动态加载页面分析、POST请求参数和内容爬取
要求:
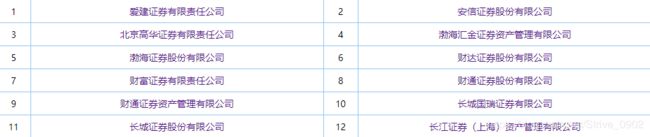
爬取网站:http://jg.sac.net.cn/pages/publicity/securities-list.html# 中的所有公司的page_url下面的公司名,注册地址、法人代表等信息。
该网站与之前网站不同的是:是动态加载的,不能使用requests请求获得列表页的信息及每一个公司的url。因此这里是使用post方法,获取到列表页面的信息。
包括模块:
- 列表页和新闻页动态加载情况分析
- 关于列表页和新闻页的headers 和 data 信息的区别
- requests.post的使用方法
- 把公司名,注册地址、法人代表等存为json格式的文件
- 再将json格式的文件转化成CSV格式的文件
完成结果:

步骤:
1.1 列表页动态加载情况分析
![]()
可以看出来,在列表页中,公司名称对应的a标签下面的href显示只有一个#,此外,公司名称在查看源码时是不存在的,因此,不能使用需求给的网址进行爬取,属于动态加载的情况。
然后将网页刷新完,在Network字段下的XHR可以看出,响应信息为:
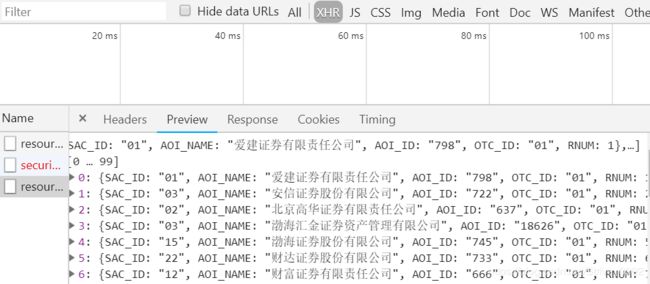
可以看出,图中有公司名称及ID号,经过观察发现page_url和上面响应得到的AOI_ID号是相同的。因此,我们要想办法得到上面的公司名称和对应的ID号。
1.2 新闻页动态加载情况分析

从新闻页的加载情况可以看出,该页面也是POST请求,因此,也没有办法使用获取到的上面的page_url对页面进行requests请求。
2 关于列表页和新闻页的headers 和 data 信息的区别
因为列表页和新闻页都是动态加载的,需要使用requests.post()的方法来获取;
2.1 下面是列表页POST请求的参数的详情页面:
网址信息:

POST的data信息:

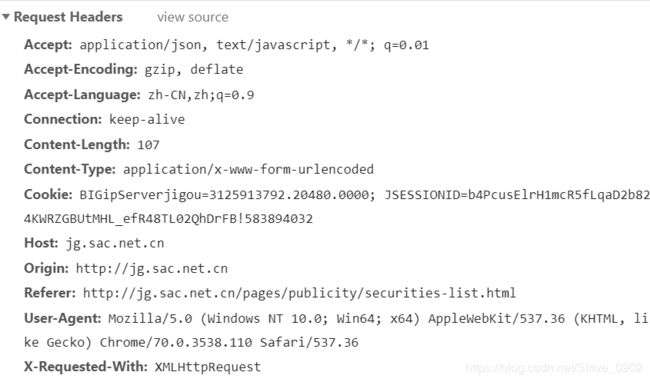
POST的headers信息:但是headers信息不是全部都要的,我们只需要获取cookie信息,Host信息及User-Agent信息就可以
2.2下面是新闻页POST请求的参数的详情页面:
POST的data信息:
通过观察发现,新闻页面下的所有信息不全是在一个POST请求返回的响应,而是进行了两个POST请求,每个POST请求都有自己的网址,data和headers信息,经过观察发现,其他都是一致的,只有data信息不一致,也就是说,在新闻页必须进行两次POST请求,才能获得所有的响应信息。情况如下:


3 requests.post的使用方法
经过2的分析结合编程实验发现:
- requests.post(url,data,headers):总共有三个参数
- 列表页和新闻页在requests.post公用 headers 和 url,不同的是data;
- 在列表页,data是一个,需要进行一次post请求;在新闻页,data分为两个部分,需要进行两次post请求。
4 把公司名,注册地址、法人代表等存为json格式的文件
这个就跟前一篇博客的方法相同了,就是定义一个字典,把新闻页中每个需要的字段添加进去,然后利用json.dumps()把它保存为json文件。实验得到的json文件格式为:
{"Chinese_Name": "爱建证券有限责任公司", "Info_Reg": "上海市世纪大道1600号32楼", "Legal_Represent": "祝健", "License_Code": "13210000", "Reg_Capital": "110000", "Office_Address": "上海市世纪大道1600号32楼", "Office_Post_Code": "200122", "Com_Website": "http://www.ajzq.com/", "Customer_Service_Tel": "4001962502", "Qualification_info": "网上交易,中国证券登记结算公司乙类结算参与人,与证券交易、证券投资活动有关的财务顾问,证券承销与保荐,报价转让,代办股份转让,自营业务开展股指期货交易资格,交易所固定收益平台做市商,全国银行间拆借市场成员,代销金融产品,银行间市场利率互换,权证交易,公开市场交易商,证券业务外汇经营许可证(外币有价证券经纪业务、外币有价证券承销业务、受托外汇\n\n资产管理业务),资产管理业务开展国债期货交易资格,工商营业执照副本,融资融券,证券投资基金代销,证券经纪,证券投资咨询,受托理财,自营业务开展股指国债期货交易资格,证券自营,证券资产管理,资产管理业务开展股指期货交易资格,"}
{"Chinese_Name": "安信证券股份有限公司", "Info_Reg": "深圳市福田区金田路4018号安联大厦35层、28层A02单元", "Legal_Represent": "王连志", "License_Code": "91440300792573957K", "Reg_Capital": "700,000", "Office_Address": "深圳市福田区金田路4018号安联大厦35层", "Office_Post_Code": "518026", "Com_Website": "http://www.essence.com.cn", "Customer_Service_Tel": "4008001001", "Qualification_info": "与证券交易、证券投资活动有关的财务顾问,融资融券,柜台交易业务试点资格,银行间债券市场做市商,资产管理业务开展股指期货交易资格,证券投资基金代销,中小企业私募债券承销业务,其他,记账式国债承销团成员,证券业务外汇经营许可证(外币有价证券经纪业务、外币有价证券承销业务、受托外汇\n\n资产管理业务),政策性银行承销商资格,受托管理保险资金资格,证券投资咨询,证券资产管理,网上交易,直接投资业务,股票收益互换业务试点资格,中国证券登记结算公司乙类结算参与人,自营业务开展股指期货交易资格,其他,代销金融产品,受托理财,其他,工商营业执照副本,证券承销与保荐,为期货公司提供中间介绍业务,合格境内机构投资者从事境外证券投资管理业务(QDII),全国银行间拆借市场成员,约定购回式证券交易资格,报价转让,自营业务开展股指国债期货交易资格,转融通业务试点资格,证券经纪,代办股份转让,证券自营,证券投资基金托管,"}
{"Chinese_Name": "北京高华证券有限责任公司", "Info_Reg": "北京市西城区金融大街7号北京英蓝国际中心18层1801-1806室、1826-1832室", "Legal_Represent": "章星", "License_Code": "Z32411000", "Reg_Capital": "107200", "Office_Address": "北京市西城区金融大街7号英蓝国际中心18层1801-1806室、1826-1832室", "Office_Post_Code": "100033", "Com_Website": "http://www.ghsl.cn", "Customer_Service_Tel": "4006508356", "Qualification_info": "证券投资咨询,工商营业执照副本,证券资产管理,证券经纪,代销金融产品,与证券交易、证券投资活动有关的财务顾问,证券自营,"}
{"Chinese_Name": "渤海汇金证券资产管理有限公司", "Info_Reg": "深圳市前海深港合作区前湾一路1号A栋 201室(入驻深圳市前海商务秘书有限公司)", "Legal_Represent": "徐海军", "License_Code": "91440300MA5DCWOF32", "Reg_Capital": "110000", "Office_Address": "深圳市南山区海岸大厦西座2901、2913号", "Office_Post_Code": "518054", "Com_Website": "http://www.bhhjamc.com/", "Customer_Service_Tel": "400-651-1717", "Qualification_info": ""}
{"Chinese_Name": "渤海证券股份有限公司", "Info_Reg": "天津经济技术开发区第二大街42号写字楼101室", "Legal_Represent": "王春峰", "License_Code": "10040000", "Reg_Capital": "803719.4486", "Office_Address": "天津市南开区宾水西道8号", "Office_Post_Code": "300381", "Com_Website": "http://www.ewww.com.cn", "Customer_Service_Tel": "400-651-5988", "Qualification_info": "自营业务开展股指国债期货交易资格,证券自营,代销金融产品,约定购回式证券交易资格,报价转让,柜台交易业务试点资格,代办股份转让,全国银行间拆借市场成员,证券业务外汇经营许可证(外币有价证券经纪业务、外币有价证券承销业务、受托外汇\n\n资产管理业务),工商营业执照副本,短期融资券承销,中国证券登记结算公司乙类结算参与人,自营业务开展股指期货交易资格,转融通业务试点资格,证券投资咨询,证券承销与保荐,证券经纪,证券投资基金代销,直接投资业务,其他,网上交易,与证券交易、证券投资活动有关的财务顾问,融资融券,银行间市场利率互换,中小企业私募债券承销业务,"}
5 再将json格式的文件转化成CSV格式的文件
这个步骤跟前一篇博客的也是相同的,代码实现也就四五行:
# -*- coding: utf-8 -*-
import csv
import json
import sys
import collections # 有序字典
import pandas as pd
inp = []
with open("2.json", "r", encoding="utf-8") as f:
line = f.readlines() # list 每个元素为字符串
for i in line:
inp.append(eval(i)) # 必须为字典才行
print(inp)
pd.DataFrame(inp).to_csv('res.csv')
实现代码:
import requests
from lxml import etree
import time
import os
import sys
import json
ua = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.135 Safari/537.36 Edge/12.10240"
cookie1 = "trs_uv=jtz38ebv_373_14pv; BIGipServerjigou=1079027904.20480.0000; JSESSIONID=gyDbm3t9JVAlnN7VBkEH7Gk9CrEcAsd65-YfiCCqMLv-IkyP53TY!499435313"
host1 = "jg.sac.net.cn"
orgin1 = "http://jg.sac.net.cn"
data1 = {"filter_EQS_O#otc_id":"01","filter_EQS_O#sac_id":"","filter_LIKES_aoi_name":"","sqlkey": "publicity","sqlval": "ORG_BY_TYPE_INFO"}
headers1 = {'User-agent': ua,'Cookie':cookie1,'Host':host1,'Orgin':orgin1}
Base_url = "http://jg.sac.net.cn/pages/publicity/resource!search.action"
page_url = "http://jg.sac.net.cn/pages/publicity/resource!search.action"
req = requests.post(Base_url,data = data1, headers=headers1)
print(req.text)
res = req.json()
#print(res[0]['AOI_ID'])
for i in range(len(res)):
page_data1 = {"filter_EQS_aoi_id": res[i]['AOI_ID'], "sqlkey": "publicity", "sqlval": "SELECT_ZQ_REG_INFO"}
page_data2 = {"filter_EQS_aoi_id": res[i]['AOI_ID'], "sqlkey": "publicity", "sqlval": "SEARCH_ZQGS_QUALIFATION"}
company_info = {}
page_req1 = requests.post(page_url, data=page_data1, headers=headers1).json()
page_req2 = requests.post(page_url, data=page_data2, headers=headers1).json()
company_info["Chinese_Name"] = page_req1[0]['MRI_CHINESE_NAME']
company_info["Info_Reg"] = page_req1[0]['MRI_INFO_REG']
company_info["Legal_Represent"] = page_req1[0]['MRI_LEGAL_REPRESENTATIVE']
company_info["License_Code"] = page_req1[0]['MRI_LICENSE_CODE']
company_info["Reg_Capital"] = page_req1[0]['MRI_REG_CAPITAL']
company_info["Office_Address"] = page_req1[0]['MRI_OFFICE_ADDRESS']
company_info["Office_Post_Code"] = page_req1[0]['MRI_OFFICE_ZIP_CODE']
company_info["Com_Website"] = page_req1[0]['MRI_COM_WEBSITE']
company_info["Customer_Service_Tel"] = page_req1[0]['MRI_CUSTOMER_SERVICE_TEL']
# print(page_req2)
# exit()
con = ""
for j in range(len(page_req2)):
con += page_req2[j]['PTSC_NAME']+","
company_info["Qualification_info"] = con
try:
with open("2.json", 'a+', encoding="utf-8") as fp:
fp.write(json.dumps(company_info, ensure_ascii=False) + "\n")
except IOError as err:
print('error' + str(err))
finally:
fp.close()
pass