Apache、nginx 、lighttpd
转自:http://blog.csdn.net/hguisu/article/details/7395181
http://blog.csdn.net/hguisu/article/details/7403622
http://blog.csdn.net/hguisu/article/details/8930668
1. web服务器简介
1. lighttpd
Lighttpd是一个德国人领导的开源软件,其根本的目的是提供一个专门针对高性能网站,安全、快速、兼容性好并且灵活的Web server环境
Lighttpd是一个具有非常低的内存开销,cpu占用率低,效能好,以及丰富的模块等特点。lighttpd是众多OpenSource轻量级的web server中较为优秀的一个。支持FastCGI, CGI, Auth, 输出压缩(output compress), URL重写, Alias等重要功能。
而Apache之所以流行,很大程度也是因为功能丰富,在Lighttpd 上很多功能都有相应的实现了,这点对于Apache的用户是非常重要的,因为迁
移到Lighttpd就必须面对这些问题。
Lighttpd使用fastcgi方式运行PHP,它会使用很少的PHP进程响应很大的并发量。其fastCGI进程管理器一般使用spawn-fcgi
2.apache
apache是世界排名第一的web服务器, 根据netcraft(www.netsraft.co.uk)所作的调查,世界上百分之五十以上的web服务器在使用apache.
1995年4月, 最早的apache(0.6.2版)由apache group公布发行. apache group 是一个完全通过internet进行运作的非盈利机构, 由它来决定apache web服务器的标准发行版中应该包含哪些内容. 准许任何人修改隐错, 提供新的特征和将它移植到新的平台上, 以及其它的工作. 当新的代码被提交给apache group时, 该团体审核它的具体内容, 进行测试, 如果认为满意, 该代码就会被集成到apache的主要发行版中.
它有优势主要在于源代码开放、有一支开放的开发队伍、支持跨平台的应用(可以运行在几乎所有的Unix、Linux、Windows系统平台之上)。Apache的模块支持非常丰富,以至于它提供了非常完善的功能。
apache 的特性:
1) 几乎可以运行在所有的计算机平台上.
2) 支持最新的http/1.1协议
3) 简单而且强有力的基于文件的配置(httpd.conf).
4) 支持通用网关接口(cgi)
5) 支持虚拟主机.
6) 支持http认证.
7) 集成perl.
8) 集成的代理服务器
9) 可以通过web浏览器监视服务器的状态, 可以自定义日志.
10) 支持服务器端包含命令(ssi).
11) 支持安全socket层(ssl).
12) 具有用户会话过程的跟踪能力.
13) 支持fastcgi(只在apache1.3时支持,apache2以后的版本不再支持了)
14) 支持Java servlets
15) 不支持epoll(这年头,epoll几乎是性能的必备,这也是为什么apache的并发性能比其他两款web软件差的主要原因吧)
16) 非常好用的proxy和proxy_ajp(很多人用它作为tomcat的前端)
3.nginx
Nginx是俄罗斯人编写的十分轻量级的HTTP服务器,Nginx,它的发音为“engine X”, 是一个高性能的HTTP和反向代理服务器,同时也是一个IMAP/POP3/SMTP 代理服务器.Nginx是由俄罗斯人 Igor Sysoev为俄罗斯访问量第二的 Rambler.ru站点开发.
Nginx以事件驱动的方式编写,所以有非常好的性能,同时也是一个非常高效的反向代理、负载平衡。其拥有匹配 Lighttpd的性能,同时还没有Lighttpd的内存泄漏问题,而且Lighttpd的mod_proxy也有一些问题并且很久没有更新。但是Nginx并不支持cgi方式运行,原因是可以减少因此带来的一些程序上的漏洞。所以必须使用FastCGI方式来执行PHP程序。
nginx做为HTTP服务器,有以下几项基本特性:
1)处理静态文件,索引文件以及自动索引;打开文件描述符缓冲.
2)无缓存的反向代理加速,简单的负载均衡和容错.
3)FastCGI,简单的负载均衡和容错.
4)模块化的结构。包括gzipping, byte ranges, chunked responses,以及 SSI-filter等filter。如果由FastCGI或其它代理服务器处理单页中存在的多个SSI,则这项处理可以并行运行,而不需要相互等待。
5) Nginx专为性能优化而开发,性能是其最重要的考量,实现上非常注重效率。它支持内核Poll模型,能经受高负载的考验,有报告表明能支持高达 50,000个并发连接数。
6) Nginx具有很高的稳定性。其它HTTP服务器,当遇到访问的峰值,或者有人恶意发起慢速连接时,也很可能会导致服务器物理内存耗尽频繁交换,失去响应,只能重启服务器。例如当前apache一旦上到200个以上进程,web响应速度就明显非常缓慢了。而Nginx采取了分阶段资源分配技术,使得它的CPU与内存占用率非常低。nginx官方表示保持10,000个没有活动的连接,它只占2.5M内存,所以类似DOS这样的攻击对nginx来说基本上是毫无用处的。就稳定性而言,nginx比lighthttpd更胜一筹。
7) Nginx支持热部署。它的启动特别容易, 并且几乎可以做到7*24不间断运行,即使运行数个月也不需要重新启动。你还能够在不间断服务的情况下,对软件版本进行进行升级。
2. Nginx与Apache的异同
Nginx和Apache一样,都是HTTP服务器软件,在功能实现上都采用模块化结构设计,都支持通用的语言接口,如PHP、Perl、Python等,同时还支持正向和反向代理、虚拟主机、URL重写、压缩传输、SSL加密传输等。
1)在功能实现上,Apache的所有模块都支持动、静态编译,而Nginx模块都是静态编译的,
2)对FastCGI的支持,Apache对Fcgi的支持不好,而Nginx对Fcgi的支持非常好;
3)在处理连接方式上,Nginx支持epoll,而Apache却不支持;
4)在空间使用上,Nginx安装包仅仅只有几百K,和Nginx比起来Apache绝对是庞然大物。
1)
Nginx 相对apache的优点:轻量级,同样起web 服务,比apache 占用更少的内存及资源
静态处理,Nginx 静态处理性能比 Apache 高 3倍以上
抗并发,nginx 处理请求是异步非阻塞的,而apache则是阻塞型的,在高并发下nginx 能保持低资源低消耗高性能。在Apache+PHP(prefork)模式下,如果PHP处理慢或者前端压力很大的情况下,很容易出现Apache进程数飙升,从而拒绝服务的现象。
高度模块化的设计,编写模块相对简单
社区活跃,各种高性能模块出品迅速啊
2) apache 相对nginx 的优点:
rewrite,比nginx 的rewrite 强大
模块超多,基本想到的都可以找到
少bug,nginx的bug相对较多
超稳定
Apache对PHP支持比较简单,Nginx需要配合其他后端用
存在就是理由,一般来说,需要性能的web 服务,用nginx 。如果不需要性能只求稳定,那就apache 吧。后者的各种功能模块实现得比前者,例如ssl 的模块就比前者好,可配置项多。
这里要注意一点,epoll(freebsd 上是 kqueue )网络IO 模型是nginx 处理性能高的根本理由,但并不是所有的情况下都是epoll 大获全胜的,如果本身提供静态服务的就只有寥寥几个文件,apache 的select 模型或许比epoll更高性能。当然,这只是根据网络IO 模型的原理作的一个假设,真正的应用还是需要实测了再说的。
3) . 选择Nginx的优势所在
Nginx作为HTTP服务器的优势是显而易见的,它有很多其他Web服务器无法比拟的性能和优势:
1) 作为Web服务器: Nginx处理静态文件、索引文件,自动索引的效率非常高。
2) 作为代理服务器,Nginx可以实现无缓存的反向代理加速,提高网站运行速度。
3) 作为负载均衡服务器,Nginx既可以在内部直接支持Rails和PHP,也可以支持HTTP代理服务器对外进行服务,同时还支持简单的容错和利用算法进行负载均衡。
4) 在性能方面,Nginx是专门为性能优化而开发的,在实现上非常注重效率。它采用内核Poll模型(epoll and kqueue ),可以支持更多的并发连接,最大可以支持对50 000个并发连接数的响应,而且只占用很低的内存资源。
5) 在稳定性方面,Nginx采取了分阶段资源分配技术,使得CPU与内存的占用率非常低。Nginx官方表示,Nginx保持10 000个没有活动的连接,而这些连接只占用2.5MB内存,因此,类似DOS这样的攻击对Nginx来说基本上是没有任何作用的。
6) 在高可用性方面,Nginx支持热部署,启动速度特别迅速,因此可以在不间断服务的情况下,对软件版本或者配置进行升级,即使运行数月也无需重新启动,几乎可以做到7×24小时不间断地运行。
这两者最核心的区别在于apache是同步多进程模型,一个连接对应一个进程;nginx是异步的,多个连接(万级别)可以对应一个进程 。
建议使用Nginx做前端,后端用apache。大型网站最好使用Nginx自带的集群功能。
Nginx和apache压力测试数据比较:
| apache | nginx | ||||||
| n | c | Time | r/s | t/r(ms) | Time | r/s | t/r |
| 40000 | 200 | 45 | 886 | 225 | 41 | 955 | 209 |
| 40000 | 200 | 36 | 1091 | 183 | 40 | 986 | 202 |
| 40000 | 400 | 361 | 110 | 3614 | 49 | 813 | 491 |
| 40000 | 400 | 49 | 811 | 492 | 38 | 1027 | 389 |
| 40000 | 400 | 38 | 1037 | 385 | 41 | 963 | 415 |
| 40000 | 1000 | 407 | 98 | 10177 | 51 | 773 | 1292 |
| 40000 | 1000 | 323 | 123 | 8091 | |||
| 40000 | 5000 | 349 | 114 | 43660 | 53 | 741 | 6742 |
| 40000 | 10000 | 364 | 109 | 91142 | 69 | 574 | 17394 |
| 40000 | 15000 | 369 | 108 | 138665 | 310 | ||
服务器数据:
| n | c | sys | sys |
| 40000 | 200 | ProcessNum:223 Mem:130.0 CPU:253.2 Load:2.57 ProcessNum:209 Mem:121.5 CPU:186.7 Load:3.52 |
ProcessNum:35 Mem:7.1 CPU:0 Load:0.29 ProcessNum:35 Mem:7.1 CPU:7.8 Load:5.99 |
| 40000 | 400 | ProcessNum:177 Mem:134.3 CPU:55.3 Load:0.46 ProcessNum:413 Mem:239.3 CPU:122.4 Load:3.52 |
ProcessNum:35 Mem:10.7 CPU:5.9 Load:0.04 ProcessNum:38 Mem:10.7 CPU:29.1 Load:5.08 |
| 40000 | 1000 | ProcessNum:188 Mem:92.9 CPU:10.8 Load:0.01 ProcessNum:401 Mem:200.0 CPU:15.3 Load:1.43 |
ProcessNum:39 Mem:7.1 CPU:8.3 Load:3.08 ProcessNum:39 Mem:7.1 CPU:15.6 L |
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
NGINX以高性能的负载均衡器,缓存,和web服务器闻名,驱动了全球超过 40% 最繁忙的网站。在大多数场景下,默认的 NGINX 和 Linux 设置可以很好的工作,但要达到最佳性能,有些时候必须做些调整。首先我们先了解其工作原理。
1. Nginx的模块与工作原理
Nginx由内核和模块组成,其中,内核的设计非常微小和简洁,完成的工作也非常简单,仅仅通过查找配置文件将客户端请求映射到一个location block(location是Nginx配置中的一个指令,用于URL匹配),而在这个location中所配置的每个指令将会启动不同的模块去完成相应的工作。
Nginx的模块从结构上分为核心模块、基础模块和第三方模块:
核心模块:HTTP模块、EVENT模块和MAIL模块
基础模块:HTTP Access模块、HTTP FastCGI模块、HTTP Proxy模块和HTTP Rewrite模块,
第三方模块:HTTP Upstream Request Hash模块、Notice模块和HTTP Access Key模块。
用户根据自己的需要开发的模块都属于第三方模块。正是有了这么多模块的支撑,Nginx的功能才会如此强大。
Nginx的模块从功能上分为如下三类。
Handlers(处理器模块)。此类模块直接处理请求,并进行输出内容和修改headers信息等操作。Handlers处理器模块一般只能有一个。
Filters (过滤器模块)。此类模块主要对其他处理器模块输出的内容进行修改操作,最后由Nginx输出。
Proxies (代理类模块)。此类模块是Nginx的HTTP Upstream之类的模块,这些模块主要与后端一些服务比如FastCGI等进行交互,实现服务代理和负载均衡等功能。
图1-1展示了Nginx模块常规的HTTP请求和响应的过程。
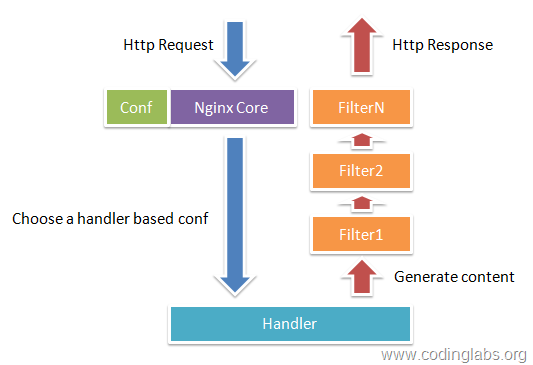
图1-1展示了Nginx模块常规的HTTP请求和响应的过程。
Nginx本身做的工作实际很少,当它接到一个HTTP请求时,它仅仅是通过查找配置文件将此次请求映射到一个location block,而此location中所配置的各个指令则会启动不同的模块去完成工作,因此模块可以看做Nginx真正的劳动工作者。通常一个location中的指令会涉及一个handler模块和多个filter模块(当然,多个location可以复用同一个模块)。handler模块负责处理请求,完成响应内容的生成,而filter模块对响应内容进行处理。
Nginx的模块直接被编译进Nginx,因此属于静态编译方式。启动Nginx后,Nginx的模块被自动加载,不像Apache,首先将模块编译为一个so文件,然后在配置文件中指定是否进行加载。在解析配置文件时,Nginx的每个模块都有可能去处理某个请求,但是同一个处理请求只能由一个模块来完成。
2. Nginx的进程模型
在工作方式上,Nginx分为单工作进程和多工作进程两种模式。在单工作进程模式下,除主进程外,还有一个工作进程,工作进程是单线程的;在多工作进程模式下,每个工作进程包含多个线程。Nginx默认为单工作进程模式。
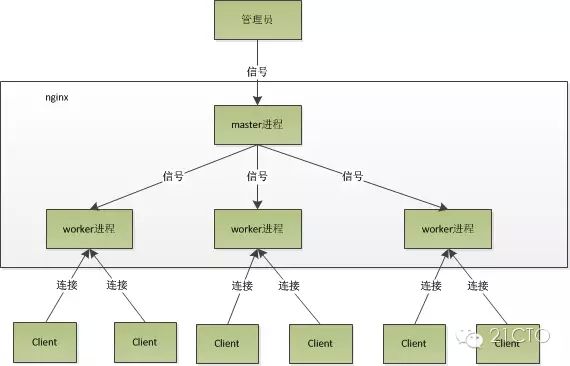
Nginx在启动后,会有一个master进程和多个worker进程。
master进程
主要用来管理worker进程,包含:接收来自外界的信号,向各worker进程发送信号,监控worker进程的运行状态,当worker进程退出后(异常情况下),会自动重新启动新的worker进程。
master进程充当整个进程组与用户的交互接口,同时对进程进行监护。它不需要处理网络事件,不负责业务的执行,只会通过管理worker进程来实现重启服务、平滑升级、更换日志文件、配置文件实时生效等功能。
我们要控制nginx,只需要通过kill向master进程发送信号就行了。比如kill -HUP pid,则是告诉nginx,从容地重启nginx,我们一般用这个信号来重启nginx,或重新加载配置,因为是从容地重启,因此服务是不中断的。master进程在接收到HUP信号后是怎么做的呢?首先master进程在接到信号后,会先重新加载配置文件,然后再启动新的worker进程,并向所有老的worker进程发送信号,告诉他们可以光荣退休了。新的worker在启动后,就开始接收新的请求,而老的worker在收到来自master的信号后,就不再接收新的请求,并且在当前进程中的所有未处理完的请求处理完成后,再退出。当然,直接给master进程发送信号,这是比较老的操作方式,nginx在0.8版本之后,引入了一系列命令行参数,来方便我们管理。比如,./nginx -s reload,就是来重启nginx,./nginx -s stop,就是来停止nginx的运行。如何做到的呢?我们还是拿reload来说,我们看到,执行命令时,我们是启动一个新的nginx进程,而新的nginx进程在解析到reload参数后,就知道我们的目的是控制nginx来重新加载配置文件了,它会向master进程发送信号,然后接下来的动作,就和我们直接向master进程发送信号一样了。
worker进程:
而基本的网络事件,则是放在worker进程中来处理了。多个worker进程之间是对等的,他们同等竞争来自客户端的请求,各进程互相之间是独立的。一个请求,只可能在一个worker进程中处理,一个worker进程,不可能处理其它进程的请求。worker进程的个数是可以设置的,一般我们会设置与机器cpu核数一致,这里面的原因与nginx的进程模型以及事件处理模型是分不开的。
worker进程之间是平等的,每个进程,处理请求的机会也是一样的。当我们提供80端口的http服务时,一个连接请求过来,每个进程都有可能处理这个连接,怎么做到的呢?首先,每个worker进程都是从master进程fork过来,在master进程里面,先建立好需要listen的socket(listenfd)之后,然后再fork出多个worker进程。所有worker进程的listenfd会在新连接到来时变得可读,为保证只有一个进程处理该连接,所有worker进程在注册listenfd读事件前抢accept_mutex,抢到互斥锁的那个进程注册listenfd读事件,在读事件里调用accept接受该连接。当一个worker进程在accept这个连接之后,就开始读取请求,解析请求,处理请求,产生数据后,再返回给客户端,最后才断开连接,这样一个完整的请求就是这样的了。我们可以看到,一个请求,完全由worker进程来处理,而且只在一个worker进程中处理。worker进程之间是平等的,每个进程,处理请求的机会也是一样的。当我们提供80端口的http服务时,一个连接请求过来,每个进程都有可能处理这个连接,怎么做到的呢?首先,每个worker进程都是从master进程fork过来,在master进程里面,先建立好需要listen的socket(listenfd)之后,然后再fork出多个worker进程。所有worker进程的listenfd会在新连接到来时变得可读,为保证只有一个进程处理该连接,所有worker进程在注册listenfd读事件前抢accept_mutex,抢到互斥锁的那个进程注册listenfd读事件,在读事件里调用accept接受该连接。当一个worker进程在accept这个连接之后,就开始读取请求,解析请求,处理请求,产生数据后,再返回给客户端,最后才断开连接,这样一个完整的请求就是这样的了。我们可以看到,一个请求,完全由worker进程来处理,而且只在一个worker进程中处理。
nginx的进程模型,可以由下图来表示:
3. Nginx+FastCGI运行原理
1、什么是 FastCGI
FastCGI是一个可伸缩地、高速地在HTTP server和动态脚本语言间通信的接口。多数流行的HTTP server都支持FastCGI,包括Apache、Nginx和lighttpd等。同时,FastCGI也被许多脚本语言支持,其中就有PHP。
FastCGI是从CGI发展改进而来的。传统CGI接口方式的主要缺点是性能很差,因为每次HTTP服务器遇到动态程序时都需要重新启动脚本解析器来执行解析,然后将结果返回给HTTP服务器。这在处理高并发访问时几乎是不可用的。另外传统的CGI接口方式安全性也很差,现在已经很少使用了。
FastCGI接口方式采用C/S结构,可以将HTTP服务器和脚本解析服务器分开,同时在脚本解析服务器上启动一个或者多个脚本解析守护进程。当HTTP服务器每次遇到动态程序时,可以将其直接交付给FastCGI进程来执行,然后将得到的结果返回给浏览器。这种方式可以让HTTP服务器专一地处理静态请求或者将动态脚本服务器的结果返回给客户端,这在很大程度上提高了整个应用系统的性能。
2、Nginx+FastCGI运行原理
Nginx不支持对外部程序的直接调用或者解析,所有的外部程序(包括PHP)必须通过FastCGI接口来调用。FastCGI接口在Linux下是socket(这个socket可以是文件socket,也可以是ip socket)。
wrapper:为了调用CGI程序,还需要一个FastCGI的wrapper(wrapper可以理解为用于启动另一个程序的程序),这个wrapper绑定在某个固定socket上,如端口或者文件socket。当Nginx将CGI请求发送给这个socket的时候,通过FastCGI接口,wrapper接收到请求,然后Fork(派生)出一个新的线程,这个线程调用解释器或者外部程序处理脚本并读取返回数据;接着,wrapper再将返回的数据通过FastCGI接口,沿着固定的socket传递给Nginx;最后,Nginx将返回的数据(html页面或者图片)发送给客户端。这就是Nginx+FastCGI的整个运作过程,如图1-3所示。
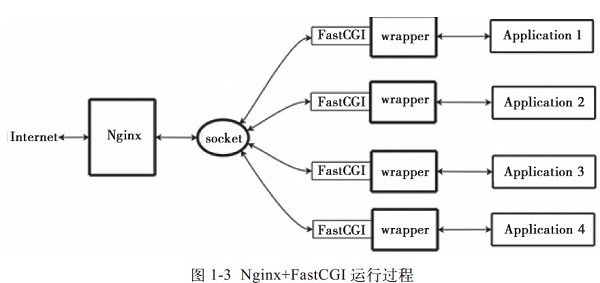
所以,我们首先需要一个wrapper,这个wrapper需要完成的工作:
- 通过调用fastcgi(库)的函数通过socket和ningx通信(读写socket是fastcgi内部实现的功能,对wrapper是非透明的)
- 调度thread,进行fork和kill
- 和application(php)进行通信
3、spawn-fcgi与PHP-FPM
FastCGI接口方式在脚本解析服务器上启动一个或者多个守护进程对动态脚本进行解析,这些进程就是FastCGI进程管理器,或者称为FastCGI引擎。 spawn-fcgi与PHP-FPM就是支持PHP的两个FastCGI进程管理器。 因此HTTPServer完全解放出来,可以更好地进行响应和并发处理。1)spawn-fcgi是HTTP服务器lighttpd的一部分,目前已经独立成为一个项目,一般与lighttpd配合使用来支持PHP。但是ligttpd的spwan-fcgi在高并发访问的时候,会出现内存泄漏甚至自动重启FastCGI的问题。即:PHP脚本处理器当机,这个时候如果用户访问的话,可能就会出现白页(即PHP不能被解析或者出错)。
由于spawn-fcgi的缺陷,现在出现了第三方(目前已经加入到PHP core中)的PHP的FastCGI处理器PHP-FPM,它和spawn-fcgi比较起来有如下优点:
由于它是作为PHP的patch补丁来开发的,安装的时候需要和php源码一起编译,也就是说编译到php core中了,因此在性能方面要优秀一些;
同时它在处理高并发方面也优于spawn-fcgi,至少不会自动重启fastcgi处理器。因此,推荐使用Nginx+PHP/PHP-FPM这个组合对PHP进行解析。
FastCGI 的主要优点是把动态语言和HTTP Server分离开来,所以Nginx与PHP/PHP-FPM经常被部署在不同的服务器上,以分担前端Nginx服务器的压力,使Nginx专一处理静态请求和转发动态请求,而PHP/PHP-FPM服务器专一解析PHP动态请求。
4、Nginx+PHP-FPM
PHP-FPM是管理FastCGI的一个管理器,它作为PHP的插件存在,在安装PHP要想使用PHP-FPM时在老php的老版本(php5.3.3之前)就需要把PHP-FPM以补丁的形式安装到PHP中,而且PHP要与PHP-FPM版本一致,这是必须的)
PHP-FPM其实是PHP源代码的一个补丁,旨在将FastCGI进程管理整合进PHP包中。必须将它patch到你的PHP源代码中,在编译安装PHP后才可以使用。
PHP5.3.3已经集成php-fpm了,不再是第三方的包了。PHP-FPM提供了更好的PHP进程管理方式,可以有效控制内存和进程、可以平滑重载PHP配置,比spawn-fcgi具有更多优点,所以被PHP官方收录了。在./configure的时候带 –enable-fpm参数即可开启PHP-FPM。
fastcgi已经在php5.3.5的core中了,不必在configure时添加 --enable-fastcgi了。老版本如php5.2的需要加此项。
当我们安装Nginx和PHP-FPM完后,配置信息:
root html;
fastcgi_pass 127.0.0.1:9000; 指定了fastcgi进程侦听的端口,nginx就是通过这里与php交互的
fastcgi_index index.php;
include fastcgi_params;
fastcgi_param SCRIPT_FILENAME /usr/local/nginx/html$fastcgi_script_name;
}
4. Nginx+PHP正确配置
一般web都做统一入口:把PHP请求都发送到同一个文件上,然后在此文件里通过解析「REQUEST_URI」实现路由。
Nginx配置文件分为好多块,常见的从外到内依次是「http」、「server」、「location」等等,缺省的继承关系是从外到内,也就是说内层块会自动获取外层块的值作为缺省值。
例如:
- server {
- listen 80;
- server_name foo.com;
- root /path;
- location / {
- index index.html index.htm index.php;
- if (!-e $request_filename) {
- rewrite . /index.php last;
- }
- }
- location ~ \.php$ {
- include fastcgi_params;
- fastcgi_param SCRIPT_FILENAME /path$fastcgi_script_name;
- fastcgi_pass 127.0.0.1:9000;
- fastcgi_index index.php;
- }
- }
1) 不应该在location 模块定义index
if (!-e $request_filename) {
rewrite . /index.php last;
}
很多人喜欢用「if」指令做一系列的检查,不过这实际上是「try_files」指令的职责:
try_files $uri $uri/ /index.php;
除此以外,初学者往往会认为「if」指令是内核级的指令,但是实际上它是rewrite模块的一部分,加上Nginx配置实际上是声明式的,而非过程式的,所以当其和非rewrite模块的指令混用时,结果可能会非你所愿。
3)fastcgi_params」配置文件:
include fastcgi_params;
Nginx有两份fastcgi配置文件,分别是「fastcgi_params」和「fastcgi.conf」,它们没有太大的差异,唯一的区别是后者比前者多了一行「SCRIPT_FILENAME」的定义:
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
注意:$document_root 和 $fastcgi_script_name 之间没有 /。
原本Nginx只有「fastcgi_params」,后来发现很多人在定义「SCRIPT_FILENAME」时使用了硬编码的方式,于是为了规范用法便引入了「fastcgi.conf」。
不过这样的话就产生一个疑问:为什么一定要引入一个新的配置文件,而不是修改旧的配置文件?这是因为「fastcgi_param」指令是数组型的,和普通指令相同的是:内层替换外层;和普通指令不同的是:当在同级多次使用的时候,是新增而不是替换。换句话说,如果在同级定义两次「SCRIPT_FILENAME」,那么它们都会被发送到后端,这可能会导致一些潜在的问题,为了避免此类情况,便引入了一个新的配置文件。
此外,我们还需要考虑一个安全问题:在PHP开启「cgi.fix_pathinfo」的情况下,PHP可能会把错误的文件类型当作PHP文件来解析。如果Nginx和PHP安装在同一台服务器上的话,那么最简单的解决方法是用「try_files」指令做一次过滤:
try_files $uri =404;
依照前面的分析,给出一份改良后的版本,是不是比开始的版本清爽了很多:
- server {
- listen 80;
- server_name foo.com;
- root /path;
- index index.html index.htm index.php;
- location / {
- try_files $uri $uri/ /index.php;
- }
- location ~ \.php$ {
- try_files $uri =404;
- include fastcgi.conf;
- fastcgi_pass 127.0.0.1:9000;
- }
- }
5. Nginx为啥性能高-多进程IO模型
参考http://mp.weixin.qq.com/s?__biz=MjM5NTg2NTU0Ng==&mid=407889757&idx=3&sn=cfa8a70a5fd2a674a91076f67808273c&scene=23&srcid=0401aeJQEraSG6uvLj69Hfve#rd
1、nginx采用多进程模型好处
首先,对于每个worker进程来说,独立的进程,不需要加锁,所以省掉了锁带来的开销,同时在编程以及问题查找时,也会方便很多。
其次,采用独立的进程,可以让互相之间不会影响,一个进程退出后,其它进程还在工作,服务不会中断,master进程则很快启动新的worker进程。当然,worker进程的异常退出,肯定是程序有bug了,异常退出,会导致当前worker上的所有请求失败,不过不会影响到所有请求,所以降低了风险。
1、nginx多进程事件模型:异步非阻塞
虽然nginx采用多worker的方式来处理请求,每个worker里面只有一个主线程,那能够处理的并发数很有限啊,多少个worker就能处理多少个并发,何来高并发呢?非也,这就是nginx的高明之处,nginx采用了异步非阻塞的方式来处理请求,也就是说,nginx是可以同时处理成千上万个请求的。一个worker进程可以同时处理的请求数只受限于内存大小,而且在架构设计上,不同的worker进程之间处理并发请求时几乎没有同步锁的限制,worker进程通常不会进入睡眠状态,因此,当Nginx上的进程数与CPU核心数相等时(最好每一个worker进程都绑定特定的CPU核心),进程间切换的代价是最小的。
而apache的常用工作方式(apache也有异步非阻塞版本,但因其与自带某些模块冲突,所以不常用),每个进程在一个时刻只处理一个请求,因此,当并发数上到几千时,就同时有几千的进程在处理请求了。这对操作系统来说,是个不小的挑战,进程带来的内存占用非常大,进程的上下文切换带来的cpu开销很大,自然性能就上不去了,而这些开销完全是没有意义的。

为什么nginx可以采用异步非阻塞的方式来处理呢,或者异步非阻塞到底是怎么回事呢?
我们先回到原点,看看一个请求的完整过程:首先,请求过来,要建立连接,然后再接收数据,接收数据后,再发送数据。
具体到系统底层,就是读写事件,而当读写事件没有准备好时,必然不可操作,如果不用非阻塞的方式来调用,那就得阻塞调用了,事件没有准备好,那就只能等了,等事件准备好了,你再继续吧。阻塞调用会进入内核等待,cpu就会让出去给别人用了,对单线程的worker来说,显然不合适,当网络事件越多时,大家都在等待呢,cpu空闲下来没人用,cpu利用率自然上不去了,更别谈高并发了。好吧,你说加进程数,这跟apache的线程模型有什么区别,注意,别增加无谓的上下文切换。所以,在nginx里面,最忌讳阻塞的系统调用了。不要阻塞,那就非阻塞喽。非阻塞就是,事件没有准备好,马上返回EAGAIN,告诉你,事件还没准备好呢,你慌什么,过会再来吧。好吧,你过一会,再来检查一下事件,直到事件准备好了为止,在这期间,你就可以先去做其它事情,然后再来看看事件好了没。虽然不阻塞了,但你得不时地过来检查一下事件的状态,你可以做更多的事情了,但带来的开销也是不小的。
关于IO模型:http://blog.csdn.net/hguisu/article/details/7453390
nginx支持的事件模型如下(nginx的wiki):
Nginx支持如下处理连接的方法(I/O复用方法),这些方法可以通过use指令指定。
- select– 标准方法。 如果当前平台没有更有效的方法,它是编译时默认的方法。你可以使用配置参数 –with-select_module 和 –without-select_module 来启用或禁用这个模块。
- poll– 标准方法。 如果当前平台没有更有效的方法,它是编译时默认的方法。你可以使用配置参数 –with-poll_module 和 –without-poll_module 来启用或禁用这个模块。
- kqueue– 高效的方法,使用于 FreeBSD 4.1+, OpenBSD 2.9+, NetBSD 2.0 和 MacOS X. 使用双处理器的MacOS X系统使用kqueue可能会造成内核崩溃。
- epoll – 高效的方法,使用于Linux内核2.6版本及以后的系统。在某些发行版本中,如SuSE 8.2, 有让2.4版本的内核支持epoll的补丁。
- rtsig – 可执行的实时信号,使用于Linux内核版本2.2.19以后的系统。默认情况下整个系统中不能出现大于1024个POSIX实时(排队)信号。这种情况 对于高负载的服务器来说是低效的;所以有必要通过调节内核参数 /proc/sys/kernel/rtsig-max 来增加队列的大小。可是从Linux内核版本2.6.6-mm2开始, 这个参数就不再使用了,并且对于每个进程有一个独立的信号队列,这个队列的大小可以用 RLIMIT_SIGPENDING 参数调节。当这个队列过于拥塞,nginx就放弃它并且开始使用 poll 方法来处理连接直到恢复正常。
- /dev/poll – 高效的方法,使用于 Solaris 7 11/99+, HP/UX 11.22+ (eventport), IRIX 6.5.15+ 和 Tru64 UNIX 5.1A+.
- eventport – 高效的方法,使用于 Solaris 10. 为了防止出现内核崩溃的问题, 有必要安装这个 安全补丁。
在linux下面,只有epoll是高效的方法
下面再来看看epoll到底是如何高效的
Epoll是Linux内核为处理大批量句柄而作了改进的poll。 要使用epoll只需要这三个系统调用:epoll_create(2), epoll_ctl(2), epoll_wait(2)。它是在2.5.44内核中被引进的(epoll(4) is a new API introduced in Linux kernel 2.5.44),在2.6内核中得到广泛应用。
epoll的优点
- 支持一个进程打开大数目的socket描述符(FD)
select 最不能忍受的是一个进程所打开的FD是有一定限制的,由FD_SETSIZE设置,默认值是2048。对于那些需要支持的上万连接数目的IM服务器来说显 然太少了。这时候你一是可以选择修改这个宏然后重新编译内核,不过资料也同时指出这样会带来网络效率的下降,二是可以选择多进程的解决方案(传统的 Apache方案),不过虽然linux上面创建进程的代价比较小,但仍旧是不可忽视的,加上进程间数据同步远比不上线程间同步的高效,所以也不是一种完 美的方案。不过 epoll则没有这个限制,它所支持的FD上限是最大可以打开文件的数目,这个数字一般远大于2048,举个例子,在1GB内存的机器上大约是10万左 右,具体数目可以cat /proc/sys/fs/file-max察看,一般来说这个数目和系统内存关系很大。
- IO效率不随FD数目增加而线性下降
传统的select/poll另一个致命弱点就是当你拥有一个很大的socket集合,不过由于网络延时,任一时间只有部分的socket是”活跃”的,但 是select/poll每次调用都会线性扫描全部的集合,导致效率呈现线性下降。但是epoll不存在这个问题,它只会对”活跃”的socket进行操 作—这是因为在内核实现中epoll是根据每个fd上面的callback函数实现的。那么,只有”活跃”的socket才会主动的去调用 callback函数,其他idle状态socket则不会,在这点上,epoll实现了一个”伪”AIO,因为这时候推动力在os内核。在一些 benchmark中,如果所有的socket基本上都是活跃的—比如一个高速LAN环境,epoll并不比select/poll有什么效率,相 反,如果过多使用epoll_ctl,效率相比还有稍微的下降。但是一旦使用idle connections模拟WAN环境,epoll的效率就远在select/poll之上了。
- 使用mmap加速内核与用户空间的消息传递。
这 点实际上涉及到epoll的具体实现了。无论是select,poll还是epoll都需要内核把FD消息通知给用户空间,如何避免不必要的内存拷贝就很 重要,在这点上,epoll是通过内核于用户空间mmap同一块内存实现的。而如果你想我一样从2.5内核就关注epoll的话,一定不会忘记手工 mmap这一步的。
- 内核微调
这一点其实不算epoll的优点了,而是整个linux平台的优点。也许你可以怀疑linux平台,但是你无法回避linux平台赋予你微调内核的能力。比如,内核TCP/IP协 议栈使用内存池管理sk_buff结构,那么可以在运行时期动态调整这个内存pool(skb_head_pool)的大小— 通过echo XXXX>/proc/sys/net/core/hot_list_length完成。再比如listen函数的第2个参数(TCP完成3次握手 的数据包队列长度),也可以根据你平台内存大小动态调整。更甚至在一个数据包面数目巨大但同时每个数据包本身大小却很小的特殊系统上尝试最新的NAPI网卡驱动架构。
(epoll内容,参考epoll_互动百科)
推荐设置worker的个数为cpu的核数,在这里就很容易理解了,更多的worker数,只会导致进程来竞争cpu资源了,从而带来不必要的上下文切换。而且,nginx为了更好的利用多核特性,提供了cpu亲缘性的绑定选项,我们可以将某一个进程绑定在某一个核上,这样就不会因为进程的切换带来cache的失效。像这种小的优化在nginx中非常常见,同时也说明了nginx作者的苦心孤诣。比如,nginx在做4个字节的字符串比较时,会将4个字符转换成一个int型,再作比较,以减少cpu的指令数等等。
代码来总结一下nginx的事件处理模型:
- while (true) {
- for t in run_tasks:
- t.handler();
- update_time(&now);
- timeout = ETERNITY;
- for t in wait_tasks: /* sorted already */
- if (t.time <= now) {
- t.timeout_handler();
- } else {
- timeout = t.time - now;
- break;
- }
- nevents = poll_function(events, timeout);
- for i in nevents:
- task t;
- if (events[i].type == READ) {
- t.handler = read_handler;
- } else { /* events[i].type == WRITE */
- t.handler = write_handler;
- }
- run_tasks_add(t);
- }
6. Nginx优化
1. 编译安装过程优化
1).减小Nginx编译后的文件大小
在编译Nginx时,默认以debug模式进行,而在debug模式下会插入很多跟踪和ASSERT之类的信息,编译完成后,一个Nginx要有好几兆字节。而在编译前取消Nginx的debug模式,编译完成后Nginx只有几百千字节。因此可以在编译之前,修改相关源码,取消debug模式。具体方法如下:
在Nginx源码文件被解压后,找到源码目录下的auto/cc/gcc文件,在其中找到如下几行:
- # debug
- CFLAGS=”$CFLAGS -g”
注释掉或删掉这两行,即可取消debug模式。
2.为特定的CPU指定CPU类型编译优化
在编译Nginx时,默认的GCC编译参数是“-O”,要优化GCC编译,可以使用以下两个参数:
- --with-cc-opt='-O3'
- --with-cpu-opt=CPU #为特定的 CPU 编译,有效的值包括:
pentium, pentiumpro, pentium3, # pentium4, athlon, opteron, amd64, sparc32, sparc64, ppc64
要确定CPU类型,可以通过如下命令:
- [root@localhost home]#cat /proc/cpuinfo | grep "model name"
2. 利用TCMalloc优化Nginx的性能
TCMalloc的全称为Thread-Caching Malloc,是谷歌开发的开源工具google-perftools中的一个成员。与标准的glibc库的Malloc相比,TCMalloc库在内存分配效率和速度上要高很多,这在很大程度上提高了服务器在高并发情况下的性能,从而降低了系统的负载。下面简单介绍如何为Nginx添加TCMalloc库支持。
要安装TCMalloc库,需要安装libunwind(32位操作系统不需要安装)和google-perftools两个软件包,libunwind库为基于64位CPU和操作系统的程序提供了基本函数调用链和函数调用寄存器功能。下面介绍利用TCMalloc优化Nginx的具体操作过程。
1).安装libunwind库
可以从http://download.savannah.gnu.org/releases/libunwind下载相应的libunwind版本,这里下载的是libunwind-0.99-alpha.tar.gz。安装过程如下:
- [root@localhost home]#tar zxvf libunwind-0.99-alpha.tar.gz
- [root@localhost home]# cd libunwind-0.99-alpha/
- [root@localhost libunwind-0.99-alpha]#CFLAGS=-fPIC ./configure
- [root@localhost libunwind-0.99-alpha]#make CFLAGS=-fPIC
- [root@localhost libunwind-0.99-alpha]#make CFLAGS=-fPIC install
2).安装google-perftools
可以从http://google-perftools.googlecode.com下载相应的google-perftools版本,这里下载的是google-perftools-1.8.tar.gz。安装过程如下:
- [root@localhost home]#tar zxvf google-perftools-1.8.tar.gz
- [root@localhost home]#cd google-perftools-1.8/
- [root@localhost google-perftools-1.8]# ./configure
- [root@localhost google-perftools-1.8]#make && make install
- [root@localhost google-perftools-1.8]#echo "/usr/
local/lib" > /etc/ld.so.conf.d/usr_local_lib.conf- [root@localhost google-perftools-1.8]# ldconfig
至此,google-perftools安装完成。
3).重新编译Nginx
为了使Nginx支持google-perftools,需要在安装过程中添加“–with-google_perftools_module”选项重新编译Nginx。安装代码如下:
- [root@localhostnginx-0.7.65]#./configure \
- >--with-google_perftools_module --with-http_stub_status_module --prefix=/opt/nginx
- [root@localhost nginx-0.7.65]#make
- [root@localhost nginx-0.7.65]#make install
到这里Nginx安装完成。
4).为google-perftools添加线程目录
创建一个线程目录,这里将文件放在/tmp/tcmalloc下。操作如下:
- [root@localhost home]#mkdir /tmp/tcmalloc
- [root@localhost home]#chmod 0777 /tmp/tcmalloc
5).修改Nginx主配置文件
修改nginx.conf文件,在pid这行的下面添加如下代码:
- #pid logs/nginx.pid;
- google_perftools_profiles /tmp/tcmalloc;
接着,重启Nginx即可完成google-perftools的加载。
6).验证运行状态
为了验证google-perftools已经正常加载,可通过如下命令查看:
- [root@ localhost home]# lsof -n | grep tcmalloc
- nginx 2395 nobody 9w REG 8,8 0 1599440 /tmp/tcmalloc.2395
- nginx 2396 nobody 11w REG 8,8 0 1599443 /tmp/tcmalloc.2396
- nginx 2397 nobody 13w REG 8,8 0 1599441 /tmp/tcmalloc.2397
- nginx 2398 nobody 15w REG 8,8 0 1599442 /tmp/tcmalloc.2398
由于在Nginx配置文件中设置worker_processes的值为4,因此开启了4个Nginx线程,每个线程会有一行记录。每个线程文件后面的数字值就是启动的Nginx的pid值。
至此,利用TCMalloc优化Nginx的操作完成。
3.Nginx内核参数优化
内核参数的优化,主要是在Linux系统中针对Nginx应用而进行的系统内核参数优化。
下面给出一个优化实例以供参考。
- net.ipv4.tcp_max_tw_buckets = 6000
- net.ipv4.ip_local_port_range = 1024 65000
- net.ipv4.tcp_tw_recycle = 1
- net.ipv4.tcp_tw_reuse = 1
- net.ipv4.tcp_syncookies = 1
- net.core.somaxconn = 262144
- net.core.netdev_max_backlog = 262144
- net.ipv4.tcp_max_orphans = 262144
- net.ipv4.tcp_max_syn_backlog = 262144
- net.ipv4.tcp_synack_retries = 1
- net.ipv4.tcp_syn_retries = 1
- net.ipv4.tcp_fin_timeout = 1
- net.ipv4.tcp_keepalive_time = 30
将上面的内核参数值加入/etc/sysctl.conf文件中,然后执行如下命令使之生效:
- [root@ localhost home]#/sbin/sysctl -p
下面对实例中选项的含义进行介绍:
TCP参数设置:
net.ipv4.tcp_max_tw_buckets :选项用来设定timewait的数量,默认是180 000,这里设为6000。
net.ipv4.ip_local_port_range:选项用来设定允许系统打开的端口范围。在高并发情况否则端口号会不够用。当NGINX充当代理时,每个到上游服务器的连接都使用一个短暂或临时端口。
net.ipv4.tcp_tw_recycle:选项用于设置启用timewait快速回收.
net.ipv4.tcp_tw_reuse:选项用于设置开启重用,允许将TIME-WAIT sockets重新用于新的TCP连接。
net.ipv4.tcp_syncookies:选项用于设置开启SYN Cookies,当出现SYN等待队列溢出时,启用cookies进行处理。
net.ipv4.tcp_max_orphans:选项用于设定系统中最多有多少个TCP套接字不被关联到任何一个用户文件句柄上。如果超过这个数字,孤立连接将立即被复位并打印出警告信息。这个限制只是为了防止简单的DoS攻击。不能过分依靠这个限制甚至人为减小这个值,更多的情况下应该增加这个值。
net.ipv4.tcp_max_syn_backlog:选项用于记录那些尚未收到客户端确认信息的连接请求的最大值。对于有128MB内存的系统而言,此参数的默认值是1024,对小内存的系统则是128。
net.ipv4.tcp_synack_retries参数的值决定了内核放弃连接之前发送SYN+ACK包的数量。
net.ipv4.tcp_syn_retries选项表示在内核放弃建立连接之前发送SYN包的数量。
net.ipv4.tcp_fin_timeout选项决定了套接字保持在FIN-WAIT-2状态的时间。默认值是60秒。正确设置这个值非常重要,有时即使一个负载很小的Web服务器,也会出现大量的死套接字而产生内存溢出的风险。
net.ipv4.tcp_syn_retries选项表示在内核放弃建立连接之前发送SYN包的数量。
如果发送端要求关闭套接字,net.ipv4.tcp_fin_timeout选项决定了套接字保持在FIN-WAIT-2状态的时间。接收端可以出错并永远不关闭连接,甚至意外宕机。
net.ipv4.tcp_fin_timeout的默认值是60秒。需要注意的是,即使一个负载很小的Web服务器,也会出现因为大量的死套接字而产生内存溢出的风险。FIN-WAIT-2的危险性比FIN-WAIT-1要小,因为它最多只能消耗1.5KB的内存,但是其生存期长些。
net.ipv4.tcp_keepalive_time选项表示当keepalive启用的时候,TCP发送keepalive消息的频度。默认值是2(单位是小时)。
缓冲区队列:
net.core.somaxconn:选项的默认值是128, 这个参数用于调节系统同时发起的tcp连接数,在高并发的请求中,默认的值可能会导致链接超时或者重传,因此,需要结合并发请求数来调节此值。
由NGINX可接受的数目决定。默认值通常很低,但可以接受,因为NGINX 接收连接非常快,但如果网站流量大时,就应该增加这个值。内核日志中的错误消息会提醒这个值太小了,把值改大,直到错误提示消失。
注意: 如果设置这个值大于512,相应地也要改变NGINX listen指令的backlog参数。
net.core.netdev_max_backlog:选项表示当每个网络接口接收数据包的速率比内核处理这些包的速率快时,允许发送到队列的数据包的最大数目。
4. PHP-FPM的优化
如果您高负载网站使用PHP-FPM管理FastCGI,这些技巧也许对您有用:
1)增加FastCGI进程数
把PHP FastCGI子进程数调到100或以上,在4G内存的服务器上200就可以建议通过压力测试获取最佳值。
2)增加 PHP-FPM打开文件描述符的限制
标签rlimit_files用于设置PHP-FPM对打开文件描述符的限制,默认值为1024。这个标签的值必须和Linux内核打开文件数关联起来,例如,要将此值设置为65 535,就必须在Linux命令行执行“ulimit -HSn 65536”。
然后 增加 PHP-FPM打开文件描述符的限制:
# vi /path/to/php-fpm.conf
找到“
重启 PHP-FPM.
ulimit -n 要调整为65536甚至更大。如何调这个参数,可以参考网上的一些文章。命令行下执行 ulimit -n65536即可修改。如果不能修改,需要设置 /etc/security/limits.conf,加入
* hard nofile65536
* soft nofile 65536
3)适当增加max_requests
标签max_requests指明了每个children最多处理多少个请求后便会被关闭,默认的设置是500。
4.nginx.conf的参数优化
nginx要开启的进程数 一般等于cpu的总核数 其实一般情况下开4个或8个就可以。
每个nginx进程消耗的内存10兆的模样
worker_cpu_affinity
仅适用于linux,使用该选项可以绑定worker进程和CPU(2.4内核的机器用不了)
假如是8 cpu 分配如下:
worker_cpu_affinity 00000001 00000010 00000100 00001000 00010000
00100000 01000000 10000000
nginx可以使用多个worker进程,原因如下:
to use SMP
to decrease latency when workers blockend on disk I/O
to limit number of connections per process when select()/poll() is
used The worker_processes and worker_connections from the event sections
allows you to calculate maxclients value: k max_clients = worker_processes * worker_connections
worker_rlimit_nofile 102400;
每个nginx进程打开文件描述符最大数目 配置要和系统的单进程打开文件数一致,linux 2.6内核下开启文件打开数为65535,worker_rlimit_nofile就相应应该填写65535 nginx调度时分配请求到进程并不是那么的均衡,假如超过会返回502错误。我这里写的大一点
use epoll
Nginx使用了最新的epoll(Linux 2.6内核)和kqueue(freebsd)网络I/O模型,而Apache则使用的是传统的select模型。
处理大量的连接的读写,Apache所采用的select网络I/O模型非常低效。在高并发服务器中,轮询I/O是最耗时间的操作 目前Linux下能够承受高并发
访问的Squid、Memcached都采用的是epoll网络I/O模型。
worker_processes
NGINX工作进程数(默认值是1)。在大多数情况下,一个CPU内核运行一个工作进程最好,建议将这个指令设置成自动就可以。有时可能想增大这个值,比如当工作进程需要做大量的磁盘I/O。
worker_connections 65535;
每个工作进程允许最大的同时连接数 (Maxclient = work_processes * worker_connections)
keepalive_timeout 75
keepalive超时时间
这里需要注意官方的一句话:
The parameters can differ from each other. Line Keep-Alive:
timeout=time understands Mozilla and Konqueror. MSIE itself shuts
keep-alive connection approximately after 60 seconds.
client_header_buffer_size 16k
large_client_header_buffers 4 32k
客户请求头缓冲大小
nginx默认会用client_header_buffer_size这个buffer来读取header值,如果header过大,它会使用large_client_header_buffers来读取
如果设置过小HTTP头/Cookie过大 会报400 错误 nginx 400 bad request
求行如果超过buffer,就会报HTTP 414错误(URI Too Long) nginx接受最长的HTTP头部大小必须比其中一个buffer大,否则就会报400的HTTP错误(Bad Request)。
open_file_cache max 102400
使用字段:http, server, location 这个指令指定缓存是否启用,如果启用,将记录文件以下信息: ·打开的文件描述符,大小信息和修改时间. ·存在的目录信息. ·在搜索文件过程中的错误信息 -- 没有这个文件,无法正确读取,参考open_file_cache_errors 指令选项:
·max - 指定缓存的最大数目,如果缓存溢出,最长使用过的文件(LRU)将被移除
例: open_file_cache max=1000 inactive=20s; open_file_cache_valid 30s; open_file_cache_min_uses 2; open_file_cache_errors on;
open_file_cache_errors
语法:open_file_cache_errors on | off 默认值:open_file_cache_errors off 使用字段:http, server, location 这个指令指定是否在搜索一个文件是记录cache错误.
open_file_cache_min_uses
语法:open_file_cache_min_uses number 默认值:open_file_cache_min_uses 1 使用字段:http, server, location 这个指令指定了在open_file_cache指令无效的参数中一定的时间范围内可以使用的最小文件数,如 果使用更大的值,文件描述符在cache中总是打开状态.
open_file_cache_valid
语法:open_file_cache_valid time 默认值:open_file_cache_valid 60 使用字段:http, server, location 这个指令指定了何时需要检查open_file_cache中缓存项目的有效信息.
开启gzip
gzip on;
gzip_min_length 1k;
gzip_buffers 4 16k;
gzip_http_version 1.0;
gzip_comp_level 2;
gzip_types text/plain application/x-JavaScript text/css
application/xml;
gzip_vary on;
缓存静态文件:
location ~* ^.+\.(swf|gif|png|jpg|js|css)$ {
root /usr/local/ku6/ktv/show.ku6.com/;
expires 1m;
}
5.访问日志
记录每个请求会消耗CPU和I/O周期,一种降低这种影响的方式是缓冲访问日志。使用缓冲,而不是每条日志记录都单独执行写操作,NGINX会缓冲一连串的日志记录,使用单个操作把它们一起写到文件中。
要启用访问日志的缓存,就涉及到在access_log指令中buffer=size这个参数。当缓冲区达到size值时,NGINX会把缓冲区的内容写到日志中。让NGINX在指定的一段时间后写缓存,就包含flush=time参数。当两个参数都设置了,当下个日志条目超出缓冲区值或者缓冲区中日志条目存留时间超过设定的时间值,NGINX都会将条目写入日志文件。当工作进程重新打开它的日志文件或退出时,也会记录下来。要完全禁用访问日志记录的功能,将access_log 指令设置成off参数。
6.限流
你可以设置多个限制,防止用户消耗太多的资源,避免影响系统性能和用户体验及安全。 以下是相关的指令:
limit_conn and limit_conn_zone:NGINX接受客户连接的数量限制,例如单个IP地址的连接。设置这些指令可以防止单个用户打开太多的连接,消耗超出自己的资源。
limit_rate:传输到客户端响应速度的限制(每个打开多个连接的客户消耗更多的带宽)。设置这个限制防止系统过载,确保所有客户端更均匀的服务质量。
limit_req and limit_req_zone:NGINX处理请求的速度限制,与limit_rate有相同的功能。可以提高安全性,尤其是对登录页面,通过对用户限制请求速率设置一个合理的值,避免太慢的程序覆盖你的应用请求(比如DDoS攻击)。
max_conns:上游配置块中服务器指令参数。在上游服务器组中单个服务器可接受最大并发数量。使用这个限制防止上游服务器过载。设置值为0(默认值)表示没有限制。
queue (NGINX Plus) :创建一个队列,用来存放在上游服务器中超出他们最大max_cons限制数量的请求。这个指令可以设置队列请求的最大值,还可以选择设置在错误返回之前最大等待时间(默认值是60秒)。如果忽略这个指令,请求不会放入队列。
7. 错误排查
1、Nginx 502 Bad Gateway
一般来说Nginx 502 Bad Gateway和php-fpm.conf的设置有关,而Nginx 504 Gateway Time-out则是与nginx.conf的设置有关
1)、查看当前的PHP FastCGI进程数是否够用:
netstat -anpo | grep "php-cgi" | wc -l
如果实际使用的“FastCGI进程数”接近预设的“FastCGI进程数”,那么,说明“FastCGI进程数”不够用,需要增大。
2)、部分PHP程序的执行时间超过了Nginx的等待时间,可以适当增加
nginx.conf配置文件中FastCGI的timeout时间,例如:
http {
......
fastcgi_connect_timeout 300;
fastcgi_send_timeout 300;
fastcgi_read_timeout 300;
......
}
2、413 Request Entity Too Large
解决:增大client_max_body_size
client_max_body_size:指令指定允许客户端连接的最大请求实体大小,它出现在请求头部的Content-Length字段. 如果请求大于指定的值,客户端将收到一个"Request Entity Too Large" (413)错误. 记住,浏览器并不知道怎样显示这个错误.
php.ini中增大
post_max_size 和upload_max_filesize
3 Ngnix error.log出现:upstream sent too big header while reading response header from upstream错误
1)如果是nginx反向代理
proxy是nginx作为client转发时使用的,如果header过大,超出了默认的1k,就会引发上述的upstream sent too big header (说白了就是nginx把外部请求给后端server,后端server返回的header 太大nginx处理不过来就导致了。
server {
listen 80;
server_name *.xywy.com ;
large_client_header_buffers 4 16k;
location / {
#添加这3行
proxy_buffer_size 64k;
proxy_buffers 32 32k;
proxy_busy_buffers_size 128k;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
}
2) 如果是 nginx+PHPcgi
错误带有 upstream: "fastcgi://127.0.0.1:9000"。就该
多加:
fastcgi_buffer_size 128k;
fastcgi_buffers 4 128k;
server {
listen 80;
server_name ddd.com;
index index.html index.htm index.php;
client_header_buffer_size 128k;
large_client_header_buffers 4 128k;
proxy_buffer_size 64k;
proxy_buffers 8 64k;
fastcgi_buffer_size 128k;
fastcgi_buffers 4 128k;
location / {
......
}
}
8. Nginx的php漏洞
漏洞介绍:nginx是一款高性能的web服务器,使用非常广泛,其不仅经常被用作反向代理,也可以非常好的支持PHP的运行。80sec发现其中存在一个较为严重的安全问题,默认情况下可能导致服务器错误的将任何类型的文件以PHP的方式进行解析,这将导致严重的安全问题,使得恶意的攻击者可能攻陷支持php的nginx服务器。
漏洞分析:nginx默认以cgi的方式支持php的运行,譬如在配置文件当中可以以
的方式支持对php的解析,location对请求进行选择的时候会使用URI环境变量进行选择,其中传递到后端Fastcgi的关键变量SCRIPT_FILENAME由nginx生成的$fastcgi_script_name决定,而通过分析可以看到$fastcgi_script_name是直接由URI环境变量控制的,这里就是产生问题的点。而为了较好的支持PATH_INFO的提取,在PHP的配置选项里存在cgi.fix_pathinfo选项,其目的是为了从SCRIPT_FILENAME里取出真正的脚本名。
那么假设存在一个http://www.80sec.com/80sec.jpg,我们以如下的方式去访问
http://www.80sec.com/80sec.jpg/80sec.php
将会得到一个URI
经过location指令,该请求将会交给后端的fastcgi处理,nginx为其设置环境变量SCRIPT_FILENAME,内容为
而在其他的webserver如lighttpd当中,我们发现其中的SCRIPT_FILENAME被正确的设置为
所以不存在此问题。
后端的fastcgi在接受到该选项时,会根据fix_pathinfo配置决定是否对SCRIPT_FILENAME进行额外的处理,一般情况下如果不对fix_pathinfo进行设置将影响使用PATH_INFO进行路由选择的应用,所以该选项一般配置开启。Php通过该选项之后将查找其中真正的脚本文件名字,查找的方式也是查看文件是否存在,这个时候将分离出SCRIPT_FILENAME和PATH_INFO分别为
最后,以/scripts/80sec.jpg作为此次请求需要执行的脚本,攻击者就可以实现让nginx以php来解析任何类型的文件了。
POC: 访问一个nginx来支持php的站点,在一个任何资源的文件如robots.txt后面加上/80sec.php,这个时候你可以看到如下的区别:
访问http://www.80sec.com/robots.txt
访问访问http://www.80sec.com/robots.txt/80sec.php
其中的Content-Type的变化说明了后端负责解析的变化,该站点就可能存在漏洞。
漏洞厂商:http://www.nginx.org
解决方案:
我们已经尝试联系官方,但是此前你可以通过以下的方式来减少损失
或者
PS: 鸣谢laruence大牛在分析过程中给的帮助
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
1. B/S交互过程
浏览器(Browser)和服务器(Web Server)的交互过程:
1、 浏览器向服务器发出HTTP请求(Request)。
2、 服务器收到浏览器的请求数据,经过分析处理,向浏览器输出响应数据(Response)。
3、 浏览器收到服务器的响应数据,经过分析处理,将最终结果显示在浏览器中。
下图是一份浏览器请求数据和服务器响应数据的快照:
关于浏览器和服务器数据交互过程非常简单,很容易理解。我想从事Web开发的人员都很清楚,在此不再赘述,仅供参考。
2. Apache概述
Apache是目前世界上使用最为广泛的一种Web Server,它以跨平台、高效和稳定而闻名。按照去年官方统计的数据,Apache服务器的装机量占该市场60%以上的份额。尤其是在 X(Unix/Linux)平台上,Apache是最常见的选择。其它的Web Server产品,比如IIS,只能运行在Windows平台上,是基于微软.Net架构技术的不二选择。
Apache并不是没有缺点,它最为诟病的一点就是变得越来越重,被普遍认为是重量级的 WebServer。所以,近年来又涌现出了很多轻量级的替代产品,比如lighttpd,nginx等等,这些WebServer的优点是运行效率很 高,但缺点也很明显,成熟度往往要低于Apache,通常只能用于某些特定场合,。
3. Apache组件逻辑图
Apache是基于模块化设计的,总体上看起来代码的可读性高于PHP的代码,它的核心代码 并不多,大多数的功能都被分散到各个模块中,各个模块在系统启动的时候按需载入。你如果想要阅读Apache的源代码,建议你直接从main.c文件读 起,系统最主要的处理逻辑都包含在里面。MPM(Multi -Processing Modules,多重处理模块)是Apache的核心组件之 一,Apache通过MPM来使用操作系统的资源,对进程和线程池进行管理。Apache为了能够获得最好的运行性能,针对不同的平台 (Unix/Linux、Window)做了优化,为不同的平台提供了不同的MPM,用户可以根据实际情况进行选择,其中最常使用的MPM有 prefork和worker两种。至于您的服务器正以哪种方式运行,取决于安装Apache过程中指定的MPM编译参数,在X系统上默认的编译参数为 prefork。由于大多数的Unix都不支持真正的线程,所以采用了预派生子进程(prefork)方式,象Windows或者Solaris这些支持 线程的平台,基于多进程多线程混合的worker模式是一种不错的选择。对此感兴趣的同学可以阅读有关资料,此处不再多讲。Apache中还有一个重要的 组件就是APR(Apache portable Runtime Library),即Apache可移植运行库,它是一个对操作系统调用的抽象库,用来实现Apache内部组件对操作系统的使用,提高系统的可移植性。 Apache对于php的解析,就是通过众多Module中的php Module来完成的。
Apache的逻辑构成以及与操作系统的关系
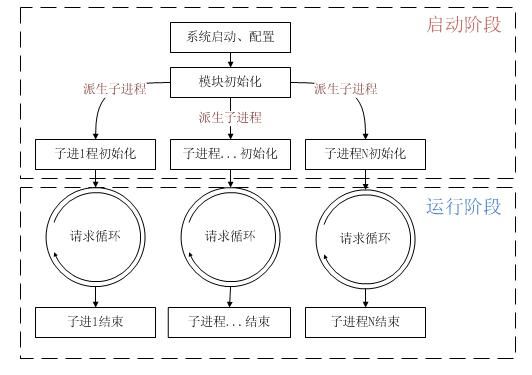
4. Apache的生命周期
这一节的内容会与php模块的载入有关,您可以略微关注一下。以下是Apache的生命周期(prefork模式)示意图。
5. Apache的两种工作模式
Apache服务的两种工作模式:prefork和worker
prefork的工作原理及配置
如果不用“--with-mpm”显式指定某种MPM,prefork就是Unix平台上缺省的MPM。它所采用的预派生子进程方式也是Apache 1.3中采用的模式。prefork本身并没有使用到线程,2.0版使用它是为了与1.3版保持兼容性;另一方面,prefork用单独的子进程来处理不同的请求,进程之间是彼此独立的,这也使其成为最稳定的MPM之一。
若使用prefork,在make编译和make install安装后,使用“httpd -l”来确定当前使用的MPM,应该会看到prefork.c(如果看到worker.c说明使用的是worker MPM,依此类推)。再查看缺省生成的httpd.conf配置文件,里面包含如下配置段:
-
- StartServers 5
- MinSpareServers 5
- MaxSpareServers 10
- MaxClients 150
- MaxRequestsPerChild 0
prefork的具体工作原理是,控制进程在最初建立“StartServers”个子进程后,为了满足MinSpareServers设置的需要创建一个进程,等待一秒钟,继续创建两个,再等待一秒钟,继续创建四个……如此按指数级增加创建的进程数,最多达到每秒32个,直到满足MinSpareServers设置的值为止。这就是预派生(prefork)的由来。这种模式可以不必在请求到来时再产生新的进程,从而减小了系统开销以增加性能。
当并发量请求数到达MaxClients(如256)时,而空闲进程只有10个。apache为继续增加创建进程。直到进程数到达256个。
当并发量高峰期过去了,并发请求数可能只有一个时,apache逐渐删除进程,直到进程数到达MaxSpareServers为止。
StartServers:指定服务器启动时建立的子进程数量,prefork默认为5。
MinSpareServers :指定空闲子进程的最小数量,默认为5。假如当前空闲子进程数少于MinSpareServers ,那么Apache将以最大每秒一个的速度产生新的子进程。此参数不要设的太大。
MaxSpareServers:设置了最大的空闲进程数,默认为10。如果空闲进程数大于这个值,Apache父进程会自动kill掉一些多余子进程。这个值不要设得过大,但如果设的值比MinSpareServers小,Apache会自动把其调整为MinSpareServers+1。如果站点负载较大,可考虑同时加大MinSpareServers和MaxSpareServers。
MaxRequestsPerChild:设置的是每个子进程可处理的请求数。每个子进程在处理了“MaxRequestsPerChild”个请求后将自动销毁。0意味着无限,即子进程永不销毁。虽然缺省设为0可以使每个子进程处理更多的请求,但如果设成非零值也有两点重要的好处:
◆ 可防止意外的内存泄漏;
◆ 在服务器负载下降的时侯会自动减少子进程数。
因此,可根据服务器的负载来调整这个值。个人认为10000左右比较合适。
MaxClients:是这些指令中最为重要的一个,设定的是Apache可以同时处理的请求,是对Apache性能影响最大的参数。
其缺省值150是远远不够的,如果请求总数已达到这个值(可通过ps -ef|grep http|wc -l来确认),那么后面的请求就要排队,直到某个已处理请求完毕。这就是系统资源还剩下很多而HTTP访问却很慢的主要原因。系统管理员可以根据硬件配置和负载情况来动态调整这个值。
虽然理论上这个值越大,可以处理的请求就越多,但在Apache1.3默认的最大只能设置为256(这是个硬限制)。如果把这个值设为大于256,那么Apache将无法起动。事实上,256对于负载稍重的站点也是不够的。如果要加大这个值,必须在“configure”前手工修改的源代码树下的src/include/httpd.h中查找256,就会发现“#define HARD_SERVER_LIMIT 256”这行。把256改为要增大的值(如4000),然后重新编译Apache即可。
但在Apache 2.0中,新加入了ServerLimit指令,可以突破最大请求数为256的限制。 使得无须重编译Apache就可以加大MaxClients。下面是prefork配置段:
-
- ServerLimit 2000
- StartServers 10
- MinSpareServers 10
- MaxSpareServers 15
- MaxClients 1000
- MaxRequestsPerChild 10000
ServerLimit:上述配置中,ServerLimit的最大值是2000,对于大多数站点已经足够。如果一定要再加大这个数值,对位于源代码树下server/mpm/prefork/prefork.c中以下两行做相应修改即可:
- #define DEFAULT_SERVER_LIMIT 256
- #define MAX_SERVER_LIMIT 2000
此时必须 MaxClients ≤ ServerLimit ≤ 2000. 即prefork的默认并发量最大是2000。
ServerLimit 生效前提:必须放在其他指令的前面,同时要想改变这个硬限制必须完全停止服务器然后再启动服务器(直接重启是不行的)。
worker的工作原理及配置
工作原理:每个进程能够拥有的线程数量是固定的。服务器会根据负载情况增加或减少进程数量。一个单独的控制进程(父进程)负责子进程的建立。每个子进程能够建立ThreadsPerChild数量的服务线程和一个监听线程,该监听线程监听接入请求并将其传递给服务线程处理和应答。Apache总是试图维持一个备用(spare)或是空闲的服务线程池。这样,客户端无须等待新线程或新进程的建立即可得到处理。在Unix中,为了能够绑定80端口,父进程一般都是以root身份启动,随后,Apache以较低权限的用户建立子进程和线程。User和Group指令用于配置Apache子进程的权限。虽然子进程必须对其提供的内容拥有读权限,但应该尽可能给予他较少的特权。另外,除非使用了suexec ,否则,这些指令配置的权限将被CGI脚本所继承。
相对于prefork,worker是2.0 版中全新的支持多线程和多进程混合模型的MPM。由于使用线程来处理,所以可以处理相对海量的请求,而系统资源的开销要小于基于进程的服务器。但是,worker也使用了多进程,每个进程又生成多个线程,以获得基于进程服务器的稳定性。这种MPM的工作方式将是Apache 2.0的发展趋势。
在configure -with-mpm=worker后,进行make编译、make install安装。在缺省生成的httpd.conf中有以下配置段:
-
- StartServers 2
- MaxClients 150
- MinSpareThreads 25
- MaxSpareThreads 75
- ThreadsPerChild 25
- MaxRequestsPerChild 0
worker的工作原理是:由主控制进程生成“StartServers”个子进程,每个子进程中包含固定的ThreadsPerChild线程数,各个线程独立地处理请求。同样,为了不在请求到来时再生成线程,MinSpareThreads和MaxSpareThreads设置了最少和最多的空闲线程数;而MaxClients设置了所有子进程中的线程总数。如果现有子进程中的线程总数不能满足负载,控制进程将派生新的子进程。
StartServers:服务器启动时建立的子进程数,默认值是"3"。
ServerLimit:服务器允许配置的进程数上限。这个指令和ThreadLimit结合使用配置了MaxClients最大允许配置的数值。任何在重启期间对这个指令的改变都将被忽略,但对MaxClients的修改却会生效。
MinSpareThreads :最小空闲线程数,默认值是"75"。这个MPM将基于整个服务器监控空闲线程数。假如服务器中总的空闲线程数太少,子进程将产生新的空闲线程。
MaxSpareThreads:配置最大空闲线程数。默认值是"250"。这个MPM将基于整个服务器监控空闲线程数。假如服 务器中总的空闲线程数太多,子进程将杀死多余的空闲线程。MaxSpareThreads的取值范围是有限制的。Apache将按照如下限制自动修正您配置的值:worker需要其大于等于MinSpareThreads加上ThreadsPerChild的和
MinSpareThreads和MaxSpareThreads这两个参数对Apache的性能影响并不大,可以按照实际情况相应调节。
ThreadLimit:每个子进程可配置的线程数上限。这个指令配置了每个子进程可配置的线程数ThreadsPerChild上限。任何在重启期间对这个指令的改变都将被忽略,但对ThreadsPerChild的修改却会生效。默认值是"64".
ThreadsPerChild:是worker MPM中与性能相关最密切的指令。ThreadsPerChild的最大缺省值是64。如果负载较大,64也是不够的。这时要显式使用ThreadLimit指令,它的最大缺省值是20000。上述两个值位于源码树server/mpm/worker/worker.c中的以下两行:
- #define DEFAULT_THREAD_LIMIT 64
- #define MAX_THREAD_LIMIT 20000
这两行对应着ThreadsPerChild和ThreadLimit的限制数。最好在configure之前就把64改成所希望的值。注意,不要把这两个值设得太高,超过系统的处理能力,从而因Apache不起动使系统很不稳定。
Worker模式下所能同时处理的请求总数是由子进程总数乘以ThreadsPerChild值决定的,应该大于等于MaxClients。如果负载很大,现有的子进程数不能满足时,控制进程会派生新的子进程。默认最大的子进程总数是16,加大时也需要显式声明ServerLimit(最大值是20000)。这两个值位于源码树server/mpm/worker/worker.c中的以下两行:
- #define DEFAULT_SERVER_LIMIT 16
- #define MAX_SERVER_LIMIT 20000
需要注意的是,如果显式声明了ServerLimit,那么它乘以ThreadsPerChild的值必须大于等于MaxClients,而且MaxClients必须是ThreadsPerChild的整数倍,否则Apache将会自动调节到一个相应值(可能是个非期望值)。下面是worker配置段:
-
- StartServers 3
- MaxClients 2000
- ServerLimit 25
- MinSpareThreads 50
- MaxSpareThreads 200
- ThreadLimit 200
- ThreadsPerChild 100
- MaxRequestsPerChild 0
通过上面的叙述,可以了解到Apache 2.0中prefork和worker这两个重要MPM的工作原理,并可根据实际情况来配置Apache相关的核心参数,以获得最大的性能和稳定性。
MaxClients:允许同时伺服的最大接入请求数量(最大线程数量)。任何超过MaxClients限制的请求都将进入等候 队列。默认值是"400",16 (ServerLimit)乘以25(ThreadsPerChild)的结果。因此要增加MaxClients的时候,您必须同时增加 ServerLimit的值。
ThreadsPerChild:每个子进程建立的常驻的执行线程数。默认值是25。子进程在启动时建立这些线程后就不再建立新的线程了。
MaxRequestsPerChild:配置每个子进程在其生存期内允许伺服的最大请求数量。到达MaxRequestsPerChild的限制后,子进程将会结束。假如MaxRequestsPerChild为"0",子进程将永远不会结束。
将MaxRequestsPerChild配置成非零值有两个好处:
1.能够防止(偶然的)内存泄漏无限进行,从而耗尽内存。
2.给进程一个有限寿命,从而有助于当服务器负载减轻的时候减少活动进程的数量。
注意
对于KeepAlive链接,只有第一个请求会被计数。事实上,他改变了每个子进程限制最大链接数量的行为。
6.Apache的运行
Apache运行分为启动阶段和运行阶段。
5.1. 启动阶段
在启动阶段,Apache主要进行配置文件解析(例如http.conf以及Include指令设定的配置文件等)、模块加载(例如mod_php.so,mod_perl.so等)和系统资源初始化(例如日志文件、共享内存段等)工作。
在这个阶段,Apache为了获得系统资源最大的使用权限,将以特权用户root(X系统)或超级管理员administrator(Windows系统)完成启动。
Apache和“php处理机”的装配过程就是在这个阶段完成的。
“php处理机”就是负责解释和执行你的php代码的系统模块。这个名字是我特意创造的,目的是为了帮助你理解本节的内容,后面的章节还会给出更专业的名称。
你单独做过php的安装配置吗?
如果你做过类似的工作,下面的内容很容易理解;如果你没有做过,可以尝试安装一下,有助于加深你的理解。不过,我的文章向来深入浅出,我会尽量把这个过程讲得更浅显一些。其实php的安装非常简单,如果你很感兴趣的话,可以到网上随便搜一篇安装指南,按步骤照做就可以了。
把php最终集成到Apache系统中,还需要对Apache进行一些必要的设置。这里,我们就以php的mod_php5 SAPI运行模式为例进行讲解,至于SAPI这个概念后面我们还会详细讲解。
假定我们安装的版本是Apache2 和 Php5,那么需要编辑Apache的主配置文件http.conf,在其中加入下面的几行内容:
Unix/Linux环境下:
LoadModule php5_module modules/mod_php5.so
AddType application/x-httpd-php .php
注:其中modules/mod_php5.so 是X系统环境下mod_php5.so文件的安装位置。
Windows环境下:
LoadModule php5_module d:/php/php5apache2.dll
AddType application/x-httpd-php .php
注:其中d:/php/php5apache2.dll 是在Windows环境下php5apache2.dll文件的安装位置。
这两项配置就是告诉Apache Server,以后收到的Url用户请求,凡是以php作为后缀,就需要调用php5_module模块(mod_php5.so/ php5apache2.dll)进行处理。
这个过程可以参考以下的示意图:
Apache启动阶段的源码包含在server/main.c中,我整理了一下源码中的对应关系:
不熟悉unix/linux的同学可能会问so文件(mod_php5.so)是个什么样的文件?
unix/linux下,so后缀文件是一个DSO文件,DSO与windows系统下的dll是等价概念,都是把一堆函数封装在一个二进制文件中。调用它们的进程把它们装入内存后,会将其映射到自己的地址空间。
DSO全称为Dynamic Shared Object,即动态共享对象。DLL全称为Dynamic Link Library 即动态链接库。
Apache 服务器的体系结构的最大特点,就是高度模块化。如果你为了追求处理效率,可以把这些dso模块在apache编译的时候静态链入,这样会提高Apache 5%左右的处理性能。
5.2、运行阶段
5.2.1 运行阶段概述
在运行阶段,Apache主要工作是处理用户的服务请求。
在这个阶段,Apache放弃特权用户级别,使用普通权限,这主要是基于安全性的考虑,防止由于代码的缺陷引起的安全漏洞。象微软的IIS就曾遭受“红色代码(Code Red)”和“尼姆达(Nimda)”等恶意代码的溢出攻击。
2.2 运行阶段流程
Apache将请求处理循环分为11个阶段,依次是:Post-Read-Request,URI Translation,Header Parsing,Access Control,Authentication,Authorization,MIME Type Checking,FixUp,Response,Logging,CleanUp。
Apache Hook机制
Apache的Hook机制是指:Apache 允许模块(包括内部模块和外部模块,例如mod_php5.so,mod_perl.so等)将自定义的函数注入到请求处理循环中。换句话说,模块可以在 Apache的任何一个处理阶段中挂接(Hook)上自己的处理函数,从而参与Apache的请求处理过程。
mod_php5.so/ php5apache2.dll就是将所包含的自定义函数,通过Hook机制注入到Apache中,在Apache处理流程的各个阶段负责处理php请求。
关于Hook机制在Windows系统开发也经常遇到,在Windows开发既有系统级的钩子,又有应用级的钩子。常见的翻译软件(例如金山词霸等等)的 屏幕取词功能,大多数是通过安装系统级钩子函数完成的,将自定义函数替换gdi32.dll中的屏幕输出的绘制函数。
Apache请求处理循环详解
Apache请求处理循环的11个阶段都做了哪些事情呢?
1、Post-Read-Request阶段
在正常请求处理流程中,这是模块可以插入钩子的第一个阶段。对于那些想很早进入处理请求的模块来说,这个阶段可以被利用。
2、URI Translation阶段
Apache在本阶段的主要工作:将请求的URL映射到本地文件系统。模块可以在这阶段插入钩子,执行自己的映射逻辑。mod_alias就是利用这个阶段工作的。
3、Header Parsing阶段
Apache在本阶段的主要工作:检查请求的头部。由于模块可以在请求处理流程的任何一个点上执行检查请求头部的任务,因此这个钩子很少被使用。mod_setenvif就是利用这个阶段工作的。
4、Access Control阶段
Apache在本阶段的主要工作:根据配置文件检查是否允许访问请求的资源。Apache的标准逻辑实现了允许和拒绝指令。mod_authz_host就是利用这个阶段工作的。
5、Authentication阶段
Apache在本阶段的主要工作:按照配置文件设定的策略对用户进行认证,并设定用户名区域。模块可以在这阶段插入钩子,实现一个认证方法。
6、Authorization阶段
Apache在本阶段的主要工作:根据配置文件检查是否允许认证过的用户执行请求的操作。模块可以在这阶段插入钩子,实现一个用户权限管理的方法。
7、MIME Type Checking阶段
Apache在本阶段的主要工作:根据请求资源的MIME类型的相关规则,判定将要使用的内容处理函数。标准模块mod_negotiation和mod_mime实现了这个钩子。
8、FixUp阶段
这是一个通用的阶段,允许模块在内容生成器之前,运行任何必要的处理流程。和Post_Read_Request类似,这是一个能够捕获任何信息的钩子,也是最常使用的钩子。
9、Response阶段
Apache在本阶段的主要工作:生成返回客户端的内容,负责给客户端发送一个恰当的回复。这个阶段是整个处理流程的核心部分。
10、Logging阶段
Apache在本阶段的主要工作:在回复已经发送给客户端之后记录事务。模块可能修改或者替换Apache的标准日志记录。
11、CleanUp阶段
Apache在本阶段的主要工作:清理本次请求事务处理完成之后遗留的环境,比如文件、目录的处理或者Socket的关闭等等,这是Apache一次请求处理的最后一个阶段。
模块的注入Apache的过程可以参考源码中server/core.c文件:
mod_php5.so/ php5apache2.dll注入到Apache的函数中,最重要的就是Response阶段的处理函数。
6. Apache的性能调优
假如apache的配置
StartServers 8
MinSpareServers 5
MaxSpareServers 20
MaxClients 256
MaxRequestsPerChild 4000
在没有启用serverlLimit的情况下,使用ab测试:
ab -n 10000 -c 1000 http://192.168.1.191/test.php

如果继续保持同样的并发量继续测试(测试完后马上继续测试),由于apache的大部分子进程还没有被kill掉,创建子进程的时间就是少了,即有部分子进程已经预派生出来了。即n=20000(ab -n 20000-c 1000 http://192.168.1.191/test.php)时,时间应该不是137 *2 = 274S.
如果过一段时间在测试,即等apache kill进程,直到进程数等于MaxSpareServers (20)再测试,时间还是差不多的(137s左右)。
如果n=40000(ab -n 40000 -c 1000 http://192.168.1.191/test.php)观察服务器 apache的进程数:ps -ef | grep httpd | wc -l 。当apache的进程数到达256个后不再增加。
如果配置serverLimit
serverLimit 1000
StartServers 8
MinSpareServers 5
MaxSpareServers 20
MaxClients 1000
MaxRequestsPerChild 4000
apache的进程就可以突破256的限制了。
调优设置:
1)如果服务器只是的某个时段的并发量很多,设置serverLimit ,并修改MaxClients 。
2)如果服务器持续性地高负载,可考虑同时加大MinSpareServers和MaxSpareServers。