机器学习 -- 总结 (概述 SVM 决策树 聚类算法 集成学习)
一、机器学习概述
1. 什么是机器学习?
机器学习是从人工智能中产生的一个重要学科分支,是实现智能化的关键。
经典定义:利用经验改善系统自身的性能。
研究内容:在计算机上从数据中产生“模型”,用于对新的情况给出判断。
2. 机器学习的流程
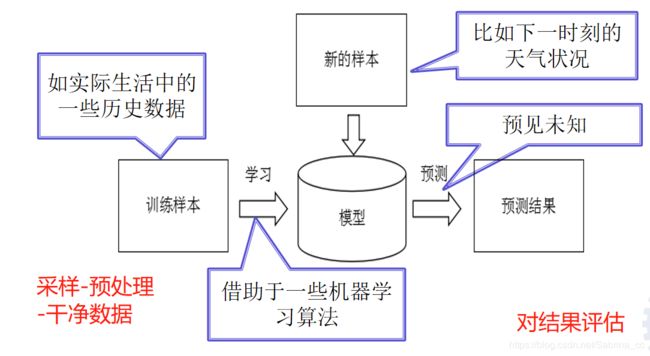
3. 机器学习的目标
使得学到的模型能很好的适用于“新样本”,而不仅仅是训练集合,我们称模型适用于新样本的能力为泛化(generalization)能力。
(训练数据 + 未知数据 表现都好)
过拟合:训练数据误差低(机器学习学的太好了,达到100%),但是预测效果却很差。(决策树方法会出现的情况)
欠拟合:训练效果不太好,但是对于未知数据效果比较好。
(参考链接:https://blog.csdn.net/Sabrina_cc/article/details/105736856)
二、支持向量机SVM
支持向量机(support vector machines. SVM) 二类分类模型.
它的基本模型是定义在特征空间上的间隔最大的线性分类器; 支持向量机还包括核技巧,这使它成为实质上的非线性分类器. 支持向量机的学习策略就是间隔最大化,可形式化为一个求解凸二次规划(convex quadratic programming)的问题,也等价于正则化的合页损失函数的最小化问题.支持向量机的学习算法是求解凸二次规划的最优化算法.
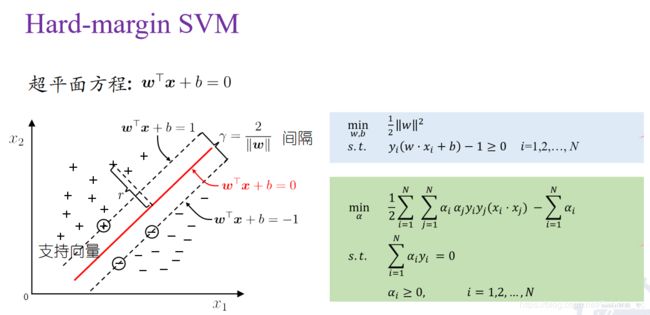
(硬间隔SVM:https://blog.csdn.net/Sabrina_cc/article/details/105727926)
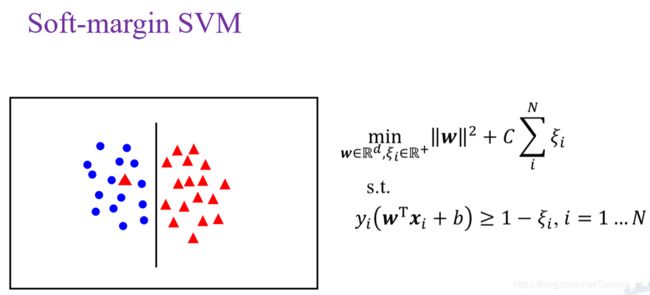
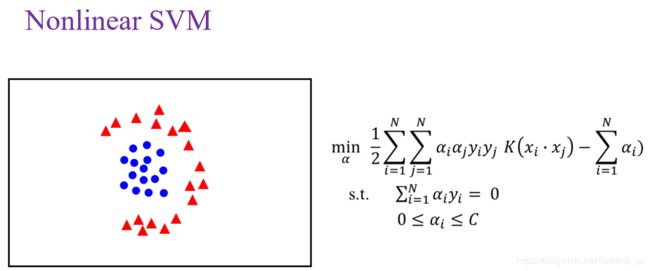
(软间隔SVM和非线性SVM:https://blog.csdn.net/Sabrina_cc/article/details/105736027)
三、决策树
决策树通过把数据样本分配到某个叶子结点来确定数据集中样本所属的分类
决策树由决策结点、有向边和叶子结点组成
决策结点表示在样本的一个属性上进行的划分
有向边表示对于决策结点进行划分的输出
叶结点代表经过分支到达的类
从决策树根结点出发,自顶向下移动,在每个决策结点都会进行次划分,通过划分的结果将样本进行分类,导致不同的分支,最后到达个叶子结点,这个过程就是利用决策树进行分类的过程
决策树的3个步骤: 如何确定每个分支节点,即选择特征 如何建立决策树,即决策树的生成 如何避免过拟合,即决策树的剪枝
(参考链接:https://blog.csdn.net/Sabrina_cc/article/details/105862120)
(参考链接:https://www.cnblogs.com/gfgwxw/p/9439482.html)
四、无监督学习之聚类算法
在无监督学习(unsupervised learning)中,训练样本的标记信息是未知的,目标是通过对无标记训练样本的学习来揭示数据的内在性质及规律,为进一步的数据分析提供基础。
聚类:K-means, 层次聚类,密度聚类
降维:PCA
聚类主要用于数据分析,也可以用于监督学习的预处理。聚类有助于发现数据的统计规律。
聚类是针对给定的样本,依据它们特征的相似度或距离,将其归并到若干个“类”或“簇”的数据分析问题。
聚类的目的是得到较高的簇内相似度和较低的簇间相似度,使得簇间的距离尽可能大,簇内样本与簇中心的距离尽可能小
聚类属于无监督学习,因为只是根据样本的相似度或距离将其进行归类,而类或簇事先并不知道。
聚类得到的簇可以用聚类中心、簇大小、簇密度等来表示
聚类中心是一个簇中所有样本点的均值(质心), K均值聚类
簇大小表示簇中所含样本的数量,层次聚类
簇密度表示簇中样本点的紧密程度,密度聚类
(参考链接:https://blog.csdn.net/Sabrina_cc/article/details/106000727)
五、集成学习
集成学习(Ensemble learning)是机器学习中近年来的一大热门领域。其中的集成方法是用多种学习方法的组合来获取比原方法更优的结果
使用于组合的算法是弱学习算法,即分类正确率仅比随机猜测略高的学习算法,但是组合之后的效果仍可能高于强学习算法,即集成之后的算法准确率和效率都很高
(参考链接:https://blog.csdn.net/Sabrina_cc/article/details/106093807)