数据去重 填补空缺值(拉格朗日)
此时我是不是该喊一声“我胡汉三又回来啦!!!”
这篇博客容许我摸一下数据清洗的裤脚......
1.首先。
这是在网上找的数据,一个心脏病的数据集,英文不好的默默打开翻译,被我悄悄的做了手脚变成“脏数据”。

2.去重

(1)将文本传入kettle,转换为excel文件
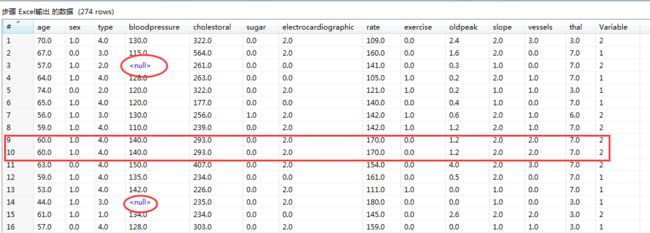
(2)进行去重步骤操作,可以看到有4条重复数据被去除,输出表格。


3.使用拉格朗日填补空缺值(一度读成朗格拉日(๑°ㅁ°๑)‼)
(1)话不多说直接上代码
#coding=utf-8
import pandas as pd
from scipy.interpolate import lagrange # 导入拉格朗日函数
inputfile = 'D:/heart0.xls'
outputfile = 'D:/heart01.xls' #数据输入输出路径
def FillNaN(input, output, k=5): #取k=5
data = pd.read_excel(input, header=None) #读入数据
title = data[:1] #数据列名
data = data[1:] #将列名去掉只取数值
for i in range(len(data.columns)):
for j in range(1, len(data)+1): #循环每个值
if j < k : #当被插值位置距第一行<5
y = data[i][list(range(1, j)) + list(range(j+1, j+1+k))] #取数
y = y[y.notnull()] # 剔除空值
if (data[i].isnull())[j]: #遇空值的话
data[i][j] = round(lagrange(y.index, list(y))(j)) #插值并返回插值多项式,代入j得到插值结果,四舍五入
elif (j >= k) and (j < len(data) - k): #位置距第一行>=5,距最后一行>5
y = data[i][list(range(j-k, j)) + list(range(j+1, j+1+k))]
y = y[y.notnull()]
if (data[i].isnull())[j]:
data[i][j] = round(lagrange(y.index, list(y))(j))
elif j >= len(data) - k: #距最后一行<=5
y = data[i][list(range(len(data)-1-2*k, j)) + list(range(j+1, len(data)))]
y = y[y.notnull()]
if (data[i].isnull())[j]:
data[i][j] = round(lagrange(y.index, list(y))(j))
data = pd.concat([title, data]) #将列名和数值合并
data.to_excel(output, header=None, index=False) #输出结果写入文件
FillNaN(inputfile, outputfile)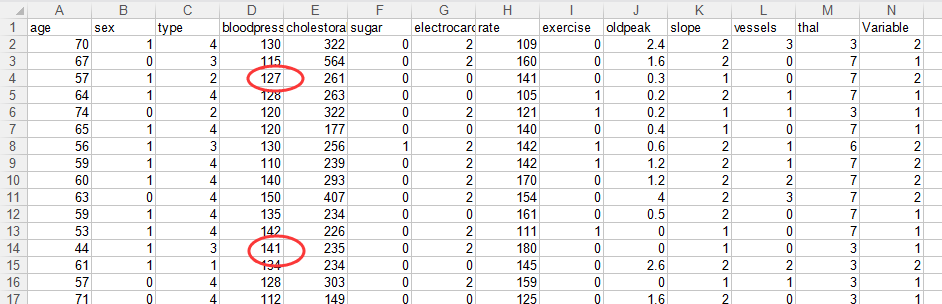
4.错误分析
(1)KeyError: 0L
Traceback (most recent call last):
File "C:/Users/DELL/Desktop/PycharmProject/python/cnki.py", line 54, in
FillNaN(inputfile, outputfile)
File "C:/Users/DELL/Desktop/PycharmProject/python/cnki.py", line 38, in FillNaN
if (data[i].isnull())[j]: #遇空值的话
File "C:\Users\DELL\Anaconda\lib\site-packages\pandas\core\series.py", line 521, in __getitem__
result = self.index.get_value(self, key)
File "C:\Users\DELL\Anaconda\lib\site-packages\pandas\core\index.py", line 1595, in get_value
return self._engine.get_value(s, k)
File "pandas\index.pyx", line 100, in pandas.index.IndexEngine.get_value (pandas\index.c:3113)
File "pandas\index.pyx", line 108, in pandas.index.IndexEngine.get_value (pandas\index.c:2844)
File "pandas\index.pyx", line 154, in pandas.index.IndexEngine.get_loc (pandas\index.c:3704)
File "pandas\hashtable.pyx", line 375, in pandas.hashtable.Int64HashTable.get_item (pandas\hashtable.c:7224)
File "pandas\hashtable.pyx", line 381, in pandas.hashtable.Int64HashTable.get_item (pandas\hashtable.c:7162)
KeyError: 0L
问题分析:我开始以为是OL,所以一直没找到错误。其实它是0L,即DataFrame的行是从1开始数的直到最后一行,所以它出这个错误就是你在访问它的值时超过了范围,在正确范围内就可以了。
问题解决:我将访问范围设置为 for j in range(1, len(data)+1):
(2)TypeError: 'Int64Index' object is not callable
Traceback (most recent call last):
File "C:/Users/DELL/Desktop/PycharmProject/python/cnki.py", line 25, in
data[i][j] = ployinterp_column(data[i], j)
File "C:/Users/DELL/Desktop/PycharmProject/python/cnki.py", line 20, in ployinterp_column
return lagrange(y.index(), list(y))(n)
TypeError: 'Int64Index' object is not callable
问题分析:一开始是看书上代码写的,它是先写了一个函数然后填值,看好多网上也是类似这样:
def ployinterp_column(s, n, k=5):
y = s[list(range(n-k, n)) + list(range(n+1, n+1+k))]
y = y[y.notnull()]
return lagrange(y.index(), list(y))(n)
for i in range(len(data.columns)):
for j in range(1,len(data)+1):
if (data[i].isnull())[j]:
data[i][j] = ployinterp_column(data[i], j)原因我也不清楚,可能人家的数据能跑出来,我的就不可以(ಥ _ ಥ)
问题解决:将s直接替换为data(i),n换成j.
5.我的平均值填补渣渣链接......http://blog.csdn.net/tt_258/article/details/69359631