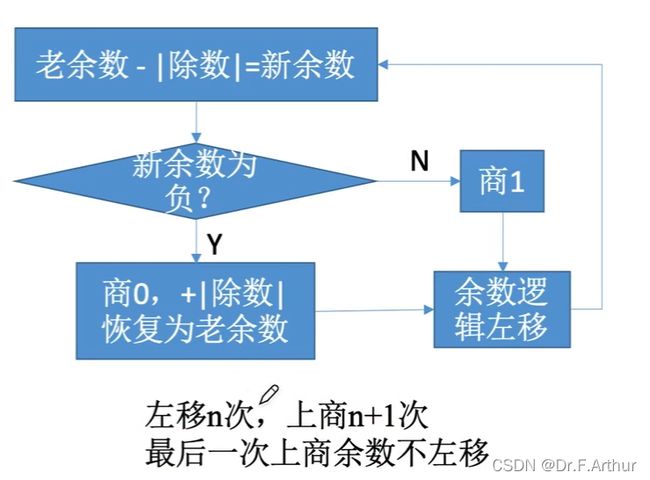 (ii)不恢复余数法
(ii)不恢复余数法
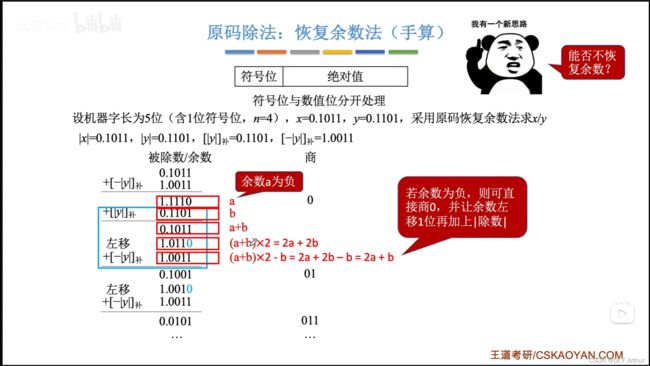
来一个小小的总结:
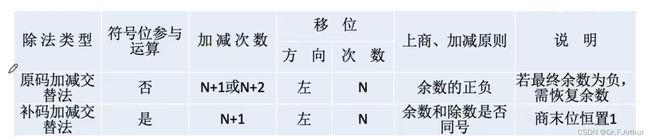
8、补码的除法
补码的除法也是采用加减交替法,不过与原码也有很大的区别,比如符号位要参与运算,而且是双符号位。
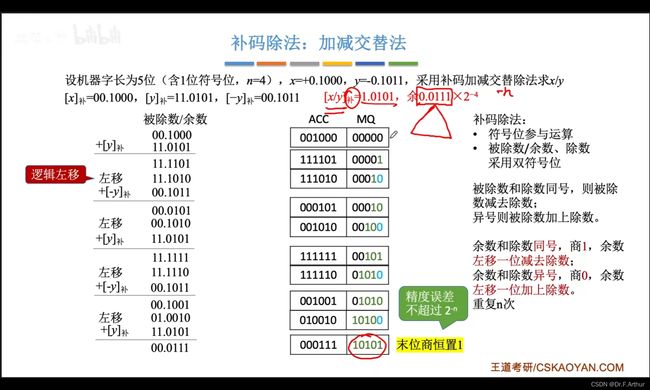
以下的小总结中,可以更加清楚的了解原码和补码的区别
9、强制类型转换
首先要在这里说明的是,在C语言中,int和long这些定点整数都是用“补码”来存储的!那么我们来看一下下图的例子。

比如x=-4321用2个字节,8个比特位来表示,上图的x是补码表示,转换为原码就是1001 0000 1110 0001
![]() )
)
=-4321
然而,如果强制转换成无符号数,比如这里的x转换成y,数值内容是没有变化了,但是怎么解释就不同了,这里的补码直接当成原码来使用,而且是没有符号位的原码!方便理解的计算过程如下:
1110 1111 0001 1111
![]()
=61215
绿色框内的部分所做的就是长整数变为短整数,高位直接不要,保留了低位。
比如上图中a=0000 0000 0000 0010 1000 0110 1010 0001=165537
截断后就是:
a=1000 0110 1010 0001(这个是补码)
=1111 1001 0101 1111(这个才是原码)
=-31071
红色框内的是短变长,要符号扩展!
比如还是x=1001 0000 1110 0001(补码),这时候要变为4字节表示的int类型,因为负的定点整数的补码进行符号扩展时是高位补1。所以扩展之后的x就是m:1111 1111 1111 1111 1110 1111 0001 1111
由于n到p都是无符号数到无符号数的扩展,或者理解为正数到整数的扩展,所以直接补0就可以了。
10、数据的存储和排列
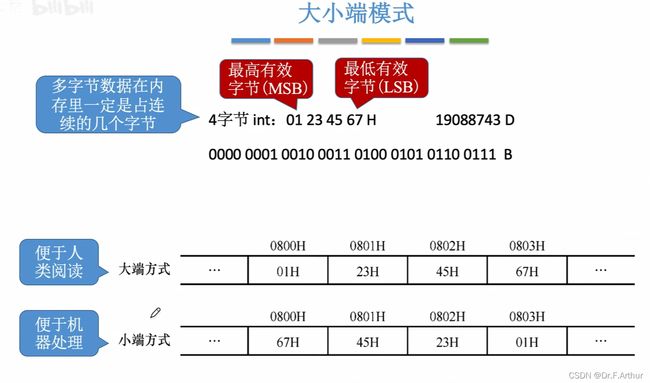
特别注意!字节、半字、字的概念区别记不清了可以翻我之前的笔记,去看定义,千万不要混淆了!
如果按照字节寻址,那么见下图的红笔标示;

下图我们要求按照半字来寻址,寻找3号半字,从0开始,3号是第4个。

下图我们要求按照字来寻址,寻找2号半字,从0开始,2号是第3个。

边界对齐有一个好处就是计算机容易读取,计算机每次访存只能读/写1个字,还不能跨行读/写。并且很显然在这个例子中,一个字就是32bit=2个半字=4个字节。所以n号字就是2n号半字(逻辑左移1位,右边补1个0),就是4n号字节(逻辑左移2位,右边补2个0),实现的时候只需要逻辑左移相应位数即可。

边界对齐是典型的空间换时间的思想。

这里我们言语描述一个例子:在C语言中,char、short、int分别是按照字节、 半字、字来存储的。那么我们假如S1的存储是short型的,存于半字1中。显然边界对齐的方式中,只需要读取第2行,也就是字号为1的内容即可,而在边界不对齐的方式中,我们不得不读取第1行的“半字1-1”和第2行的“半字1-2”来拼凑出S1。
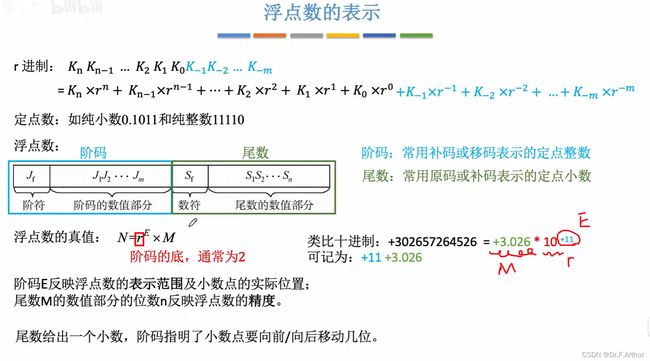
11、浮点数的表示
浮点数其实可以类比于科学计数来理解和记忆:
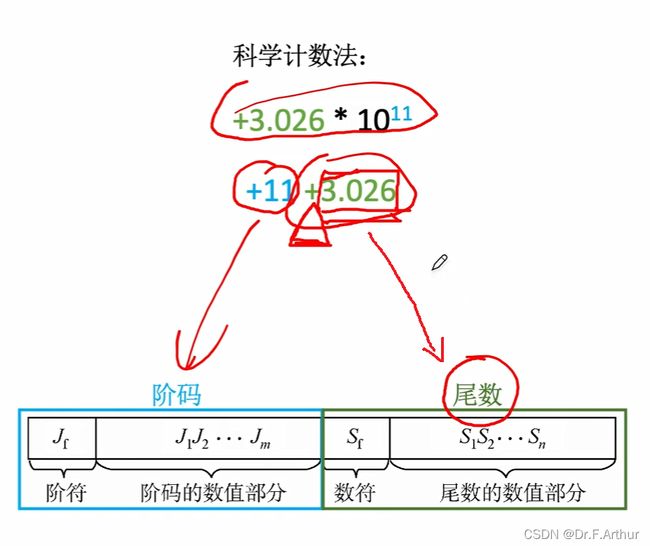
阶符和数符都是有正负性!并且阶码反映的是数值的大小,而尾数则表明数值的精度。
空泛的理论远远没有实际的例子让人容易理解,所以,我们看一道例题:

既然我们看到了a的例子,照猫画虎我们也能写一下b的答案(因为懒得截图):
b:阶码0,10对应的真值为+2;尾数0.01001对应的真值就是+01001
b的真值是![]()
规格化
一般来说,存储按照字节来存,1bit是8位,而上例中的b显然是不能存下的因为有9位,虽然a恰巧可以存下。那么我们就必须考虑解决这个问题,规格化就是一种好的解救方法。
尴尬的情况是这样的表格:
| 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 1 |
我们还是从科学计数法来引入理解:

所以我们只需要保证阶码和尾数的同步变换,就可以做到规格化了。
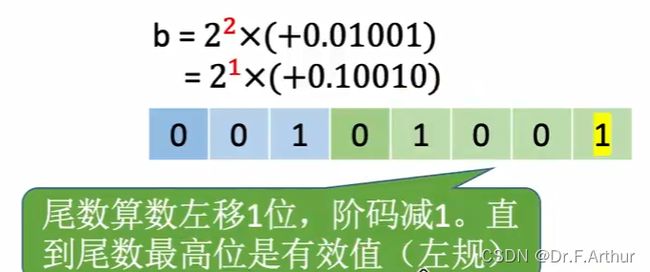
总的来说就是下图的要点:


注意有一个容易想不通的地方就是为什么负数的补码1.00....0表示最小值-1:我的理解就是首先小数点之前的1实际上是符号位,代表负数!然后负数的补码转原码是取反再加1,那么实际上的数值位0.000...0取反再加1的结果就是1.000...0,看清楚!这里的1可不是符号位了而是真真切切的![]() ,再加上之前的-号,那就是-1了!
,再加上之前的-号,那就是-1了!

这是对于上图的辅助理解!
12、IEEE 754
这个是使移码标准化的一个协议,但在理解之前,我们必须先了解它的移码(这和我们之前学的移码比,有扩展和延申):

要明白偏置值是怎么得到的,n就是代表位数。下面是一些例子,可以自己手算验证验证。

好了,既然了解了相关的移码部分,那么就深入了解这个标准吧!
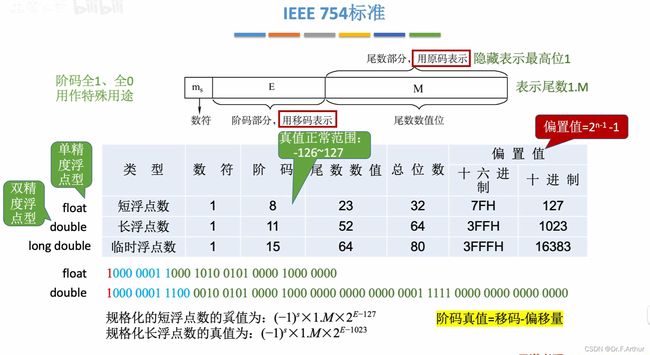
上图中我还是有一些个人的疑惑在里面的,所以写下我的看法。尾数的数值位,注意是数值位,这和我们之前学的浮点数的表示是有区别的,它的符号位直接放在了最前面,所以最前面的那个数符不是表示阶码的正负性,因为阶码的正负完全可以自己表示了;然后尾数的数值位因为是原码表示,根据我们之前学的浮点数的表示,必然其最高位是1,这样可以保证最大的精度(详见上一小标题内的内容),那么我们就可以省去这个1。一开始,我不太懂为什么要写成1.M来记,后来看了王道书上的举例解释就明白了:
十进制的12转换成二进制就是1100,如果规格化表示的话,很显然,类似于科学计数法就成了![]() ,其中整数部分的“1”将不存储在23位的尾数内,也就是隐含了。
,其中整数部分的“1”将不存储在23位的尾数内,也就是隐含了。
这里有例题1:求十进制(-0.75)的IEEE 754单精度浮点数格式。
解:![]()
所以![]() ,M=1(十进制)=10000000000000000000000(补全23位),s=1;最终的答案是:1 01111110 10000000000000000000000
,M=1(十进制)=10000000000000000000000(补全23位),s=1;最终的答案是:1 01111110 10000000000000000000000
例题2:求解IEEE 754的单精度浮点数C0 A0 00 00 H的值是多少?
解:C0 A0 00 00->1100 0000 1010 0000 0000 0000(也就是简单的十六进制转二进制的过程)
数符s:1表明是负数;
阶码E:100 0000 1=129;
尾数数值位M:.010 0000 0000 0000;
所以就是![]() ,答案就是十进制的-5了。
,答案就是十进制的-5了。
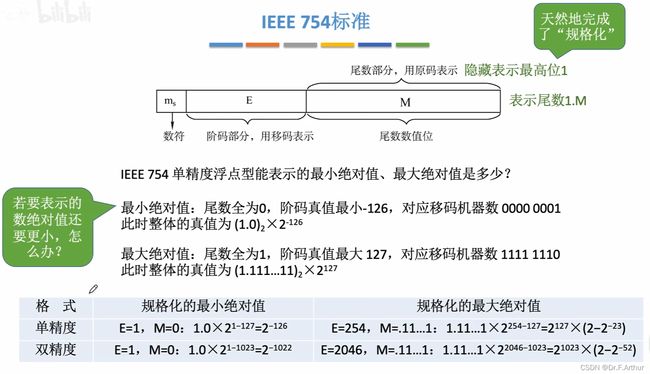
上图说的就是范围问题了,值得看一看。下面这个是补充,也是重要结论,记住!

13、浮点数的运算
分为五个步骤:
(1)对阶
小阶向大阶靠齐,这样可以方便计算机的表示。大、小阶是相对的,比如:![]() 是大阶,
是大阶,![]() 是小阶,对阶之后就是:
是小阶,对阶之后就是:![]()
(2)尾数加减
顾名思义,就是尾数相加减就可以了。这里承接之前的例子是:![]()
(3)规格化
规格化是建立在尾数相加减的基础上的,如果出现了![]() 这样的就需要左规;同理右规也是。
这样的就需要左规;同理右规也是。
(4)舍入
一般来说,计算机表示能力有限,所以会对尾数的位数有要求,过长的部分需要舍弃。同样,该怎么舍弃也是有相关的规定。
(5)判溢出
规定阶码的位数,这是不能超过的,否则计算机就无法表示了。

例题1:

目前我们是得到了正确的格式,接下来就是5步来实现运算。




这里舍入是也要注意看一下,有不同的舍入策略的:

!C强制类型转换!
14、电路的基本原理、加法器设计
那首先就是重要的硬件ALU,我们需要认识,知道基本的一些数字电路的知识。
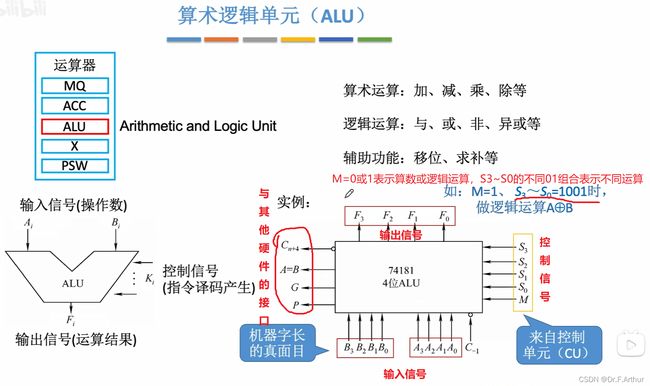
接下来我们从最基本的逻辑电路看起;
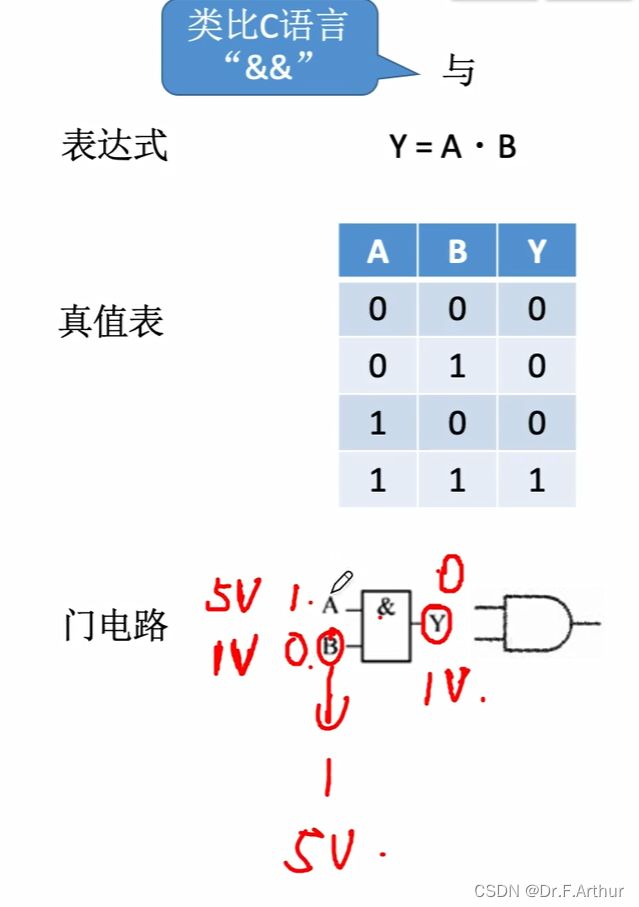
5V代表1,1V代表0,“与”运算只有都是1的时候才会输出1;

“或”运算只要求有一个为1就可以,所以那个框里面就写了![]() ;
;
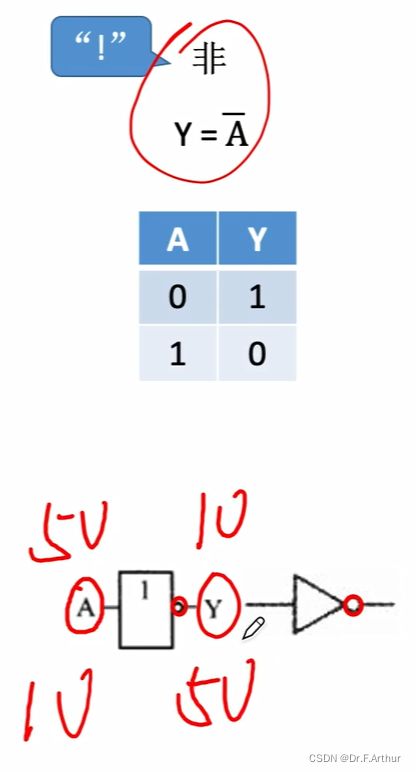
“非”运算就是取相反嘛,挺简单的。重点是要记得它们的电路符号长什么样。下面也是一些要点和例子 。
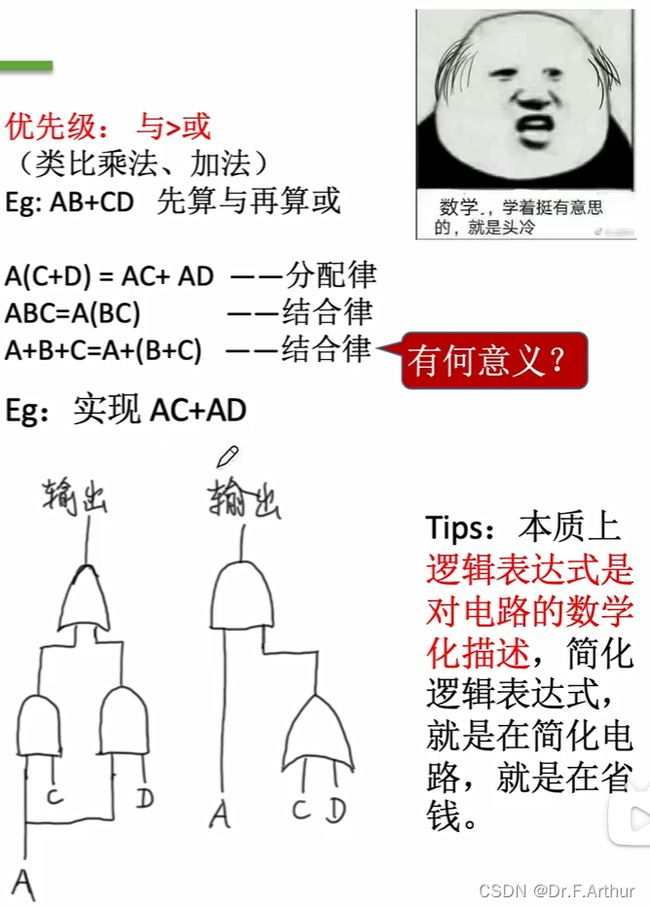
既然说过了简单的逻辑,那么这里也需要了解复合逻辑的相关内容。
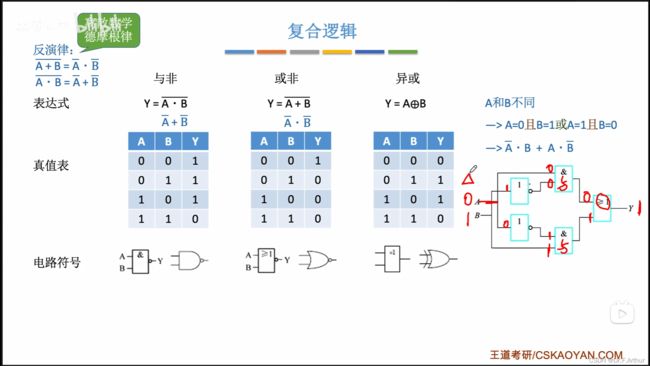
“与非”就是先与再非, “或非”就是先或再非,“异或”就是那句“同0异1”。还有一个提的比较少的就是“同或”运算,这和“异或”的运算口诀相反就是了,它的符号是 。
。
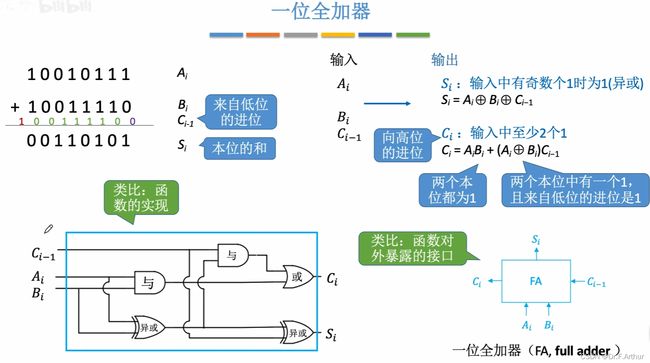
一个类比就是,上图左边那个电路图可以当成是代码实现,右边就是封包。下面看一下实际的加法器:
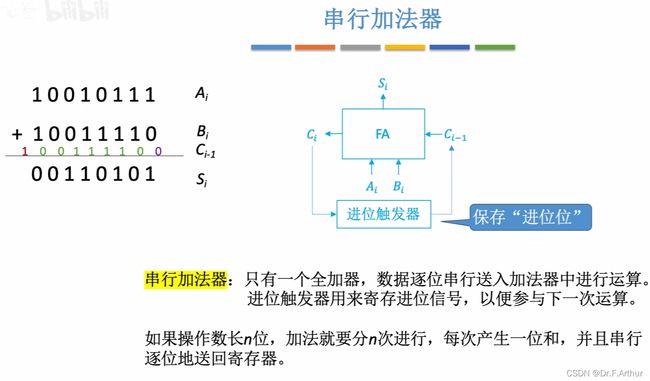
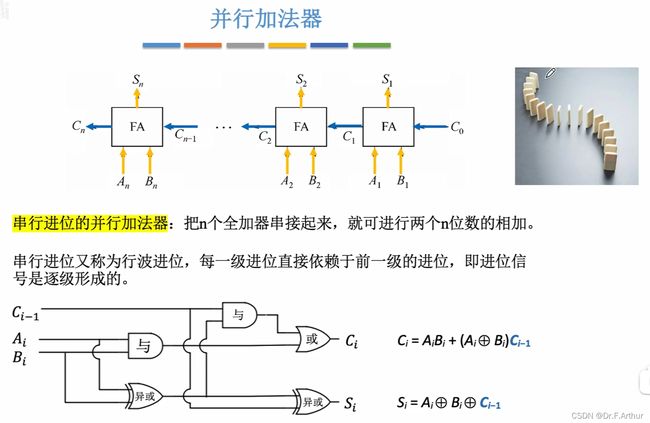
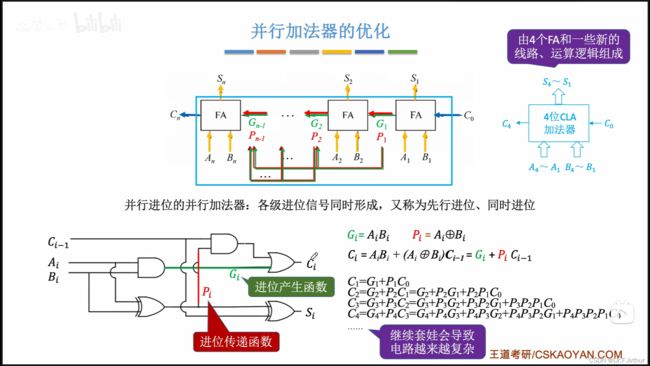
但是串行加法器效率显然是低下的,每算一位就得一级延迟 。所以与串行相对应的就是并行加法器:
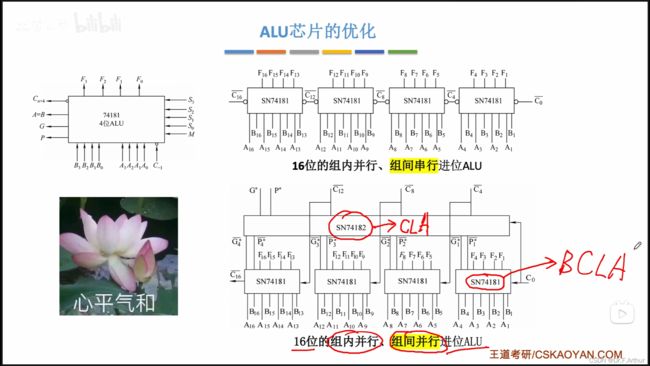
15、加法器、ALU的改进
唉,这个很麻烦,疯狂在套娃,看图吧,不想说了。


感想
好烦的内容,我不敢想,谢谢~祝大家都能学好学通!