Python数据挖掘学习笔记(7)频繁模式挖掘算法----FP-growth
一、相关原理
FP-Growth算法是韩嘉炜等人在2000年提出的关联分析算法,它采取如下分治策略:将提供频繁项集的数据库压缩到一棵频繁模式树(FP-tree),但仍保留项集关联信息。在算法中使用了一种称为频繁模式树(Frequent Pattern Tree)的数据结构。FP-tree是一种特殊的前缀树,由频繁项头表和项前缀树构成。FP-Growth算法基于以上的结构加快整个挖掘过程。
FP-growth算法只需要对数据库进行了两次扫描,而Apriori算法对于每个潜在的频繁项集都会扫描数据集判定给定模式是否频繁,因此FP-growth算法的速度要比Apriori算法快。在小规模数据集上,这不是什么问题,但是当处理大规模数据集时,就会产生很大的区别。大致流程如下图:
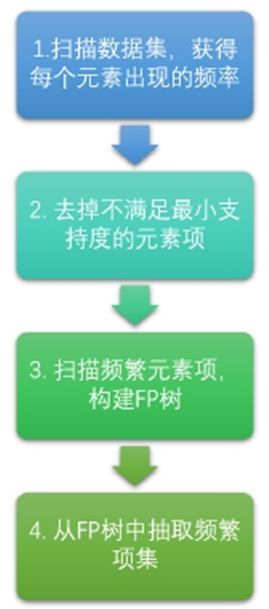
关于FP-growth算法需要注意的两点是:
(1)该算法采用了与Apriori完全不同的方法来发现频繁项集
(2)该算法虽然能更为高效地发现频繁项集,但不能用于发现关联规则。
从FP-growth算法挖掘频繁项集这个流程图中可以看出,FP-growth算法主要有两个步骤,即构建FP树以及从FP树中挖掘频繁项集。
其他相关原理可查看相关文章,推荐机器学习实战一书。
二、编写代码
1、数据初始化方法:
#创建数据集
def loadSimpDat():
simpDat = [['r', 'z', 'h', 'j', 'p'],
['z', 'y', 'x', 'w', 'v', 'u', 't', 's'],
['z'],
['r', 'x', 'n', 'o', 's'],
['y', 'r', 'x', 'z', 'q', 't', 'p'],
['y', 'z', 'x', 'e', 'q', 's', 't', 'm']]
return simpDat
#数据格式化
def createInitSet(dataSet):
retDict = {}
for trans in dataSet:
#print(trans)
fset = frozenset(trans)
#print(fset)
retDict.setdefault(fset, 0) #返回指定键的值,如果没有则添加一个键
#print(retDict)
retDict[fset] += 1
#print(retDict)
return retDict2、FP的数据结构类:
#FP树的数据结构类
class treeNode:
def __init__(self, nameValue, numOccur, parentNode):
self.name = nameValue #名字变量
self.count = numOccur #计数变量(频率)
self.nodeLink = None #链接相似元素项
self.parent = parentNode #当前父节点
self.children = {} #用于存放子节点
def inc(self, numOccur): #对count变量增加给定值
self.count += numOccur
def disp(self, ind=1): #将树以文本形式显示,主要是方便调试。
print(' '*ind, self.name, ' ', self.count)
for child in self.children.values():
child.disp(ind+1) #子节点向右缩减3、创建FP树的相关方法:
#更新头指针表
def updateHeader(nodeToTest, targetNode):
while (nodeToTest.nodeLink != None):
nodeToTest = nodeToTest.nodeLink
nodeToTest.nodeLink = targetNode
#FP树的生长函数
def updateTree(items, myTree, headerTable, count):
if items[0] in myTree.children:
myTree.children[items[0]].inc(count)
else:
myTree.children[items[0]] = treeNode(items[0], count, myTree)
if headerTable[items[0]][1] == None:
headerTable[items[0]][1] = myTree.children[items[0]]
else:
updateHeader(headerTable[items[0]][1], myTree.children[items[0]])
if len(items) > 1:
updateTree(items[1:], myTree.children[items[0]], headerTable, count)
#创建FP树,默认最小支持度为1,将根据支持度对数据进行第一次过滤
def createTree(dataSet, minSup=1):
headerTable = {}
#第一次遍历数据集, 记录每个数据项的支持度
for trans in dataSet:
for item in trans:
headerTable[item] = headerTable.get(item, 0) + 1
#根据最小支持度过滤
lessThanMinsup = list(filter(lambda k:headerTable[k] < minSup, headerTable.keys()))
for k in lessThanMinsup:
del(headerTable[k])
freqItemSet = set(headerTable.keys())
#如果所有数据都不满足最小支持度,返回None, None
if len(freqItemSet) == 0:
return None, None
for k in headerTable:
headerTable[k] = [headerTable[k], None]
myTree = treeNode('φ', 1, None)
#第二次遍历数据集,构建fp-tree
for tranSet, count in dataSet.items():
#根据最小支持度处理一条训练样本,key:样本中的一个样例,value:该样例的的全局支持度
localD = {}
for item in tranSet:
if item in freqItemSet:
localD[item] = headerTable[item][0]
if len(localD) > 0:
#根据全局频繁项对每个事务中的数据进行排序,等价于 order by p[1] desc, p[0] desc
orderedItems = [v[0] for v in sorted(localD.items(), key=lambda p:(p[1],p[0]), reverse=True)]
updateTree(orderedItems, myTree, headerTable, count)
return myTree, headerTable4、从FP树中获得条件模式基
#迭代上溯整棵树
def ascendTree(leafNode, prefixPath):
if leafNode.parent != None:
prefixPath.append(leafNode.name)
ascendTree(leafNode.parent, prefixPath)
#遍历链表
def findPrefixPath(basePat, headerTable):
condPats = {}
treeNode = headerTable[basePat][1]
while treeNode != None:
prefixPath = []
ascendTree(treeNode, prefixPath)
if len(prefixPath) > 1:
condPats[frozenset(prefixPath[1:])] = treeNode.count
treeNode = treeNode.nodeLink
return condPats5、创造条件FP树
def mineTree(inTree, headerTable, minSup=1, preFix=set([]), freqItemList=[]):
#排序minSup asc, value asc
bigL = [v[0] for v in sorted(headerTable.items(), key=lambda p: (p[1][0],p[0]))]
for basePat in bigL:
newFreqSet = preFix.copy()
newFreqSet.add(basePat)
freqItemList.append(newFreqSet)
# 通过条件模式基找到的频繁项集
condPattBases = findPrefixPath(basePat, headerTable)
myCondTree, myHead = createTree(condPattBases, minSup)
if myHead != None:
print('condPattBases: ', basePat, condPattBases)
myCondTree.disp()
print('*' * 30)
mineTree(myCondTree, myHead, minSup, newFreqSet, freqItemList)6、运行:
#初始化数据集
simpDat = loadSimpDat()
dictDat = createInitSet(simpDat)
freqItems=[] #存储频繁项集
#创建FP树,支持度设为3
myFPTree,myheader = createTree(dictDat, 3)
#创建条件FP树,支持度设为2
mineTree(myFPTree, myheader, 2 ,set([]),freqItems)
print('频繁项集为'+str(freqItems))7、运行结果:

condPattBases:XXXX是频繁项的前缀路径,下面的是条件FP树。
三、参考资料
1、Harrington P , 李锐等. 机器学习实战[M]. 人民邮电出版社, 2013.
2、https://www.bilibili.com/video/av40754697 (推荐购买完整版)
3、https://blog.csdn.net/dq_dm/article/details/38111097