- 2025.03.22【读书笔记】| fastq-multx:高效barcode拆分数据解决工具
穆易青
读书笔记数据处理读书笔记linux运维服务器
文章目录1.工具介绍为什么需要`fastq-multx`?`fastq-multx`的特点2.安装方式通过源代码编译安装使用包管理器安装3.使用命令基本命令高级参数设置结语1.工具介绍在生物信息学的世界里,工具的选择至关重要。今天,我们要介绍的这个工具,就是fastq-multx,一个用于高效barcode去复用和demultiplex的解决方案。fastq-multx是一个专门设计用于处理高通量
- 基于Azure云平台构建实时数据仓库
weixin_30777913
云计算azure开发语言sparkpython
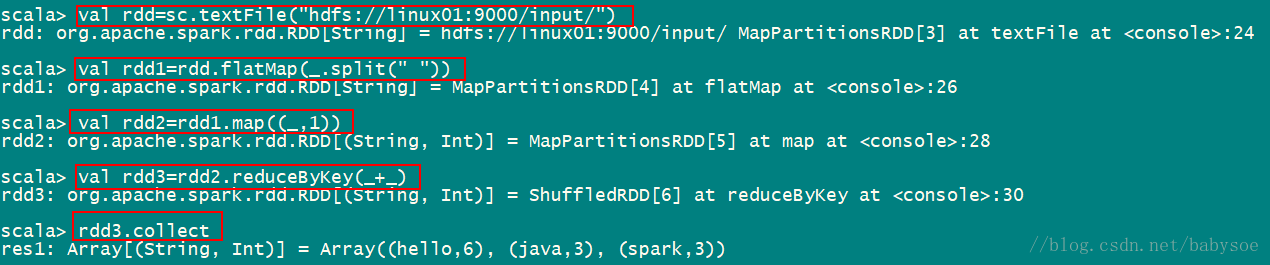
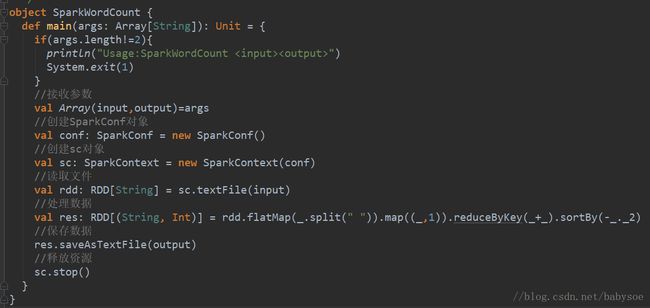
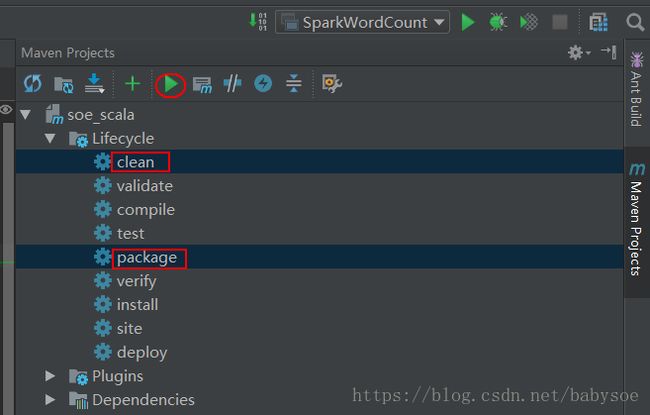
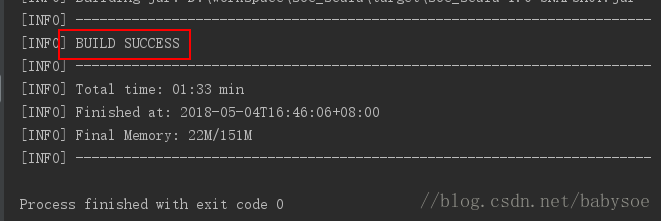
设计Azure云架构方案实现AzureDeltaLake和AzureDatabricks,结合电商网站的流数据,构建实时数据仓库,支持T+0报表(如电商订单分析),具以及具体实现的详细步骤和关键PySpark代码。一、架构设计[电商网站]→[AzureEventHubs]→[AzureDatabricksStreaming]↓[AzureDeltaLake]←→[DatabricksSQLAnal
- 《java面向对象(5)》<不含基本语法>
java小白板
java开发语言
本笔记基于黑马程序员java教程整理,仅供参考1.异常1.1异常分类1.1.1Error指系统级别的错误,程序员无法解决,不必理会1.1.2Exception(异常)分为两类:RuntimeException:运行时异常,编译时程序不会报错,运行时报错,如数组越界其他异常:编译时异常,编译时就会报错运行时异常:publicclassText{publicstaticvoidmain(String[
- S32K144入门笔记(二十):eDMA的API函数解读
上层精灵的赞美诗
S32K144入门笔记系列单片机嵌入式硬件eclipsemcu笔记
文章目录1.SDK中的函数2.API函数的释义1.SDK中的函数在SDK中并没有转为PDB设置专门的PAL驱动,在基本的DRIVER库中一共有32个API函数,本文将解读这些函数的功能。2.API函数的释义status_tEDMA_DRV_Init(edma_state_t*edmaState,constedma_user_config_t*userConfig,edma_chn_state_t*
- Neo4j GDS-02-graph-data-science 插件库安装实战笔记
老马啸西风
neo4jneo4j笔记数据库图数据结构算法
neo4japoc系列Neo4jAPOC-01-图数据库apoc插件介绍Neo4jAPOC-01-图数据库apoc插件安装neo4jonwindows10Neo4jAPOC-03-图数据库apoc实战使用使用Neo4jAPOC-04-图数据库apoc实战使用使用apoc.path.spanningTree最小生成树Neo4jAPOC-05-图数据库apoc实战使用使用labelFilterNeo4
- 笔记本装机系统选择指南
mmoo_python
windows
笔记本装机系统选择指南在众多笔记本用户中,选择一款合适的装机系统始终是一个热门话题。不同的系统不仅影响着电脑的性能,还关乎用户的使用体验和安全性。那么,在众多装机系统中,哪款最适合你的笔记本呢?本文将为你推荐几款热门的笔记本装机系统,帮助你做出明智的选择。一、游戏本专用:Windows1064位性能优化专业版对于游戏爱好者来说,一款高性能的游戏本是必不可少的装备。而为了充分发挥游戏本的潜力,一个专
- Effective Modern C++ 条款6:auto推导若非己愿,使用显式类型初始化惯用法
举个栗子2
EffectiveModernC++c++
更多C++学习笔记,关注wx公众号:cpp读书笔记Item6:Usetheexplicitlytypedinitializeridiomwhenautodeducesundesiredtypes在Item5中解释了比起显式指定类型使用auto声明变量有若干技术优势,但是有时当你想向左转auto却向右转。举个例子,假如我有一个函数,参数为Widget,返回一个std::vector,这里的bool表
- 跟着黑马学MySQL基础篇笔记(1)-概述与SQL
小杜不吃糖
mysql笔记sql
03.安装与启动启动netstartmysql80netstopmysql80客户端连接mysql[-h127.0.0.1][-P3306]-uroot-p04.mysql数据模型关系型数据库RDBMS05.通用语法及分类DDL:数据定义语言,用来定义数据库对象(数据库,表,字段)DML:数据操作语言,用来对数据库表中的数据进行增删改DQL:数据查询语言,用来查询数据库中表的记录DCL:数据控制语
- SSM卫生人员评审专家申报系统
浅浅学姐
课程设计毕业设计服务器运维java开发语言数据库后端
点赞+收藏+关注→添加文档最下方联系方式咨询本源代码、数据库本人在Java毕业设计领域有多年的经验,陆续会更新更多优质的Java实战项目希望你能有所收获,少走一些弯路。关注我不迷路项目视频SSM347的卫生人员项目申报评审管理系统资料介绍一、设计说明1.1研究背景面对大量的信息,传统的管理系统,都是通过笔记的方式进行详细信息的统计,后来出现电脑,通过电脑输入软件将纸质的信息统计到电脑上,这种方式比
- SSM卫生人员评审专家申报系统
Plume98
课程设计毕业设计服务器运维java开发语言数据库后端
点赞+收藏+关注→添加文档最下方联系方式咨询本源代码、数据库本人在Java毕业设计领域有多年的经验,陆续会更新更多优质的Java实战项目希望你能有所收获,少走一些弯路。关注我不迷路项目视频SSM347的卫生人员项目申报评审管理系统资料介绍一、设计说明1.1研究背景面对大量的信息,传统的管理系统,都是通过笔记的方式进行详细信息的统计,后来出现电脑,通过电脑输入软件将纸质的信息统计到电脑上,这种方式比
- HCIA-AI人工智能笔记3:数据预处理
噗老师
华为认证人工智能笔记wpf数据处理AI华为认证
统讲解数据预处理的核心技术体系,通过Python/Pandas与华为MindSpore双视角代码演示,结合特征工程优化实验,深入解析数据清洗、标准化、增强等关键环节。一、数据预处理技术全景图graphTDA[原始数据]-->B{数据清洗}B-->B1[缺失值处理]B-->B2[异常值检测]B-->B3[重复值删除]A-->C{特征工程}C-->C1[标准化/归一化]C-->C2[离散化分箱]C--
- 网络安全-信息收集
One_Blanks
网络安全网络安全
声明学习视频来自B站UP主泷羽sec,如涉及侵权马上删除文章。笔记的只是方便各位师傅学习知识,以下网站只涉及学习内容,其他的都与本人无关,切莫逾越法律红线,否则后果自负。目录X一、Whois信息1.思路2.工具3.社工库二、搜索1.Google、bing、baidu三、Github四、搜索引擎FOFA:[https://fofa.info/](https://fofa.info/)360网络空间测
- 笔记-LeetCode 787: K 站中转内最便宜的航班
我只是什么都不会而已
算法
题目描述有n个城市通过一些航班连接。给你一个数组flights,其中flights[i]=[fromi,toi,pricei],表示该航班都从城市fromi开始,以价格pricei抵达toi。现在给定所有的城市和航班,以及出发城市src和目的地dst,你的任务是找到出一条最多经过k站中转的路线,使得从src到dst的价格最便宜,并返回该价格。如果不存在这样的路线,则输出-1。代码模板(BFS+最短
- Linux内核学习之 -- epoll()一族系统调用分析笔记
lagransun
linux学习笔记
背景linux4.19epoll()也是一种I/O多路复用的技术,但是完全不同于select()/poll()。更加高效,高效的原因其他博客也都提到了,这篇笔记主要是从源码的角度来分析一下实现过程。作为自己的学习笔记,分析都在代码注释中,后续回顾的时候看注释好一点。相关链接:Linux内核学习之–ARMv8架构的系统调用笔记Linux内核学习之–系统调用open()和write()的实现笔记Lin
- 《Armv8/armv9架构入门指南》-【第十四章】多核处理器
Arm精选
ARM-TEE-Androidarmv8armv9多核处理DSU嵌入式
快速链接:.ARMv8/ARMv9架构入门到精通-[目录]付费专栏-付费课程【购买须知】:联系方式-加入交流群----联系方式-加入交流群个人博客笔记导读目录(全部)
- C语言复习笔记(一维数组)
会飞的CR7
C语言数组一维数组初始化数组元素
数组是一组有序数据的集合,在程序设计中,为方便处理往往会把一些同类型的数据按有序的形式组织起来,且用一个统一的名字标识这组数据,这个名字就称为数组名,构成数组的每一数据称为数组元素或者下标变量。在C语言中,数组属于构造数据类型。一个数组可以包含多个数组元素,这些数组元素可以是基本数据类型或构造类型,按照数组的维数可以分为一维数组和多维数组,按照数组元素的类型,数组又可以分为数值型数组、字符型数组、
- C语言复习笔记6---while循环for循环
.又是新的一天.
C语言复习笔记c语言算法c++
感谢张学长为大家整理的笔记~考点整合A+B问题分离一个整数每一位从后往前从前往后→字符数组(字符串)/看成一堆字符栈(先入后出)→递归while→循环版的if(while循环的直接应用→模拟)gcd和lcm打擂法求max,min判断素数O(n)O(sqrt(n))→分离因子的快捷的求法打印素数表数列求和、斐波那契数列(递推)递推和递归递推往往用迭代(循环)来实现讲从前往后分离整数的递归写法实现方式
- C语言复习笔记5---数组
.又是新的一天.
C语言复习笔记c语言算法c++
数组考点排序冒泡排序O(n^2)选择排序O(n^2)(插入排序)分离每一位正序逆序哈希(hash)→用值直接作为下标日期处理问题数组的基本操作插入和删除逆序(移位)7-19田忌赛马(双指针)二维数组→矩阵矩阵转置判断对称矩阵矩阵运算矩阵移位杨辉三角*知识点数组:存储若干个相同的数据类型的元素intchardoublefloatlonglong定义数组数据类型数组名[数组大小]inta[100];数
- 《沉思录》
froxy
读书笔记程序人生
《沉思录》是古罗马皇帝马可·奥勒留(MarcusAurelius)在戎马倥偬中写下的哲学笔记,也是斯多葛学派的重要代表作。全书以自我对话的形式,探讨了生命、死亡、责任、自然法则以及心灵的安宁。以下是总结与启示:《沉思录》的核心思想总结顺应自然与理性斯多葛哲学认为,宇宙是一个有序的整体,人应遵循自然法则(逻各斯),接受命运的安排。理性是人与神的共通点,通过理性控制欲望和情绪,才能获得内心的自由。专注
- gcc version 11.4.0 (Ubuntu 11.4.0-1ubuntu1~22.04) 上编译问题笔记
老爸我爱你
开发语言c++
编译错误如下:Infileincludedfrom/usr/include/glib-2.0/glib/glib-typeof.h:39,from/usr/include/glib-2.0/glib/gatomic.h:28,from/usr/include/glib-2.0/glib/gthread.h:32,from/usr/include/glib-2.0/glib/gasyncqueue.
- 【自学笔记】Web3基础知识点总览-持续更新
Long_poem
笔记web3
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档文章目录Web3基础知识点总览(Markdown格式)1.引言2.区块链基础3.智能合约4.去中心化应用(DApps)5.数字货币与钱包6.跨链技术7.Web3生态与工具代码块示例(Solidity智能合约)总结Web3基础知识点总览(Markdown格式)1.引言Web3,也称为第三代互联网或去中心化互联网,旨在通过区块链技术实现更
- MyBatis-plus 2.x -> 3.x 版本升级笔记
三只松鼠@
工作日常springjavasql
参考链接:https://github.com/baomidou/mybatis-plus/issues/32621.官方更新日志升级JDK8+优化性能Wrapper支持lambda语法模块化MP合理的分配各个包结构移除com.baomidou.mybatisplus.extension.injector.methods.additional包下的过时类fix:初始化TableInfo中遇到多个字
- Vue3-笔记002-Ref与Reactive
·焱·
vue3学习笔记笔记vue.jsjavascript
002-Ref与Reactive-目录Refref案例ref与RefifRefshallowReftriggerRefcustomRefdom元素的refReactive与ref的共同点与ref的不同点数组的异步赋值问题readonlyshallowReactivetoReftoRefstoRawRef接受一个内部值并返回一个响应式且可变的ref对象。ref对象仅有一个.valueproperty
- Python笔记——DeprecationWarning
小橘猫cate
Pythonpython开发语言
定义如下阶跃函数时出现警告,defstep_function(x):returnnp.array(x>0,dtype=np.int)DeprecationWarning:`np.int`isadeprecatedaliasforthebuiltin`int`.Tosilencethiswarning,use`int`byitself.Doingthiswillnotmodifyanybehavio
- Linux内核srio驱动,Zynq—Linux移植学习笔记(十四):RapidIO驱动开发
weixin_39942572
Linux内核srio驱动
#defineDRIVER_NAME"xiic-rio"#defineSRIO_ZYNQ_BASEADDR0x40000000#defineSRIO_ZYNQ_NODE_BASEADDR0x10100#defineSRIO_ZYNQ_MAX_HOPCOUNT13structxiic_rio{structmutexlock;u8*data;};/*Weneedglobalvarriableforma
- lingo使用笔记(仅入门)
发篇博客骗自己
笔记
lingo使用教程㈠,大致描述(平白无趣的科普)Lingo是一款用于线性规划、整数规划和非线性规划的优化软件。以下是一些常见的Lingo语法和写法的笔记,帮助你快速上手。1.基本结构Lingo模型通常由以下几个部分组成:集合定义:定义模型中使用的集合。数据输入:定义模型中的参数和数据。变量定义:定义决策变量。目标函数:定义优化目标。约束条件:定义模型的约束条件。求解命令:告诉Lingo进行求解。2
- Kubernetes学习笔记-移除Nacos迁移至K8s
人生偌只如初见
KubernetesJ2EEkubernetesk8sjava
项目服务的配置管理和服务注册发现由原先的Nacos全面迁移到Kubernetes上。一、移除Nacos移除Nacos组件依赖。com.alibaba.cloudspring-cloud-starter-alibaba-nacos-discoverycom.alibaba.cloudspring-cloud-starter-alibaba-nacos-configorg.springframewor
- Java基础笔记(小白友好版)
代码什么的真不会呀
java笔记开发语言
Java基础笔记(小白友好版)1.Java简介Java是一种广泛使用的计算机编程语言,由詹姆斯·高斯林(JamesGosling)在1995年创建Java的口号是"一次编写,到处运行"(WriteOnce,RunAnywhere)Java程序需要先编译成字节码(.class文件),然后在Java虚拟机(JVM)上运行主要特点:面向对象:一切皆对象,代码更清晰易懂平台无关性:可以在Windows、M
- 从零至巅:逆向爬虫之道 0_0
蓝花楹下
逆向爬虫爬虫
逆向爬虫-涅槃吾本一介凡鸟,栖于尘世,碌碌无为,浑浑噩噩,如沧海一粟,渺小而无足轻重。然,虽为小雀,心亦怀鸿鹄之志,欲挥羽向天,如凤凰般,翱翔九天,俯瞰苍茫大地。奈何羽翼未丰,学识浅薄,常感力不从心,困于樊笼,不得展翅高飞。然,吾深知,学如逆水行舟,不进则退。故,今执笔为记,以明志,以自勉。愿以此笔记为舟,载吾渡学海,以勤为桨,以思为帆,逐浪前行,终至彼岸。虽前路漫漫,荆棘丛生,然吾心坚定,誓不负
- ruoyi 小程序使用笔记
万变不离其宗_8
笔记小程序笔记
1.上传图片页面jsimportuploadfrom'@/utils/upload.js'methods:{upload(){constconfig={filePath:this.$refs.imageUploadRetire.files[0].path,url:'/api/common/file/upload'}upload(config).then(res=>{this.form.retire
- windows下源码安装golang
616050468
golang安装golang环境windows
系统: 64位win7, 开发环境:sublime text 2, go版本: 1.4.1
1. 安装前准备(gcc, gdb, git)
golang在64位系
- redis批量删除带空格的key
bylijinnan
redis
redis批量删除的通常做法:
redis-cli keys "blacklist*" | xargs redis-cli del
上面的命令在key的前后没有空格时是可以的,但有空格就不行了:
$redis-cli keys "blacklist*"
1) "blacklist:12:
[email protected]
- oracle正则表达式的用法
0624chenhong
oracle正则表达式
方括号表达示
方括号表达式
描述
[[:alnum:]]
字母和数字混合的字符
[[:alpha:]]
字母字符
[[:cntrl:]]
控制字符
[[:digit:]]
数字字符
[[:graph:]]
图像字符
[[:lower:]]
小写字母字符
[[:print:]]
打印字符
[[:punct:]]
标点符号字符
[[:space:]]
- 2048源码(核心算法有,缺少几个anctionbar,以后补上)
不懂事的小屁孩
2048
2048游戏基本上有四部分组成,
1:主activity,包含游戏块的16个方格,上面统计分数的模块
2:底下的gridview,监听上下左右的滑动,进行事件处理,
3:每一个卡片,里面的内容很简单,只有一个text,记录显示的数字
4:Actionbar,是游戏用重新开始,设置等功能(这个在底下可以下载的代码里面还没有实现)
写代码的流程
1:设计游戏的布局,基本是两块,上面是分
- jquery内部链式调用机理
换个号韩国红果果
JavaScriptjquery
只需要在调用该对象合适(比如下列的setStyles)的方法后让该方法返回该对象(通过this 因为一旦一个函数称为一个对象方法的话那么在这个方法内部this(结合下面的setStyles)指向这个对象)
function create(type){
var element=document.createElement(type);
//this=element;
- 你订酒店时的每一次点击 背后都是NoSQL和云计算
蓝儿唯美
NoSQL
全球最大的在线旅游公司Expedia旗下的酒店预订公司,它运营着89个网站,跨越68个国家,三年前开始实验公有云,以求让客户在预订网站上查询假期酒店时得到更快的信息获取体验。
云端本身是用于驱动网站的部分小功能的,如搜索框的自动推荐功能,还能保证处理Hotels.com服务的季节性需求高峰整体储能。
Hotels.com的首席技术官Thierry Bedos上个月在伦敦参加“2015 Clou
- java笔记1
a-john
java
1,面向对象程序设计(Object-oriented Propramming,OOP):java就是一种面向对象程序设计。
2,对象:我们将问题空间中的元素及其在解空间中的表示称为“对象”。简单来说,对象是某个类型的实例。比如狗是一个类型,哈士奇可以是狗的一个实例,也就是对象。
3,面向对象程序设计方式的特性:
3.1 万物皆为对象。
- C语言 sizeof和strlen之间的那些事 C/C++软件开发求职面试题 必备考点(一)
aijuans
C/C++求职面试必备考点
找工作在即,以后决定每天至少写一个知识点,主要是记录,逼迫自己动手、总结加深印象。当然如果能有一言半语让他人收益,后学幸运之至也。如有错误,还希望大家帮忙指出来。感激不尽。
后学保证每个写出来的结果都是自己在电脑上亲自跑过的,咱人笨,以前学的也半吊子。很多时候只能靠运行出来的结果再反过来
- 程序员写代码时就不要管需求了吗?
asia007
程序员不能一味跟需求走
编程也有2年了,刚开始不懂的什么都跟需求走,需求是怎样就用代码实现就行,也不管这个需求是否合理,是否为较好的用户体验。当然刚开始编程都会这样,但是如果有了2年以上的工作经验的程序员只知道一味写代码,而不在写的过程中思考一下这个需求是否合理,那么,我想这个程序员就只能一辈写敲敲代码了。
我的技术不是很好,但是就不代
- Activity的四种启动模式
百合不是茶
android栈模式启动Activity的标准模式启动栈顶模式启动单例模式启动
android界面的操作就是很多个activity之间的切换,启动模式决定启动的activity的生命周期 ;
启动模式xml中配置
<activity android:name=".MainActivity" android:launchMode="standard&quo
- Spring中@Autowired标签与@Resource标签的区别
bijian1013
javaspring@Resource@Autowired@Qualifier
Spring不但支持自己定义的@Autowired注解,还支持由JSR-250规范定义的几个注解,如:@Resource、 @PostConstruct及@PreDestroy。
1. @Autowired @Autowired是Spring 提供的,需导入 Package:org.springframewo
- Changes Between SOAP 1.1 and SOAP 1.2
sunjing
ChangesEnableSOAP 1.1SOAP 1.2
JAX-WS
SOAP Version 1.2 Part 0: Primer (Second Edition)
SOAP Version 1.2 Part 1: Messaging Framework (Second Edition)
SOAP Version 1.2 Part 2: Adjuncts (Second Edition)
Which style of WSDL
- 【Hadoop二】Hadoop常用命令
bit1129
hadoop
以Hadoop运行Hadoop自带的wordcount为例,
hadoop脚本位于/home/hadoop/hadoop-2.5.2/bin/hadoop,需要说明的是,这些命令的使用必须在Hadoop已经运行的情况下才能执行
Hadoop HDFS相关命令
hadoop fs -ls
列出HDFS文件系统的第一级文件和第一级
- java异常处理(初级)
白糖_
javaDAOspring虚拟机Ajax
从学习到现在从事java开发一年多了,个人觉得对java只了解皮毛,很多东西都是用到再去慢慢学习,编程真的是一项艺术,要完成一段好的代码,需要懂得很多。
最近项目经理让我负责一个组件开发,框架都由自己搭建,最让我头疼的是异常处理,我看了一些网上的源码,发现他们对异常的处理不是很重视,研究了很久都没有找到很好的解决方案。后来有幸看到一个200W美元的项目部分源码,通过他们对异常处理的解决方案,我终
- 记录整理-工作问题
braveCS
工作
1)那位同学还是CSV文件默认Excel打开看不到全部结果。以为是没写进去。同学甲说文件应该不分大小。后来log一下原来是有写进去。只是Excel有行数限制。那位同学进步好快啊。
2)今天同学说写文件的时候提示jvm的内存溢出。我马上反应说那就改一下jvm的内存大小。同学说改用分批处理了。果然想问题还是有局限性。改jvm内存大小只能暂时地解决问题,以后要是写更大的文件还是得改内存。想问题要长远啊
- org.apache.tools.zip实现文件的压缩和解压,支持中文
bylijinnan
apache
刚开始用java.util.Zip,发现不支持中文(网上有修改的方法,但比较麻烦)
后改用org.apache.tools.zip
org.apache.tools.zip的使用网上有更简单的例子
下面的程序根据实际需求,实现了压缩指定目录下指定文件的方法
import java.io.BufferedReader;
import java.io.BufferedWrit
- 读书笔记-4
chengxuyuancsdn
读书笔记
1、JSTL 核心标签库标签
2、避免SQL注入
3、字符串逆转方法
4、字符串比较compareTo
5、字符串替换replace
6、分拆字符串
1、JSTL 核心标签库标签共有13个,
学习资料:http://www.cnblogs.com/lihuiyy/archive/2012/02/24/2366806.html
功能上分为4类:
(1)表达式控制标签:out
- [物理与电子]半导体教材的一个小问题
comsci
问题
各种模拟电子和数字电子教材中都有这个词汇-空穴
书中对这个词汇的解释是; 当电子脱离共价键的束缚成为自由电子之后,共价键中就留下一个空位,这个空位叫做空穴
我现在回过头翻大学时候的教材,觉得这个
- Flashback Database --闪回数据库
daizj
oracle闪回数据库
Flashback 技术是以Undo segment中的内容为基础的, 因此受限于UNDO_RETENTON参数。要使用flashback 的特性,必须启用自动撤销管理表空间。
在Oracle 10g中, Flash back家族分为以下成员: Flashback Database, Flashback Drop,Flashback Query(分Flashback Query,Flashbac
- 简单排序:插入排序
dieslrae
插入排序
public void insertSort(int[] array){
int temp;
for(int i=1;i<array.length;i++){
temp = array[i];
for(int k=i-1;k>=0;k--)
- C语言学习六指针小示例、一维数组名含义,定义一个函数输出数组的内容
dcj3sjt126com
c
# include <stdio.h>
int main(void)
{
int * p; //等价于 int *p 也等价于 int* p;
int i = 5;
char ch = 'A';
//p = 5; //error
//p = &ch; //error
//p = ch; //error
p = &i; //
- centos下php redis扩展的安装配置3种方法
dcj3sjt126com
redis
方法一
1.下载php redis扩展包 代码如下 复制代码
#wget http://redis.googlecode.com/files/redis-2.4.4.tar.gz
2 tar -zxvf 解压压缩包,cd /扩展包 (进入扩展包然后 运行phpize 一下是我环境中phpize的目录,/usr/local/php/bin/phpize (一定要
- 线程池(Executors)
shuizhaosi888
线程池
在java类库中,任务执行的主要抽象不是Thread,而是Executor,将任务的提交过程和执行过程解耦
public interface Executor {
void execute(Runnable command);
}
public class RunMain implements Executor{
@Override
pub
- openstack 快速安装笔记
haoningabc
openstack
前提是要配置好yum源
版本icehouse,操作系统redhat6.5
最简化安装,不要cinder和swift
三个节点
172 control节点keystone glance horizon
173 compute节点nova
173 network节点neutron
control
/etc/sysctl.conf
net.ipv4.ip_forward =
- 从c面向对象的实现理解c++的对象(二)
jimmee
C++面向对象虚函数
1. 类就可以看作一个struct,类的方法,可以理解为通过函数指针的方式实现的,类对象分配内存时,只分配成员变量的,函数指针并不需要分配额外的内存保存地址。
2. c++中类的构造函数,就是进行内存分配(malloc),调用构造函数
3. c++中类的析构函数,就时回收内存(free)
4. c++是基于栈和全局数据分配内存的,如果是一个方法内创建的对象,就直接在栈上分配内存了。
专门在
- 如何让那个一个div可以拖动
lingfeng520240
html
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml
- 第10章 高级事件(中)
onestopweb
事件
index.html
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/
- 计算两个经纬度之间的距离
roadrunners
计算纬度LBS经度距离
要解决这个问题的时候,到网上查了很多方案,最后计算出来的都与百度计算出来的有出入。下面这个公式计算出来的距离和百度计算出来的距离是一致的。
/**
*
* @param longitudeA
* 经度A点
* @param latitudeA
* 纬度A点
* @param longitudeB
*
- 最具争议的10个Java话题
tomcat_oracle
java
1、Java8已经到来。什么!? Java8 支持lambda。哇哦,RIP Scala! 随着Java8 的发布,出现很多关于新发布的Java8是否有潜力干掉Scala的争论,最终的结论是远远没有那么简单。Java8可能已经在Scala的lambda的包围中突围,但Java并非是函数式编程王位的真正觊觎者。
2、Java 9 即将到来
Oracle早在8月份就发布
- zoj 3826 Hierarchical Notation(模拟)
阿尔萨斯
rar
题目链接:zoj 3826 Hierarchical Notation
题目大意:给定一些结构体,结构体有value值和key值,Q次询问,输出每个key值对应的value值。
解题思路:思路很简单,写个类词法的递归函数,每次将key值映射成一个hash值,用map映射每个key的value起始终止位置,预处理完了查询就很简单了。 这题是最后10分钟出的,因为没有考虑value为{}的情