HBase API+优化+Phenix+索引 笔记
文章目录
- API
- DDL
- DML
- HBase优化
- 预分区
- 1.手动设定预分区
- 2.指明分区个数
- 3.按照文件中设置的规则预分区
- 4.使用javaApi创建预分区
- rowKey的设计
- 小案例:
- 内存优化
- 基础优化
- HBase底层原理
- HBase与Hive集成使用
- Phoenix
- 安装配置
- 配置环境变量
- 启动
- Shell操作
- 删除表
- 映射:
- 视图映射
- 创建视图
- 删除视图
- 表映射
- Phoenix数字问题
- idea可视化
- Phoenix JDBC操作
- Thin 瘦客户端
- Thick胖客户端
- 索引
- 参数配置
- 全局二级索引
- 本地二级索引
API
创建表 、删除表、表是否存在、
添加依赖
<dependency>
<groupId>org.apache.hbasegroupId>
<artifactId>hbase-serverartifactId>
<version>2.0.5version>
dependency>
<dependency>
<groupId>org.apache.hbasegroupId>
<artifactId>hbase-clientartifactId>
<version>2.0.5version>
dependency>
DDL
java
package com.vanas.hbase.client;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.NamespaceDescriptor;
import org.apache.hadoop.hbase.NamespaceExistException;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
/**
* @author Vanas
* @create 2020-06-28 2:20 下午
*/
public class HBaseUtil {
public static Connection connection;
static {
try {
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", "hadoop102,hadoop103,hadoop104");
connection = ConnectionFactory.createConnection(conf);
} catch (IOException e) {
e.printStackTrace();
}
}
public static void createNameSpace(String nameSpace) throws IOException {
Admin admin = connection.getAdmin();
NamespaceDescriptor namespaceDescriptor = NamespaceDescriptor.create(nameSpace).build();
try {
admin.createNamespace(namespaceDescriptor);
} catch (NamespaceExistException e) {
System.err.println(nameSpace + "已存在");
} finally {
admin.close();
}
}
public static void createTable(String nameSpace, String tableName, String... families) throws IOException {
if (families.length < 1) {
System.out.println("至少有一个列族");
return;
}
Admin admin = connection.getAdmin();
try {
if (admin.tableExists(TableName.valueOf(nameSpace, tableName))) {
System.out.println(nameSpace + ":" + tableName + "已存在");
return;
}
TableDescriptorBuilder builder = TableDescriptorBuilder.newBuilder(TableName.valueOf(nameSpace, tableName));
for (String family : families) {
ColumnFamilyDescriptorBuilder cfBuilder = ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes(family));
builder.setColumnFamily(cfBuilder.build());
}
admin.createTable(builder.build());
} finally {
admin.close();
}
}
public void deleteTable(String nameSpace, String tableName) throws IOException {
Admin admin = connection.getAdmin();
try {
if (!admin.tableExists(TableName.valueOf(nameSpace, tableName))) {
System.out.println(nameSpace + ":" + tableName + "不存在");
return;
}
admin.disableTable(TableName.valueOf(nameSpace, tableName));
admin.deleteTable(TableName.valueOf(nameSpace, tableName));
} finally {
admin.close();
}
}
public static void main(String[] args) throws IOException {
createNameSpace("vanas");
createTable("vamas", "student", "info", "msg");
}
}
Scala
package com.vanas.hbase
import org.apache.hadoop.hbase.{HBaseConfiguration, NamespaceDescriptor, TableName}
import org.apache.hadoop.hbase.client.{Admin, ColumnFamilyDescriptorBuilder, Connection, ConnectionFactory, TableDescriptorBuilder}
import org.apache.hadoop.hbase.util.Bytes
/**
* @author Vanas
* @create 2020-06-24 9:22 上午
*/
object HbaseDDL {
//1.先获取hbase的连接
val conf = HBaseConfiguration.create()
conf.set("hbase.zookeeper.quorum", "hadoop130,hadoop133,hadoop134")
val conn: Connection = ConnectionFactory.createConnection(conf)
def main(args: Array[String]): Unit = {
//println(tableExists("user"))
createTable("hbase1", "cf1", "cf2")
//createNS("abc")
closeConnection()
}
def createNS(name: String) = {
val admin: Admin = conn.getAdmin
if (!nsExists(name)) {
val nd: NamespaceDescriptor.Builder = NamespaceDescriptor.create(name)
admin.createNamespace(nd.build())
} else {
println(s"创建的命名空间:${name}已经存在")
}
admin.close()
}
def nsExists(name: String): Boolean = {
val admin: Admin = conn.getAdmin
val nss: Array[NamespaceDescriptor] = admin.listNamespaceDescriptors()
val r: Boolean = nss.map(_.getName).contains(name)
admin.close()
r
}
def deleteTable(name: String) = {
val admin: Admin = conn.getAdmin
if (tableExists(name)) {
admin.disableTable(TableName.valueOf(name))
admin.deleteTable(TableName.valueOf(name))
}
admin.close()
}
/**
* 创建指定编表
*
* @param name
*/
def createTable(name: String, cfs: String*): Boolean = {
val admin: Admin = conn.getAdmin
val tableName = TableName.valueOf(name)
if (tableExists(name)) return false
val td = TableDescriptorBuilder.newBuilder(tableName)
cfs.foreach(cf => {
val cfd = ColumnFamilyDescriptorBuilder
.newBuilder(Bytes.toBytes(cf))
.build()
td.setColumnFamily(cfd)
})
admin.createTable(td.build())
admin.close()
true
}
/**
* 判断表是否存在
*
* @param name
* @return
*/
def tableExists(name: String): Boolean = {
//2.获取管理对象 Admin
val admin: Admin = conn.getAdmin
//3.利用Admin进行各种操作
val tableName = TableName.valueOf(name)
val b: Boolean = admin.tableExists(tableName)
//4.关闭Admin
admin.close()
b
}
//4.关闭连接
def closeConnection() = conn.close()
}
DML
java
public static void putCell(String nameSpace, String tableName, String rowKey, String family, String column, String value) throws IOException {
Table table = connection.getTable(TableName.valueOf(nameSpace, tableName));
try {
Put put = new Put(Bytes.toBytes(rowKey));
put.addColumn(Bytes.toBytes(family), Bytes.toBytes(column), Bytes.toBytes(value));
table.put(put);
} finally {
table.close();
}
}
public static void getCell(String nameSpace, String tableName, String rowKey, String family, String column) throws IOException {
Table table = connection.getTable(TableName.valueOf(nameSpace, tableName));
Get get = new Get(Bytes.toBytes(rowKey));
get.addColumn(Bytes.toBytes(family), Bytes.toBytes(column));
Result result = table.get(get);
Cell[] cells = result.rawCells();
for (Cell cell : cells) {
System.out.println("CF:" + Bytes.toString(CellUtil.cloneFamily(cell)) +
",CN:" + Bytes.toString(CellUtil.cloneQualifier(cell)) +
",Value:" + Bytes.toString(CellUtil.cloneValue(cell)));
}
table.close();
}
public static void scanRows(String nameSpace, String tableName, String startRow, String stopRow) throws IOException {
Table table = connection.getTable(TableName.valueOf(nameSpace, tableName));
Scan scan = new Scan();
Scan scan1 = scan.withStartRow(Bytes.toBytes(startRow)).withStopRow(Bytes.toBytes(stopRow));
ResultScanner scanner = table.getScanner(scan1);
for (Result result : scanner) {
Cell[] cells = result.rawCells();
for (Cell cell : cells) {
System.out.println("CF:" + Bytes.toString(CellUtil.cloneFamily(cell)) +
",CN:" + Bytes.toString(CellUtil.cloneQualifier(cell)) +
",Value:" + Bytes.toString(CellUtil.cloneValue(cell)));
}
}
scanner.close();
table.close();
}
public void deleteCell(String nameSpace, String tableName, String rowKey, String family, String column) throws IOException {
Table table = connection.getTable(TableName.valueOf(nameSpace, tableName));
Delete delete = new Delete(Bytes.toBytes(rowKey));
delete.addColumns(Bytes.toBytes(family), Bytes.toBytes(column)); //删所有版本
table.delete(delete);
table.close();
}
scala
package com.vanas.hbase
import java.util
import org.apache.hadoop.hbase.client._
import org.apache.hadoop.hbase.filter.SingleColumnValueFilter
import org.apache.hadoop.hbase.util.Bytes
import org.apache.hadoop.hbase.{Cell, CellUtil, CompareOperator, HBaseConfiguration, TableName}
/**
* @author Vanas
* @create 2020-06-24 11:04 上午
*/
object HbaseDML {
//1.先获取hbase的连接
val conf = HBaseConfiguration.create()
conf.set("hbase.zookeeper.quorum", "hadoop130,hadoop133,hadoop134")
val conn: Connection = ConnectionFactory.createConnection(conf)
def main(args: Array[String]): Unit = {
//putData("user", "1001", "info", "name", "ww")
//deleteData("user", "1001", "info", "age")
//getData("user", "1001", "info", "name")
scanData("user")
closeConnection()
}
def scanData(tableName: String) = {
val table: Table = conn.getTable(TableName.valueOf(tableName))
val scan = new Scan()
val filter = new SingleColumnValueFilter(Bytes.toBytes("info"), Bytes.toBytes("name"), CompareOperator.EQUAL, Bytes.toBytes("ww"))
filter.setFilterIfMissing(true)
scan.setFilter(filter)
val results: ResultScanner = table.getScanner(scan)
import scala.collection.JavaConversions._
//从scanner拿到所有数据
for (result <- results) {
val cells: util.List[Cell] = result.listCells() //rowCells
if (cells != null) {
for (cell <- cells) {
println(
s"""
|row =${Bytes.toString(CellUtil.cloneRow(cell))}
|cf =${Bytes.toString(CellUtil.cloneFamily(cell))}
|name =${Bytes.toString(CellUtil.cloneQualifier(cell))}
|value =${Bytes.toString(CellUtil.cloneValue(cell))}
|""".stripMargin)
}
}
}
table.close()
}
def getData(tableName: String, rowKey: String, cf: String, columnName: String) = {
val table: Table = conn.getTable(TableName.valueOf(tableName))
val get = new Get(Bytes.toBytes(rowKey))
get.addColumn(Bytes.toBytes(cf), Bytes.toBytes(columnName))
val result: Result = table.get(get)
//这个是用来在java的集合和scala的集合之间转换(隐式转换)
import scala.collection.JavaConversions._
val cells: util.List[Cell] = result.listCells() //rowCells
if (cells != null) {
for (cell <- cells) {
//cell.getFamilyArray
//println(Bytes.toString(CellUtil.cloneFamily(cell)))
println(
s"""
|row =${Bytes.toString(CellUtil.cloneRow(cell))}
|cf =${Bytes.toString(CellUtil.cloneFamily(cell))}
|name =${Bytes.toString(CellUtil.cloneQualifier(cell))}
|value =${Bytes.toString(CellUtil.cloneValue(cell))}
|""".stripMargin)
}
}
table.close()
}
def deleteData(tableName: String, rowKey: String, cf: String, columnName: String) = {
val table: Table = conn.getTable(TableName.valueOf(tableName))
val delete = new Delete(Bytes.toBytes(rowKey))
//delete.addColumn(Bytes.toBytes(cf), Bytes.toBytes(columnName))
delete.addColumns(Bytes.toBytes(cf), Bytes.toBytes(columnName)) //删除所有版本
table.delete(delete)
table.close()
}
def putData(tableName: String, rowKey: String, cf: String, columnName: String, value: String) = {
//最好先判断下
//1.先获取到表对象,客户端到表连接
val table: Table = conn.getTable(TableName.valueOf(tableName))
//2.调用表对象的put
//2.1 把需要添加的数据封装到一个Put对象 ,put ''.rowkey,''
val put = new Put(Bytes.toBytes(rowKey))
put.addColumn(Bytes.toBytes(cf), Bytes.toBytes(columnName), Bytes.toBytes(value))
//put.addColumn(Bytes.toBytes(cf), Bytes.toBytes(columnName + "abc"), Bytes.toBytes(value + "efg"))
//2.2 提交Put对象
table.put(put)
//3.关闭到table的连接
table.close()
}
//4.关闭连接
def closeConnection() = conn.close()
}
HBase优化
预分区
1.手动设定预分区
hbase> create 'staff1','info',SPLITS => ['1000','2000','3000','4000']
2.指明分区个数
15个区,分区策略按照16进制字符串分
所以rowKey也要变为16进制字符串才能匹配
分区键什么样对应的rowKey也要保持什么样
create 'staff2','info',{NUMREGIONS => 15, SPLITALGO => 'HexStringSplit'}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dgaH2VeG-1593336073442)(/Users/vanas/Desktop/截屏2020-06-28下午4.01.10.png)]
3.按照文件中设置的规则预分区
vim splits.txt
aaaa
bbbb
cccc
dddd
--要有序
--在当前路径进入到hbase shell
create 'staff3','info',SPLITS_FILE => 'splits.txt'
4.使用javaApi创建预分区
byte[][] splits=new byte[3][];
splits[0]=Bytes.toBytes("aaa");
splits[1]=Bytes.toBytes("bbb");
splits[2]=Bytes.toBytes("ccc");
Admin admin = connection.getAdmin();
TableDescriptorBuilder builder = TableDescriptorBuilder.newBuilder(TableName.valueOf("bigdata"));
ColumnFamilyDescriptorBuilder cfBuilder= ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes("info"));
builder.setColumnFamily(cfBuilder.build());
admin.createTable(builder.build(),splits);
admin.close();
scala
def createTable(name: String, cfs: String*): Boolean = {
val admin: Admin = conn.getAdmin
val tableName = TableName.valueOf(name)
if (tableExists(name)) return false
val td = TableDescriptorBuilder.newBuilder(tableName)
cfs.foreach(cf => {
val cfd = ColumnFamilyDescriptorBuilder
.newBuilder(Bytes.toBytes(cf))
.build()
td.setColumnFamily(cfd)
})
//admin.createTable(td.build())
val splites = Array(Bytes.toBytes("aaa"), Bytes.toBytes("bbb"), Bytes.toBytes("ccc"))
admin.createTable(td.build(), splites)
admin.close()
true
}
rowKey的设计
1.长度
1亿条
row:10字节 1亿*10 =10亿字节
row:100字节
10-100字节 2的幂次方 8、16、32、64
长度相同
2.散列
对rowKey散列 防止数据倾斜
md5
hash
3.唯一性
放置rowKey重复
反转的意义:把类似的信息放一起,方便之后查找
hbase.apache.org => gro.echapa…
hadoop.apache.org
kafka.apache.org
rowKey里包含有意义的信息
ID name age sex
rowKey :id
列:name age sex
rowKey :1001_lisi_10
小案例:
统计网站的每分钟的访问次数,怎么设计预分区和rowKey?
user_id timestamp
rowKey唯一性,保证后期查询时的数据 要写在一起
1.满足业务
2.解决热点问题
yyyyMMddHHmmssSSS. 避免这种单调递增的rowkey
当分裂时都往新的region里写,出现热点问题
违反唯一性
yyyyMMddHHmmssSSS_user_id
mmHHddMMyyyy_user_id 这种可行
加有规律的随机数 %5(0,1,2,3,4)分区键设计1,2,3,4
取前缀 求哈希值 模一个数 (分区键=>按取模的数订就可以了)
“yyyyMMddHHmm”.hashCode()%5_yyyyMMddHHmmssSSS_user_id
-,1
1,2
2,3
3,4
4,+
查询:202003211203
scan("202003211203".hashCode()%5_202003211203,
"202003211203".hashCode()%5_202003211203|)
如果50个分区,分区键设计?
-,01
01,02
02,03
03,04
04,+
设计rowKey时尽量短一些不要太长,保证业务要求的情况下越短越好,列族,列名也尽可能短
内存优化
regionServer占用的多,一般分配16-36G就可以
hbase-env.sh
export HBASE_OFFHEAPSIZE 调整参数大小
# Uncomment below if you intend to use off heap cache. For example, to allocate 8G of
# offheap, set the value to "8G".
# export HBASE_OFFHEAPSIZE=1G
基础优化
--1.Zookeeper会话超时时间
hbase-site.xml
属性:zookeeper.session.timeout
解释:默认值为90000毫秒(90s)。当某个RegionServer挂掉,90s之后Master才能察觉到。可适当减小此值,以加快Master响应,可调整至600000毫秒。
--2.设置RPC监听数量
hbase-site.xml
属性:hbase.regionserver.handler.count
解释:默认值为30,用于指定RPC监听的数量,可以根据客户端的请求数进行调整,读写请求较多时,增加此值。
一般调regionServer所在节点的核数的倍数 2倍就行
--3.手动控制Major Compaction
hbase-site.xml
属性:hbase.hregion.majorcompaction
解释:默认值:604800000秒(7天), Major Compaction的周期,若关闭自动Major Compaction,可将其设为0
--4.优化HStore文件大小
hbase-site.xml
属性:hbase.hregion.max.filesize
解释:默认值10737418240(10GB),如果需要运行HBase的MR任务,可以减小此值,因为一个region对应一个map任务,如果单个region过大,会导致map任务执行时间过长。该值的意思就是,如果HFile的大小达到这个数值,则这个region会被切分为两个Hfile。
--5.优化HBase客户端缓存
hbase-site.xml
属性:hbase.client.write.buffer
解释:默认值2097152bytes(2M)用于指定HBase客户端缓存,增大该值可以减少RPC调用次数,但是会消耗更多内存,反之则反之。一般我们需要设定一定的缓存大小,以达到减少RPC次数的目的。
一般做测试来决定值,没什么固定值
--6.指定scan.next扫描HBase所获取的行数
hbase-site.xml
属性:hbase.client.scanner.caching
解释:用于指定scan.next方法获取的默认行数,值越大,消耗内存越大。
--7.BlockCache占用RegionServer堆内存的比例
hbase-site.xml
属性:hfile.block.cache.size
解释:默认0.4,读请求比较多的情况下,可适当调大
--8.MemStore占用RegionServer堆内存的比例
hbase-site.xml
属性:hbase.regionserver.global.memstore.size
解释:默认0.4,写请求较多的情况下,可适当调大
--7 和 --8 加起来差不多0.8就可以了
HBase底层原理
Log Struct Merge Tree
LSMT数据结构
HBase与Hive集成使用
hive-site.xml
<property>
<name>hive.zookeeper.quorumname>
<value>hadoop102,hadoop103,hadoop104value>
property>
<property>
<name>hive.zookeeper.client.portname>
<value>2181value>
property>
Hive 建表 关联hbase
CREATE TABLE hive_hbase_emp_table(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,info:ename,info:job,info:mgr,info:hiredate,info:sal,info:comm,info:deptno")
TBLPROPERTIES ("hbase.table.name" = "hbase_emp_table");
临时表
CREATE TABLE emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)
row format delimited fields terminated by '\t';
只能用insert
load data local inpath '/opt/module/hive/datas/emp.txt' into table emp;
insert into table hive_hbase_emp_table select * from emp;
Hive 映射一个 在hbase已经存在的表
CREATE EXTERNAL TABLE relevance_hbase_emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)
STORED BY
'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" =
":key,info:ename,info:job,info:mgr,info:hiredate,info:sal,info:comm,info:deptno")
TBLPROPERTIES ("hbase.table.name" = "hbase_emp_table");
Phoenix
协处理器是给HBase建立二级索引用的
绑定的表发生写操作或者读操作时,相应的去做什么
协处理器需要放在hbase的lib目录下
有2种客户端
胖客户端 瘦客户端
安装配置
tar -zxvf apache-phoenix-5.0.0-HBase-2.0-bin.tar.gz -C /opt/module/
mv apache-phoenix-5.0.0-HBase-2.0-bin phoenix-5.0.0
cd /opt/module/phoenix/
cp phoenix-5.0.0-HBase-2.0-server.jar /opt/module/hbase-5.0.0/lib/
cd /opt/module/hbase-5.0.0/lib/
xsync phoenix-5.0.0-HBase-2.0-server.jar
配置环境变量
#phoenix
export PHOENIX_HOME=/opt/module/phoenix-5.0.0
export PHOENIX_CLASSPATH=$PHOENIX_HOME
export PATH=$PATH:$PHOENIX_HOME/bin
启动
hadoop集群、zookeeper、hbase
sqlline.py 胖客户端 zk地址 不传地址默认时localhost
[vanas@hadoop130 ~]$ sqlline.py hadoop130,hadoop133,hadoop134:2181
queryserver.py 瘦客户端
Shell操作
!table
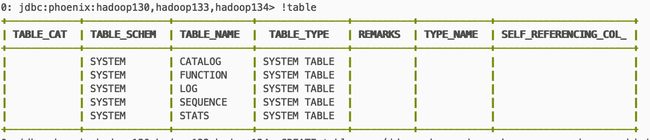
--primary key 相当于hbase里的rowkey
CREATE table user(id varchar primary key,name varchar,age bigint);
!table
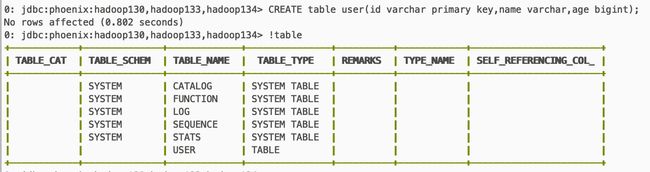
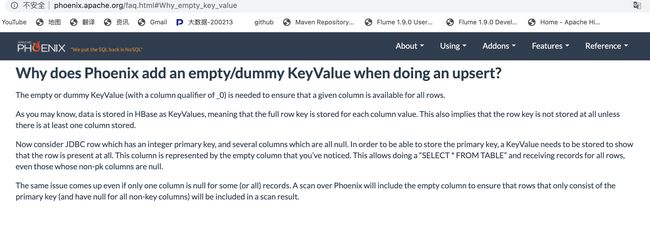
第一行涉及到空值的处理问题
列名编码 0是列族名、\x00\x00 减少对磁盘的占用 把列名映射成数字
COLUMN_ENCODED_BYTES=0
一般还是会使用列名的

--更新和插入合体
0: jdbc:phoenix:hadoop130,hadoop133,hadoop134> upsert into user values('1001','lisi',10);
1 row affected (0.082 seconds)
0: jdbc:phoenix:hadoop130,hadoop133,hadoop134> select * from user;
+-------+-------+------+
| ID | NAME | AGE |
+-------+-------+------+
| 1001 | lisi | 10 |
+-------+-------+------+
1 row selected (0.039 seconds)
0: jdbc:phoenix:hadoop130,hadoop133,hadoop134> upsert into user values('1002','ww',20);
1 row affected (0.012 seconds)
0: jdbc:phoenix:hadoop130,hadoop133,hadoop134> upsert into user values('1003','zs',15);
1 row affected (0.013 seconds)
0: jdbc:phoenix:hadoop130,hadoop133,hadoop134> upsert into user values('1004','wb',30);
1 row affected (0.013 seconds)
0: jdbc:phoenix:hadoop130,hadoop133,hadoop134> select * from user;
+-------+-------+------+
| ID | NAME | AGE |
+-------+-------+------+
| 1001 | lisi | 10 |
| 1002 | ww | 20 |
| 1003 | zs | 15 |
| 1004 | wb | 30 |
+-------+-------+------+
0: jdbc:phoenix:hadoop130,hadoop133,hadoop134> select * from user where age>15;
+-------+-------+------+
| ID | NAME | AGE |
+-------+-------+------+
| 1002 | ww | 20 |
| 1004 | wb | 30 |
+-------+-------+------+
0: jdbc:phoenix:hadoop130,hadoop133,hadoop134> delete from user where age=15;
1 row affected (0.019 seconds)
0: jdbc:phoenix:hadoop130,hadoop133,hadoop134> select * from user;
+-------+-------+------+
| ID | NAME | AGE |
+-------+-------+------+
| 1001 | lisi | 10 |
| 1002 | ww | 20 |
| 1004 | wb | 30 |
+-------+-------+------+
hbase创建的表默认在phoneix看不到
phoneix建的表默认在hbase是可以看到的,而且可读
[vanas@hadoop130 ~]$ hbase shell
hbase(main):001:0> scan 'USER'

删除表
drop table user;
!table
单引号 表示 String
双引号 表示 小写
1.联合主键
id name age
CREATE table person(id varchar,name varchar,age bigint constraint my_pk primary key(id,name));
2.列族
CREATE 'c','info1','info2' hbase
phoneix 如果不置顶列族,默认是'0'
CREATE table person1(id varchar primary key,info1.name varchar,info2.age bigint);
3.预分区
CREATE table person2(id varchar primary key,info1.name varchar,info2.age bigint) split on ('100','200','300');
映射:
hbase表和phoenix表的映射
hbase中建立的表,在phoenix无法访问
视图映射
比如hbase已经建立表 test100
想再phoenix访问,在phoenix建立一个同样的名字的视图(view)
视图是只读的,用来查询,无法通过源数据进行修改等操作
hbase(main):004:0> create 'test100','info'
Created table test100
Took 0.9261 seconds
=> Hbase::Table - test100
hbase(main):005:0> put 'test100','100','info:name','lisi'
Took 0.1809 seconds
hbase(main):006:0> put 'test100','200','info:name','zs'
Took 0.0068 seconds
hbase(main):007:0> put 'test100','200','info:age',10
Took 0.0074 seconds
hbase(main):008:0> put 'test100','100','info:age',20
Took 0.0089 seconds
创建视图
create view "test100" ("id" varchar primary key,"info"."name" varchar,"info"."age" varchar);
0: jdbc:phoenix:hadoop130,hadoop133,hadoop134> select * from "test100";
+------+-------+------+
| id | name | age |
+------+-------+------+
| 100 | lisi | 20 |
| 200 | zs | 10 |
+------+-------+------+
删除视图
drop view "test100";
表映射
hbase也会联动
hbase中不存在表
直接在Phoenix创建
hbase中已存在表
把view改为table,把列编码设置为0 不然列的数据找不到
create table "test100"(id varchar primary key,"info"."name" varchar, "info"."age" varchar) column_encoded_bytes=0;
Phoenix数字问题
10->000000…1010
-10-> 11111…
phoenix中存在,把符号位取反
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PJdAUyRM-1593336073447)(/Users/vanas/Library/Application Support/typora-user-images/截屏2020-06-26下午6.48.23.png)]
存的是补码
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EAa7g4yM-1593336073448)(/Users/vanas/Library/Application Support/typora-user-images/截屏2020-06-26下午6.52.21.png)]
phoenix 保证排序负数都在正数上面 所有把首位反转
所以在声明时候不要用INTEGER 改用 UNSIGNED_INT
客户端默认当成Long处理
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wwT0V4VS-1593336073448)(/Users/vanas/Library/Application Support/typora-user-images/截屏2020-06-26下午6.54.06.png)]
idea可视化
hive
hiveserver2+beeline
涉及到如何在idea下去连接Phoenix
有2种连接Phoenix的方法:
使用瘦客户端(优先使用)
使用胖客户端
可视化工具:
1.dbeaver 在eclipse的基础上做的二次开发
2.SQuirrel phoenix官方推荐的
3.idea自带的插件 database
Phoenix JDBC操作
添加依赖
<dependencies>
<dependency>
<groupId>org.apache.phoenixgroupId>
<artifactId>phoenix-queryserver-clientartifactId>
<version>5.0.0-HBase-2.0version>
dependency>
dependencies>
Thin 瘦客户端
1.需要在服务器端起一个查询服务器
2.idea使用瘦客户端连接
queryserver.py start
Java
public class TestThinClient {
public static void main(String[] args) throws SQLException {
String url = ThinClientUtil.getConnectionUrl("hadoop130", 8765);
System.out.println(url);
//jdbc:phoenix:thin:url=http://hadoop130:8765;serialization=PROTOBUF
Connection connection = DriverManager.getConnection(url);
PreparedStatement ps = connection.prepareStatement("select * from person");
ResultSet resultSet = ps.executeQuery();
while (resultSet.next()){
System.out.println(resultSet.getString(1)+":"+resultSet.getString(2));
}
}
}
Scala
object PhoenixTest {
def main(args: Array[String]): Unit = {
//本质:就是通过jdbc访问Phoenix
//1.建立连接
val url = ThinClientUtil.getConnectionUrl("hadoop130", 8765)
println(url) //jdbc:phoenix:thin:url=http://hadoop130:8765;serialization=PROTOBUF
val conn: Connection = DriverManager.getConnection(url)
//2.PrepareState
val ps: PreparedStatement = conn.prepareStatement("select * from person")
//3.执行
val resultSet: ResultSet = ps.executeQuery()
//4.解析结果
while (resultSet.next()) {
val id: String = s"id=${resultSet.getString(1)},name=${resultSet.getString(2)},age=${resultSet.getLong(3)}"
println(id)
}
//5.关闭连接
conn.close()
}
}
Thick胖客户端
<dependency>
<groupId>org.apache.phoenixgroupId>
<artifactId>phoenix-coreartifactId>
<version>5.0.0-HBase-2.0version>
<exclusions>
<exclusion>
<groupId>org.glassfishgroupId>
<artifactId>javax.elartifactId>
exclusion>
exclusions>
dependency>
<dependency>
<groupId>org.glassfishgroupId>
<artifactId>javax.elartifactId>
<version>3.0.1-b06version>
dependency>
Java
public class TestThickClient {
public static void main(String[] args) throws SQLException {
String url = "jdbc:phoenix:hadoop130,hadoop133,hadoop134:2181";
Connection connection = DriverManager.getConnection(url);
PreparedStatement ps = connection.prepareStatement("select * from person");
ResultSet resultSet = ps.executeQuery();
while (resultSet.next()){
System.out.println(resultSet.getString(1)+":"+resultSet.getString(2));
}
}
}
若还不成功补充配置
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uL7QaD5R-1593336073449)(/Users/vanas/Desktop/截屏2020-06-26下午8.05.06.png)]
scala
object PhoenixTest {
def main(args: Array[String]): Unit = {
//本质:就是通过jdbc访问Phoenix
//1.建立连接
val url = "jdbc:phoenix:hadoop130,hadoop133,hadoop134:2181"
println(url) //jdbc:phoenix:thin:url=http://hadoop130:8765;serialization=PROTOBUF
val conn: Connection = DriverManager.getConnection(url)
//2.PrepareState
val ps: PreparedStatement = conn.prepareStatement("select * from person")
//3.执行
val resultSet: ResultSet = ps.executeQuery()
//4.解析结果
while (resultSet.next()) {
val id: String = s"id=${resultSet.getString(1)},name=${resultSet.getString(2)},age=${resultSet.getLong(3)}"
println(id)
}
//5.关闭连接
conn.close()
}
}
索引
二级索引:索引字段 -> rowkey -> 数据
优化查询速度
参数配置
hbase-site.xml
<property>
<name>hbase.regionserver.wal.codecname>
<value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodecvalue>
property>
<property>
<name>hbase.region.server.rpc.scheduler.factory.classname>
<value>org.apache.hadoop.hbase.ipc.PhoenixRpcSchedulerFactoryvalue>
<description>Factory to create the Phoenix RPC Scheduler that uses separate queues for index and metadata updatesdescription>
property>
<property>
<name>hbase.rpc.controllerfactory.classname>
<value>org.apache.hadoop.hbase.ipc.controller.ServerRpcControllerFactoryvalue>
<description>Factory to create the Phoenix RPC Scheduler that uses separate queues for index and metadata updatesdescription>
property>
分发配置文件
重启
全局二级索引
新建一个表,索引数据和数据表存在不同的
create index。。
在查询的字段中,有非索引字段就需要全表扫描
适用范围:多读少写
explain select "id" from "test100" where "id" ='100';
create index index2 on "test100"("info"."name");
explain select "name" from "test100" where "name" ='a';
explain select "name","age" from "test100" where "name" ='a';

删除索引
drop index index2 on "test100"
覆盖索引(包含索引)
create index index4 on "test100" ("info"."name") include ("info"."age");
explain select "name","age" from "test100" where "name" ='a';

强制索引(还存在问题 先预留)
如果辨识度不高 还不如全表扫描
explain select /*+ INDEX("test100" index2)*/"name","age" from "test100" where "name" ='zs';
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VYqMW9we-1593336073451)(/Users/vanas/Library/Application Support/typora-user-images/截屏2020-06-26下午8.28.13.png)]
官方给出的3种索引
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sy1ttBH0-1593336073451)(/Users/vanas/Library/Application Support/typora-user-images/截屏2020-06-26下午8.48.25.png)]
本地二级索引
不新建表 在本地中
create local index 。。。
查询字段的时候,即使查询的字段没有索引,也可以优化(where 字段必须有索引)
使用范围:多写少读
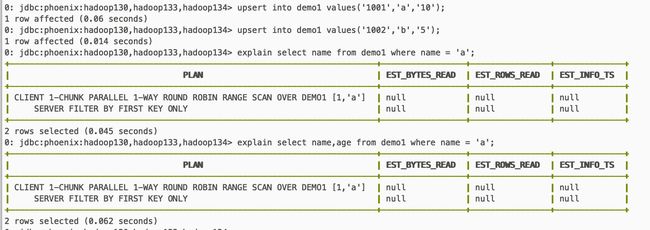
create table demo1(id varchar primary key,name varchar ,age varchar);
create local index loal_1 on demo1(name);
可以在前两行看出 列拼接主键
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tf8P3ozO-1593336073452)(/Users/vanas/Library/Application Support/typora-user-images/截屏2020-06-26下午8.41.38.png)]
都是范围扫描