矩阵计算与AI革命:可将计算性能提高150倍的异构计算

本文翻译自Wikibon矩阵计算与AI革命系列研究文章。
如今异构计算(Heterogeneous Compute,HC)已经部署在消费类移动设备中,与传统架构相比可以将矩阵工作负载的性能提高50倍。同时,这也将性价比和功耗节省提高了150倍以上。企业HC可能会使用与消费HC相同的技术。因此,异构计算的改进将大幅提升实时矩阵工作负载的价值,尤其是那些AI推理工作负载的子集。
更具战略意义的前提是,虽然异构计算可以将处理数据的成本降低五十倍,但存储和移动数据的成本将高出50倍。如果矩阵工作负载使用传统的数据中心流程,非处理器组件的成本将占主导地位。但是,通过使用数据主导的运营架构(Data-led Operational Architecture,DLOA),可以使存储和网络成本与计算成本保持一致。这两个基本体系结构改变的结果是,允许实时矩阵工作负载在与传统企业计算相同的成本范围内,处理两个数量级以上的数据。用异构计算运行矩阵工作负载,这是数据导向型企业的重要技术。
Wikibon的研究员表示,上述前提与假设的观点非常激进。如果其他研究人员发现错误,遗漏或不合适的数字,Wikibon也愿意更新研究结果。注意:AI训练工作负载不是矩阵工作负载,因为它不是实时的。训练工作负载通常是分批的,这将显著提高GPU吞吐量。目前,训练在AI计算能力中占比很高,但在这十年中,推理将更加重要。
执行摘要
对于矩阵工作负载,异构计算的性能优于传统的x86
苹果和谷歌首先在消费类应用中采用了神经网络技术。2017年,Apple的iPhone X内置了早期的异构计算架构,该架构具有集成的GPU、处理器和神经网络单元(NPU)。这款智能手机让移动用户可以使用软件而不是硬件来拍摄更好的照片,并通过面部识别技术改善隐私性。Google在其Pixel智能手机中随附了一个独立的NPU,以增强摄影和音频功能,还提供了依靠大型水冷TPU(Tensor Processing Unit)的云服务来支撑在手机上发展机器学习(ML)。
Wikibon将“异构计算体系结构”定义为CPU、加速器、NPU、ASIC、GPU和FPGA的组合。它们以非常低的延迟和高带宽彼此直接互连,这比DRAM的运行速度快得多。在本研究中,代表性的异构计算系统是基于Arm的iPhone 11。传统体系结构的代表是基于最新的Intel i7-1065G7技术的x86 PC系统。下面的图1总结了本研究的性能和性价比部分的结论。
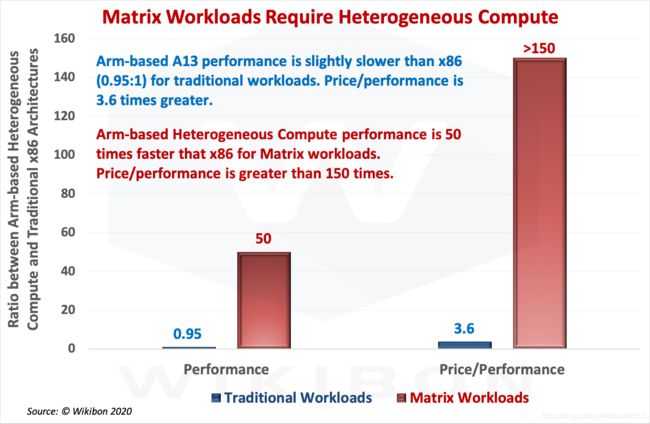
图1:对比传统和矩阵工作负载下异构计算与传统x86的性能和性价比
来源:©Wikibon,2020年
图1中的y轴是基于Arm的异构计算架构(iPhone 11 Pro Max)和传统x86架构(Intel i7-1065G7 PC)之间的比值。对于传统的工作负载,这两种设备的性能大致相同。
第一组相邻的列表示性能比率,以Y轴显示。蓝色的列显示了传统的工作负载性能,这表明异构计算的性能比x86略慢(0.95:1)。红色的列则显示了在异构计算体系结构上运行的矩阵工作负载性能是x86的50倍。
第二组相邻的列展示了性价比比率,以Y轴显示。蓝柱表明传统工作负载下HC性价比是x86的3.6倍。红柱展示了矩阵工作负载下HC的性价比高出x86超过150倍。
数据主导的运营架构(DLOA)
支持矩阵工作负载的异构计算系统将需要截然不同的部署策略。传统的IT组织思维方式是降低计算成本。对于矩阵工作负载,其思路是需要关注数据存储和移动数据的成本最小化。而处理方式也将转向在数据创建处拦截数据,并实时从数据中提取最大价值。数据的创建可以在边缘、移动边缘、集中式数据中心,也可以是在互联网POP等集中式站点。提取的数据中的一小部分子集可以相邻地存储,从而允许来自其它系统的额外处理请求。这些子集还将允许数据通过现代的混合多云网络移动到其它系统。
图2说明了传统工作负载操作流程与矩阵工作负载操作流程之间的区别。图2的上半部分显示了常规数据源,该数据源将数据发送到实时操作系统,然后将所有原始数据和提取的数据,存储在数据仓库和数据湖中。
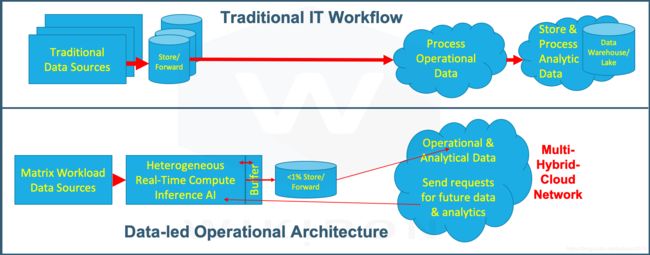
图2:传统的IT工作流程vs以数据为主导的运营架构工作流程
来源:Wikibon©2020
图2的下半部分显示了解决问题的另一种方式,更接近人工的操作方式。数据(通常来自越来越多的传感器或数据流)是实时处理的。一般情况下,应用是一个分布式推理AI模块,异构计算架构提供了处理数据所需的巨大计算能力。每个步骤的输出在缓冲区中保存很短的一段时间(10分钟左右),以便将上下文保留在未来的结果中。例如,如果几分钟后发生异常,则可以将缓冲区中的所有剩余数据保存并集中发送,以便进行遵从性和技术审查。缓冲区中的数据会不断被覆盖。
还可以处理分析和其他数据的需求。例如,来自特定的罕见情况的数据可以被保存下来,以帮助开发在微调或扩展AI推理代码。异构计算可以更新以处理短期实时分析的请求。保留的数据小于原始数据的1%,通常远小于1%。该数据包含被提炼过的,有价值的信息。在可能的情况下,工作流设计人员将把计算资源放在靠近主数据的位置,并避免数据移动。必要时,多云网络将保护最终数据并将其传输到需要的地方。在以数据为主导的企业中,这些其它地点将为转移过程付费。
降低异构计算成本的结果(图1)和DLOA部署架构的变化(图2)导致运行矩阵工作负载的成本降低了两个数量级。
异构计算供应商
异构计算领域的领先者目前主要是以消费者为主导的厂商,他们利用Arm公司的设计授权。特斯拉还使用Arm组件和自己的NPU设计来构建其HW3 HC系统。唯一的HC供应商是早期先驱者MobilEye,该公司于2017年被英特尔收购。
目前,Arm主导的系统性能已经等同或超过传统x86系统。Wikibon预计,未来十年,Arm主导的硬件、框架和软件将在异构计算领域占据主导地位,无论是分布式&边缘计算,还是大型集中式云计算。假设x86供应商继续其当前的设计和制造策略,Wikibon研究结论是,到2020年代末,企业服务器支出的72%将用于基于Arm的服务器。
以数据为主导的策略
人类是在源头过滤大量数据的专家。他们专注于从一系列的视觉、听觉、嗅觉、味觉和触觉传感器中过滤出必不可少的东西,这些数据轰炸着我们。人类的大脑通过大脑的神经结构在几毫秒内得出结论。人们也在不断学习改进这种过滤过程。它们将重要事件保留为记忆,并丢弃其余数据。
企业正在努力成为以数据为主导的组织,但问题的一部分是数据太多。移动数据费时费钱,并且会删除相关的上下文。理想的做法是在创建数据的时间点和地点处进行过滤,用它来自动化本地流程,并为远程流程提供信息。问题在于,当前的计算机体系结构不能处理这些带有大量数据的实时工作负载。我们需要更像人脑一样运作的设计,并在源头过滤数据。
在前面的研究中,Wikibon将这些工作负载称为矩阵工作负载。本次研究的重点是异构计算(HC)架构,该架构可以在相同的成本范围内实时处理比传统设计多2个数量级的数据。矩阵工作负载的示例包括智能系统、实时分析、人工智能推理、随机树林、机器人技术、自动驾驶汽车等。Wikibon预测,到2020年代末,矩阵计算收入的增长将占到全球企业计算的42%,此预测假定x86供应商策略没有重大变化。
异构计算架构的战略重要性是作为数据主导型企业的重要工具。当然还需要许多其它工具。例如,数据流的管理和合规性需要DataOps工具。而且,为了更快更安全地传输较小数量的数据,混合多云网络是必要的。总而言之,数据主导型企业的核心是能够在数据产生的地方实时从数据中提取价值,并实现自动化。
定义异构计算架构
为什么需要新架构
传统的架构注重以CPU为主要部件,并把重点放在提供更多的核心、更多的CPU、更快的CPU以及DRAM上。有时会添加GPU,PCIe网络提供带宽,中间的存储是DRAM。这种架构无法以所需的延迟或合理的成本处理实时矩阵工作负载。
异构计算架构(HC)允许采用更灵活的方法,提供广泛的处理器类型,并在这些处理器之间提供灵活的、极低延迟的连接。带宽和中间存储由SRAM提供,SRAM比PCIe的延迟更低,带宽更高。并行性和低延迟高带宽使得大多数矩阵工作负载的处理速度至少快一个数量级,而成本却低两个数量级。
异构计算(HC)架构的定义
Wikibon将HC定义为CPU、加速器、NPU、GPU和其它组件(如ASIC),以及与灵活的、极低延迟的高带宽连接和不同元素之间的中间存储的组合。由操作系统管理资源的使用,以满足矩阵工作负载的处理、带宽和延迟要求。
异构计算体系结构的主要组件如下:
CPU
在矩阵工作负载中,标量处理非常重要。并非矩阵工作负载中的所有算法都能利用GPU或NPU。一般来说,这些工作负载中的算法有大量的标量整数和浮点运算,而这些算法不能从机器学习中获益。
加速器
将某些高开销功能卸载分担给加速器可以改善CPU的标量处理能力。一个例子是加速加密的加速器。对于矩阵工作负载,算术加速器至关重要。例如,Apple A13 AMX加速器将浮点算法提高了六倍。复杂的处理器组合,可以适应特定的矩阵工作负载。
X86在体系结构中添加了大量的专用指令,这些指令提供了大量的加速器。X86方法的区别在于,每个处理器都具有这些加速器,并且它提供了处理器优先的通用计算。HC的方法在将设计与工作负载进行匹配方面提供了更大的灵活性。
GPU(图形处理器单元)

图3:GPU和CPU架构的比较
来源:Wikibon 2020(根据Jill Reese和Sarah Zaranek改编 )
图3显示了GPU与CPU的不同之处。GPU具有数百个简单的算术单元。如果某个应用是计算密集型的,并将计算任务分解成数百个独立的工作元素,GPU就可以卸载分担这些计算或加速该应用。
GPU的主要任务是将图像、动画、视频和视频游戏渲染到PC、智能手机和游戏机的屏幕上。2D和3D图形利用的是多边形。多边形变换计算需要快速的浮点运算。图3所示的GPU AU阵列提供了这种能力。
一些非图形应用也可以使用GPU的原始能力。然而,GPU架构对于大多数矩阵工作负载来说并不理想。大多数矩阵不使用多边形,因此不使用很多浮点运算。整数运算比浮点运算快得多,耗电量也少得多。
当GPU加载完计算工作负载后再进行处理时,对非图形应用的效果最好,批量处理可以实现这一点。当批处理量较大时,如256个,GPU的工作效果最好。
然而,矩阵工作负载的实时元素将重点从批处理吞吐量转变为低延迟任务完成。合适的批次大小仅为1。新的瓶颈是移动、加载和卸载GPU中数据的进出。因此,矩阵工作负载的GPU瓶颈是系统内存和GPU内存之间的内存到内存通信,如图3所示。如果IT运营部门试图增加额外的GPU,就会导致扩展性差,降低GPU的利用率。
多年来,智能手机和iPad使用神经处理单元(NPU)来运行消费者级的矩阵工作负载。下一部分将介绍NPU,以及为什么在大多数矩阵工作负载中NPU比GPU更高效。
神经处理器单元(NPU)
神经网络(通常称为人工神经网络)是反映人脑结构的计算系统。神经网络单元(NPU)是计算架构的最新成员,旨在更加高效地运行矩阵工作负载。
Google员工为神经网络理论和硬件开发做出了重要贡献。例如Google的Ng和Dean创建了一个突破性的神经网络,该网络可以“自我学习”,以识别未标记图像中的高级概念。

图4:简单的神经网络
来源:©Wikibon 2020
图4显示了一个简单的神经网络。红色的输入节点从软件或连接的设备接收初始输入。两个蓝色隐藏层和绿色输出层中的每个节点或神经元都从左侧的神经元接收数据。
在图4的简单示例中,这些输入会与权重相乘,权重由两个神经元之间的连接深度来描绘。每个神经元将从左边的神经元收到的所有数据加起来。如果总和超过阈值,神经元就会触发与其连接的神经元(图4中右侧的神经元)。几乎所有的计算都是乘法/加法运算,并且从左到右进行。
在第一个周期中,输入神经元将数据发送到下一层后,一个连续过程处理为下一个周期加载数据和权重。在每个周期中,系统都会加载一小块数据和权重作为输入,短的数据块会从输出端卸载。以企业为例,Tesla FSD HW3系统具有96 x 96的输入阵列,并以2GHz的频率运行。两个NPU的总操作吞吐量为96×96×2个操作×2GHz(2个10^9)×2个NPU =〜73 TOPS。TOPS为每秒操作万亿次。
神经网络节点和连接数通常比图4中的要大得多。整数乘/加操作通常占代码的99.5%以上。此外,整数运算比浮点运算更快、功耗更低。使用32位整数乘法和8位整数仅需要0.2皮焦耳的功率。与浮点GPU相比,功耗和空间需求减少了三倍以上。整数数学的精度,足以满足大多数神经网络应用的需求。
为什么NPU需要SRAM
企业级Tesla HW3系统中两个NPU的数据输入和输出总数约为0.5KB×2GHz(10^9)x 2 NPU = 2TB/秒。带宽要求至少为4TB/秒,工作在大约64 GB /秒范围内的DRAM无法处理。因此,系统部署了64MB的SRAM。同时,SRAM移动32KB的数据只需要消耗20pj的能量,而使用DRAM则需要100倍的能量(2000pj)。
64MB的SRAM足以容纳神经网络程序、输入、权重和输出。SoC的设计可以在裸片上包含SRAM。
SRAM的缺点是它的成本比DRAM高得多,而且密度低1/3左右。SRAM在带宽和功耗上都比DRAM至少高一个数量级。苹果、MobilEye和Tesla都在NPU和HC上部署了大量的SRAM。
即使下一代处理器(例如IBM POWER系统和AMD服务器)具有PCIe Gen4接口,并且带宽是PCIe Gen3的两倍,但这仍然不足以支撑NPU。还必须考虑到,大量的下一代计算机将会以10-100 TB /秒的算力实现增长,并增长到PB /秒。
HC架构可以使用更小、更快的NPU,在大多数矩阵工作负载下,它们的扩展性都比GPU好得多。
训练NPU
神经网络的训练方法主要有三种,有监督、无监督和强化。最常见的是监督式训练,对结果的正确与否进行反馈。这种训练需要大量的标记数据。
反向传播是一套辅助神经网络训练的算法,用来识别事件或对象。该系统将实际输出与神经网络的预期输出进行比较,然后修改权重(图4中线条的粗细)以减小差异。网络从输出单元反向工作,通过隐藏神经元层到输入神经元。随着时间的推移,反向传播允许系统进行学习,使差异越来越小,最终达到精确的匹配。此时,神经网络已经“学习”了正确的输出,并为推理测试做好准备。这个训练过程是应用开发过程的一部分,需要大量的标签数据,而且几乎都是中心化的功能。
AI开发输出的是推理代码,在应用程序的生命周期中,推理代码通常占总计算量的99%。而推理代码不会学习。如果推理代码接收到相同的输入,它每次都会产生相同的结果,这对于合规性来说至关重要。Tesla利用这一事实,通过将所有的输入分别发送到两个处理器,并确保结果相同的方式,来自我检查硬件是否正确运行。
虽然NPU是新事物,但NPU的设计者和供应商数量众多。这些包括阿里巴巴、亚马逊、AmLogic、苹果、Arm、Flex Logic、谷歌、Graphcore、微软、NPX、高通、NationalChip、三星、RockChip、特斯拉等。
其它异构计算组件
这些包括DPU(数据处理单元)、DisplayPU(显示处理单元)、ASIC和FPGA。未来还有很大的发展空间。
DPU从CPU中分担以数据为中心的任务,包括数据传输、数据减少(压缩和重复数据删除)、安全和加密、随时间检查数据完整性、分析和自动化。Pensando等公司正在开发DPU解决方案。
DisplayPU专注于从GPU那里分担图形管理功能。DisplayPU在虚拟现实(VR)应用程序中特别有用,这是一种非常具有挑战性的实时矩阵工作负载。
苹果A13异构计算架构
在本项研究中,将苹果A13 SoC作为异构计算架构的早期例子进行了深入的关注。在相邻的研究中,Wikibon详细研究了企业级的Tesla FSD,这是一个先进的企业级HCA。
下图5是异构计算SoC Apple A13的芯片布局。该系统的组件是六个处理器,其中包括加速器,这些处理器占用了SoC面积的30%。其中还有一个GPU,占41%。将SoC变成异构计算体系结构的组件是NPU(面积占10%)、系统级缓存、以及48 MB的SRAM(面积占19%)。

图5:异构计算SoC的芯片布局,基于Arm的Apple A13
来源:Wikichip Wikibon于3/14/2020下载基于Apple Arm的A13芯片布局。Wikibon 2020。
正如在上面的“神经处理器单元(NPU)”小节中了解到的,在推理模式下,神经网络中最常见的运算是乘法/加法运算,占总数的99.5%。
Apple A13中的SRAM总量为48MB,批量购买成本约为30美元。SRAM允许组件之间的带宽大于5TB /秒,而正常情况下主内存和组件之间的带宽约为64 GB/秒。NPU中最常见的运算是乘法/加法运算,它在1个周期内完成。程序、权重、输入和输出都可以在SRAM中共享。NPU和CPU一直处于忙碌状态。假设不使用GPU,以保持功率低于6.2瓦。
这种架构极大地提高了处理的数据量。如果没有NPU、加速器、系统级缓存和SRAM,Apple A13 CPU将以12 GHz或0.012 TOPS的速度运行(请参见 下面脚注2表3中的第17行)。使用异构计算组件,矩阵工作负载的总吞吐量(请参见 下面脚注2表3中的第24和25行)为6(NPU)+ 1(CPU +加速器)= 7 TOPS。与非HCA Apple架构相比,增幅为7÷0.012=>500倍。同样,NPU是矩阵工作负载性能提升的原因。
总结:定义异构计算体系结构
- Wikibon将HCA定义为CPU、加速器、NPU、GPU和ASIC等其他组件的组合,以及灵活的、非常低延迟的高带宽存储和不同元素之间的互连。
- 异构计算体系结构可以支持具有NPU、加速器的矩阵工作负载,并改进所有其它组件与 SRAM 和一致的系统级缓存的集成。SRAM提供了存储空间、带宽和低功耗,可以驱动NPU 进行高效利用,并与其它组件互连。
- 通过在基于Apple Arm的移动和平板设备中增加NPU,Apple引领了异构计算体系结构的快速采用。苹果正在推出消费级扫描激光雷达(光检测和测距),并使用 NPU来驱动消费级的3D AR 矩阵工作负载。
- 苹果和谷歌现在正在使用NPU来从根本上改善面部识别、消费级摄影、视频、音频和虚拟现实服务的消费者软件功能。越来越多的ioS和Android开发人员正在快速开发矩阵应用程序,包括游戏应用程序。
- 具有异构计算架构特性的苹果 A13处理器的性能比没有 HCA 特性的 A13处理器的性能提高了500倍。
- 使用NPU的矩阵工作负载性能的提升要比GPU大得多,对SoC上真实空间的使用要少得多。可以很容易地增加多个NPU处理器,这对GPU来说是不行的。
- 至少在一段时间内,用于向屏幕输出图形的GPU将主要继续保持不变。许多基准都在使用一个公认的指标,即帧/秒(FPS)。更多的FPS意味着更好的用户体验。对于游戏应用来说,如果帧/秒更快,游戏就会更流畅。随着新算法的发展,NPU的图形输出用途可能会随着时间的推移而发展。
HCA与x86的性能和性价比
本节是对苹果iPhone 11 Pro Max的异构计算架构与传统的英特尔i7-1065G7第十代最新Ice Lake PC架构的性能和性价比进行的详细技术对比。
方法
这里的做法是将传统x86架构与异构计算架构的性能和性价比进行比较。这些比较是针对传统工作负载和实时矩阵(推理)工作负载进行分析的。估计和测量性能是一门科学也是门艺术。特别是要对来自不同系统架构的CPU、GPU和NPU,并运行不同的工作负载时进行对比,这一点尤其棘手。
这些比较的结果是帮助得出一个合理的估计,即在异构计算与传统x86架构上运行的传统工作负载和矩阵工作负载的性能和性价比。如果差异很大,则将支持这样的论点,即系统架构将发生根本性的转变。系统软件和应用程序的更改等因素将产生大量阻力,并延长发生这些根本性转变的时间。但是,收益越大、消除阻力的业务案例就越好,并且开发更高级的系统和应用软件的速度就越快。
选择的工作负载是使用Apple TrueDepth技术的面部识别系统。Apple目前没有此技术的可用版本。可以在下面的脚注部分的脚注3中找到这套矩阵工作负载的完整详细信息。在本实验中,作为地点位置管理者,您有责任选择运行该系统的平台。选择平台所需的部分信息是所选平台的性能和性价比。
架构比较
下图6的左侧展示了传统x86 Intel 17-1065G7处理器的处理器管芯布局。右边是基于Arm异构计算架构的Apple A13处理器的芯片布局。这颗芯片类似于上面“异构计算架构示例”小节中图5的分析。
英特尔i7-1065G7处理器SoC是传统的x86架构,主要用于从入门级到中型体积的移动PC。Gen 11 GPU与上一代GPU相比从24个执行单元增加到64个执行单元。这些组件与4个Sunny Cove CPU一起,通过系统级缓存、环形互连和8MB L3 last-level SRAM缓存(LLC)相互互连。SRAM的总数为17 MB。SoC和DRAM之间的通信具有大约64 GB /秒的内存带宽。

图6:英特尔i7-1065G7 Ice Lake SoC和基于Arm的Apple A13 SoC芯片布局。
来源:Wikibon于2020年3月14日由Wikichip Intel i7-1065G7 Die Layout下载。Wikibon于2020年3月14日下载基于 Wikichip Apple Arm的A13模具布局。Wikibon 2020。
图6的右侧是具有异构计算架构的基于Arm的Apple A13 SoC。有一个GPU、两个高速的Lightning CPU和四个缓速的Thunder CPU,还有一个NPU。它们都通过一个大的系统级缓存与大量的SLC SRAM相互连接。A13 SoC上的SLC SRAM总量为48MB,远高于传统的x86架构。因此,所有异构计算元件之间可以达到5 TB /秒的带宽,这比传统x86 Intel处理器快约100倍。
下面列出了通过比较上面图6中的两种体系结构得出的最重要的结论。
- GPU占用大量空间。英特尔GPU占据了处理器空间的57%,苹果GPU占据了41%。空间意味着面积、晶体管数量和耗电量。因此将额外的GPU添加到SoC以执行矩阵计算不是一个可行的选择。
- 关于芯片上的处理器专用空间,Apple需要45 mm^2、小于Intel 的72 mm^2。Apple A13裸片制造采用7nm与EUV(Extreme UltraViolet)工艺,比英特尔先进了两代。因此,苹果的晶体管密度更高,为1.16亿个/ mm^2。英特尔最早的宏伟目标是在其10nm晶圆上实现1.08亿个/ mm^2的密度,但由于生产良率和质量问题,不得不削减到6700万个/ mm^2(估计)。两种架构的处理器晶体管数量大致相同,这意味着两种CPU架构对于传统计算工作负载的预期性能很可能相似。
- A13的功率要求为6.2瓦,而英特尔处理器的功率为25瓦。在iPhone上,苹果公司重点使用了先进的7nm EUV制造工艺来降低功耗。苹果已做出大致声明,表示与以前的A12处理器相比,A13的性能提高了20%,功耗节省了35%。芯片上有足够的空间来为iPad添加更多功能,这些功能可以以最高15瓦的功率运行。可能针对Mac会出现更高性能,更高功率的基于Arm的SoC!
- 以上七个部分得出的总体结论是,像苹果A13这样的基于Arm的处理器对于传统工作负载的性能应该和英特尔x86处理器差不多。
- 对于矩阵工作负载的总体结论是,采用NPU的苹果A13的异构计算架构有可能比英特尔x86处理器快得多。
有关本节中的任何分析,请参见下面脚注1中的注意事项。
比较苹果和x86的性能和性价比
下表1是以下脚注 2中表3的摘要。它比较了传统x86架构和基于Arm的Apple异构计算架构的性能和性价比。工作负载性能分别有传统(显示为黄色行)和矩阵(显示为紫色行)。

表1:汇总表——比较在基于Arm的Apple异构计算和传统x86架构上运行的矩阵工作负载和传统工作负载的性能和性价比
来源:©Wikibon,2020年。有关其他行和解释,请参见脚注2中的表3 ,数据源,假设和计算的详细信息。
基于Arm的Apple异构计算体系结构的详细信息在表1的第二行和第三行中,在左侧以绿色表示。该产品是消费级的iPhone 11 Pro Max。搭载英特尔x86架构的Ice Lake i7-1065G7第十代CPU PC系统的详细信息在另一侧,以蓝色显示。
表1中的第21行展现了绿色数字表示的Apple HCA iPhone和蓝色数字表示的x86(设置为1)之间的性能比。工作负载设为传统时,其比值为0.95:1。这个比值是依据脚注2中表3的第19行和第20行,来自2019年Geekbench单核和多核成绩,并在表3后面的注释中描述。这个结果并不意外,因为基于Arm的系统的性能已经赶上了英特尔,并且在一些数据中心的领域超过了它。
表1中的第22行展示了传统工作负载的性价比对比。它们基于下面的表3第2-10行。英特尔x86系统的价格估计为1825美元(表3的第10行),基于iPhone 11技术的系统价格估计为505美元(根据实际价格(表3第10行)482美元÷表1第22行的0.95计算)。如第22行最后一列所示,性价比对苹果有利,为3.6:1。
表1中的第27行展现了绿色数字表示的Apple HCA iPhone与蓝色数字表示的x86(设置为1)的性能比为50:1。工作负载设置为矩阵,第23行最后一列的比值为50:1。这种计算很复杂,在下面的脚注表3之后的“矩阵工作负载的TOPS计算:第23-27行”小节中的注释中有详细说明。TOPS指的是每秒万亿次操作,是GPU营销中最常用的噱头数字。该表中的GPU声明已修改,以反映现实世界中实时矩阵工作负载的性能。表1第26行的TOPS等级是GPU + CPU + NPU的总和。对于Apple HCA,这个值是0 + 1 + 6 = 7,对于x86,这个值是0.11 + 0.03 + 0 = 0.14。比率是7÷0.14 = 50。差距如此之大的原因是,与实时矩阵工作负载中的GPU相比,带有SRAM的NPU的效率更高。
表1中的第28行显示了矩阵工作负载的性价比对比。它是由第22行÷第27行计算得出的。最后一列的性价比比值是190:1,并且具有NPU的基于Arm 的Apple系统比传统的x86平台便宜两个数量级。
表1中的第29行显示了4年期运行矩阵工作负载的不同体系结构的电力成本。计算结果包括电源成本、每千瓦时0.12美元的电费,以及比率为2的PUE(电源使用效率)。这两种架构之间的比值为179倍,Arm同样比传统x86平台的功耗低两个数量级以上。
其它异构计算平台
神经网络处理器单元(NPU)的其它供应商包括阿里巴巴、亚马逊、AmLogic、苹果、Arm、Flex Logic、谷歌、Graphcore、微软、NPX、高通、NationalChip、三星、RockChip、特斯拉等。这些厂商中的绝大多数都与Arm有着紧密的关系,是Arm的授权商。
Nvidia是该列表中的一个例外。Wikibon希望Nvidia将在18个月内填补这一空白,并将NPU纳入其CUDA软件框架。Nvidia其实也是Arm的授权方,与Arm长期合作。
总结:HCA与x86性能和性价比

表2:执行摘要表–适用于传统和矩阵工作负载的Arm主导的Apple异构计算和传统x86体系结构的性能与性价比之间的比较
来源:©Wikibon,2020年。请参见脚注中的表3和数据说明,以获取详细信息来源,假设和计算。
表2总结了基于Arm的Apple异构计算和传统x86架构之间的性能和性价比。传统工作负载显示在黄色行上,而矩阵工作负载显示在紫色行上。表2是上文“执行摘要”中图1的来源。
主要结论是:
- 对于传统工作负载,基于Arm的A13性能比x86(0.95:1)稍慢。性价比是后者的3.6倍。
- 对于矩阵工作负载,基于Arm的异构计算性能比x86快50倍。性价比超过150倍。
- 矩阵工作负载的电源成本和电源需求成本比传统x86架构节省了两个数量级。
Arm设计的重要性
分离处理器设计与制造
许多供应商表示,“企业级”计算比“消费级”设备需要更高级别的健壮性和恢复能力。这是事实,然而这些厂商忽略了处理器行业的根本变化。传统的处理器设计和生产的垂直整合已经发生了变化。现在处理器的制造和生产由台积电和三星等公司主导,处理器的设计由日本软银旗下的Arm主导。
Arm公司拥有一套合格的标准功能处理器组件设计组合。这些也是由合格的晶圆厂制造的。处理器厂商,如苹果、AWS、富士通、高通、微软、英伟达、三星、特斯拉等,可以专注于(可能)一两个组件的创新,其余的则采取标准组件。Arm公司已经推出了NPU。Arm公司已经将针对传统工作负载的Neoverse E1和N1服务器引入其设计组合中。AWS、富士通、微软、Nvidia、Tesla等公司已经在企业的高性能高可用性环境中使用基于Arm的处理器。
分离的好处
设计和制造分离的结果是,大幅缩短了处理器创新的周期。50:1的性能变化是一场设计革命,而不是进化。基于Arm的设计模型在处理器的组件级别就拥有了体积优势,而不是在更大的SoC级别。与x86相比,基于Arm的处理器已经占全球晶圆厂晶圆数量的10倍。这一数量降低了基于Arm的组件和SoC的成本。因此,才有了前面分析的性价比差异。
相比于传统的5年以上的集成处理器周期,这种分离对于消费类和企业级计算来说,是一个更高效的创新引擎。不同的实时矩阵工作负载将受益于运行在为该特定类型矩阵工作负载优化的架构上。Wikibon认为,由此产生的创新将从根本上改变这2020年代的服务器和系统架构,以及企业的计算分配策略。
分离的结果——推理服务器

图7:Arm NPU的技术细节
来源:Arm Ltd. 2020,数据由Wikibon编译
推理NPU现已投入量产。通过查看Arm的NPU设计范围可以说明NPU的引入速度。图7显示了Arm公司目前的NPU设计范围。Arm在2019年推出了其第一款NPU设计,即Ethos-N77。
Arm在2020年初推出了Ethos-U55。U55是一款适合小外形尺寸的微型NPU设计。
Arm Ethos-N78于2020年5月推出,规格有了显著改进。它现在支持台积电的6nm EUV技术。
目前Arm NPU设计的弱点是还不能支持较大数量的SRAM。当前,每个NPU限制为4MB。特斯拉每个NPU有32MB SRAM,与苹果处理器中的数量差不多。Wikibon希望在将来的设计版本中可以解决此问题。
目前,异构计算领域的领先者是消费级主导的开发专业技术和Arm主导的硬件系统。Arm主导的系统性能现在等于或超过传统的x86系统。Wikibon期望Arm主导的硬件、框架和软件在未来十年内将主导企业异构计算市场。
Wikibon预计,未来十年,AI推理系统将增长到AI系统支出的99%。开发训练部分将减少到1%左右。在早前的研究中,Wikibon预测到2020年代末,矩阵工作负载将增长到企业计算收入的42%。
分离结果——x86规模的分担和替换
大约20%的处理专用于管理存储和网络。这是相对容易分担的工作,特别是对于大型云数据中心来说。一个例子是AWS Nitro系统,它是EC2实例的基础平台,使AWS可以卸载存储和网络服务。此外,Nitro还可以帮助AWS改善这些服务的性能和安全性。另一个例子是最近被Nvidia收购的Mellanox,他们在ConnectX SmartNIC上用基于Arm的处理器卸载存储网络。诸如NVMe over Fabrics(NVMe-oF)存储的RDMA加速和高速视频传输等功能可以从通用CPU上卸载下来,性能更快,安全性更高。在基于Arm的专用服务器上可以更高效地处理特定工作负载的卸载将继续增长。
随着部分工作负载从x86迁移到基于Arm的服务器,基于Arm的服务器还将对云数据中心产生越来越大的影响。AWS和Microsoft Azure很好地完成了此过程。在re:invent 2019上,AWS宣布了AWS Graviton2处理器,该处理器由Amazon Web Services使用64位Arm Neoverse内核定制构建。这些内核可为AWS M6g、C6g和R6g EC2实例降低40%的成本,并提供同等或更好的性能。
此外,Arm还推出了Neoverse N1和E1高性能架构,作为x86处理器的高性能和低功耗直接替代品。Ampere现在正在发售Ampere Altra,这是一种基于Arm Neoverse N1平台的具有80个内核的64位Arm处理器。功耗仅为211瓦。
分离结果——市场影响
下图8显示了低成本和高性能的基于Arm的处理器将对企业服务器市场产生的影响。2019年企业服务器市场总额为760亿美元,Wikibon预计到本十年末它将增长到1130亿美元。从存储和网络功能迁移转到基于Arm的处理器的收入以蓝色显示。引入用于传统工作负载的Arm处理器的收入以绿色显示。最后,灰色显示了矩阵工作负载的引入,这将需要异构计算体系结构。

图8:按工作量细分的基于Arm的Enterprise Server增长
来源:Wikibon,2020年。此预测假定x86供应商的设计和生产策略不会发生重大变化。
Wikibon预测,到本十年末,企业服务器市场的72%将是基于Arm的服务器。这种迁移速度的根本原因是量产带来的成本降低,为特定工作负载而构建的服务器创新速度加快,因而能更好地利用晶圆厂,以及因为阿里巴巴、亚马逊、谷歌和微软等大规模云提供商而减少了来自软件相互不兼容而产生的障碍。需要强调的是,图8中的Wikibon预测假设x86厂商的设计和生产策略不会发生重大变化。
最后一点是,Arm Ltd.是软银在日本以外拥有的英国公司。许多欧洲和远东国家正悄悄地希望减少对美国处理器技术的依赖。
总结:Arm设计的重要性
- 处理器设计和制造的分离为消费级和企业级带来了更快的创新周期。苹果和特斯拉等公司可以通过对系统的其余部分使用基于Arm的标准设计来发展NPU创新。因此,创新时间减缩短了一半或更多。这会带来更多的设计和更高的产量,从而导致成本降低。
- 最大的云提供商正带头迁移到基于Arm的服务器,因为它们具有进行相应软件变更的规模效应。Arm的第一种用途是分担存储和网络压力,第二种是将Arm处理器用于特定的工作负载,第三种是使用基于Arm的异构体系结构。Wikibon预测,到本十年末,约有72%的服务器支出将用于更多种类的基于Arm的服务器。
全文结论
分离设计和制造,使得业界其它厂商在这两个领域的创新速度比x86厂商更快。领先的处理器晶圆厂使用7nm与EVA,并且正在部署5nm的道路上。更小的制程意味着速度更快,功耗也会降低一些。Arm是领先的设计者,拥有一套广泛的处理器组件,这使得处理器厂商可以把标准部件和设计精力集中在特定的差异化部件上。需要强调的是,本研究中的Wikibon Arm假设是x86供应商继续采用当前策略。
异构计算架构
本项研究表明,异构计算体系结构可以以比传统x86体系结构低两个数量级的成本运行矩阵工作负载。HC体系结构是由处理器的广泛选择和极高的带宽来定义的。苹果和特斯拉提供的性能最高的系统包括带有大量SRAM的神经网络处理器单元(NPU),以驱动其互连性和中间存储。这些系统能够以比带有集成GPU的传统x86系统快50倍的速度运行推理AI应用程序,并且性价比要高出150倍以上。Wikibon预测,这种运行矩阵工作负载成本的巨大变化将带来五个重大变化。
在未来五年内,将GPU用于非图形推理工作负载的速度将会放缓。它们仍将致力于多边形变换的工作负载。通常,NPU的较低成本和较高性能将带来部署NPU的新方法。随着NPU软件框架的成熟以及NPU专业技术的普及,这一趋势将加速发展。
处理器设计和制造的分离至少导致创新速度翻了一番。由设计公司Arm公司领导。苹果等处理器公司能够从Arm公司获得标准设计SoC组件,并专注于NPU等创新,以提高实时AI推理软件的性能。结果,这些应用程序以毫秒为单位交付结果,而不是几秒钟。
特斯拉能够构建定制的HW3异构计算系统,使用基于Arm的构建块在不到3年的时间内对其进行部署,并实现了比之前的GPU解决方案运行速度快21倍的解决方案。如果没有设计和制造分离,则需要6年以上的时间,且伴随着巨大的失败风险。
数据主导的运营架构
人类是过滤海量数据的专家,并使用神经网络来实现这一点。之后,他们只记住重要的东西,并丢弃输入的数据。基因组计算也是如此,它从海量数据开始,以超过100:1的倍数减少数据,只剩下大量描述染色体和基因的有用数据。
特斯拉是一家完全由数据主导的公司。它每秒钟从车队中所有正在行驶的车辆中持续捕获30亿字节的数据。HW3在处理所有这些数据时,要么是以影子模式(在影子模式下,它正在将自己的计划与司机的实际执行情况进行比较),要么是在司机偶尔的指导下实际自动驾驶汽车。只有特殊的数据才会被反馈回来,比如说,险些失误或事故。开发团队也可以要求采集特定的、异常的数据,比如看司机如何处理附近的大型动物。十分钟后,缓冲区的数据会被覆盖。
特斯拉的数据架构是一种数据导向的运营架构,如图2所述。这种数据处理的效率使特斯拉能够采集整个车队的数据。74 TOPS系统的成本约为1600美元,相机和传感器的成本约为1400美元。每辆汽车的成本为3000美元,特斯拉可以从其全球超过100万辆汽车的完整车队中采集数据。
以数据为主导的策略
特斯拉拥有所有数据,并可以探索使用此数据扩展传统汽车市场的新方法。例如,特斯拉唯一知道谁在驾驶以及驾驶状况如何,并且可以在数分钟内有选择地提供保险,或者提供住宿或用餐场所的选择。特斯拉与MobilEye断绝了关系,因为他们的长期商业利益不一致,特斯拉设计了一台计算机,以确保它仍然是一个数据主导的企业。
数据主导型企业的核心是能够在数据产生的地方实时提取数据的价值,并实现自动化。运行矩阵工作负载的异构计算架构、数据主导的运营架构、利用DataOps工具设计端到端的企业数据架构,都是建立数据主导的企业和文化的重要内容。
行动项目
IT主管
高级管理人员应该评估异构计算架构、矩阵工作负载和数据主导的运营架构如何协助或启动企业数据主导战略。Wikibon预计,如果不能在数据主导的矩阵工作负载上进行投资,将导致许多行业的业务失败,尤其是汽车行业。
服务器供应商主管
Wikibon希望在2026年及以后出现完整的5级自动驾驶软件和硬件。世界上大约有10亿辆各类车辆。每辆车的单价将在2000美元至5000美元之间。该行业的一些细分市场,如军用车辆,将会标注更高的价格。
从2024年开始,TAM市场的总规模约为4万亿美元,并在接下来的20年中逐步扩展,每年的TAM平均扩展规模为2000亿美元。升级换代的TAM将在每年装机量的10%左右。在政府认证和合规方面的专业知识将处于优势地位。
此外,还有一个相邻的固定和半移动的工业和消费设备市场,其单位成本较低,但整体TAM相似。
软件供应商主管
Wikibon将在未来的研究中讨论矩阵工作负载软件。
脚注:
脚注1
关于裸片布局,要提醒一下的是,英特尔并没有发布太多关于他们10纳米+SoC的详细信息。虽然WikiChips和维基百科有优秀的、知识渊博的贡献者,但他们并不是万无一失的!
脚注2

系统成本:第1-10行
绿色栏中的1-8行显示了Apple iPhone 11 Pro Max的拆解成本。 这项研究仅采用了创建异构计算服务器来运行面部识别软件(Matrix工作负载)所需的组件。例如,屏幕成本不包括在内。由于该产品的高消费量,因此成本很低。
红柱中的1-8行显示了英特尔系统的等效成本。处理器的费用来自英特尔网站。其它成本由Wikibon估算。一般来说,由于英特尔PC平台的架构和体积要小得多,所以连接组件的成本很高。
- 英特尔PC i7-1065G7处理器的价格是Apple A13处理器的6.7倍。
- 额外的PC系统组件比iPhone组件贵2.4倍。
第9行是两个面部识别系统的总物料清单成本,计算方式为第1-8行之和。
第10行是每个系统的预期销售价格,假设两个系统的提升幅度是第9行的2.5倍。
- 总体而言,带有PC 组件的面部识别系统比iPhone组件贵3.9倍。
- 这两个系统在传统工作负载下的性能大致相同,这将在下一部分中介绍。
测试计算传统工作量:第19-22行
本部分使用著名的跨平台测试软件Geekbench。它会运行单核和多核工作负载。每个单核工作负载都有一个多核对应的工作负载。有三种工作负载类型。它们分别是密码学(5%的权重)、整数(65%)和浮点(30%)。假设和计算如下:
- 所有行均为黄色,并评估两种体系结构上的传统工作负载。
- Geekbench是跨平台基准测试,具有单核和多核打分。
- 假设i7-1065G7没有外部GPU,并且没有外置散热。
- 第19行是两个平台在正确瓦数下的单核Geekbench 5得分。
- 第20行是两个平台在正确瓦数下的多核Geekbench 5得分。
- Apple A13平台的第21行是(A13单核和多核分数的调和平均值)÷(i7-1065G7单核和多核分数的调和平均值)= 0.95
- 英特尔i7-1065G7平台的第21行设置为1。对于传统工作负载,A13比i7-1065G7的性能慢5%左右。
- 第 22 行显示了性价比。配置的销售价格显示在第10行。第22行=第10行/第21行。Intel i7-1065G7系统的价格性能是Apple A13系统的3.6倍。
- 结论:基于Arm的移动设备苹果在传统工作负载性能方面已经赶上了x86移动设备,并且性价比高出三倍以上。
未来Wikibon的研究将表明,Arm已经赶上了x86数据中心处理器,并提供了更好的性价比。
虽然有许多基准测试,但跨平台基准测试很少。基准测试只是数据点。对第11至18行的分析还表明,英特尔和苹果移动处理器的传统工作负载性能可能是相似的。在一些特定的传统工作负载中,会有其中一个系统发挥作用。
矩阵工作负载分析显示了一个截然不同的故事。
矩阵工作量的TOPS计算:第23-27 行
用来评估系统性能的另一个指标是TOPS或每秒操作数。该过程是获取系统的所有组件,并为每个组件累加TOPS值。例如,如果CPU的TOPS值为0.5,GPU的TOPS值为1,而NPU的TOPS值为6,则整个系统的TOPS值为7.5。您可能会想到,营销部门喜欢此指标的简单性。
正如之前所说,性能指标只是信息。总体TOPS数据指的是,在工作负载允许每个组件以100%运行时,系统可以运行的最大速率。当然,这种利用率实际上是不可能实现的。
Wikibon研究表明,GPU具有最高的TOPS等级,并且是高估矩阵工作负载性能的最大罪魁祸首。Wikibon的方法是将这一指标原封不动地用于处理器和NPU,并根据可实现的大致利用率百分比调整GPU的TOPS值。
- 第23-27行为紫色,用于评估两种体系结构上的矩阵工作负载性能。
- 英特尔将i7-1065G7 中GPU 的峰值速率定为1.024 TOPS,峰值频率为1.1 GHz。但是,保证的基本额定值为0.3 GHz。因此,保证的TOPS = 1.024×0.3÷1.1 = 0.28 TOPS。一个合理的假设是,此GPU的可持续吞吐量约为保证速率的2倍,即0.28×2 = 0.56 TOPS,以保持在25瓦功率限制内。
- 同样,用于实时矩阵工作负载的任何GPU都需要具有批处理大小= 1的设置。这个设置优化的是延迟,而不是吞吐量。但是,根据粗略的经验,此设置意味着吞吐量将下降到可持续吞吐量的大约10%-20%。在下面的计算中,假设为20%。
- Wikibon评估英特尔GPU对实时矩阵工作负载的持续TOPS等级是0.56×20%= 0.11 TOPS。结果显示在蓝色列的第23行中。
- 假定不使用Apple A13的GPU(将其设置为0 TOPS)以将功率保持在6.2瓦以下。结果显示在上面表3的第23行的绿色栏中。
- i7-1065G7有4个核心,每个核心带有两个线程,主频为3.5 GHz。TOPS等级为2×4×3.5÷1,000 = 0.028 TOPS。 结果显示在上面表3的第24行的蓝色栏中。
- 苹果公司将带有加速器的处理器定为1 TOPS。上面表3中第24行的绿色栏中显示了这一点。
- 由于i7-1065G7没有NPU,因此值为0 TOPS。苹果将A13 NPU评为6 TOPS。 这些显示在上面表3的第25行中。
- i7-1065G7的总TOPS为0.11 + 0.028 + 0 = 0.14 TOPS。苹果A13的总TOPS = 0 + 6 + 1 = 7 TOPS。 这些显示在上面表3的第26行中。
- TOPS性能之比A13 / i7-1065G7 = 7:0.14 = 50:1。这些在上面表3的第27行中显示。
- 结论:
- 用于确定不同架构下矩阵工作负载的相对性能,TOPS并不是一个很好的指标。Wikibon已经调整了GPU的TOPS评级,提高了准确度,但它并不是一个可靠的指标。
- 这个性能研究的结果有不完善之处,但它表明采用NPU的异构架构比采用GPU的传统架构快50倍。
- 这是一个合理且极有可能得出的结论,即异构体系结构比矩阵工作负载的传统方法快一个数量级。
注意:AI训练工作负载 不是 矩阵工作负载,因为它不是实时的。训练工作负载通常是分批的,这将显著提高GPU吞吐量。目前,训练在AI计算能力中占比很高,但在这十年中,推理将更加重要。
矩阵工作负载的性价比计算:第28 行
- 矩阵工作负载的价格-性能是通过取第10行的销售价格除以第27行的相对性能计算出来的(x86=基数)。异构计算的每性能单位价格为9.62美元,传统体系结构的每单位性能价格为1825美元。比率为190:1,有利于异构计算。
- 结论:一个合理且极有可能得出的结论是,异构体系结构比矩阵工作负载的传统方法要便宜两个数量级。
电力成本:第29行
表1中的第29行显示了运行矩阵工作负载的不同体系结构的4年电力成本。计算包括电源成本(第8行),每千瓦时0.12美元的电费,并假设PUE(电源使用效率)比率为2。两种架构之间的比值为179倍,同样比传统x86平台的功耗低两个数量级以上。
结论:
- 上表3在两边均使用了TOPS这个说法。TOPS对于实际工作来说是一个失败的指标。该指标易于计算,但大幅高估了实际效果。即使Wikibon进行了复杂的修改,它也远不能可靠地给出真实世界应用的性能。
- Wikibon对异构计算和传统计算之间的50:1的比例应该谨慎对待。但即便如此,这个比例仍然很可能很高。
- 一个更好的长期衡量标准和性能估计基础是不同矩阵工作负载的多个基准数据。
- 矩阵工作负载非常不同,在传统体系结构上无法很好地工作。
- Apple A13异构计算体系结构更适合这些工作负载,并且可以通过多个NPU扩展并行性,以处理更大的工作负载。
- 未来的Apple A13X和A14芯片将具有更高的性能,更大的峰包功率和改进的体系结构。
- Apple / TSMC和Google /三星在消费级矩阵应用程序上进行了大量投资,其创新率很高。
- 企业矩阵工作负载不太可能在GPU或传统x86架构上很好地工作。基于Arm的解决方案似乎将成为在移动、PC、分布式服务器和数据中心解决方案中运行矩阵工作负载的主流。
脚注3:面部识别矩阵的工作量
这种理想型实验的工作负载是设计一个面部识别系统,以百分之百的信心确保没有未经授权的人无法进入高度安保的设施。这里有一个合规性要求,就是要有一个特定的记录,记录任何人在任何时候进入或曾经进入过该设施。每天都有成千上万的人进出该设施。入口和出口的数量有限。
被授权进入的每个人都拥有一个机器可读的卡。该系统的工作是读取卡,使用红外3D光扫描面部,并将输入系统中记录的面部与系统中保存的面部记录进行比较。只有本人持卡亲临现场,持必要的授权文件,才能将新的人脸记录录入系统。此时人脸数据才会被录入系统。
为了避免潜在地滥用面部数据(例如更改面部数据记录),面部数据只能保存在该站点上,不能被任何其它应用程序访问,也不能被面部识别系统以外的任何其他设备读取或写入。必须对每一次访问面部数据的行为进行不可更改的记录,但面部数据不包括在此记录中。在任何试图访问这些数据的情况下,面部数据必须自毁。
显然,手动系统不能满足百分之百的要求。这个理想型实验中的一个假设是Apple商业化并提供了运行面部TruDepth识别系统的软件。(云科技时代编译)
【原文链接:https://wikibon.com/Arm-yourself-heterogeneous-compute/ 】