DetectoRS论文解读
DetectoRS
- DetectoRS
- Introduce
- Recursive Feature Pyramid
- Feature Pyramid Networks
- Recursive Feature Pyramid
- backbone输入的不同
- RFP中的特征提取
- 特征融合模块
- Switchable Atrous Convolution
- Atrous Convolution
- Switchable Atrous Convolution
- Global Context
- Implementation Details
- 实验结果
DetectoRS: Detecting Objects with Recursive Feature Pyramid and Switchable Atrous Convolution
DetectoRS
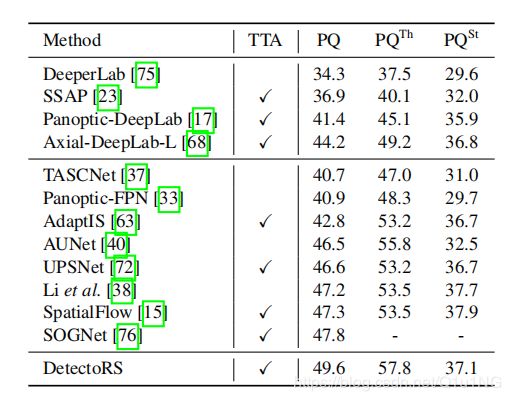
DetectoRS是谷歌团队提出的目标检测模型,论文中探讨了目标检测中looking and thinking twice的机制,在宏观上提出了递归特征金字塔RFN(Recursive Feature Pyramid),在微观上提出了可切换空洞卷积SAC(Switchable Atrous Convolution)。在COCO test-dev中取得了SOTA的结果,目标检测box mAP达到54.7,实例分割mask mAP达到47.1,全景分割PQ达到49.6。
Introduce
为了检测对象,人类视觉感知通过反馈连接传递高级语义信息,选择性地增强和抑制神经元的激活, 在人类视觉系统的启发下,looking and thinking twice的机制在计算机视觉领域得到实例化,并展示了卓越的性能。许多two-stage方法,比如Faster R-CNN,首先在特征图上进行候选区域提议,再对这些区域提取特征检测对象。沿着这个方向,Cascade R-CNN开发了一种 multi-stage检测器,通过多个检测器来不断的筛选和优化结果,论文中将这种级联的思想运用在backbone中,在宏观(RFN)与微观(SAC)两个方面部署该机制,以HTC作为baseline提出了DetectoRS,在具有相似inference time的情况下精度大大的提高。

Recursive Feature Pyramid
RFP是在FPN的基础上,反复的通过自下而上的backbone结构来丰富FPN的表征能力。

Feature Pyramid Networks
FPN提供了一条自上而下的路径来融合多个尺度特征图的特征,利用高层网络提取的语义信息和低层网络提取的细粒细节特征信息来预测多尺度的目标。


其中fS+1=0。
Recursive Feature Pyramid
论文中提出的递归特征金字塔(RFP)的思想就是添加反馈连接到FPN。
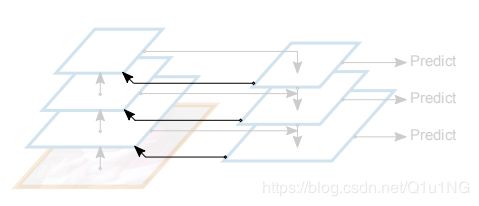
添加反馈连接之后的FPN公式如下,Ri表示反馈到backbone前的进一步特征提取操作。
![]()
![]()
其中fi0为0,并且Fit和Rit在不同步骤中是共享的。在实验中,默认情况下Bit在每个步骤中是不同的,且T=2。后面会有使用相同Bit和使用不同T的实验结果比较。

backbone输入的不同
为了方便RFP反馈的特征信息作为backbone中stage的输入,论文中对ResNet进行修改从而允许x与R(f)同时作为输入,ResNet通常有四个stage,每个stage包含几个相似结构的blocks,论文中只对每个stage中的第一个block进行修改:

RFP中的特征提取
论文中采用ASPP( Atrous Spatial Pyramid Pooling)结构来执行前面中提到的R模块,也就是图1当中的ASPP,在这个模块中有四个分支,其中三个分支为卷积层+ReLU,每个卷积层的输出通道都为input的1/4,最后一个分支是全局平均池化+1x1卷积层+ReLU,最后将其resize再与其他三个分支的输出进行concat操作。其中三个卷积分支的配置为:kernel_size[1,3,3],atrous rate[1,3,6],padding[0,3,6]。实验中有比较添加ASPP与没有添加的实验结果。(论文中没有给出该结构的图,笔者笔记本电脑上没有安装绘图软件,后续会补上结构图。)
特征融合模块
论文中的RFP还使用一个融合模块来组合fit和fit+1得到一个新的fit+1(也就是图1当中的Fusion操作),以更新方程(3)中使用的展开阶段t+1的fi值,也就是说将进行融合后的值将作为fit+1进行下一个步骤的计算。(比如说,如果不进行融合操作,按照公式(3),当需要求得fit+2时,就直接将得到的fit+1作为R模块的输入,进行R(fit+1)操作,但实际论文中是将fit和fit+1通过一个融合模块得到新的fit+1’,再将**fit+1’**作为R模块的输入,进行R(fit+1’)操作),融合模块的使用至少需要进行一次反馈连接之后,所以融合模块使用在步骤2到T中。
融合的方式为:对fit+1通过一个1x1卷积层和一个sigmoid操作,得到注意力掩码,在使用该掩码来计算fit和fit+1的加权和,得到一个新的fit+1。

Switchable Atrous Convolution

Atrous Convolution
空洞卷积是扩大滤波器在卷积层中的感受野的有效技术。空洞卷积将0添加在普通的卷积中间,等效地将k×k滤波器的核大小扩大到k=k(k-1)(r-1),而不增加参数的数量或计算量。同一种不同尺度的物体可以使用相同的卷积权值、设置不同的atrous rates来粗略的检测。
Switchable Atrous Convolution
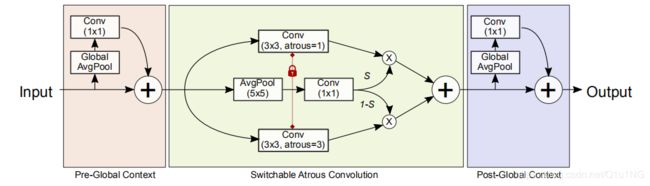
SAC模块有3个主要的组成部分:两个全局上下文模块和一个SAC组件,两个上下文模块分别添加在SAC组件的前后。这里先介绍SAC组件,使用y = Conv(x, w, r)表示权重为w,atrous rates为r,输入为x,y为输出的卷积操作,下图为普通卷积到SAC组件的转换:

Global Context
论文中在SAC组件的前后分别插入全局上下文模块,这里的全局上下文模块与SENet的相似,但是有两个不同:
- 只有一个卷积层,没有任何其他非线性层
- 全局上下文模块的输出是与主干路径相加,而不是经过sigmoid之后再相乘
在实验中,作者发现将全局上下文模块添加到SAC组件之前有积极效果,推测是因为全局的信息使得变换函数S(·) 的判断更加稳定, 然后,作者将其放置在主SAC组件之前和之后,以便Conv和S都可以从中受益。
Implementation Details
在实际的实施当中,作者采用可变形卷积Deformable Convolution 作为前面提到的方程(4)中的Conv操作, 它们的偏移函数不被共享,当从预先训练的backbone加载权重时,这些函数被初始化为预测0。在ResNet及其变体上添加SAC结构时,代替backbone中3x3卷积核,全局上下文模块的权重weights和偏差biases都初始化为0,S(·) 函数的权重weights初始化为0,偏差bias初始化为1,Δw初始化为0,以上初始化策略以确保在训练之前加载backbone预训练权重时,使用SAC结构代替backbone中的普通卷积,输出不会改变。
实验结果
以下为论文中的消融实验,HTC作为baseline,RFP + sharing表示Bi1和Bi2权重是分享的;RFP - aspp表示未使用ASPP结构;RFP - fusion表示未使用特征融合模块;RFP + 3X表示T=3,即展开之后递归三次,并得到一定的精度提升;SAC - DCN表示未使用可变形卷积(默认是使用DCN的);SAC - DCN - global表示未使用DCN和全局上下文信息模块;SAC - DCN - locking表示未使用DCN和锁定机制;SAC - DCN + DS (dual-switch)表示使用S1(x)和S2(x)代替方程(4)当中的S(x)与1-S(x);

下图从左至右分别为HTC,HTC+RFP,HTC+SAC,ground truth的结果,从这个比较中,可以注意到RFP,类似于人类的视觉感知,选择性地增强或抑制神经元的激活,能够更容易地找到被遮挡的物体, 由于SAC能够根据需要增加感受野,因此它更有能力检测图像中的大型物体:

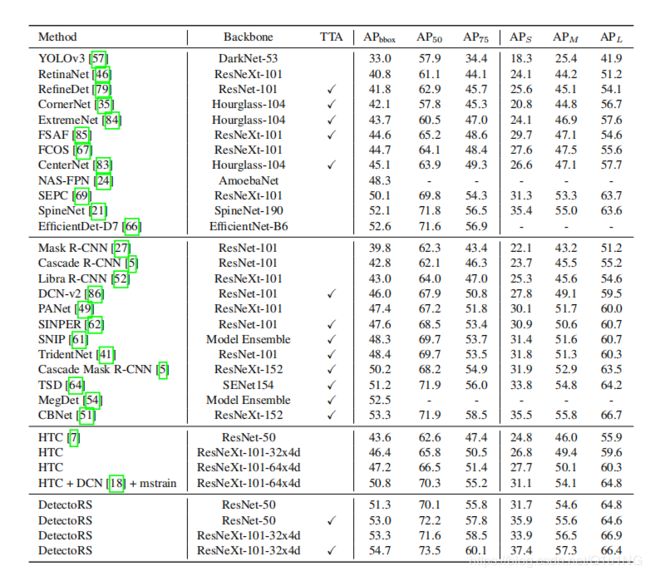
下图展示的是在COCO test-dev与一些具有良好效果的检测器的精度对比, TTA:测试时间增强,包括多尺度测试、水平翻转等。 没有TTA的DetectoRS的输入大小为(1333,800)。mstrain:多尺度训练。第一组为one-stage方法,第二组为multi-stage方法,第三组为HTC,第四组为DetectoRS,其中以ResNet50和ResNeXt-101-32x4d的 DetectoRS效果良好,达到了SOTA的结果。
下图为实例分割的结果对比,由于上图中的大部分模型没有给出实例分割的结果,论文中仅比较了HTC与DetectoRS的结果, 可以看到,与box的结果一致,DetectoRS在分割领域也带来了显著的改进。