python-opencv的学习 环境搭建 基本案例
python-opencv的学习 环境搭建 基本案例
题目:
背景:在生产汽车轮胎中,会有各种各样的缺陷需要人工检测,现用图像算法代替人工进 行检测。
1根据给出的正常轮胎及有缺陷的轮胎图片识别出轮胎的胎侧缺胶的缺陷类型,并在所给图片中定位缺陷(可用一个矩形框框出)
解决过程
环境搭建
pip install opencv-python
(pip install opencv-contrib-python 【扩展模块】,pip install pytesseract)
什么是opencv(open computer view)
OpenCV是一个基于BSD许可(开源)发行的跨平台计算机视觉库,可以运行在Linux、Windows、Android和Mac OS操作系统上。它轻量级而且高效——由一系列 C 函数和少量 C++ 类构成,同时提供了Python、Ruby、MATLAB等语言的接口,实现了图像处理和计算机视觉方面的很多通用算法。
安装和配置opencv(mac)
#下载cmake ''' CMake是一个跨平台的安装(编译)工具,可以用简单的语句来描述所有平台的安装(编译过程)。他能够输出各种各样的makefile或者project文件,能测试编译器所支持的C++特性,类似UNIX下的automake。 ''' brew insatl cmake #获取opencv源代码 git clone https://github.com/opencv/opencv.git git clone https://github.com/opencv/opencv_contrib.git #构建opencv #在源码目录中创建一个临时目录,这里会存放一下cmake编译生成的文件 cd~ / opencv mkdir build #配置 cd build cmake -D CMAKE_BUILD_TYPE=RELEASE -D CMAKE_INSTALL_PREFIX=/usr/local .. #构建安装 make -j6#并行运行6个作业 sudo make installmanblue@appledeMBP ~ % pip install opencv-python Looking in indexes: http://pypi.douban.com/simple/ Collecting opencv-python Downloading http://pypi.doubanio.com/packages/7c/0b/df5987ee6671eb7645d990b70832780daf0ece89469af0a792d8dcbcfe62/opencv_python-4.2.0.34-cp37-cp37m-macosx_10_9_x86_64.whl (49.1 MB) |████████████████████████████████| 49.1 MB 3.4 MB/s Requirement already satisfied: numpy>=1.14.5 in /usr/local/lib/python3.7/site-packages (from opencv-python) (1.18.2) Installing collected packages: opencv-python Successfully installed opencv-python-4.2.0.34 manblue@appledeMBP ~ % pip install opencv-contrib-python Looking in indexes: http://pypi.douban.com/simple/ Collecting opencv-contrib-python Downloading http://pypi.doubanio.com/packages/ee/9a/ce4d349af0648bb4d98fbb24959b1bd91a2b79e6903d8f25f23ab33a3e2e/opencv_contrib_python-4.2.0.34-cp37-cp37m-macosx_10_9_x86_64.whl (60.3 MB) |████████████████████████████████| 60.3 MB 352 kB/s Requirement already satisfied: numpy>=1.14.5 in /usr/local/lib/python3.7/site-packages (from opencv-contrib-python) (1.18.2) Installing collected packages: opencv-contrib-python Successfully installed opencv-contrib-python-4.2.0.34 manblue@appledeMBP ~ % pip install pytesseract Looking in indexes: http://pypi.douban.com/simple/ Collecting pytesseract Downloading http://pypi.doubanio.com/packages/3c/1d/2993a05adb253902a372d7886733ae7688615cf000c54fe3c075892cb5d4/pytesseract-0.3.3.tar.gz (13 kB) Collecting Pillow Downloading http://pypi.doubanio.com/packages/43/0e/db0117d3c810cc5c5d04802988be8983f4f51a78ae65d53bddcff68bf692/Pillow-7.1.1-cp37-cp37m-macosx_10_10_x86_64.whl (2.2 MB) |████████████████████████████████| 2.2 MB 43 kB/s Building wheels for collected packages: pytesseract Building wheel for pytesseract (setup.py) ... done Created wheel for pytesseract: filename=pytesseract-0.3.3-py2.py3-none-any.whl size=13399 sha256=3434014f14281e70903194b4aa9ab5b0c71b2d0c8bfad16e6665247dffd8be31 Stored in directory: /Users/manblue/Library/Caches/pip/wheels/82/94/6b/d92b5802d82860e110c9d757c5c5bb6658cb9aa8268e415c7c Successfully built pytesseract Installing collected packages: Pillow, pytesseract Successfully installed Pillow-7.1.1 pytesseract-0.3.3
##知识点学习:python-opencv学习
图像的读取 展示
img=cv2.imread('image/lenacolor.png',cv2.IMREAD_UNCHANGED) ''' 原图展示 cv2.IMREAD_UNCHANGED 灰度图展示 cv2.IMREAD_GRAYSCALE 彩色图展示 cv2.IMREAD_COLOR ''' #2、图片保存 cv2.imwrite('image/gray_test.jpg',img) #3、图片展示 cv2.imshow('original',img) #4、图片暂停展示 cv2.waitKey(num)视频展示
import cv2 #捕捉视频 cap = cv2.VideoCapture('vedio/重庆.m4v') #逐桢读取 while True: successs,img = cap.read() cv2.imshow('vedio',img) #按q结束 if cv2.waitKey(1) & 0xFF == ord('q'): break网络摄像头
import cv2 #0表示默认摄像头 cap = cv2.VideoCapture(0) #根据id改变视频显示的各种参数的参数 cap.set(3,640)#3是wide cap.set(4,480)#4是height cap.set(10,100)#10是亮度 #逐桢读取 while True: successs,img = cap.read() cv2.imshow('vedio',img) #按q结束 if cv2.waitKey(1) & 0xFF == ord('q'): break图片操作
import cv2 import numpy as np img1 = cv2.imread('image/正常图片.jpg') img_2 = cv2.imread('image/胎侧缺胶1.jpg') #灰化图像 imgGray = cv2.cvtColor(img1,cv2.COLOR_BGR2GRAY) #设置图片大小 img1 = cv2.resize(imgGray, (320, 240)) #模糊化图像 imgBlur = cv2.GaussianBlur(imgGray,(9,9),0) img2 = cv2.resize(imgBlur, (320, 240)) #让线条更清晰 imgCanny = cv2.Canny(img1,100,100) img3 = cv2.resize(imgCanny, (320, 240)) #膨胀操作,即让图片里的线条更粗 ''' cv2.dilate(src, kernel, iteration) 参数说明: src表示输入的图片, kernel表示方框的大小, iteration表示迭代的次数 膨胀操作原理:存在一个kernel,在图像上进行从左到右,从上到下的平移,如果方框中存在白色,那么这个方框内所有的颜色都是白色 ''' kernel = np.ones((5,5),np.uint8) imgDialation = cv2.dilate(imgCanny,kernel,iterations=1) img4 = cv2.resize(imgDialation, (320, 240)) #侵蚀操作,即让图片里的线条更细 imgEroded = cv2.erode(imgDialation,kernel,iterations=1) img5 = cv2.resize(imgCanny, (320, 240)) cv2.imshow('gray',img1) cv2.imshow('blur',img2) cv2.imshow('canny',img3) cv2.imshow('canny',img3) cv2.imshow('dialete',img4) cv2.imshow('eroded',img5) cv2.waitKey(0)裁剪图片
import cv2 img = cv2.imread("./data/cut/thor.jpg") print(img.shape) # 裁剪坐标为[y0:y1, x0:x1] cropped = img[0:128, 0:512] #存储图片 cv2.imwrite("./data/cut/cv_cut_thor.jpg", cropped)图像二值化
####cv2.threshold()
第一个参数 src 指原图像,原图像应该是灰度图。
第二个参数 x 指用来对像素值进行分类的阈值。
第三个参数 y 指当像素值高于(有时是小于)阈值时应该被赋予的新的像素值
第四个参数 Methods 指,不同的不同的阈值方法,这些方法包括:
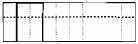
•cv2.THRESH_BINARY 图(1)
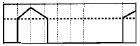
•cv2.THRESH_BINARY_INV 图(2)
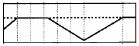
•cv2.THRESH_TRUNC 图(3)
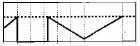
•cv2.THRESH_TOZERO 图(4)
•cv2.THRESH_TOZERO_INV 图(5)
破折线为将被阈值化的值;虚线为阈值
图(1)
大于阈值的像素点的灰度值设定为最大值(如8位灰度值最大为255),灰度值小于阈值的像素点的灰度值设定为0。
图(2)
大于阈值的像素点的灰度值设定为0,而小于该阈值的设定为255。
图(3)
像素点的灰度值小于阈值不改变,大于阈值的灰度值的像素点就设定为该阈值。
图(4)
像素点的灰度值小于该阈值的不进行任何改变,而大于该阈值的部分,其灰度值全部变为0**。**
图(5)
像素点的灰度值大于该阈值的不进行任何改变,像素点的灰度值小于该阈值的,其灰度值全部变为0。
cv2.findContours() 轮廓检测
cv2.findContours(image, mode, method, contours=None, hierarchy=None, offset=None)
mage代表输入的图片。注意**输入的图片必须为二值图片。**若输入的图片为彩色图片,必须先进行灰度化和二值化。
mode 表示轮廓的检索模式,有4种:
cv2.RETR_EXTERNAL 表示只检测外轮廓。
cv2.RETR_LIST 检测的轮廓不建立等级关系。
cv2.RETR_CCOMP 建立两个等级的轮廓,上面的一层为外边界,里面的一层为内孔的边界信息。如果内孔内还有一 个连通物体,这个物体的边界也在顶层。
cv2.RETR_TREE 建立一个等级树结构的轮廓。
method 为轮廓的近似办法,有4种:
cv2.CHAIN_APPROX_NONE 存储所有的轮廓点,相邻的两个点的像素位置差不超过1,即max(abs(x1-x2), abs(y2-y1))<=1。
cv2.CHAIN_APPROX_SIMPLE 压缩水平方向,垂直方向,对角线方向的元素,只保留该方向的终点坐标,例如一个 矩形轮廓只需4个点来保存轮廓信息。
cv2.CHAIN_APPROX_TC89_L1 和 cv2.CHAIN_APPROX_TC89_KCOS使用teh-Chinl chain 近似算法。返回值:
cv2.findContours()函数返回两个值,一个是轮廓本身contours,还有一个是每条轮廓对应的属性hierarchy。
contours:
cv2.findContours()函数首先返回一个list,list中每个元素(本例为2个)都是图像中的一个轮廓信息,list中每个元素(轮廓信息)类型为ndarray。len(contours[1]) 表示第一个轮廓储存的元素个数,即该轮廓中储存的点的个数。本例第一个轮廓为矩形,轮廓中有4个点,这是因为当参数***mode*** 设置成: cv2.CHAIN_APPROX_SIMPLE ,轮廓中并不是存储轮廓上所有的点,而是只存储可以用直线描述轮廓的点的个数,比如一个“正立”的矩形,只需4个顶点就能描述轮廓了
其它操作
##按键输入消失 num<0 ##0或不填系数 ,一直不消失 num==0 ##停滞num秒 num>0 5、 关闭所有窗口 cv2.destroyAllWindows() 6、图像赋值 1)基本操作 img[100,100]=255 #灰度图赋值 img[100,100,0]=255 #彩色图单通道赋值 img[100,100]=[255,255,255] #彩色图多通道赋值 2)numpy操作 img.item(100, 100, 2) #获得(100,100)点,2通道的值 img.itemset((100, 100, 2), 255) #设置(100,100)点2通道的值 7、获取图像属性 ##获取BGR图 高、宽、深度 h,w,d=img.shape ##获得图片大小 h*w 或 h*w*d img_size=img.size ##获得图片数据类型 img.dtype 8、感兴趣区域ROI (region of interest) ##获得面部图像 face= img[220:400, 250:350] ##粘贴脸部图像,可以跨图粘贴 img[0:180, 0:100]=face 9、通道分解合并 ##通道分解方案1 b=img[:,:,0] g=img[:,:,1] r=img[:,:,2] ##通道分解方案2 b,g,r=cv2.split(img) ##通道合并 rgb=cv2.merge([r,g,b]) ##只显示蓝色通道 b=cv2.split(a)[0] g = np.zeros((rows,cols),dtype=a.dtype) r = np.zeros((rows,cols),dtype=a.dtype) m=cv2.merge([b,g,r]) 10、图像加法 ##超过255则为0 result1= img1 + img2 ##超过255则为255 result2=cv2.add(img1, img2) ##图像带权重融合,第5个参数为偏移量 result=cv2.addWeighted(img1,0.5,img2,0.5, 0) 11、图像类型转换 ##彩色图转灰度图 img2=cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY) ##BGR图转RGB图(重点:opencv的通道是 蓝、绿、红跟计算机常用的红、绿、蓝通道相反) img2=cv2.cvtColor(img1, cv2.COLOR_BGR2RGB) ##灰度图转BGR图,每个通道都是之前的灰度值 img2=cv2.cvtColor(img1, cv2.COLOR_GRAY2BGR) 12、图像缩放 (宽、高) ##图片缩放->(200,100) img2=cv2.resize(img1, (200, 100)) ##按比例缩放->(0.5,1.2) img2=cv2.resize(img1, (round(cols * 0.5), round(rows * 1.2))) ##按比例缩放,参数版 img2=cv2.resize(img1, None, fx=1.2, fy=0.5) 13、图像翻转 img2=cv2.flip(img1, 0) #上下翻转 img2=cv2.flip(img1, 1) #左右翻转 img2=cv2.flip(img1, -1) #上下、左右翻转 14、图像移动、旋转、缩放 ##图像移动=>(100,200) M = np.float32([[1, 0, 100], [0, 1, 200]]) b=cv2.warpAffine(img1, M, (height, width)) ##图像中心、旋转45度、缩放0.6 M=cv2.getRotationMatrix2D((height/2,width/2),45,0.6) img2=cv2.warpAffine(img1, M, (height, width)) ##图像菱形转换 p1=np.float32([[0,0],[cols-1,0],[0,rows-1]]) #左上角、右上角、左下角 p2=np.float32([[0,rows*0.33],[cols*0.85,rows*0.25],[cols*0.15,rows*0.7]]) M=cv2.getAffineTransform(p1,p2) dst=cv2.warpAffine(img,M,(cols,rows)) 15、图像阈值转换 、二值化 r,b=cv2.threshold(img, 127, 255, cv2.THRESH_BINARY) #图像二值化,阈值127,r为返回阈值,b为二值图 r,b=cv2.threshold(img, 127, 255, cv2.THRESH_BINARY_INV) #图像反二值化 r,b=cv2.threshold(a,127,255,cv2.THRESH_BINARY) #低于threshold则为0 r,b=cv2.threshold(a,127,255,cv2.THRESH_BINARY_INV) #高于threshold则为0 r,b=cv2.threshold(a,127,255,cv2.THRESH_TRUNC) #截断=>高于threshold则为threshold 16、图像平滑处理 ##均值滤波 img2=cv2.blur(img1, (5, 5)) #sum(square)/25 ##normalize=1 均值滤波,normalize=0 区域内像素求和 img1=cv2.boxFilter(img, -1, (2, 2), normalize=1) ##高斯滤波,第三个参数是方差,默认0计算公式: sigmaX=sigmaxY=0.3((ksize-1)*0.5-1)+0.8 (注:卷积核只能是奇数) img1=cv2.GaussianBlur(img, (3, 3), 0) #距离像素中心点近的权重较大,以高斯方式往四周分布 ##中值滤波,效果非常好? img1=cv2.medianBlur(img,3) #获得中心点附近像素排序后的中值 17、形态学操作 ##图像腐蚀,k为全1卷积核 k=np.ones((5,5),np.uint8) img1=cv2.erode(img, k, iterations=2) ##图像膨胀 k=np.ones((5,5),np.uint8) img1=cv2.dilate(img, k, iterations=2) ##图像开运算 (先腐蚀后膨胀),去掉图形外侧噪点 k=np.ones((5,5),np.uint8) img1=cv2.morphologyEx(img, cv2.MORPH_OPEN, k, iterations=2) ##图像闭运算(先膨胀后腐蚀) ,去掉图形内侧噪点 k=np.ones((5,5),np.uint8) img1=cv2.morphologyEx(img, cv2.MORPH_CLOSE, k, iterations=2) ##图像梯度运算(膨胀-腐蚀) k=np.ones((5,5),np.uint8) img1=cv2.morphologyEx(img, cv2.MORPH_GRADIENT, k) ##高帽运算 (原图-开运算),获得图形外噪点 k=np.ones((5,5),np.uint8) img1=cv2.morphologyEx(img, cv2.MORPH_TOPHAT, k) ##黑帽运算(闭运算-原图),获得图像内噪点 k=np.ones((10,10),np.uint8) img1=cv2.morphologyEx(img, cv2.MORPH_BLACKHAT, k) 18、图像梯度,边缘提取 ##sobel梯度边缘提取,卷积核竖向[[-1,-2,-1][0,0,0][1,2,1]] sobelx = cv2.Sobel(o,cv2.CV_64F,1,0,ksize=3) #横向边缘提取 sobely = cv2.Sobel(o,cv2.CV_64F,0,1,ksize=3) #竖向边缘提取 sobelx = cv2.convertScaleAbs(sobelx) # 负值取正,图像展示只能有正值 sobely = cv2.convertScaleAbs(sobely) sobelxy = cv2.addWeighted(sobelx,0.5,sobely,0.5,0) #图像融合 ##scharr梯度边缘提取,卷积核竖向[[-3,-10,-3][0,0,0][3,10,3]] ,scharr比sobel卷积核过滤出更多细节 scharrx = cv2.Scharr(o,cv2.CV_64F,1,0) scharry = cv2.Scharr(o,cv2.CV_64F,0,1) scharrx = cv2.convertScaleAbs(scharrx) # 负值取正 scharry = cv2.convertScaleAbs(scharry) scharrxy = cv2.addWeighted(scharrx,0.5,scharry,0.5,0) #图像融合 ## 拉普拉斯梯度,边缘提取版本1 , 拉普拉斯图像梯度 [[0,1,0][1,-4,1][0,1,0] ] img1 = cv2.Laplacian(img, cv2.CV_64F) img1 = cv2.convertScaleAbs(img1) ##拉普拉斯梯度,边缘提取版本2,结果略有不同 f=np.array([[0,1,0],[1,-4,1],[0,1,0]]) img1=cv2.filter2D(img, -1, f) 19、canny边缘检测 ##canny边缘检测理论 sobel梯度大小:0.5|x|+0.5|y| 高斯滤波 梯度方向:arctan(y/x) 同方向上保留最大梯度 去噪------------------------->梯度------------------------------------->非极大值抑制----------------------------> 跟高阈值连通的线会保留 滞后阈值--------------------->out ##canny边缘检测代码 img1 = cv2.Canny(img,100,200) #参数:图片、低阈值、高阈值 20、图像金字塔 ##图片向下采样,高斯滤波 1/2 删掉偶数列 img1 = cv2.pyrDown(img) ##图片向上采样 ,面积*2 高斯滤波*4 ,下采样为不可逆运算 img3=cv2.pyrUp(img2) ##计算拉普拉斯金字塔 img1 = cv2.pyrDown(img) #下采样 img2=cv2.pyrUp(img1) #上采样 img3=img-img2 21、图像轮廓标注 gray_img=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY) #灰度图转化 dep,img_bin=cv2.threshold(gray_img,128,255,cv2.THRESH_BINARY) #二值图转化 image_,contours,hierarchy=cv2.findContours(img_bin,mode=cv2.RETR_TREE, method=cv2.CHAIN_APPROX_SIMPLE) #获得图像轮廓 to_write=img.copy() #原始图像copy,否则会在原图上绘制 ret=cv2.drawContours(to_write,contours,-1,(0,0,255),2) #红笔绘制图像轮廓 22、直方图 ##matplotlib 绘制直方图 plt.hist(img.ravel(),256) ##用opencv计算直方图列表 hist=cv2.calcHist(images= [img],channels=[0],mask=None,histSize=[256],ranges=[0,255]) ##掩膜提取局部直方图 pad=np.zeros(img.shape,np.uint8) pad[200:400,200:400]=255 hist_MASK=cv2.calcHist(images= [img],channels=[0],mask=pad,histSize=[256],ranges=[0,255]) ##opencv 交、并、补、异或操作 masked_img=cv2.bitwise_and(img,mask) ##直方图均衡化原理 图像直方图->直方图归一化->累计直方图->*255 x坐标映射->对原来的像素值进行新像素值编码 ##直方图均衡化调用 img1=cv2.equalizeHist(img) ##matplotlib绘制图片前通道转换 img_rgb=cv2.cvtColor(img,cv2.COLOR_BGR2RGB) #通道不一致性 ##matplotlib多图绘制在一个面板上 plt.subplot('221'),plt.imshow(img,cmap=plt.cm.gray),plt.axis('off'),plt.title('original') plt.subplot('222'), plt.imshow(img1, cmap=plt.cm.gray), plt.axis('off') plt.subplot('223'), plt.hist(img.ravel(),256) plt.subplot('224'), plt.hist(img1.ravel(), 256) 23、图像傅里叶变换(空间域=>频域) ##图像傅里叶变换 (转化为虚数,实部为幅度,虚部为频率) fft=np.fft.fft2(img) fft_center=np.fft.fftshift(fft) fft_flect=20*np.log(np.abs(fft_center)) ##图像傅里叶逆变换 fft_left=np.fft.ifftshift(fft_center) ifft=np.fft.ifft2(fft_left) img_f=np.abs(ifft) ##高通滤波 h_c,w_c=round(h/2),round(w/2) fft_center[h_c-10:h_c+10,w_c-10:w_c+10]=0 #原图操作,低频信号归0 ##opencv 傅里叶变换 dft=cv2.dft(np.float32(img),flags=cv2.DFT_COMPLEX_OUTPUT) fft_center=np.fft.fftshift(dft) ##opencv 低通滤波 mask=np.zeros((h,w,2),dtype=np.uint8) #定义掩膜 h_c,w_c=round(h/2),round(w/2) R=20 mask[h_c-R:h_c+R,w_c-R:w_c+R]=1 dshift=fft_center*mask #点乘,保留低频信号 ##opencv 傅里叶反变换 fft_left=np.fft.ifftshift(dshift) ifft=cv2.idft(fft_left) img_f=cv2.magnitude(ifft[:,:,0],ifft[:,:,1]) #Square(x*2+y*2)


##知识点简单认识-简单人脸识别
import sys #face_recognition是人脸识别的一个模块 import face_recognition import cv2 #读取图像 face_image = face_recognition.load_image_file('image/IMG_2784.jpeg') #给一张图片,返回图像每个面的128维的人脸编码 face_encondings = face_recognition.face_encodings(face_image) #返回每个人脸的面部特征位置 face_locations = face_recognition.face_locations(face_image) #判断图像中的人数 face_number = len(face_encondings) print(face_number) if face_number > 2: print('人脸书超过了2') #退出程序 sys.exit() try: face_01 = face_encondings[0] face_02 = face_encondings[1] except: print('出错') sys.exit() #比较脸部的编码是否匹配,tolerance比较的误差值 result = face_recognition.compare_faces([face_01],face_02,tolerance=0.1) print(result) if result == True: print('1') name = 'yes' else: print('0') name = 'no' #绘图 for i in range(len(face_encondings)): #得到人脸编码 face_enconding = face_encondings[(i-1)] #得到人脸特征 位置参数 face_location = face_locations[(i-1)] print(face_location) top,right,bottom,left = face_location#坐标 #画框 照片 坐标 颜色 粗细 # 左上角 右下角 cv2.rectangle(face_image,(left,top),(right,bottom),(0,255,0),2) #放上字体 图像 文字 坐标 字体 大小 颜色 粗细 cv2.putText(face_image,name,(left-10,top-10),cv2.FONT_HERSHEY_COMPLEX,0.5,(255,0,0),2) #颜色 face_image_rgb = cv2.cvtColor(face_image,cv2.COLOR_BGR2RGB) #展示图像 cv2.imshow('output',face_image_rgb) #关闭,如果没有这个,图片会一闪而过 cv2.waitKey(0)
轮胎检测
第一步:
把所有图片用ps裁剪成同样大小
第二步:
进行如下操作
import cv2 import numpy as np # 拿到照片,并做相应处理 for i in range(4): name = 'image/'+str(i+1)+'.jpg' imgCom = cv2.imread(name, cv2.IMREAD_UNCHANGED) # 灰化处理 imgGray = cv2.cvtColor(imgCom, cv2.COLOR_BGR2GRAY) #边缘检测 imgCanny = cv2.Canny(imgGray, 100, 100) #膨胀操作 kernel_01 = np.ones((5, 5), np.uint8) imgDialation_common = cv2.dilate(imgCanny, kernel_01, iterations=1) #侵蚀操作 imgEroded = cv2.erode(imgDialation_common, None, iterations=5) # 二值化处理 ret, img_bin = cv2.threshold(imgEroded, 125, 255, cv2.THRESH_BINARY_INV) # 轮廓检测(返回值:contours-轮廓本身,hierarchy-轮廓的属性) contours, hierarchy = cv2.findContours(img_bin, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE) ''' 第一个参数是指明在哪幅图像上绘制轮廓;image为三通道才能显示轮廓 第二个参数是轮廓本身,在Python中是一个list; 第三个参数指定绘制轮廓list中的哪条轮廓,如果是-1,则绘制其中的所有轮廓。后面的参数很简单。其中thickness表明轮廓线的宽度,如果是-1(cv2.FILLED),则为填充模式。 ''' # 画轮廓 img = cv2.drawContours(imgCom, contours, -1, (0, 255, 0), 1) ''' x, y, w, h = cv2.boundingRect(img) 参数: img 是一个二值图 x,y 是矩阵左上点的坐标, w,h 是矩阵的宽和高 ''' #得到坐标 x, y, w, h = cv2.boundingRect(img_bin) ''' cv2.rectangle(img, (x,y), (x+w,y+h), (0,255,0), 2) img: 原图 (x,y): 矩阵的左上点坐标 (x+w,y+h):是矩阵的右下点坐标 (0,255,0): 是画线对应的rgb颜色 2: 线宽 ''' #画矩形框 cv2.rectangle(imgCom, (x, y), (x + w, y + h), (0, 255, 0), 2) cv2.imshow('drawimg', imgCom) cv2.waitKey(0) cv2.destroyAllWindows()
结果
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GB1qy83s-1587010795340)
(/Users/manblue/Downloads/轮胎检测/未标题-1.jpg)]
总结
以上是用简单的opencv进行的有限操作的结果,若要追求准确的结果,则还需要使用卷积神经网络
因为我们首先要找到轮胎上的缺陷,缺陷是一个特征,如一个缝隙(包括缝隙的长 宽 深度 磨损度等),用简单的几组数据如法得出准确的结果,需要用到深度学习中的卷积神经网络。
卷积神经网络
卷积神经网络是一类包含卷积计算且具有深度结构的前馈神经网络,是深度学习的代表算法之一 [1-2] 。卷积神经网络具有表征学习能力,能够按其阶层结构对输入信息进行平移不变分类(因此也被称为“平移不变人工神经网络.
知识点链接:https://www.paddlepaddle.org.cn/documentation/docs/zh/api_guides/low_level/layers/index.html
学习进度:4月15日:9:00–13:00
4月16日:8:00–11:00
总耗时7h。