先注册官网
官方接入文档
官方的github链接
我的github的demo链接
上图直观
国内在作翻译的也有很多,科大讯飞的语音技术也是很6的。这里由于需要,选用了微软的语音翻译技术,
在网上几乎找不到相关的博客有所介绍移动端的微软智能语音翻译
微软的智能语音还能将你的语音翻译成不同国家的语言的音频流,实现在线语音的翻译,这里数要做了在线翻译成不同语言文字的实现
官方的接入需求如下:
Implementation Notes
Connecting
Before connecting to the service, review the list of parameters given later in this section. An example request is:
GET wss://dev.microsofttranslator.com/speech/translate?from=en-US&to=it-IT&features=texttospeech&voice=it-IT-Elsa&api-version=1.0
Ocp-Apim-Subscription-Key: {subscription key}
X-ClientTraceId: {GUID}
The request specifies that spoken English will be streamed to the service and translated into Italian. Each final recognition result will generate a text-to-speech audio response with the female voice named Elsa. Notice that the request includes credentials in the Ocp-Apim-Subscription-Key header. The request also follows a best practice by setting a globally unique identifier in header X-ClientTraceId. A client application should log the trace ID so that it can be used to troubleshoot issues when they occur.
Sending audio
Once the connection is established, the client begins streaming audio to the service. The client sends audio in chunks. Each chunk is transmitted using a Websocket message of type Binary.
Audio input is in the Waveform Audio File Format (WAVE, or more commonly known as WAV due to its filename extension). The client application should stream single channel, signed 16bit PCM audio sampled at 16 kHz. The first set of bytes streamed by the client will include the WAV header. A 44-byte header for a single channel signed 16 bit PCM stream sampled at 16 kHz is:
Offset Value
0 - 3 "RIFF"
4 - 7 0
8 - 11 "WAVE"
12 - 15 "fmt "
16 - 19 16
20 - 21 1
22 - 23 1
24 - 27 16000
28 - 31 32000
32 - 33 2
34 - 35 16
36 - 39 "data"
40 - 43 0
Notice that the total file size (bytes 4-7) and the size of the "data" (bytes 40-43) are set to zero. This is OK for the streaming scenario where the total size is not necessarily known upfront.
After sending the WAV (RIFF) header, the client sends chunks of the audio data. The client will typically stream fixed size chunks representing a fixed duration (e.g. stream 100ms of audio at a time).
中文版 ,在线的翻译
语音翻译 :语音翻译的操作列表 显示隐藏 列表操作 展开操作
连接到服务之前,请查看本节后面给出的参数列表。示例请求是:
GET wss://dev.microsofttranslator.com/speech/translate?from=en-US&to=it-IT&features=texttospeech&voice=it-IT-Elsa&api-version=1.0
Ocp-Apim-Subscription-Key: {subscription key}
X-ClientTraceId: {GUID}
该要求规定,英语口语将被传送到服务,并翻译成意大利语。每个最终的识别结果都会产生一个名为Elsa的女性声音的文本到语音的响应。请注意,该请求在Ocp-Apim-Subscription-Key标题中包含凭据 。该请求也遵循最佳实践,通过在标题中设置全局唯一标识符X-ClientTraceId。客户端应用程序应该记录跟踪ID,以便在出现问题时可以使用它来解决问题。
发送音频
连接建立后,客户端开始将音频流式传输到服务。客户端以块的形式发送音频。每个块都使用Binary类型的Websocket消息来传输。
音频输入采用波形音频文件格式 (WAVE,由于文件扩展名,通常称为WAV)。客户端应用程序应该以16 kHz的频率对单声道,有符号16位PCM音频进行流式传输。客户端传输的第一组字节将包括WAV头。以16kHz采样的单信道带符号16位PCM流的44字节标题为:
抵消 值
0 - 3 “RIFF”
4 - 7 0
8 - 11 “波”
12 - 15 “fmt”
16 - 19 16
20 - 21 1
22 - 23 1
24 - 27 16000
28 - 31 32000
32 - 33 2
34 - 35 16
36 - 39 “数据”
40 - 43 0
请注意,总文件大小(字节4-7)和“数据”(字节40-43)的大小设置为零。对于总体大小未必事先知道的流式场景,这是可以的。
发送WAV(RIFF)头后,客户端发送音频数据块。客户端通常会传输代表固定持续时间的固定大小的块(例如,一次流100ms的音频)。
最后结果
最后的语音识别结果在话语的结尾处生成。使用Text类型的WebSocket消息将结果从服务传输到客户端。消息内容是具有以下属性的对象的JSON序列化:
type:字符串常量来标识结果的类型。该值为final最终结果。
id:分配给识别结果的字符串标识符。
recognition:源语言中的识别文本。在错误识别的情况下,文本可能是空字符串。
translation:以目标语言翻译的识别文本。
audioTimeOffset:蜱中识别开始的时间偏移(1滴答= 100纳秒)。偏移是相对于流的开始。
audioTimeSize:识别的持续时间(100纳秒)。
audioStreamPosition:识别开始的字节偏移量。偏移是相对于流的开始。
audioSizeBytes:识别的字节大小。
接入 的时候,官方的链接大多是C#的,有一个java代码,也是纯java代码,没有移动端的,所以只能看文档了;
文档要求使用websocket链接
The application has dependency on following external libraries, which are configured in pom.xml
[Jetty] (http://www.eclipse.org/jetty/) For lightweight websocket client api
[GSON] (https://github.com/google/gson) For deserializing json response
这里采用了直接使用的websocket的包实现的链接。按照API文档
Use the subscription key to authenticate. Microsoft Translator Speech API supports two modes of authentication:
Using an access token. In your application, obtain an access token from the token service. Use your Microsoft Translator Speech API subscription key to obtain an acess token from the Cognitive Services authentication service. The acces token is valid for 10 minutes. Obtain a new acces token every 10 minutes, and keep using the same access token for repeated requests within these 10 minutes.
Using a subscription key directly. In your application, pass your subscription key as a value in Ocp-Apim-Subscription-Key header.
两种方式选者一种完成,我们选者后者,在websocket的header里添加key
Map header =new HashMap();
header.put("Ocp-Apim-Subscription-Key","d6c3bc8fe5a94bac9db92a58efdd0856");
webSocketWorker=new SocketUtils(uri,new Draft_17(),header,10000);
如上所示
连接websocket成功以后,就按API要求,拼接出wav的Header,代码如下:
/*
任何一种文件在头部添加相应的头文件才能够确定的表示这种文件的格式,wave是RIFF文件结构,每一部分为一个chunk,其中有RIFF WAVE chunk,
FMT Chunk,Fact chunk,Data chunk,其中Fact chunk是可以选择的,
*/
private byte[] WriteWaveFileHeader() {
byte[] header = new byte[44];
long longSampleRate=16000;
long byteRate=32000;
header[0] = 'R'; // RIFF
header[1] = 'I';
header[2] = 'F';
header[3] = 'F';
header[4] = 0;//数据大小
header[5] = 0;
header[6] = 0;
header[7] = 0;
header[8] = 'W';//WAVE
header[9] = 'A';
header[10] = 'V';
header[11] = 'E';
//FMT Chunk
header[12] = 'f'; // 'fmt '
header[13] = 'm';
header[14] = 't';
header[15] = ' ';//过渡字节
//数据大小
header[16] = (byte) (16 & 0xff); // 4 bytes: size of 'fmt ' chunk
header[17] = 0;
header[18] = 0;
header[19] = 0;
//编码方式 10H为PCM编码格式
header[20] = 1; // format = 1
header[21] = 0;
//通道数
header[22] = 1;
header[23] = 0;
//采样率,每个通道的播放速度
header[24] = (byte) (longSampleRate & 0xff);
header[25] = (byte) ((longSampleRate >> 8) & 0xff);
header[26] = (byte) ((longSampleRate >> 16) & 0xff);
header[27] = (byte) ((longSampleRate >> 24) & 0xff);
//音频数据传送速率,采样率*通道数*采样深度/8
header[28] = (byte) (byteRate & 0xff);
header[29] = (byte) ((byteRate >> 8) & 0xff);
header[30] = (byte) ((byteRate >> 16) & 0xff);
header[31] = (byte) ((byteRate >> 24) & 0xff);
// 确定系统一次要处理多少个这样字节的数据,确定缓冲区,通道数*采样位数
header[32] = (byte)(2&0xff);
header[33] = 0;
//每个样本的数据位数
header[34] = (byte) (16 & 0xff);
header[35] = 0;
//Data chunk
header[36] = 'd';//data
header[37] = 'a';
header[38] = 't';
header[39] = 'a';
header[40] = 0;
header[41] = 0;
header[42] = 0;
header[43] = 0;
return header;
}
有关wav的相关,可以百度,android采用的是AudioRecord录制音频
初始化相关数据
recorder = new AudioRecord(audioSource,audioRate,audioChannel,audioFormat,bufferSize);
得到相关的对象,接下来就是操作
当创建好了 AudioRecord 对象之后,就可以开始进行音频数据的采集了,通过下面两个函数控制采集的开始/停止:
AudioRecord.startRecording();
AudioRecord.stop();
调用的读取数据的接口是:
AudioRecord.read(byte[] audioData, int offsetInBytes, int sizeInBytes);
相关的一些配置要观看微软提供的API文档,在demo里都配置好了
如下配置是重点
Once the connection is established, the client begins streaming audio to the service. The client sends audio in chunks. Each chunk is transmitted using a Websocket message of type Binary.
Audio input is in the Waveform Audio File Format (WAVE, or more commonly known as WAV due to its filename extension). The client application should stream single channel, signed 16bit PCM audio sampled at 16 kHz. The first set of bytes streamed by the client will include the WAV header. A 44-byte header for a single channel signed 16 bit PCM stream sampled at 16 kHz is:
Offset Value
0 - 3 "RIFF"
4 - 7 0
8 - 11 "WAVE"
12 - 15 "fmt "
16 - 19 16
20 - 21 1
22 - 23 1
24 - 27 16000
28 - 31 32000
32 - 33 2
34 - 35 16
36 - 39 "data"
40 - 43 0
Notice that the total file size (bytes 4-7) and the size of the "data" (bytes 40-43) are set to zero. This is OK for the streaming scenario where the total size is not necessarily known upfront.
After sending the WAV (RIFF) header, the client sends chunks of the audio data. The client will typically stream fixed size chunks representing a fixed duration (e.g. stream 100ms of audio at a time).
详情可以看demo里
如下方法里是获取到的缓存的音频audioData
AudioRecord.read(byte[] audioData, int offsetInBytes, int sizeInBytes);
回到开头,我们说了建立了websocket连接,发送了wav的头文件,按照API格式发送过去了的,现在就只需要发送 音频audioData
发送音频audioData到websocket,在我们websocket消息回调里就能看到回调
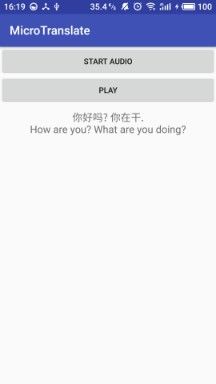
这是我的语音翻译的回调。一旦你对着麦克风说话,就能获得回调
{"type":"final","id":"1","recognition":"你好吗? 你在干.","translation":"How are you? What are you doing?"}