ClickHouse表引擎MergeTree详解
一:MergeTree简介
MergeTree(合并树)及该系列(*MergeTree)是ClickHouse中最强大的表引擎。
MergeTree引擎的基本原理如下:当你有巨量数据要插入到表中时,你要高效地一批批写入数据片段,并希望这些数据片段在后台按照一定的规则合并。相比在插入时不断修改(重写)数据进行存储,这种策略会高效很多。
它的特点如下:
1)数据按主键排序。
2)可以使用分区(如果指定了主键)。
3)支持数据副本。
4)支持数据采样。
二:MergeTree的使用
格式:
ENGINE = MergeTree() ENGINE:引擎名和参数。
[PARTITION BY expr] PARTITION BY:分区键。要按月分区,可以使用表达式toYYYYMM(date_column)。
[ORDER BY expr] ORDER BY:表的排序键。可以是一组列的元组或任意的表达式,例如(id, name)。
[PRIMARY KEY expr] PRIMARY KEY:主键,需要与排序键字段不同,默认情况下主键和排序键相同。
[SAMPLE BY expr] SAMPLE BY:用于抽样的表达式。如果要用抽样表达式,主键中必须包含这个表达式。
[SETTINGS name = value, ...]
SETTINGS:影响MergeTree性能的额外参数:
(1)index_granularity:索引粒度。即索引中相邻标记间的数据行数。默认值:8192。
(2)use_minimalistic_part_header_in_zookeeper:数据片段头在ZooKeeper中的存储方式。
(3)min_merge_bytes_to_use_direct_io:使用直接I/O来操作磁盘的合并操纵时要求的最小数据量。
根据上述语法,可以发现必须要有时间列,因为要按月分区。
例:
create table mt_table(date Date, id UInt8, name String)
engine=MergeTree()
partition by date
order by(id, name)
settings index_granularity=8192;插入数据:
insert into mt_table values('2019-1-1', 1, 'zs1');
insert into mt_table values('2019-2-2', 2, 'zs2');
insert into mt_table values('2019-3-1', 3, 'zs3');
insert into mt_table values('2019-1-1', 4, 'zs4');
insert into mt_table values('2019-2-2', 5, 'zs5');
insert into mt_table values('2019-3-1', 6, 'zs6');
insert into mt_table values('2019-1-1', 7, 'zs7');
insert into mt_table values('2019-2-2', 8, 'zs8');
insert into mt_table values('2019-3-1', 9, 'zs9');
insert into mt_table values('2019-1-1', 10, 'zs10');
insert into mt_table values('2019-2-2', 11, 'zs11');
insert into mt_table values('2019-3-1', 12, 'zs12');查看数据存储结构(可见是以时间为文件夹存储):
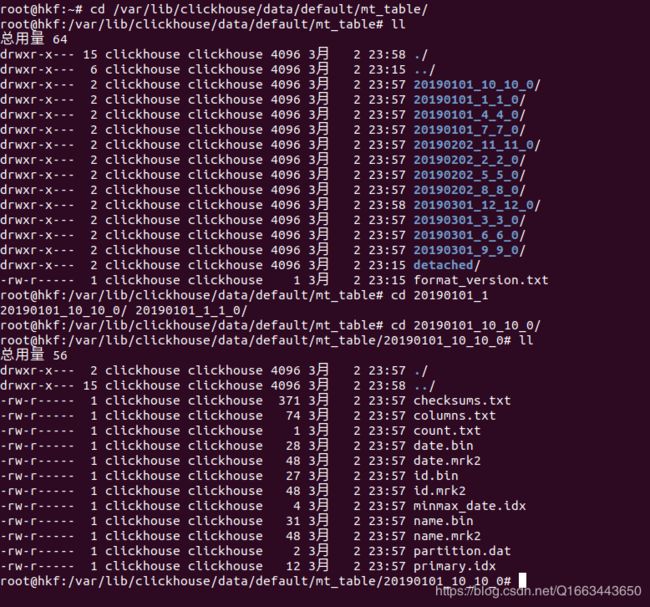
checknums.txt:检查文件,此处打开乱码就不做过多解释了。
columns.txt:有哪些列,如图:

count.txt:1列。
date.bin,id.bin,name.bin同TinyLog,存的是一列具体的属性。
date.mrk:存的是偏移量,索引有关。
minmax_date:最小和最大时间,此处只有一个时间,因此为0,待会合并会变化。
partition.dat:存储分区信息。
primary.idx:主键。
前面提到了,MergeTree以时间合并,因此多插入数据观察变化:
insert into mt_table values('2019-1-1', 1, 'zs1');
insert into mt_table values('2019-2-2', 2, 'zs2');
insert into mt_table values('2019-3-1', 3, 'zs3');
insert into mt_table values('2019-1-1', 4, 'zs4');
insert into mt_table values('2019-2-2', 5, 'zs5');
insert into mt_table values('2019-3-1', 6, 'zs6');
insert into mt_table values('2019-1-1', 7, 'zs7');
insert into mt_table values('2019-2-2', 8, 'zs8');
insert into mt_table values('2019-3-1', 9, 'zs9');
insert into mt_table values('2019-1-1', 10, 'zs10');
insert into mt_table values('2019-2-2', 11, 'zs11');
insert into mt_table values('2019-3-1', 12, 'zs12');
insert into mt_table values('2019-1-1', 1, 'zs1');
insert into mt_table values('2019-2-2', 2, 'zs2');
insert into mt_table values('2019-3-1', 3, 'zs3');
insert into mt_table values('2019-1-1', 4, 'zs4');
insert into mt_table values('2019-2-2', 5, 'zs5');
insert into mt_table values('2019-3-1', 6, 'zs6');
insert into mt_table values('2019-1-1', 7, 'zs7');
insert into mt_table values('2019-2-2', 8, 'zs8');
insert into mt_table values('2019-3-1', 9, 'zs9');
insert into mt_table values('2019-1-1', 10, 'zs10');
insert into mt_table values('2019-2-2', 11, 'zs11');
insert into mt_table values('2019-3-1', 12, 'zs12');
insert into mt_table values('2019-1-1', 1, 'zs1');
insert into mt_table values('2019-2-2', 2, 'zs2');
insert into mt_table values('2019-3-1', 3, 'zs3');
insert into mt_table values('2019-1-1', 4, 'zs4');
insert into mt_table values('2019-2-2', 5, 'zs5');
insert into mt_table values('2019-3-1', 6, 'zs6');
insert into mt_table values('2019-1-1', 7, 'zs7');
insert into mt_table values('2019-2-2', 8, 'zs8');
insert into mt_table values('2019-3-1', 9, 'zs9');
insert into mt_table values('2019-1-1', 10, 'zs10');
insert into mt_table values('2019-2-2', 11, 'zs11');
insert into mt_table values('2019-3-1', 12, 'zs12');插入完成后,初始状态:
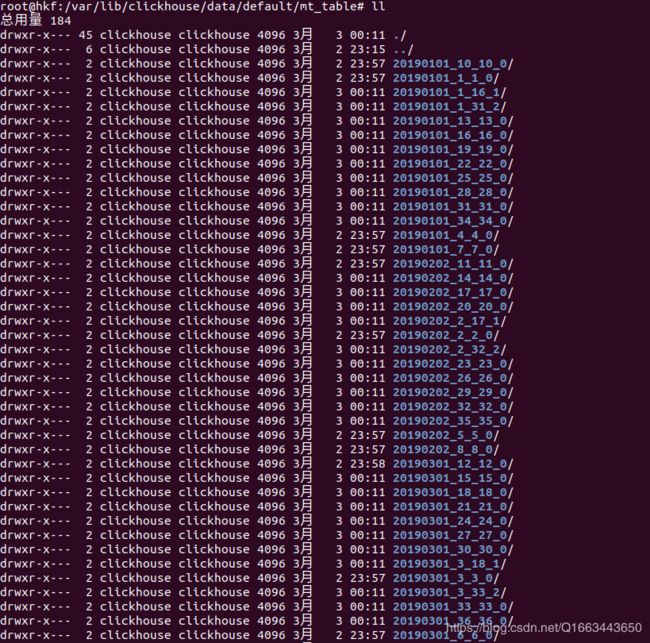
等待几分钟......
...
ok!经过几分钟等待后,变成如下结果:
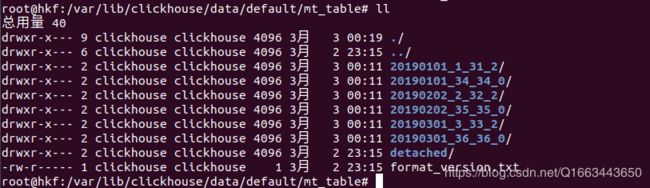
注意:可以使用以下命令进行手动触发,但是有可能出现错误,有时不会变化,有时文件数不仅不会减少反而会增加,而且在数据量特别大的时候会占用大量资源,因此实际使用中不建议这么做。
optimize table mt_table;下篇文章将介绍分布式表引擎Distributed。