Python文本挖掘练习(一)// 新闻摘要
一、练习目标
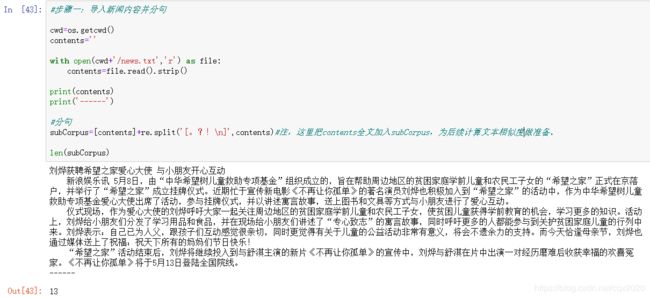
1、掌握读取文档内容、文章分句、文本分词的方法
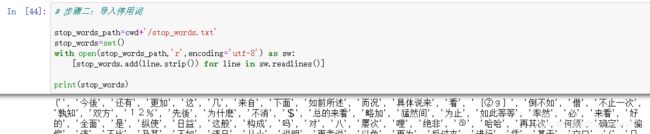
2、掌握文本向量化,剔除停用词
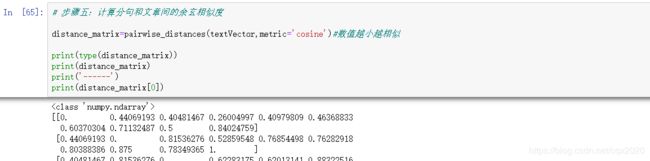
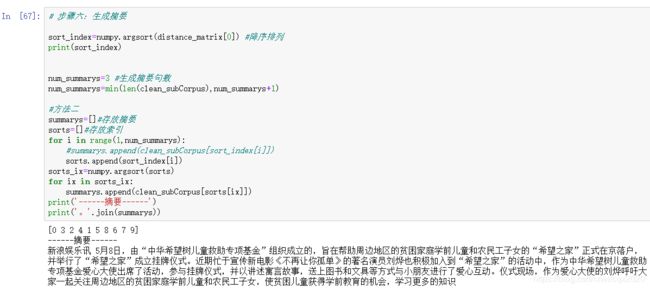
3、掌握用cosine方法计算文档相似度,并基于此提取文档摘要
4、将过程封装成函数,方便调用
二、步骤与代码



三、封装函数
def summary(path,num_summary=2):
'''
函数功能:实现文本摘要
参数说明:
path:文档路径
num_summary:摘要长短
返回:
result:摘要
'''
import re #文档内容分句
import os #获取文件路径
import jieba #分词
import numpy
from sklearn.metrics import pairwise_distances #计算文本相似度
from sklearn.feature_extraction.text import CountVectorizer #转化为文本向量
#导入文本
cwd=os.getcwd()
contents=''
with open(cwd+path,'r') as file:
contents=file.read().strip()
#分句
subCorpus=[contents]+re.split('[。?!\n]',contents)
#导入停用词
stop_words_path=cwd+'/stop_words.txt'
stop_words=set()
with open(stop_words_path,'r',encoding='utf-8') as sw:
[stop_words.add(line.strip()) for line in sw.readlines()]
#分词
segments=[]
clean_subCorpus=[]
for content in subCorpus:
segs=jieba.cut(content) #断词,list格式
segment=' '.join(segs) #转化为一个元素
if len(segment.strip())>=5: #剔除长度小于5的句子
segments.append(segment.strip())
clean_subCorpus.append(content.strip())
#文本向量
countVectorizer=CountVectorizer(stop_words=stop_words)#设置关键参数stop_words
textVector=countVectorizer.fit_transform(segments) #shape=(10, 89)
#文本相似度
distance_matrix=pairwise_distances(textVector,metric='cosine')#数值越小越相似
#生成摘要
sort_index=numpy.argsort(distance_matrix[0]) #降序排列
num_summary=min(len(clean_subCorpus),num_summary+1)
summarys=[]#存放摘要
sorts=[]#存放索引
for i in range(1,num_summary):
sorts.append(sort_index[i])
sorts_ix=numpy.argsort(sorts)
for ix in sorts_ix:
summarys.append(clean_subCorpus[sorts[ix]])
result='。'.join(summarys)
return result
附调用函数
