机器学习系列(一)——理论基础
机器学习是一个计算机程序,针对某个特定的任务,从经验(即数据,谁的数据规模大、质量好,谁就占据了机器学习个人工智能领域最有利的资本。)中学习,并且越做越好。
机器学习工具
库:numpy、pandas、scikit-learn、matplotlib
开发环境:Anaconda、Pycharm
scikit-learn包含了几乎所有主流的机器学习算法,提供了一致的调用接口。详情可以参考官网文档:http://scikit-learn.org
机器学习流程
-
数据采集和标注
-
数据预处理
缺失值、异常值和重复值的处理,将不适合进入机器学习模型的数据处理掉。缺失值、异常值和重复值的处理,将不适合进入机器学习模型的数据处理掉。 -
特征选择
基于业务背景人工选择特征、基于模型自动选择特征。 -
模型选择
scikit-learn官网提供了一个模型速查表,针对几个简单问题就可以选择一个相对合适的模型。

-
模型训练与测试
模型训练需要把数据集分成训练集和测试集,训练集建模,测试集评价模型准确性。
#切分数据
from sklearn.cross_validation import train_test_split
x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size=0.2, random_state=2)
#建立模型,训练
from sklearn import svm
clf = svm.SVC(C=1.0, kernel='rbf', gamma=0.5)
clf.fit(x_train, y_train)
#模型测试
clf.score(x_train, y_train)
clf.score(x_test, y_test)
- 模型评价与优化
从众多的模型中选择一个合适的模型去拟合数据,然后从这个选定模型的众多参数中,选择适合的参数,使得成本函数最小。 - 模型保存与使用
对模型满意后,就可以把模型保存下来,下次使用时可以直接加载模型,不需要重新训练。
#保存模型
from sklearn.externals import joblib
joblib.dump(clf, 'svm.pkl')
#加载模型
clf = joblib.load('svm.pkl')
y_pred = clf.predict(x_test)
## 过拟合、欠拟合
-
过拟合
过拟合(over fitting),也称高方差(high variance),指模型能较好地拟合训练样本,但对于新数据的预测准确性很差。
处理方法:增加样本量、减少输入的特征数量。 -
欠拟合
欠拟合(under fitting),也称高偏差(high bias),指模型不能很好地拟合训练样本,对于新数据的预测准确性也不好。
处理方法:欠拟合说明模型过于简单,可以增加有价值的特征使模型复杂些。
学习曲线
以模型在训练集train和交叉验证数据集validation上的准确率为纵坐标,画出与训练集样本量m的大小关系,这就是学习曲线。学习曲线可以看出,随着样本量的增加,模型对训练集拟合的准确性以及对交叉验证数据集预测的准确性的变化规律。

#学习曲线绘制
from sklearn.svm import LinearSVC
from sklearn.learning_curve import learning_curve
#绘制学习曲线,以确定模型的状况
def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None,
train_sizes=np.linspace(.1, 1.0, 5)):
"""
画出data在某模型上的learning curve.
参数解释
----------
estimator : 你用的分类器。
title : 表格的标题。
X : 输入的feature,numpy类型
y : 输入的target vector
ylim : tuple格式的(ymin, ymax), 设定图像中纵坐标的最低点和最高点
cv : 做cross-validation的时候,数据分成的份数,其中一份作为cv集,其余n-1份作为training(默认为3份)
train_sizes=np.linspace(0.1, 1.0, 5) :表示把样本数量从0.1~1.0分成5等份,然后逐个计算每个等份样本量下模型准确性。
"""
plt.figure()
train_sizes, train_scores, test_scores = learning_curve(
estimator, X, y, cv=5, n_jobs=1, train_sizes=train_sizes)
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
plt.fill_between(train_sizes, train_scores_mean - train_scores_std,
train_scores_mean + train_scores_std, alpha=0.1,
color="r")
plt.fill_between(train_sizes, test_scores_mean - test_scores_std,
test_scores_mean + test_scores_std, alpha=0.1, color="g")
plt.plot(train_sizes, train_scores_mean, 'o-', color="r",
label="Training score")
plt.plot(train_sizes, test_scores_mean, 'o-', color="g",
label="Cross-validation score")
plt.xlabel("Training examples")
plt.ylabel("Score")
plt.legend(loc="best")
plt.grid("on")
if ylim:
plt.ylim(ylim)
plt.title(title)
plt.show()
#少样本的情况情况下绘出学习曲线
plot_learning_curve(LinearSVC(C=10.0), "LinearSVC(C=10.0)",
X, y, ylim=(0.8, 1.01),
train_sizes=np.linspace(.05, 0.2, 5))
## 查准率、召回率
有时候,不能单靠模型的准确性去衡量模型的好坏。在scikit-learn中,可以使用查准率和召回率评估模型性能,即sklearn.metrics.precision_score()和sklearn.metrics.recall_score()。
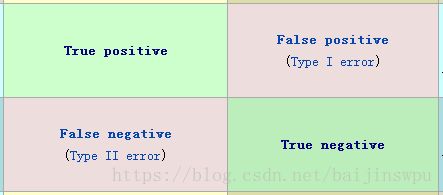
TP: 实际是正样本, 被识别成正样本(识别正确).
FP: 实际是负样本, 被识别成正样本(识别错误).
FN: 实际是正样本, 被识别为负样本(识别正确).
TN: 实际是负样本, 被识别为正样本(识别错误).
查准率和召回率定义如下:
Precision = TP/(TP+FP); 查准率, 在所有被判断为正样本中, 真正正样本的数量.
Recall = TP/(TP+FN); 召回率, 在所有正样本中, 被识别为正样本的数量.
综合指标F1 score定义:
F = 2PR/(P+R)
scikit-learn中,计算F1 score的函数是sklearn.metrics.f1_score()。