Python 小甲鱼教程 课后练习30 番外篇_需要谨记!!!
这题的要求是搜索当前目录内,包含所输入关键字的txt文件,并标注出,是在文件的第几行,和第几个位置
这道题目中,碰到了好几个基础知识缺失的地方,以及后期调试中莫名其妙的报错,经过一个上午的纠结,找到了报错真实位置,并看到一些规律,这里记录下。

代码如下:
import os
def print_pos(key_dict):
keys = key_dict.keys() #这里是将字典里的键值迭代出来,注意,keys()函数返回的是一个dict_keys的类型,类似于list,可以被迭代!!
keys = sorted(keys) #由于字典是无序的,出来的数字我们要排序一下
for each_key in keys:
print ('keyword is in %s line, %s position'%(each_key,str(key_dict[each_key]))) #这里有一个巨型坑,这句话的最后一个括号,我一开始漏了,但是运行时候报 # 错报在下面一个函数的def上面,报语法错误,找错误找了2小时,后来一行一 #行拿小甲鱼的代码替代进去才发现错误,并且发现,如果上面一行的最后是 # print函数,那么,如果最后漏了一个括号,他不会报错报在单行,他会报在下 #一行!!天坑!!!
#我在文末最后写一点东西,记录一下这个错误,太糟心了。
def pos_in_line(line, key):
pos = []
begin = line.find(key) #find函数,在目标中搜索关键str,如果找到,返回索引位置,如果未找到,返回-1
while begin != -1: #这句话的意思是,当找到匹配值时
pos.append(begin + 1) #将这个位置添加到列表里去(然后python的索引是从0开始,但是对用户来说,是从1开始)
begin = line.find(key, begin+1) #这句很关键,在上一个索引返回后,继续从下一个开始搜索匹配
return pos
def search_in_file(file_name,key): #我觉得第二个要写的部分是这里,搜索行数
f=open(file_name)
count=0 #计数器初始化为0
key_dict=dict()
for each_line in f:
count+=1 #后面每搜索一行,计数器count就自己加1
if key in each_line:
pos = pos_in_line(each_line,key) #调用pos_in_line函数,嵌套好多次啊,太复杂了.......
key_dict[count]=pos #这里严重笔记!如果一行内出现多次关键字,那不是字典内一个key要对应好几个value吗?请记住!!!key是可以对应列表 #list的,所以,这里是把一个count,也就是行数,对应一个列表,在列表内部,才是出现的具体位置
f.close()
return key_dict
def search_files(key,detail): #最先写的应该是这部分,因为你首先是定位到,哪些是txt文档,然后再进入内部搜索.
all_files=os.walk(os.getcwd()) #os.walk函数,历遍当前目录和子目录,返回三个对象,1:str形式的当前目录,2:list形式的文件夹目录,3:list形式的文件目录
txt_files=[]
for i in all_files:
for each_file in i[2]: #将当前目录内的所有文件迭代出来
if os.path.splitext(each_file)[1]=='.txt': #分割后缀名和文件,如果后缀为.txt
each_file=os.path.join(i[0],each_file) #更新each_file这个变量,他原来只是文件名,现在通过join函数拼接,成为完成路径名
txt_files.append(each_file)
for each_txt_file in txt_files:
key_dict=search_in_file(each_txt_file,key) #这里调用下一个函数search_in_file
if key_dict: #这里的意思是,如果在key_dict里面有值,那么就打印一行===,并继续打印具体文件路径和关键字
print ('=======================================')
print ('in file %s we found keyword %s'%(each_txt_file,key))
if detail in ['YES','Yes','yes']:
print_pos(key_dict) #这里调用另外一个函数,打印具体位置,我觉得写代码的时候肯定是先在这做一个伏笔,等后续上面的函数写完, #再来替换的
key=input('please enter the keywords:')
detail=input(('do you want to print out the position in file of %s (yes/no)')%key)
search_files(key,detail)
最后的最后,添加一下上面碰到的天坑错误和自己做的试验
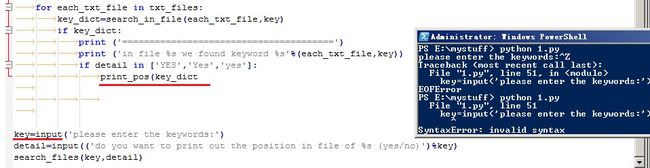
看到下面的报错了吗?我找了2小时,没明白这个def语句这一行有什么错误,包括缩进什么的,都没问题,找到最后,结果发现是上面一行的print语句最后一个括号给漏了
但是他给我报错报在下一行!!!
然后,见图2,我做了个试验,在其他代码里,只要最后一句是print,漏了右边括号的话,他就会自动报错报在下面一行的开头。。。。WTF

牢记错误。。。。。。。。。。