ps:
1、本文示例使用的消息中间件为Rabbitmq。
2、示例代码是以测试用例的形式给出。
3、使用@ActiveProfiles( active_profile(s) )让指定配置生效。
前言
前面两篇文章 Spring Cloud Stream 进阶配置——高吞吐量(一)、Spring Cloud Stream 进阶配置——高吞吐量(二),第一篇是通过增加消费者数量进而提高消费端的吞吐量,但配置的消费者数量是固定,配置的过少,吞吐量提升的有限,而过多会造成系统资源浪费;于是就有了第二篇,通过配置最大消费者数量,让消费端有了动态增加/销毁消费者的能力,另外最大消费者数量同时也是一个阈值,动态增加的消费者数量无法超过该阈值,也就避免创建过多消费者(线程)占用过多系统资源影响到其他程序。
俗话说,凡事都是有两面的。比如,消费者数量多了之后,就会衍生另一个问题——如何更均衡地分发消息给不同消费者?
下面先来介绍一下 Rabbitmq 的分发策略。
轮询分发
轮询分发 Rabbitmq 默认的分发策略。顾名思义,有多个消费者,当消息来了,会一条一条按顺序平均分发给消费者,而且来多少分发多少,并不管你消费能力如何。
可以看到轮询分发策略,思路很简单,容易实现,但是有很多弊端。
第一,消息是平均分发给所有消费者。看到这里,你可能会说,这没毛病啊,平均分发消息,让所有消费者平摊消费消息。表面上看,是这样没错,但是可能会出现这样的场景:假设有3个消费者A, B, C,其中消费者A由于各种原因导致消费力下降,但还是分配了与其他2个消费者一样的待消费消息,于是当其他2个消费者把消息都消费完了,消费者A还堆积了好多消息。
另一个弊端,来多少消息分发多少,这种机制,当生产者大量发布消息而消费者又消费力低下时,消费者会大量堆积消息,造成系统资源(特别是堆内存)被大量占用。
由上可以看出,轮询分发策略虽然简单,但存在很大的隐患,因此 Spring Cloud Stream 默认不支持这种分发策略,而使用另一种——公平分发策略。
公平分发
一般情况下,不同消费者之间,消费能力(消费消息的速度)都是不一样的,有快有慢,为了提高吞吐量,那么就应该消费快的,分担多一点,反之,量力而行。于是 Spring Cloud Stream 提供了一个配置 spring.cloud.stream.rabbit.bindings.,默认值为 1,prefetch 有 预取 的意思,那么该配置可以理解为:消费者每次从队列获取的消息数量。
使用 prefetch 有什么好处呢?消费者每次只从队列获取一定数量的消息,当所有消息消费完了,再接着从队列获取相同数量的消息。
这样一来,消费快的消费者,向队列获取消息的频率就高,反之,频率就低,因此,单位时间内,消费力强的消费者消费的消息就多,而不会出现无论消费力强弱,却需要消费相同数量的消息。由木桶效应我们可以知道,若是使用轮询分发策略,消费一定数量的消息,全部消费完所花费的时间肯定取决于消费力最弱的消费者所花的时间。但是,公平分发策略不会出现这种情况,最坏的情况也只有 prefetch 对应数量的消息被阻塞在消费力异常的消费者上,而其他消息会被其他消费者消费。
另外,配置了 prefetch ,也不会出现像轮询分发策略那样,消费者消费力低下时,消费者会大量堆积消息的隐患。
看到这里,应该就可以明白,Spring Cloud Stream 为什么不支持轮询分发策略了吧。
批量获取消息
上面提到,prefetch 的默认值是 1,也就是说消费者一次只会向队列取回一条消息进行消费。每一次获取消息会消耗一定的时间,而一个来回又只取回一条消息,这妥妥让人感觉有很大的提升空间啊。试下一下,如果你在搬砖,从楼下把砖搬到楼上,一次只搬一块,这是不是让人感觉闲得蛋疼。
所以,如果配置 prefetch 的值为10,这就凭空减少9个来回,不说消耗的时间会减少为原来总时间的1/10,但消耗的时间变少是可以预见的。接下来我们通过代码验证一下。
示例
以下代码可在 源码 查看。
配置
spring:
application:
name: scas-data-collection
profiles:
active:
default
cloud:
stream:
binders:
rabbit:
type: rabbit
environment:
spring:
rabbitmq:
host: localhost
port: 5672
username: guest
password: guest
bindings:
packetUplinkOutput:
destination: packetUplinkTopic
content-type: application/json
binder: rabbit
packetUplinkInput:
destination: packetUplinkTopic
content-type: application/json
group: ${spring.application.name}
binder: rabbit
consumer:
concurrency: 1 # 初始/最少/空闲时 消费者数量。默认1
rabbit:
bindings:
packetUplinkInput:
consumer:
prefetch: 1 # 限制consumer在消费消息时,一次能同时获取的消息数量,默认:1。
消息模型
@Data
@NoArgsConstructor
@AllArgsConstructor
public class PacketModel {
/**
* 设备 eui
*/
private String devEui;
/**
* 数据
*/
private String data;
// 省略其他字段
}
测试用例
@Slf4j
@RunWith(SpringRunner.class)
@SpringBootTest
@EnableBinding({ScasPrefetchTest.MessageSink.class, ScasPrefetchTest.MessageSource.class})
@ActiveProfiles("prefetch")
public class ScasPrefetchTest {
@Autowired
private PacketUplinkProducer packetUplinkProducer;
private Random random = new Random();
private List devEuis = new ArrayList<>(10);
@PostConstruct
private void initDevEuis() {
devEuis.add("10001");
devEuis.add("10002");
devEuis.add("10003");
devEuis.add("10004");
devEuis.add("10005");
devEuis.add("10006");
devEuis.add("10007");
devEuis.add("10008");
devEuis.add("10009");
devEuis.add("10010");
}
@Test
public void test() throws InterruptedException {
for (int i = 0; i < 500000; i++) {
String devEui = getDevEuis();
packetUplinkProducer.publish(new PacketModel(devEui, UUID.randomUUID().toString()));
}
Thread.sleep(1000000);
}
private String getDevEuis() {
return devEuis.get(random.nextInt(10));
}
@Component
public static class PacketUplinkProducer {
@Autowired
private MessageSource messageSource;
public void publish(PacketModel model) {
log.info("发布上行数据包消息. model: [{}].", model);
messageSource.packetUplinkOutput().send(MessageBuilder.withPayload(model).build());
}
}
@Component
public static class PacketUplinkHandler {
@StreamListener("packetUplinkInput")
public void handle(PacketModel model) throws InterruptedException {
log.info("消费上行数据包消息. model: [{}].", model);
}
}
public interface MessageSink {
@Input("packetUplinkInput")
SubscribableChannel packetUplinkInput();
}
public interface MessageSource {
@Output("packetUplinkOutput")
MessageChannel packetUplinkOutput();
}
}
运行测试用例
1. prefetch = 1
可以看到,上面的配置均使用 Spring Cloud Stream 的默认配置,运行测试用例后,访问 Rabbitmq可视化页面 可以看到类似下图的页面:
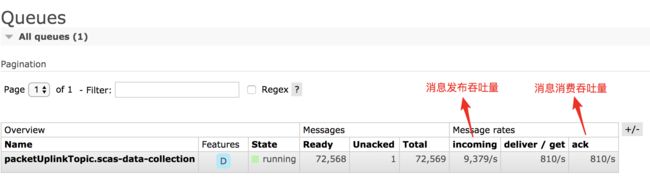
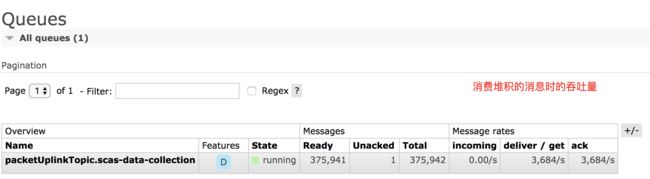
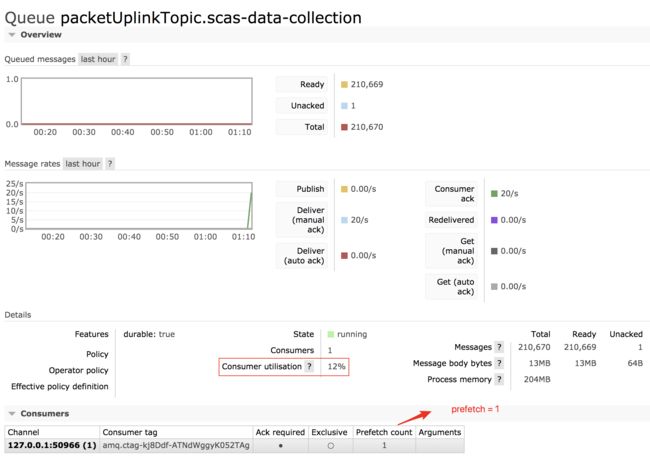
若点击队列列表中的 packetUplinkTopic.scas-data-collection 可以看到如下该队列的更详细的信息:
2. prefetch = 3
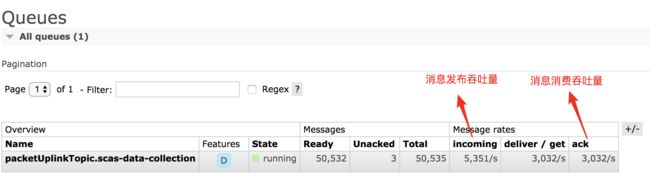
将 prefetch 配置为3,再次启动测试用例,可以看到结果测试如下:

查看队列 packetUplinkTopic.scas-data-collection的详细信息,可以可以看到:
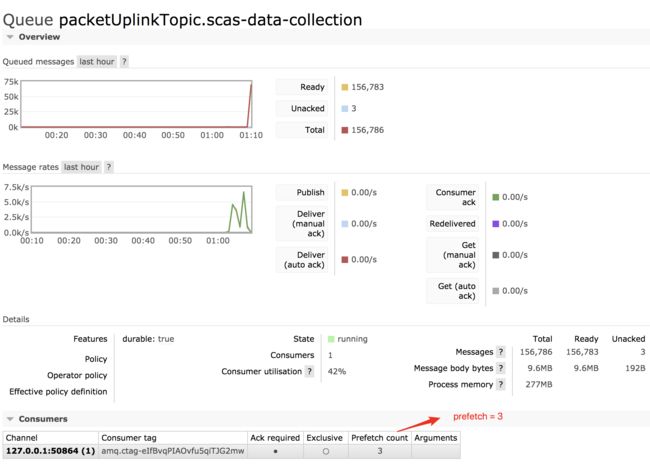
可以看到,当 prefetch = 3 的时候,不管是哪种情况,吞吐量都有相应的提升。再看看当 prefetch = 5 的情况。
3. prefetch = 5
将 prefetch 配置为5,再次启动测试用例,可以看到结果测试如下:
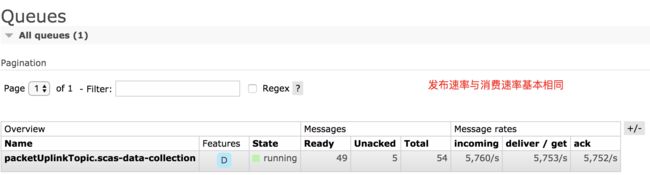
查看队列 packetUplinkTopic.scas-data-collection的详细信息,可以可以看到:
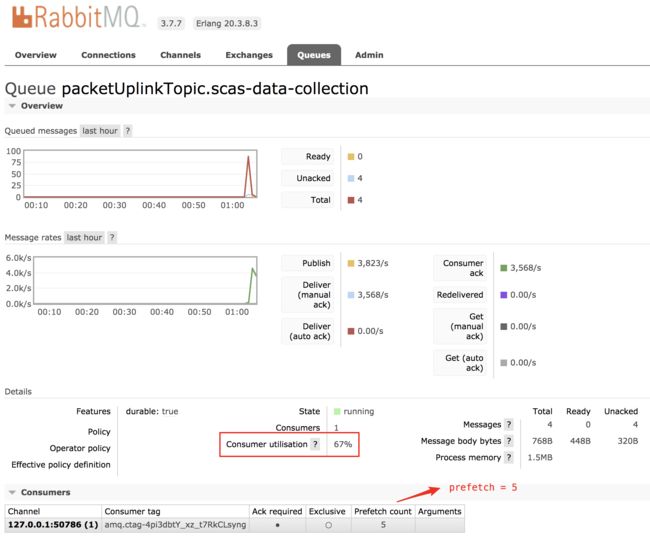
可以看到,发布速率与消费速率基本相同,在这种情况下,吞吐量是最大的。
Consumer utilisation
有没有发现,上面每一种情景下的最后一张图片都圈出一个指标:Consumer utilisation,翻译过来为:消费者的利用率。点击后面的问号,会弹出下面一个提示:

大意就是,当该指标小于100的时候,可以通过以下方式使消息投递得更快,也就是消费得更快,吞吐量更高,具体的方法有:
- 增加消费者数量
- 提高消费者消费单个消息的速度
- 让消费者有更大的
prefetch值
现在回去再观察那3张图,可以看见随着 prefetch 值的增大,该指标也得到相应的提高。
但是,到了 prefetch = 5 的时候,发布速率与消费速率已经基本相同了,再这种情况下,再增加 prefetch 值,提升的吞吐量就极为有限了。再结合第一条方法(因为第二条在这里无法再优化了),我们可以尝试增加消费者数量,看能不能让该指标变得更接近100。
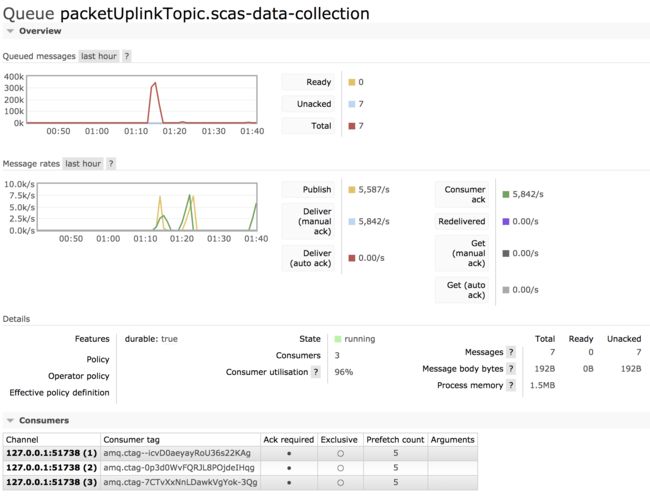
consumer = 3 & prefetch = 3
配置 consumer = 3 & prefetch = 3,可以看到,想比consumer = 1 & prefetch = 3,指标 Consumer utilisation 得到大幅度提高。
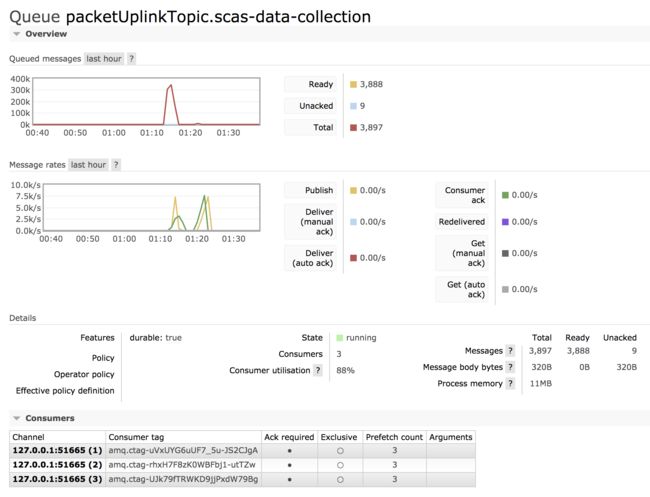
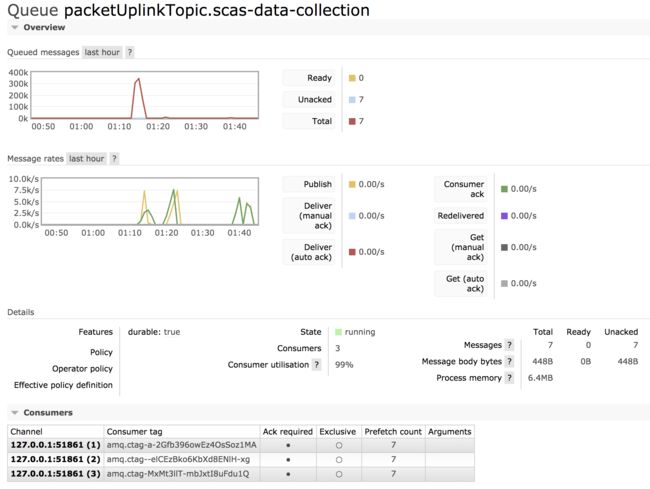
consumer = 3 & prefetch = 5
再配置 consumer = 3 & prefetch = 5,可以看到,指标 Consumer utilisation 的值已经很接近100了。
更大的prefetch
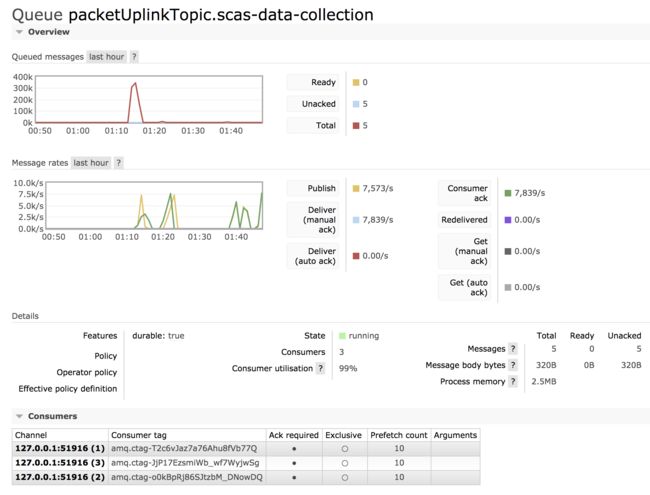
可以看到,当 prefetch = 5 时,指标 Consumer utilisation 很接近100了,如果再继续增大 prefetch 的值,指标 Consumer utilisation 并没有很大的提升。
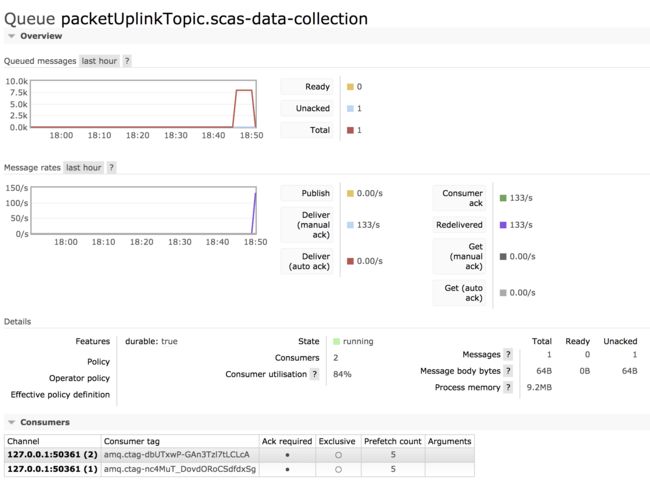
consumer = 1 & prefetch = 5 & maxConcurrency = 5
最后再结合配置 maxConcurrency,可以看到指标 Consumer utilisation 随着消费者数量动态增加也在逐渐增大,最后达到 100%:
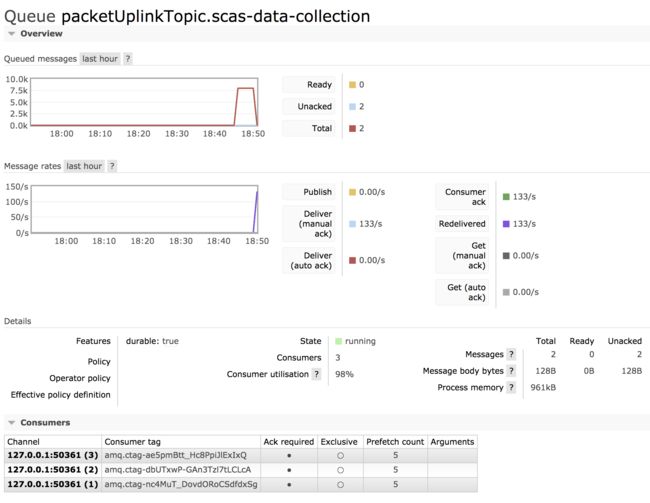

小结
所以,经过上面的一系列测试后,prefetch 的值也并不是越大就越好,而prefetch = 5、maxConcurrency = 5 应该就是相对合适的配置。
结论
prefetch 可以用于配置消费者每次从队列预取的消息数量,当配置大于1的数值后,可以减少从队列获取的消息的次数,从而减少获取相同数量消息的总耗时,这样也就达到提高消费端吞吐量的目的。
另外,本文还提到一个指标——消费者利用率(Consumer utilisation),可以用于衡量消费端的消费能力,最大值为100,数值越大,消费能力越强,相应的吞吐量也就越高。同时还介绍了当该指标低于100时,提升该指标的几种途径:1、增加消费者数量、2、提升消费消息的速度、3、增大消费者的 prefetch 值。其中第2点具有业务相关性,这里就不细说,而其他2点则可以通过配置轻松实现,分别对应配置 concurrency 和 prefetch,而再配合 maxConcurrency,则可以动态控制消费者数量,减少不必要的资源占用。
所以 concurrency、maxConcurrency 和 prefetch 配合一起使用的话,可以大幅提高消费端的吞吐量,起到意想不到的效果。当然,是建立在合理配置这几个参数的情况下。
推荐阅读
Spring Cloud Stream 进阶配置——高吞吐量(一)——多消费者
Spring Cloud Stream 进阶配置——高吞吐量(二)——弹性消费者数量
相关链接
https://blog.csdn.net/yhl_jxy/article/details/85322696
https://www.kancloud.cn/longxuan/rabbitmq-arron/117513
http://yuanwhy.com/2016/09/10/rabbitmq-concurrency-prefetch/
完!!!