2018-2019-2 移动平台应用开发实践第四周作业
第12章枚举
什么情况下使用枚举类?
有的时候一个类的对象是有限且固定的,这种情况下我们使用枚举类就比较方便。- 为什么不用静态常量来替代枚举类呢?
public static final int SEASON_SPRING = 1;
public static final int SEASON_SUMMER = 2;
public static final int SEASON_FALL = 3;
public static final int SEASON_WINTER = 4;枚举类更加直观,类型安全。使用常量会有以下几个缺陷:
- 类型不安全。若一个方法中要求传入季节这个参数,用常量的话,形参就是int类型,开发者传入任意类型的int类型值就行,但是如果是枚举类型的话,就只能传入枚举类中包含的对象。
- 没有命名空间。开发者要在命名的时候以SEASON_开头,这样另外一个开发者再看这段代码的时候,才知道这四个常量分别代表季节。
3.枚举类入门
先看一个简单的枚举类
package enumcase;
public enum SeasonEnum {
SPRING,SUMMER,FALL,WINTER;
}1.enum和class、interface的地位一样
2.使用enum定义的枚举类默认继承了java.lang.Enum,而不是继承Object类。枚举类可以实现一个或多个接口。
3.枚举类的所有实例都必须放在第一行展示,不需使用new 关键字,不需显式调用构造器。自动添加public static final修饰。
4.使用enum定义、非抽象的枚举类默认使用final修饰,不可以被继承。
5.枚举类的构造器只能是私有的。
4.枚举类介绍
枚举类内也可以定义属性和方法,可是是静态的和非静态的。
package enumcase;
public enum SeasonEnum {
SPRING("春天"),SUMMER("夏天"),FALL("秋天"),WINTER("冬天");
private final String name;
private SeasonEnum(String name)
{
this.name = name;
}
public String getName() {
return name;
}
}实际上在第一行写枚举类实例的时候,默认是调用了构造器的,所以此处需要传入参数,因为没有显式申明无参构造器,只能调用有参数的构造器。
构造器需定义成私有的,这样就不能在别处申明此类的对象了。枚举类通常应该设计成不可变类,它的Field不应该被改变,这样会更安全,而且代码更加简洁。所以我们将Field用private final修饰。
5.switch语句里的表达式可以是枚举值
package enumcase;
public class SeasonTest {
public void judge(SeasonEnum s)
{
switch(s)
{
case SPRING:
System.out.println("春天适合踏青。");
break;
case SUMMER:
System.out.println("夏天要去游泳啦。");
break;
case FALL:
System.out.println("秋天一定要去旅游哦。");
break;
case WINTER:
System.out.println("冬天要是下雪就好啦。");
break;
}
}
public static void main(String[] args) {
SeasonEnum s = SeasonEnum.SPRING;
SeasonTest test = new SeasonTest();
test.judge(s);
}
}第十三章 操作时间和日期
一、Java中的日期概述
日期在Java中是一块非常复杂的内容,对于一个日期在不同的语言国别环境中,日期的国际化,日期和时间之间的转换,日期的加减运算,日期的展示格式都是非常复杂的问题。
在Java中,操作日期主要涉及到一下几个类:
1、java.util.Date
类 Date 表示特定的瞬间,精确到毫秒。从 JDK 1.1 开始,应该使用 Calendar 类实现日期和时间字段之间转换,使用 DateFormat 类来格式化和分析日期字符串。Date 中的把日期解释为年、月、日、小时、分钟和秒值的方法已废弃。
2、java.text.DateFormat(抽象类)
DateFormat 是日期/时间格式化子类的抽象类,它以与语言无关的方式格式化并分析日期或时间。日期/时间格式化子类(如 SimpleDateFormat)允许进行格式化(也就是日期 -> 文本)、分析(文本-> 日期)和标准化。将日期表示为 Date 对象,或者表示为从 GMT(格林尼治标准时间)1970 年,1 月 1 日 00:00:00 这一刻开始的毫秒数。
3、java.text.SimpleDateFormat(DateFormat的直接子类)
SimpleDateFormat 是一个以与语言环境相关的方式来格式化和分析日期的具体类。它允许进行格式化(日期 -> 文本)、分析(文本 -> 日期)和规范化。
SimpleDateFormat 使得可以选择任何用户定义的日期-时间格式的模式。但是,仍然建议通过 DateFormat 中的 getTimeInstance、getDateInstance 或 getDateTimeInstance 来新的创建日期-时间格式化程序。
4、java.util.Calendar(抽象类)
Calendar 类是一个抽象类,它为特定瞬间与一组诸如 YEAR、MONTH、DAY_OF_MONTH、HOUR 等 日历字段之间的转换提供了一些方法,并为操作日历字段(例如获得下星期的日期)提供了一些方法。瞬间可用毫秒值来表示,它是距历元(即格林威治标准时间 1970 年 1 月 1 日的 00:00:00.000,格里高利历)的偏移量。
与其他语言环境敏感类一样,Calendar 提供了一个类方法 getInstance,以获得此类型的一个通用的对象。Calendar 的 getInstance 方法返回一个 Calendar 对象,其日历字段已由当前日期和时间初始化。
5、java.util.GregorianCalendar(Calendar的直接子类)
GregorianCalendar 是 Calendar 的一个具体子类,提供了世界上大多数国家使用的标准日历系统。
GregorianCalendar 是一种混合日历,在单一间断性的支持下同时支持儒略历和格里高利历系统,在默认情况下,它对应格里高利日历创立时的格里高利历日期(某些国家是在 1582 年 10 月 15 日创立,在其他国家要晚一些)。可由调用方通过调用 setGregorianChange() 来更改起始日期。
代码清单13.1 使用Instant来计时一项操作
import java.time.Duration;
import java.time.Instant;
public class InstantDemo1{
public static void main(String[] args){
Instant start=Instant.now();
System.out.println("Hello World");
Instant end=Instant.now();
System.out.println(Duration.between(start,end).toMillis());
}
}LocalDate类建模了没有时间部分的日期。
代码清单13.2 LocalDate示例
import java.time.LocalDate;
import java.time.temporal.ChronoField;
import java.time.temporal.ChronoUnit;
public class LocalDateDemo1{
public static void main(String[] args){
LocalDate today=LocalDate.now();
LocalDate tomorrow=today.plusDays(1);
LocalDate oneDecadeAgo=today.minus(1,
ChronoUnit.DECADES);
System.out.println("Day of month:"
+today.getDayOfMonth());
System.out.println("Today is"+today);
System.out.println("Tomorrow is"+tomorrow);
System.out.println("A decade ago was"+oneDecadeAgo);
System.out.println("Year:"
+today.get(ChronoField.YEAR));
System.out.println("Day of year:"+today.getDayOfYear());
}
}1、java.util.Date的API简介
类 java.util.Date 表示特定的瞬间,精确到毫秒。提供了很多的方法,但是很多已经过时,不推荐使用,下面仅仅列出没有过时的方法:
构造方法摘要
-------------
Date()
分配 Date 对象并用当前时间初始化此对象,以表示分配它的时间(精确到毫秒)。
Date(long date)
分配 Date 对象并初始化此对象,以表示自从标准基准时间(称为“历元(epoch)”,即 1970 年 1 月 1 日 00:00:00 GMT)以来的指定毫秒数。
方法摘要
-------------
boolean after(Date when)
测试此日期是否在指定日期之后。
boolean before(Date when)
测试此日期是否在指定日期之前。
Object clone()
返回此对象的副本。
int compareTo(Date anotherDate)
比较两个日期的顺序。
boolean equals(Object obj)
比较两个日期的相等性。
long getTime()
返回自 1970 年 1 月 1 日 00:00:00 GMT 以来此 Date 对象表示的毫秒数。
int hashCode()
返回此对象的哈希码值。
void setTime(long time)
设置此 Date 对象,以表示 1970 年 1 月 1 日 00:00:00 GMT 以后 time 毫秒的时间点。
String toString()
把此 Date 对象转换为以下形式的 String: dow mon dd hh:mm:ss zzz yyyy 其中:
dow 是一周中的某一天 (Sun, Mon, Tue, Wed, Thu, Fri, Sat)。
mon 是月份 (Jan, Feb, Mar, Apr, May, Jun, Jul, Aug, Sep, Oct, Nov, Dec)。
dd 是一月中的某一天(01 至 31),显示为两位十进制数。
hh 是一天中的小时(00 至 23),显示为两位十进制数。
mm 是小时中的分钟(00 至 59),显示为两位十进制数。
ss 是分钟中的秒数(00 至 61),显示为两位十进制数。
zzz 是时区(并可以反映夏令时)。标准时区缩写包括方法 parse 识别的时区缩写。如果不提供时区信息,则 zzz 为空,即根本不包括任何字符。
yyyy 是年份,显示为 4 位十进制数。
import java.util.Date;
/**
* Created by IntelliJ IDEA.
* User: leizhimin
* Date: 2007-11-30
* Time: 8:45:44
* 日期测试
*/
public class TestDate {
public static void main(String args[]) {
TestDate nowDate = new TestDate();
nowDate.getSystemCurrentTime();
nowDate.getCurrentDate();
}
/**
* 获取系统当前时间
* System.currentTimeMillis()返回系统当前时间,结果为1970年1月1日0时0分0秒开始,到程序执行取得系统时间为止所经过的毫秒数
* 1秒=1000毫秒
*/
public void getSystemCurrentTime() {
System.out.println("----获取系统当前时间----");
System.out.println("系统当前时间 = " + System.currentTimeMillis());
}
/**
* 通过Date类获取当前日期和当前时间
* date.toString()把日期转换为dow mon dd hh:mm:ss zzz yyyy
*/
public void getCurrentDate() {
System.out.println("----获取系统当前日期----");
//创建并初始化一个日期(初始值为当前日期)
Date date = new Date();
System.out.println("现在的日期是 = " + date.toString());
System.out.println("自1970年1月1日0时0分0秒开始至今所经历的毫秒数 = " + date.getTime());
}
}
运行结果:
----获取系统当前时间----
系统当前时间 = 1196413077278
----获取系统当前日期----
现在的日期是 = Fri Nov 30 16:57:57 CST 2007
自1970年1月1日0时0分0秒开始至今所经历的毫秒数 = 1196413077278 2、java.text.DateFormat抽象类的使用
DateFormat 是日期/时间格式化子类的抽象类,它以与语言无关的方式格式化并分析日期或时间。日期/时间格式化子类(如 SimpleDateFormat)允许进行格式化(也就是日期 -> 文本)、分析(文本-> 日期)和标准化。将日期表示为 Date 对象,或者表示为从 GMT(格林尼治标准时间)1970 年,1 月 1 日 00:00:00 这一刻开始的毫秒数。
DateFormat 提供了很多类方法,以获得基于默认或给定语言环境和多种格式化风格的默认日期/时间 Formatter。格式化风格包括 FULL、LONG、MEDIUM 和 SHORT。方法描述中提供了使用这些风格的更多细节和示例。
DateFormat 可帮助进行格式化并分析任何语言环境的日期。对于月、星期,甚至日历格式(阴历和阳历),其代码可完全与语言环境的约定无关。
要格式化一个当前语言环境下的日期,可使用某个静态工厂方法:
myString = DateFormat.getDateInstance().format(myDate);
如果格式化多个日期,那么获得该格式并多次使用它是更为高效的做法,这样系统就不必多次获取有关环境语言和国家约定的信息了。
DateFormat df = DateFormat.getDateInstance();
for (int i = 0; i < myDate.length; ++i) {
output.println(df.format(myDate[i]) + "; ");
}
要格式化不同语言环境的日期,可在 getDateInstance() 的调用中指定它。
DateFormat df = DateFormat.getDateInstance(DateFormat.LONG, Locale.FRANCE);
还可使用 DateFormat 进行分析。
myDate = df.parse(myString);
使用 getDateInstance 来获得该国家的标准日期格式。另外还提供了一些其他静态工厂方法。使用 getTimeInstance 可获得该国家的时间格式。使用 getDateTimeInstance 可获得日期和时间格式。可以将不同选项传入这些工厂方法,以控制结果的长度(从 SHORT 到 MEDIUM 到 LONG 再到 FULL)。确切的结果取决于语言环境,但是通常:
SHORT 完全为数字,如 12.13.52 或 3:30pm
MEDIUM 较长,如 Jan 12, 1952
LONG 更长,如 January 12, 1952 或 3:30:32pm
FULL 是完全指定,如 Tuesday, April 12, 1952 AD 或 3:30:42pm PST。
如果愿意,还可以在格式上设置时区。如果想对格式化或分析施加更多的控制(或者给予用户更多的控制),可以尝试将从工厂方法所获得的 DateFormat 强制转换为 SimpleDateFormat。这适用于大多数国家;只是要记住将其放入一个 try 代码块中,以防遇到特殊的格式。
还可以使用借助 ParsePosition 和 FieldPosition 的分析和格式化方法形式来:逐步地分析字符串的各部分。 对齐任意特定的字段,或者找出字符串在屏幕上的选择位置。
DateFormat 不是同步的。建议为每个线程创建独立的格式实例。如果多个线程同时访问一个格式,则它必须保持外部同步
3、java.util.Calendar(抽象类)
java.util.Calendar是个抽象类,是系统时间的抽象表示,它为特定瞬间与一组诸如 YEAR、MONTH、DAY_OF_MONTH、HOUR 等 日历字段之间的转换提供了一些方法,并为操作日历字段(例如获得下星期的日期)提供了一些方法。瞬间可用毫秒值来表示,它是距历元(即格林威治标准时间 1970 年 1 月 1 日的 00:00:00.000,格里高利历)的偏移量。
与其他语言环境敏感类一样,Calendar 提供了一个类方法 getInstance,以获得此类型的一个通用的对象。Calendar 的 getInstance 方法返回一个 Calendar 对象,其日历字段已由当前日期和时间初始化。
一个Calendar的实例是系统时间的抽象表示,从Calendar的实例可以知道年月日星期月份时区等信息。Calendar类中有一个静态方法get(int x),通过这个方法可以获取到相关实例的一些值(年月日星期月份等)信息。参数x是一个产量值,在Calendar中有定义。
Calendar中些陷阱,很容易掉下去:
1、Calendar的星期是从周日开始的,常量值为0。
2、Calendar的月份是从一月开始的,常量值为0。
3、Calendar的每个月的第一天值为1
第十四章 集合框架
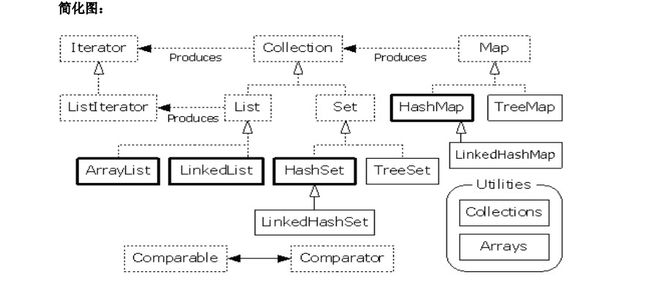
说明:对于以上的框架图有如下几点说明
1.所有集合类都位于java.util包下。Java的集合类主要由两个接口派生而出:Collection和Map,Collection和Map是Java集合框架的根接口,这两个接口又包含了一些子接口或实现类。
- 集合接口:6个接口(短虚线表示),表示不同集合类型,是集合框架的基础。
- 抽象类:5个抽象类(长虚线表示),对集合接口的部分实现。可扩展为自定义集合类。
- 实现类:8个实现类(实线表示),对接口的具体实现。
- Collection 接口是一组允许重复的对象。
- Set 接口继承 Collection,集合元素不重复。
- List 接口继承 Collection,允许重复,维护元素插入顺序。
- Map接口是键-值对象,与Collection接口没有什么关系。
9.Set、List和Map可以看做集合的三大类:
List集合是有序集合,集合中的元素可以重复,访问集合中的元素可以根据元素的索引来访问。
Set集合是无序集合,集合中的元素不可以重复,访问集合中的元素只能根据元素本身来访问(也是集合里元素不允许重复的原因)。
Map集合中保存Key-value对形式的元素,访问时只能根据每项元素的key来访问其value。
Collection接口是处理对象集合的根接口,其中定义了很多对元素进行操作的方法。Collection接口有两个主要的子接口List和Set,注意Map不是Collection的子接口,这个要牢记
**1.List接口*
List集合代表一个有序集合,集合中每个元素都有其对应的顺序索引。List集合允许使用重复元素,可以通过索引来访问指定位置的集合元素。
List接口继承于Collection接口,它可以定义一个允许重复的有序集合。因为List中的元素是有序的,所以我们可以通过使用索引(元素在List中的位置,类似于数组下标)来访问List中的元素,这类似于Java的数组。
List接口为Collection直接接口。List所代表的是有序的Collection,即它用某种特定的插入顺序来维护元素顺序。用户可以对列表中每个元素的插入位置进行精确地控制,同时可以根据元素的整数索引(在列表中的位置)访问元素,并搜索列表中的元素。实现List接口的集合主要有:ArrayList、LinkedList、Vector、Stack。
(1)ArrayList
ArrayList是一个动态数组,也是我们最常用的集合。它允许任何符合规则的元素插入甚至包括null。每一个ArrayList都有一个初始容量(10),该容量代表了数组的大小。随着容器中的元素不断增加,容器的大小也会随着增加。在每次向容器中增加元素的同时都会进行容量检查,当快溢出时,就会进行扩容操作。所以如果我们明确所插入元素的多少,最好指定一个初始容量值,避免过多的进行扩容操作而浪费时间、效率。
size、isEmpty、get、set、iterator 和 listIterator 操作都以固定时间运行。add 操作以分摊的固定时间运行,也就是说,添加 n 个元素需要 O(n) 时间(由于要考虑到扩容,所以这不只是添加元素会带来分摊固定时间开销那样简单)。
ArrayList擅长于随机访问。同时ArrayList是非同步的。(2)LinkedList
同样实现List接口的LinkedList与ArrayList不同,ArrayList是一个动态数组,而LinkedList是一个双向链表。所以它除了有ArrayList的基本操作方法外还额外提供了get,remove,insert方法在LinkedList的首部或尾部。
由于实现的方式不同,LinkedList不能随机访问,它所有的操作都是要按照双重链表的需要执行。在列表中索引的操作将从开头或结尾遍历列表(从靠近指定索引的一端)。这样做的好处就是可以通过较低的代价在List中进行插入和删除操作。
与ArrayList一样,LinkedList也是非同步的。如果多个线程同时访问一个List,则必须自己实现访问同步。一种解决方法是在创建List时构造一个同步的List: List list = Collections.synchronizedList(new LinkedList(...))
2.Set接口
Set是一种不包括重复元素的Collection。它维持它自己的内部排序,所以随机访问没有任何意义。与List一样,它同样允许null的存在但是仅有一个。由于Set接口的特殊性,所有传入Set集合中的元素都必须不同,同时要注意任何可变对象,如果在对集合中元素进行操作时,导致e1.equals(e2)==true,则必定会产生某些问题。Set接口有三个具体实现类,分别是散列集HashSet、链式散列集LinkedHashSet和树形集TreeSet。
Set是一种不包含重复的元素的Collection,无序,即任意的两个元素e1和e2都有e1.equals(e2)=false,Set最多有一个null元素。需要注意的是:虽然Set中元素没有顺序,但是元素在set中的位置是由该元素的HashCode决定的,其具体位置其实是固定的。
3.Hash Set
HashSet 是一个没有重复元素的集合。它是由HashMap实现的,不保证元素的顺序(这里所说的没有顺序是指:元素插入的顺序与输出的顺序不一致),而且HashSet允许使用null 元素。HashSet是非同步的,如果多个线程同时访问一个哈希set,而其中至少一个线程修改了该set,那么它必须保持外部同步。 HashSet按Hash算法来存储集合的元素,因此具有很好的存取和查找性能。
HashSet的实现方式大致如下,通过一个HashMap存储元素,元素是存放在HashMap的Key中,而Value统一使用一个Object对象。
HashSet使用和理解中容易出现的误区:
a.HashSet中存放null值
HashSet中是允许存入null值的,但是在HashSet中仅仅能够存入一个null值。
b.HashSet中存储元素的位置是固定的
HashSet中存储的元素的是无序的,这个没什么好说的,但是由于HashSet底层是基于Hash算法实现的,使用了hashcode,所以HashSet中相应的元素的位置是固定的。
c.必须小心操作可变对象(Mutable Object)。如果一个Set中的可变元素改变了自身状态导致Object.equals(Object)=true将导致一些问题。
4.Map接口
Map与List、Set接口不同,它是由一系列键值对组成的集合,提供了key到Value的映射。同时它也没有继承Collection。在Map中它保证了key与value之间的一一对应关系。也就是说一个key对应一个value,所以它不能存在相同的key值,当然value值可以相同。1.HashMap
以哈希表数据结构实现,查找对象时通过哈希函数计算其位置,它是为快速查询而设计的,其内部定义了一个hash表数组(Entry[] table),元素会通过哈希转换函数将元素的哈希地址转换成数组中存放的索引,如果有冲突,则使用散列链表的形式将所有相同哈希地址的元素串起来,可能通过查看HashMap.Entry的源码它是一个单链表结构。5.Iterator
1.Iterator
Iterator的定义如下:
public interface Iterator {}
Iterator是一个接口,它是集合的迭代器。集合可以通过Iterator去遍历集合中的元素。Iterator提供的API接口如下:
boolean hasNext():判断集合里是否存在下一个元素。如果有,hasNext()方法返回 true。
Object next():返回集合里下一个元素。
void remove():删除集合里上一次next方法返回的元素。
使用示例:
public class IteratorExample {
public static void main(String[] args) {
ArrayList a = new ArrayList();
a.add("aaa");
a.add("bbb");
a.add("ccc");
System.out.println("Before iterate : " + a);
Iterator it = a.iterator();
while (it.hasNext()) {
String t = it.next();
if ("bbb".equals(t)) {
it.remove();
}
}
System.out.println("After iterate : " + a);
}
}
输出结果如下:
Before iterate : [aaa, bbb, ccc]
After iterate : [aaa, ccc] 第十五章 泛型
1.什么是泛型
泛型,即“参数化类型”。一提到参数,最熟悉的就是定义方法时有形参,然后调用此方法时传递实参。那么参数化类型怎么理解呢?顾名思义,就是将类型由原来的具体的类型参数化,类似于方法中的变量参数,此时类型也定义成参数形式(可以称之为类型形参),然后在使用/调用时传入具体的类型(类型实参)。看着好像有点复杂,首先我们看下上面那个例子采用泛型的写法。
1 public class GenericTest {
2
3 public static void main(String[] args) {
4 /*
5 List list = new ArrayList();
6 list.add("qqyumidi");
7 list.add("corn");
8 list.add(100);
9 */
10
11 List list = new ArrayList();
12 list.add("qqyumidi");
13 list.add("corn");
14 //list.add(100); // 1 提示编译错误
15
16 for (int i = 0; i < list.size(); i++) {
17 String name = list.get(i); // 2
18 System.out.println("name:" + name);
19 }
20 }
21 } 采用泛型写法后,在//1处想加入一个Integer类型的对象时会出现编译错误,通过List,直接限定了list集合中只能含有String类型的元素,从而在//2处无须进行强制类型转换,因为此时,集合能够记住元素的类型信息,编译器已经能够确认它是String类型了。
结合上面的泛型定义,我们知道在List中,String是类型实参,也就是说,相应的List接口中肯定含有类型形参。且get()方法的返回结果也直接是此形参类型(也就是对应的传入的类型实参)。下面就来看看List接口的的具体定义:
1 public interface List extends Collection {
2
3 int size();
4
5 boolean isEmpty();
6
7 boolean contains(Object o);
8
9 Iterator iterator();
10
11 Object[] toArray();
12
13 T[] toArray(T[] a);
14
15 boolean add(E e);
16
17 boolean remove(Object o);
18
19 boolean containsAll(Collection c);
20
21 boolean addAll(Collection c);
22
23 boolean addAll(int index, Collection c);
24
25 boolean removeAll(Collection c);
26
27 boolean retainAll(Collection c);
28
29 void clear();
30
31 boolean equals(Object o);
32
33 int hashCode();
34
35 E get(int index);
36
37 E set(int index, E element);
38
39 void add(int index, E element);
40
41 E remove(int index);
42
43 int indexOf(Object o);
44
45 int lastIndexOf(Object o);
46
47 ListIterator listIterator();
48
49 ListIterator listIterator(int index);
50
51 List subList(int fromIndex, int toIndex);
52 } 我们可以看到,在List接口中采用泛型化定义之后,中的E表示类型形参,可以接收具体的类型实参,并且此接口定义中,凡是出现E的地方均表示相同的接受自外部的类型实参。
自然的,ArrayList作为List接口的实现类,其定义形式是:
1 public class ArrayList extends AbstractList
2 implements List, RandomAccess, Cloneable, java.io.Serializable {
3
4 public boolean add(E e) {
5 ensureCapacityInternal(size + 1); // Increments modCount!!
6 elementData[size++] = e;
7 return true;
8 }
9
10 public E get(int index) {
11 rangeCheck(index);
12 checkForComodification();
13 return ArrayList.this.elementData(offset + index);
14 }
15
16 //...省略掉其他具体的定义过程
17
18 } 由此,我们从源代码角度明白了为什么//1处加入Integer类型对象编译错误,且//2处get()到的类型直接就是String类型了。
自定义泛型接口、泛型类和泛型方法
从上面的内容中,大家已经明白了泛型的具体运作过程。也知道了接口、类和方法也都可以使用泛型去定义,以及相应的使用。是的,在具体使用时,可以分为泛型接口、泛型类和泛型方法。
自定义泛型接口、泛型类和泛型方法与上述Java源码中的List、ArrayList类似。如下,我们看一个最简单的泛型类和方法定义:
1 public class GenericTest {
2
3 public static void main(String[] args) {
4
5 Box name = new Box("corn");
6 System.out.println("name:" + name.getData());
7 }
8
9 }
10
11 class Box {
12
13 private T data;
14
15 public Box() {
16
17 }
18
19 public Box(T data) {
20 this.data = data;
21 }
22
23 public T getData() {
24 return data;
25 }
26
27 } 在泛型接口、泛型类和泛型方法的定义过程中,我们常见的如T、E、K、V等形式的参数常用于表示泛型形参,由于接收来自外部使用时候传入的类型实参。那么对于不同传入的类型实参,生成的相应对象实例的类型是不是一样的呢?
1 public class GenericTest {
2
3 public static void main(String[] args) {
4
5 Box name = new Box("corn");
6 Box age = new Box(712);
7
8 System.out.println("name class:" + name.getClass()); // com.qqyumidi.Box
9 System.out.println("age class:" + age.getClass()); // com.qqyumidi.Box
10 System.out.println(name.getClass() == age.getClass()); // true
11
12 }
13
14 } 由此,我们发现,在使用泛型类时,虽然传入了不同的泛型实参,但并没有真正意义上生成不同的类型,传入不同泛型实参的泛型类在内存上只有一个,即还是原来的最基本的类型(本实例中为Box),当然,在逻辑上我们可以理解成多个不同的泛型类型。
究其原因,在于Java中的泛型这一概念提出的目的,导致其只是作用于代码编译阶段,在编译过程中,对于正确检验泛型结果后,会将泛型的相关信息擦出,也就是说,成功编译过后的class文件中是不包含任何泛型信息的。泛型信息不会进入到运行时阶段。
对此总结成一句话:泛型类型在逻辑上看以看成是多个不同的类型,实际上都是相同的基本类型。
statistics.sh脚本运行结果的截图