大数据Hadoop分布式集群部署(详细版)
大数据Hadoop分布式集群部署(详细集群)
一、 搭建思路
1. 软件版本
本文 介绍大数据平台Hadoop的分布式环境搭建,为保证大家都可以在自己的电脑上使用,我们选取在VMware Workstation Pro 12.0以上版本的虚拟机上部署5台CentOS-7系统模拟5台服务器。Java jdk环境采用jdk-1.8以上版本,Hadoop采用hadoop-2.8.3版本
2. 节点地址规划
下表为地址规划表,地址规划以及与主机名的映射关系如下表所示:master1地址为192.168.150.101;master2地址为192.168.150.102;slave1地址为192.168.150.103;slave2地址为192.168.150.104;slave3地址为192.168.150.105。
| 序号 |
主机名 |
IP地址 |
掩码 |
网关 |
DNS |
| 1 |
master1 |
192.168.150.101 |
255.255.255.0 |
192.168.150.2 |
8.8.8.8 |
| 2 |
master2 |
192.168.150.102 |
255.255.255.0 |
192.168.150.2 |
8.8.8.8 |
| 3 |
slave1 |
192.168.150.103 |
255.255.255.0 |
192.168.150.2 |
8.8.8.8 |
| 4 |
slave2 |
192.168.150.104 |
255.255.255.0 |
192.168.150.2 |
8.8.8.8 |
| 5 |
slave3 |
192.168.150.105 |
255.255.255.0 |
192.168.150.2 |
8.8.8.8 |
3. 每节点资源规划
每台主机的资源配置如下表,后期也可以根据需要动态调整资源(vCPU的资源可以大于物理CPU 2倍左右,比如你的电脑只有4核,可以虚出8 vcpu)
| 序号 |
主机名 |
IP地址 |
内存 |
cpu |
硬盘 |
| 1 |
master1 |
192.168.150.101 |
2G |
1 |
100 |
| 2 |
master2 |
192.168.150.102 |
2G |
1 |
100 |
| 3 |
slave1 |
192.168.150.103 |
1G |
1 |
100 |
| 4 |
slave2 |
192.168.150.104 |
1G |
1 |
100 |
| 5 |
slave3 |
192.168.150.105 |
1G |
1 |
100 |
4. 系统账号和密码
| 序号 |
主机名 |
IP地址 |
管理账号/密码 |
普通用户/密码 |
| 1 |
master1 |
192.168.150.101 |
root/huawei@123 |
hadoop/huawei@123 |
| 2 |
master2 |
192.168.150.102 |
root/huawei@123 |
hadoop/huawei@123 |
| 3 |
slave1 |
192.168.150.103 |
root/huawei@123 |
hadoop/huawei@123 |
| 4 |
slave2 |
192.168.150.104 |
root/huawei@123 |
hadoop/huawei@123 |
| 5 |
slave3 |
192.168.150.105 |
root/huawei@123 |
hadoop/huawei@123 |
5. 节点功能规划
以下为Hadoop节点的部署图,将NameNode部署在master1,SecondaryNameNode部署在master2,slave1、slave2、slave3中分别部署一个DataNode节点。
| 序号 |
主机名 |
IP地址 |
Namenode |
Secondnamenode |
Datanode |
| 1 |
master1 |
192.168.150.101 |
Y |
|
|
| 2 |
master2 |
192.168.150.102 |
|
Y |
|
| 3 |
slave1 |
192.168.150.103 |
|
|
Y |
| 4 |
slave2 |
192.168.150.104 |
|
|
Y |
| 5 |
slave3 |
192.168.150.105 |
|
|
Y |
6. 节点文件目录规划
| 序号 |
主机名 |
IP地址 |
软件存放目录 |
软件安装目录 |
文件测试目录 |
| 1 |
master1 |
192.168.150.101 |
/opt/software |
/opt/hadoop |
/opt/test |
| 2 |
master2 |
192.168.150.102 |
/opt/software |
/opt/hadoop |
/opt/test |
| 3 |
slave1 |
192.168.150.103 |
/opt/software |
/opt/hadoop |
/opt/test |
| 4 |
slave2 |
192.168.150.104 |
/opt/software |
/opt/hadoop |
/opt/test |
| 5 |
slave3 |
192.168.150.105 |
/opt/software |
/opt/hadoop |
/opt/test |
二、 环境准备
1. VMware Workstation Pro 虚拟机安装
详细的搭建过程及其相关软件链接如下(仅参考 第三部分基础平台搭建,第1小结VMware 虚拟机安装调试即可):https://blog.csdn.net/arnoldmapo/article/details/104964971
2. CentOS-7-x86_64操作系统安装
详细的搭建过程及其相关软件链接如下(仅参考 第三部分基础平台搭建,第2小结VMware 虚拟机安装调试即可):https://blog.csdn.net/arnoldmapo/article/details/104964971
三、 设置每台主机环境满足规划需求
1. 将安装好的操作系统做个原始系统的快照备份,以便出问题时候还原
1) 右击系统名称master1,找到快照,点击快照拍摄
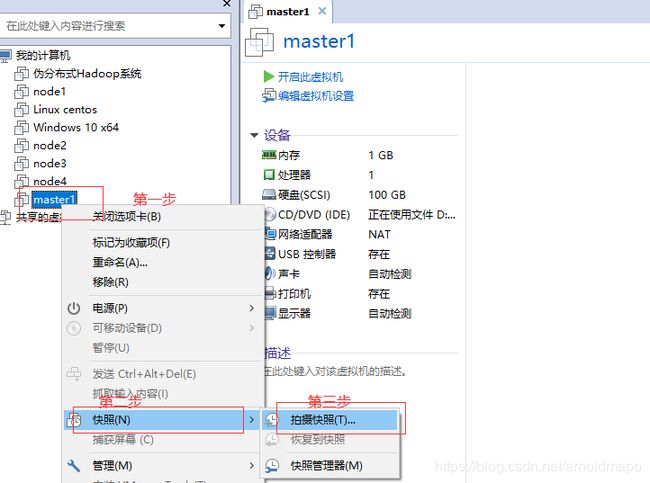
2) 拍摄快照,设置描述

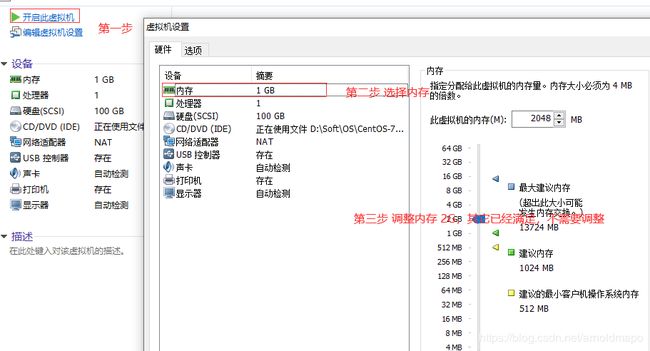
2. 按搭建思路的系统资源分配要求调整资源分配(如果已经有操作系统可以直接在此基础上修改成我们需要的系统环境)。
1) 调整硬件需求,内存2G,处理器1核,硬盘100G
3. 调整IP地址
1) 开启已经安装好的操作系统。
2) 右击打开终端,通过ifconfig命令查看地址是否满足
使用命令:ifconfig

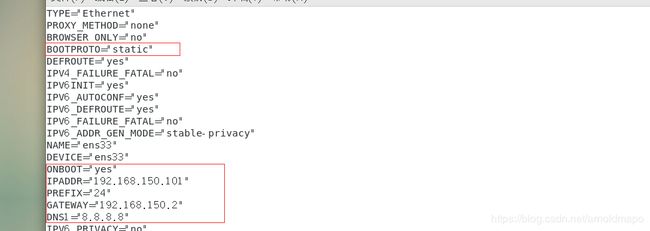
3) 永久修改IP地址
使用命令:vi /etc/sysconfig/network-scripts/ifcfg-ens33
![]()
4) 重启网卡
使用命令:service network start
![]()
4. 测试连通性,并实现第三方插件远程登陆
使用命令:ping
使用第三方软件:MobaXterm


5. 修改主机的名称(如果已经修改,则不需要)
使用命令:hostnamectl set-hostname master1

重新登陆一次root用户才能看到修改成功
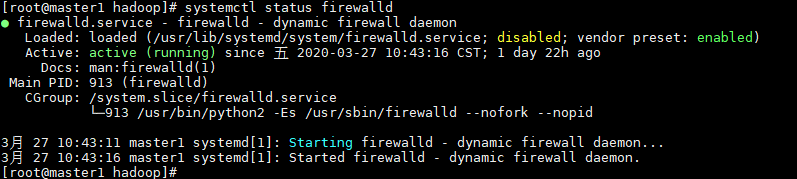
6. 关闭系统防火墙功能
1) 查看防火状态
使用命令:systemctl status firewalld
2) 永久关闭防火墙
使用命令:systemctl disable firewalld
7. 创建一个普通用户与组
1) 创建普通用户组
使用命令:groupadd hadoop

2) 创建普通用户
使用命令: useradd hadoop -m -g hadoop
3) 设置用户密码
使用命令:passwd hadoop

8. 按照规划创建文件夹
1) 软件存放目录/opt/software,测试目录/opt/test,软件安装目录/opt/hadoop。
使用命令:mkdir software
mkdir test
mkdir hadoop

9. 修改主机名与服务器的映射关系
使用命令:vi /etc/hosts
192.168.150.101 master1
192.168.150.102 master2
192.168.150.103 slave1
192.168.150.104 slave2
192.168.150.105 slave3

10. 按照刚刚设置好的主机master1再克隆1台主机,并按照每个节点要求调整对应参数
1) 关闭计算机,克隆1台主机

2) 下一步

3) 勾选虚拟机中的当前状态

4) 勾选创建完整克隆

5) 设置安装位置

6) 等待2分钟,完成克隆
7) 完成克隆
8) 打开主机,按照主机规划设置相应参数,并调整IP地址,完成登陆(可参考第三步搭建设置每台主机环境的步骤)
11. 同理按照第9步骤过程克隆出slave1、slave2、slave3
1) 测试连通性
使用命令:ping master1

![]()

![]()

12. 主机之间配置免密码登录(每台主机重复配置)
1) 切换至hadoop用户
使用命令:su Hadoop

2) 生成公私钥
使用命令:ssh-keygen -t rsa
3) 拷贝公钥到各个服务器
使用命令:ssh-copy-id hadoop@master1
ssh-copy-id hadoop@master2
ssh-copy-id hadoop@slave1
ssh-copy-id hadoop@slave2
ssh-copy-id hadoop@slave3

同样操作省略
4) 在每一台设备同样操作,保证每个设备相互之间都可以ssh登陆
使用命令:ssh master1
成功的免密登陆
5) 退出登陆
使用命令:exit
四、 Hadoop集群安装步骤
1. 软件包下载
1) 下载Hadoop软件包
官网地址:https://archive.apache.org/dist/hadoop/common/hadoop-2.8.3/
云盘地址:https://pan.baidu.com/s/14EsLaoY1rPMYwTehDhxdvQ 提取码:mfo3
2) 下载Java jdk-8u231-linux-x64.tar环境安装包
云盘地址:https://pan.baidu.com/s/1h6qrNM10B6Vl-3p06lLpEg 提取码:j071
3) 上传文件到/opt/software目录中

2. 修改文件权限
1) hadoop、software、test文件的属主为hadoop、属组为hadoop,否则后面hadoop用户会没有操作权限
使用命令:chown -R hadoop:hadoop /opt/software
chown -R hadoop:hadoop /opt/test
chown -R hadoop:hadoop /opt/hadoop

3. jdk-8u231-linux-x64.tar Java jdk环境安装
1) 解压缩安装jdk
使用命令:tar zxvf jdk-8u231-linux-x64.tar.gz -C /opt/hadoop/

查看已经成功安装解压,使用命令:ls

2) 重命名文件夹,便于后面调用编写
使用命令:mv jdk1.8.0_231/ jdk1.8

3) 设置JAVA_HOME
将jdk环境路径插入到目录最下方
使用命令:vi ~/.bashrc
export JAVA_HOME=/opt/hadoop/jdk1.8
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar


4) 应用变量
使用命令:source ~/.bashrc
![]()
5) 查看使用版本情况
使用命令:java -version

4. hadoop-2.8.3.tar Hadoop 环境安装调试
大致可以看到,解压后的目录如上图:

bin目录下是常用的一些执行任务的脚本,比如我们用的hdfs相关的shell,hadoop相关的一些提交任务的脚本,都在这里。
etc下就只有一个目录,叫做hadoop,用途就是我们hdfs,mapreduce,yarn运行中的各种配置,非常重要,常用的一些调优,配置都在这里,后面做配置就是到这个目录下的hadoop中进行配置。
sbin目录,里面大部分是启动服务的脚本,与bin不同,这里是用于启动hdfs,启动yarn的,用于支撑我们其他服务的运行,hdfs和yarn后面的启动命令就存放于此。
share文件夹,里面是我们hadoop常用的很多包,这就可以解释为什么我们执行任务时候直接以hadoop jar的方式就能够正常运行一些包了,因为很多的第三方的包,都已经由hadoop默认给我们加载了;这也启发我们,如果想要对hadoop底层一些东西进行修改的话,我们可以把这里面的jar包的源码下载下来,自己进行修改,然后重新打包运行,就可以达到满意的效果了,我们的单词统计实验就是用到里面的hadoop-mapreduce-examples-2.8.3.jar包。
在启动完hdfs系统后还会定义产生data目录,用于存放hadoop使用过程中一些临时数据,。
1) 解压缩安装Hadoop
使用命令:tar zxvf /opt/software/hadoop-2.8.3.tar.gz -C /opt/hadoop/![]()
2) 重命名文件夹
使用命令:mv hadoop-2.8.3/ hadoop

3) 设置Hadoop环境变量
使用命令:vi ~./.bashrc
export HADOOP_HOME=/opt/hadoop/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
![]()

4) 应用变量
使用命令:source ~/.bashrc
5. 配置hadoop文件
1) 进入配置目录配置文件
使用命令:cd /opt/hadoop/hadoop/etc/hadoop/
2) 配置 Core-site.xml
使用命令:vi core-site.xml

3) 配置Hdfs-site.xml
使用命令:vi hdfs-site.xml
![]()

4) mapred-site.xml
由于Hadoop文件中没有携带mapred-site.xml文件,但是可以有mapred-site.xml.template复制过来
使用命令: cp mapred-site.xml.template mapred-site.xml
![]()
使用命令:vi mapred-site.xml
![]()
配置文件
![]()
5) yarn-site.xml
使用命令:vi yarn-site.xml
![]()

6) 配置slaves
使用命令:vi slaves
slave1;slave2;slave3

7) 设置hadoop-env.sh环境变量
使用命令:vi hadoop-env.sh
export JAVA_HOME=/opt/hadoop/jdk1.8 (修改成绝对路径)
export HADOOP_CONF_DIR=/opt/hadoop/hadoop/etc/hadoop
![]()
8) 设置yarn-env.sh环境变量
使用命令:vi yarn-env.sh
export JAVA_HOME=/opt/hadoop/jdk1.8
![]()
9) 设置mapred-env.sh环境变量
使用命令:vi mapred-env.sh
export JAVA_HOME=/opt/hadooo/jdk1.8
![]()
![]()
10) 应用环境变量
使用命令:. yarn-env.sh;. mapred-env.sh;. hadoop-env.sh
6. 将master1配置好的hadoop分别远程传递给master2,slave1,slave2,slave3
1) 进入root,修改其它节点opt属主和属组为hadoop:hadoop
使用命令:chown -R hadoop:hadoop /opt/

其它三个节点同理修改opt属主和属组为hadoop:hadoop
2) 将hadoop远程传递给master2,slave1,slave2,slave3
使用命令:scp -r /opt/hadoop hadoop@master2:/opt/
scp -r /opt/hadoop hadoop@slave1:/opt/
scp -r /opt/hadoop hadoop@slave2:/opt/
scp -r /opt/hadoop hadoop@slave3:/opt/
![]()
![]()
![]()
![]()
7. 讲master1设置好的bashrc环境变量分别传递给master2,slave1,slave2,slave3,并运行
1) 变量传递
使用命令:scp -r .bashrc hadoop@master2:~
scp -r .bashrc hadoop@slave1:~
scp -r .bashrc hadoop@slave2:~
scp -r .bashrc hadoop@slave3:~

2) 变量运行
使用命令:source .bashrc

![]()
![]()
![]()
五、 启动集群平台
1. 如果集群是第一次启动,需要格式化namenode
使用命令:hdfs namenode -format
需要看到成功

3) 启动hadoop服务
可以一次性全部启动
使用命令:start-dfs.sh、start-yarn.sh或者使用命令start-all.sh(这个命令已经被弃用)
![]()
![]()
可以单独一个个服务启动
使用命令:
hadoop-daemon.sh start namenode
hadoop-daemon.sh start datanode
hadoop-daemon.sh start secondarynamenode
yarn-daemon.sh start resourcemanager
yarn-daemon.sh start nodemanager
各个服务显示已经启动成功

4) 查看java进程状态命令
使用命令: jps





5) 查看接口服务情况
使用命令:ss -tnl
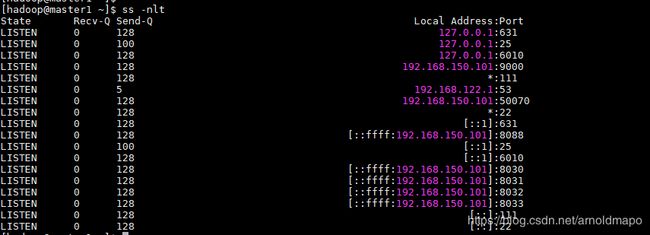
6) 浏览器中访问50070的端口,如下证明集群部署成功
Namenode节点
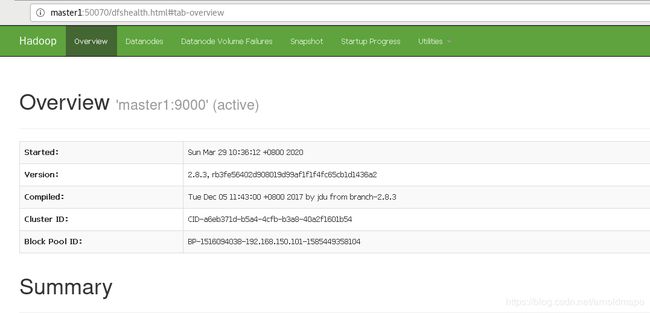
数据节点3个

六、 平台环境测试
可以通过单词统计实验测试平台使用练习,具体测试文档参考链接:
https://blog.csdn.net/arnoldmapo/article/details/105025816
七、 参考文档
http://hadoop.apache.org/docs/r2.8.3/