机器学习公式推导
本篇笔记主要记录及推导Andrew NG的Machine Learning课程中出现的公式。
我们假设对于任意的分类、聚类、回归等问题在自然界中总是存在一个精确的模型与之相对应,接下来我们要做的就是根据获取的样本来反推并确定这个模型。由于我们毕竟无法遍历这个问题所有的情况,所以我们只能根据获取的样本去尽可能接近的确定这个模型。
公式化上面这段描述,问题对应的模型就藏在假设空间(Hypothesis) hθ(x) h θ ( x ) 中,我们需要通过观测样本,确定其中的 θ θ 值。在确定 θ θ 值的过程中,定义一个损失函数(Cost Function) J(θ) J ( θ ) ,如果我们获取的样本在某一个参数 θ θ 时使损失值达到最小,即表示当前 θ θ 值确定的模型可以使预测值很接近观察值。那么这个模型就是我们需要寻找的。
对于监督学习,我们要做的就是确定目标函数,损失函数,然后通过样本训练,得到损失值最小的那一组参数值,用该参数值代入目标函数,即可得到对应问题的模型。
一、线性回归模型
1、单一变量的线性回归模型
目标函数:
损失函数:
公式说明:
hθ(x(i)):第i个样本 h θ ( x ( i ) ) : 第 i 个 样 本
y(i):第i个样本对应的实际值 y ( i ) : 第 i 个 样 本 对 应 的 实 际 值
接下来的目标就是找到一组参数值,使得损失函数值最小,即
求损失函数最小值时,使用梯度下降(Gradient descent)的方法。在微积分中我们学过梯度,梯度方向是函数值下降最快的方向,所以在梯度下降方法中,我们分别求 θ0和θ1 θ 0 和 θ 1 的偏导数,然后用该导数值更新参数值。
说明,上面公式中的 := := 表示赋值的意思,如果直接写a = 1可能会被误理解为判断a是否等于1。
求损失函数 J(θ0,θ1) J ( θ 0 , θ 1 ) 对 θ0 θ 0 和 θ1 θ 1 的偏导数,
使用偏导数公式对上式展开。
2、多变量线性回归模型
上一节的模型中只有一个指标 x x ,理解了线性回归模型及其寻找最优化参数的过程。接下来将该思路应用到多变量模型中。
(1)目标函数
上式中的 x1,x2,⋯,xn x 1 , x 2 , ⋯ , x n 都是给定样本中的指标,其中 x0=1 x 0 = 1 是人为增加的。
如果将目标函数使用向量表示,
(2)损失函数
(3)梯度下降
分别对 θ0,θ1,θ2 θ 0 , θ 1 , θ 2 求偏导数并进行展开,如下所示
(4)公式法
如果我们将目标函数向量化, TXTθ=y T X T θ = y ,需要求解其中的 θ θ ,
这里需要说明一下, θ,y,X θ , y , X 分别代表的含义。在本文中,向量都是小写字母表示,并且都是列向量,即 n∗1 n ∗ 1 维。矩阵的维度 m∗n m ∗ n 表示有 m m 行 n n 列。那么上式中,我们假设 m=4 m = 4 , n=5 n = 5 其中包括 x0 x 0 ,给出一组示例数据
对应的 X X 为,每个 x(i) x ( i ) 表示一行数据的话:
对应的 y y 为:
对应的 θ θ 为:
二、逻辑回归模型
1、逻辑回归模型
上面的线性回归模型输出结果为连续值,如果我们面对的是一个分类模型,比如判断是否为垃圾邮件,或者其他的分类问题时,就不能直接使用线性回归模型了。
逻辑回归模型是在线性回归模型上的一个演变,它通过一个逻辑函数可以将线性回归模型的输出结果转变为0或1的离散输出。
(1)逻辑函数
即Logistic Function,也称为Sigmoid Function,如下所示,
对应的函数图形为:
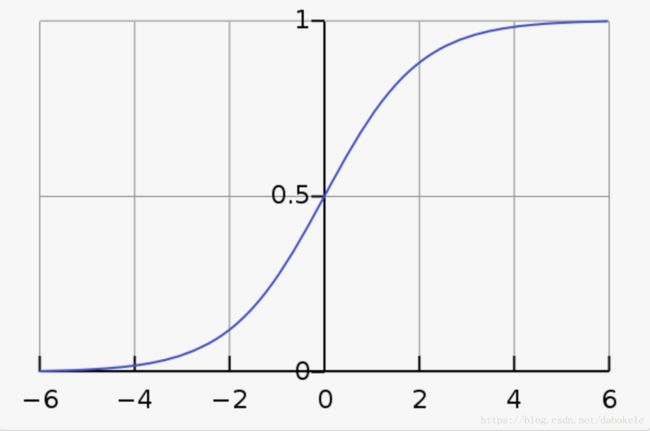
从图中可以看到,横轴是连续取值,但是纵轴上的取值范围被限制在0和1之间,Sigmoid函数可以将连续值转变为0或1的离散值。
如果将上面的逻辑函数 g(z) g ( z ) 应用在线性回归模型的输出函数 hθ(x) h θ ( x ) 上,就可以得到本节所讲的逻辑回归模型。
(2)目标函数
当 y=1 y = 1 时, hθ(x) h θ ( x ) 的值,可以理解为是对当前样本 x x ,在参数 θ θ 的情况下被预测为1的概率。即
(3)损失函数
在前面的线性回归模型中,损失函数如下
上式第二行中将 12 1 2 向后移动到求和项中,如果将求和项中整体定义为
那么线性回归的损失函数可以写成
线性回归使用的是平方损失,如果我们直接将平方损失函数应用到逻辑回归模型中,最终得到的 J(θ) J ( θ ) 可能如下图所示,

逻辑回归模型中使用的是对数损失,定义如下
可以画出对数损失函数图形来看,当 y=1 y = 1 并且 hθ(x)=1 h θ ( x ) = 1 时, Cost=0 C o s t = 0 ,当 y=1 y = 1 并且 hθ(x)→0 h θ ( x ) → 0 时, Cost→∞ C o s t → ∞ 。 y=0 y = 0 时情况类似。
最后,将逻辑回归的对数损失函数进行融合,
将 Cost(hθ(x),y) C o s t ( h θ ( x ) , y ) 代入 J(Θ) J ( Θ ) 可以得到逻辑回归完整的损失函数如下
逻辑回归中使用对数损失函数来求解参数,与采用极大似然估计求参数是一致的。
以下为对数损失函数和极大似然估计的分析过程:
假设样本服从伯努利分布(0-1分布),则有
P(hθ(x)=y)={1−ppn=0n=1 P ( h θ ( x ) = y ) = { 1 − p n = 0 p n = 1
似然函数如下:L(θ)=∏i=1mP(y=1|xi,θ)yiP(y=0|xi,θ)1−yi L ( θ ) = ∏ i = 1 m P ( y = 1 | x i , θ ) y i P ( y = 0 | x i , θ ) 1 − y i
对数似然函数为:lnL(θ)=∑i=1m[yiln(P(y=1|xi,θ)+(1−yi)lnP(y=0|xi,θ)]=∑i=1m[yiln(P(y=1|xi,θ)+(1−yi)ln(1−P(y=0|xi,θ))] l n L ( θ ) = ∑ i = 1 m [ y i l n ( P ( y = 1 | x i , θ ) + ( 1 − y i ) l n P ( y = 0 | x i , θ ) ] = ∑ i = 1 m [ y i l n ( P ( y = 1 | x i , θ ) + ( 1 − y i ) l n ( 1 − P ( y = 0 | x i , θ ) ) ]
根据对数损失函数的定义Cost(y,p(y|x)=−ylnp(y|x)−(1−y)ln(1−p(y|x)) C o s t ( y , p ( y | x ) = − y l n p ( y | x ) − ( 1 − y ) l n ( 1 − p ( y | x ) )
那么对于全体样本,损失函数如下:Cost(y,p(y|x)=−∑i=1m[yilnp(yi|xi)−(1−yi)ln(1−p(yi|xi))] C o s t ( y , p ( y | x ) = − ∑ i = 1 m [ y i l n p ( y i | x i ) − ( 1 − y i ) l n ( 1 − p ( y i | x i ) ) ]
可以看到,对数损失函数与上面的极大似然函数本质上是等价的。所以,逻辑回归直接采用对数损失函数,与采用极大似然估计是一致的。
(4)梯度下降
接下来使用梯度下降方法求解逻辑回归的最佳参数,求解损失函数
的最优解过程如下,
以下为求 ∂∂θjJ(θ) ∂ ∂ θ j J ( θ ) 的过程,
以下为了简便,将 hθ(x) h θ ( x ) 记作 h h ,那么 h=11+e−θTx h = 1 1 + e − θ T x 对 θ θ 求偏导数如下,
∂∂θh=xe−θTx(1+e−θTx)2=xe−θTx1+e−θTx11+e−θTx=x(1−11+e−θTx)11+e−θTx=x(1−h)h ∂ ∂ θ h = x e − θ T x ( 1 + e − θ T x ) 2 = x e − θ T x 1 + e − θ T x 1 1 + e − θ T x = x ( 1 − 1 1 + e − θ T x ) 1 1 + e − θ T x = x ( 1 − h ) h
将Cost(hθ(x),y)=−ylog(hθ(x))−(1−y)log(1−hθ(x)) C o s t ( h θ ( x ) , y ) = − y l o g ( h θ ( x ) ) − ( 1 − y ) l o g ( 1 − h θ ( x ) )简记为Cost(h,y)=−ylog(h)−(1−y)log(1−h) C o s t ( h , y ) = − y l o g ( h ) − ( 1 − y ) l o g ( 1 − h )
那么∂∂θCost(h,y)=−y1h∂∂θh−(1−y)11−h(−∂∂θh)=−y1h∂∂θh+(1−y)11−h∂∂θh=−y(1−h)h(1−h)∂∂θh+h(1−y)h(1−h)∂∂θh=−y+yh+h−yhh(1−h)∂∂θh=h−yh(1−h)∂∂θh=h−yh(1−h)xh(1−h)=x(h−y) ∂ ∂ θ C o s t ( h , y ) = − y 1 h ∂ ∂ θ h − ( 1 − y ) 1 1 − h ( − ∂ ∂ θ h ) = − y 1 h ∂ ∂ θ h + ( 1 − y ) 1 1 − h ∂ ∂ θ h = − y ( 1 − h ) h ( 1 − h ) ∂ ∂ θ h + h ( 1 − y ) h ( 1 − h ) ∂ ∂ θ h = − y + y h + h − y h h ( 1 − h ) ∂ ∂ θ h = h − y h ( 1 − h ) ∂ ∂ θ h = h − y h ( 1 − h ) x h ( 1 − h ) = x ( h − y )
将上式代入 J(θ)=1m∑mi=1Cost(hθ(x),y) J ( θ ) = 1 m ∑ i = 1 m C o s t ( h θ ( x ) , y ) ,可得到
∂θJ(θ)=1m∑i=1m∂∂θCost(hθ(x),y)=1m∑i=1m(hθ(x(i))−y(i))x(i) ∂ θ J ( θ ) = 1 m ∑ i = 1 m ∂ ∂ θ C o s t ( h θ ( x ) , y ) = 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) x ( i )
那么对于梯度下降,
θj:=θj−α∂θJ(θ):=θj−α1m∑i=1m(hθ(x(i))−y(i))x(i)j θ j := θ j − α ∂ θ J ( θ ) := θ j − α 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) x j ( i )
因为 α α 是一个常量,并且 1m 1 m 对于一个给定的样本也是一个常量,所以可以将 αm α m 直接写成 α α 。
三、正则化
1、过拟合
正则化的目的是防止过拟合,当指标较多,并且训练样本较少时得到的模型可能会出现过拟合。过拟合从函数图像上的理解就是,训练得到的模型完全拟合给定样本,可能出现对于训练样本,损失值为0,而对于未在训练样本中出现过的样本,误差会很大。下图示例了过拟合,
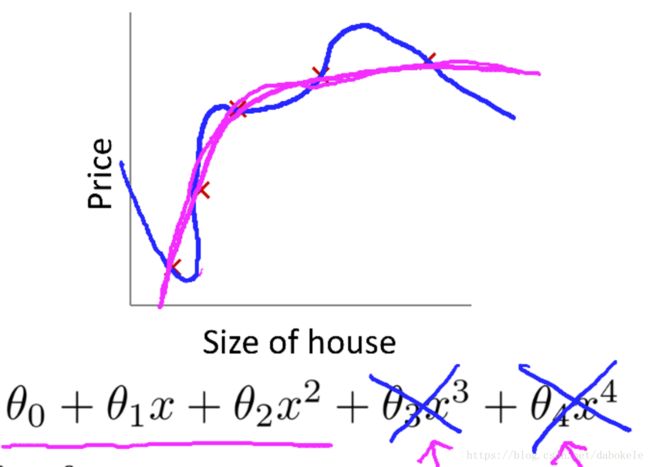
2、线性回归模型正则化
图中蓝色线条为线性回归模型的过拟合情况,增加了 θ3x3 θ 3 x 3 和 θ4x4 θ 4 x 4 两项后,曲线完全拟合给定样本。而红色曲线是训练的比较好的情况。在这里,我们如果想将 θ3x3 θ 3 x 3 和 θ4x4 θ 4 x 4 从模型中剔除,可以将损失函数进行一定改造,如下所示,
上面这个损失函数中,由于给了 θ3 θ 3 和 θ4 θ 4 两个很大的系数,所以最终得到 θ3 θ 3 和 θ4 θ 4 接近于0才能使损失函数值尽可能小。
正则化基本上就是这个过程,会为除 θ0 θ 0 之外每个参数值增加一个类似的系数。增加了正则化后的线性回归模型损失函数如下,
3、欠拟合
假如我们给 λ λ 设置一个很大的参数,可能会出现过拟合的情况,因为这时候需要得到最小损失值,可能会将所有 θ θ 全部训练为0。可能最终得到的目标函数是 hθ(x)=θ0 h θ ( x ) = θ 0 ,欠拟合的函数图形如下所示,
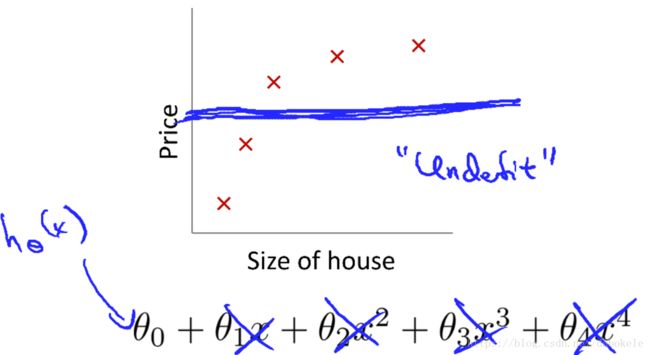
4、线性回归模型梯度下降
对正则化之后的损失函数进行梯度下降求解参数值的过程如下所示,
这里更新 θj θ j 时乘以了一个系数 1−αλm 1 − α λ m ,由于 α,λ,m α , λ , m 都是正数,所以该系数是一个大于零的分数,最终和之前不同的是在更新 θ θ 值时会逐渐缩小 θ θ 值。
5、逻辑回归模型正则化
逻辑回归模型的正则化也是在损失函数最后增加正则项,如下所示,
6、逻辑回归模型梯度下降
7、L1正则
8、L2正则
四、神经网络
1、神经网络结构
神经网络模型是模拟生物神经元,神经网络中每个节点可以理解成一个变量比如 xi x i ,不同层之间的连接线可以理解成参数比如 θj θ j 。神经网络结构如下所示,

上图中,第一层中的 x1,x2,x3 x 1 , x 2 , x 3 即前面回归模型中见到的样本各指标值,第一层也被称为输入层,最后一层的输出就是我们前面介绍到的 hθ(x) h θ ( x ) 的输出值,最后一层也被称为输出层。并且在实现神经网络模型时会为除输出层之外的每一层增加一个 x0 x 0 或$a_0^{(2)}这么一个偏置项。
定义几个概念:
- a(j)i a i ( j ) ,表示第 j j 层的第 i i 个节点
Θ(j) Θ ( j ) ,表示从第 j