爬虫简介
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
其实,说白了就是爬虫可以模拟浏览器的行为做你想做的事,订制化自己搜索和下载的内容,并实现自动化的操作。比如浏览器可以下载小说,但是有时候并不能批量下载,那么爬虫的功能就有用武之地了。
实现爬虫技术的编程环境有很多种,Java,Python,C++等都可以用来爬虫。但是博主选择了Python,相信很多人也一样选择Python,因为Python确实很适合做爬虫,丰富的第三方库十分强大,简单几行代码便可实现你想要的功能,更重要的,Python也是数据挖掘和分析的好能手。
requests库
Requests 唯一的一个非转基因的 Python HTTP 库,人类可以安全享用。
警告:非专业使用其他 HTTP 库会导致危险的副作用,包括:安全缺陷症、冗余代码症、重新发明轮子症、啃文档症、抑郁、头疼、甚至死亡。
Requests 允许你发送纯天然,植物饲养的 HTTP/1.1 请求,无需手工劳动。你不需要手动为 URL 添加查询字串,也不需要对 POST 数据进行表单编码。Keep-alive 和 HTTP 连接池的功能是 100% 自动化的,一切动力都来自于根植在 Requests 内部的 urllib3。
各种请求方式
requests里提供个各种请求方式
import requests
requests.post("http://httpbin.org/post")
requests.put("http://httpbin.org/put")
requests.delete("http://httpbin.org/delete")
requests.head("http://httpbin.org/get")
requests.options("http://httpbin.org/get")
基本GET请求
import requests
response = requests.get('http://httpbin.org/get')
print(response.text)
带参数的GET请求
import requests
response = requests.get("http://httpbin.org/get?name=zhaofan&age=23")
print(response.text)
import requests
data = {
"name":"zhaofan",
"age":22
}
response = requests.get("http://httpbin.org/get",params=data)
print(response.url)
print(response.text)
上述两种的结果是相同的,通过params参数传递一个字典内容,从而直接构造url
注意:第二种方式通过字典的方式的时候,如果字典中的参数为None则不会添加到url上
基本POST请求
通过在发送post请求时添加一个data参数,这个data参数可以通过字典构造成,这样
对于发送post请求就非常方便
import requests
data = {
"name":"zhaofan",
"age":23
}
response = requests.post("http://httpbin.org/post",data=data)
print(response.text)
同样的在发送post请求的时候也可以和发送get请求一样通过headers参数传递一个字典类型的数据
响应
我们可以通过response获得很多属性,例子如下
import requests
response = requests.get("http://www.baidu.com")
print(type(response.status_code),response.status_code)
print(type(response.headers),response.headers)
print(type(response.cookies),response.cookies)
print(type(response.url),response.url)
print(type(response.history),response.history)
获取cookie
import requests
response = requests.get("http://www.baidu.com")
print(response.cookies)
for key,value in response.cookies.items():
print(key+"="+value)
会话维持
cookie的一个作用就是可以用于模拟登陆,做会话维持
import requests
s = requests.Session()
s.get("http://httpbin.org/cookies/set/number/123456")
response = s.get("http://httpbin.org/cookies")
print(response.text)
证书验证
现在的很多网站都是https的方式访问,所以这个时候就涉及到证书的问题
import requests
response = requests.get("https:/www.12306.cn")
print(response.status_code)
import requests
from requests.packages import urllib3
urllib3.disable_warnings()
response = requests.get("https://www.12306.cn",verify=False)
print(response.status_code)
代理设置
import requests
proxies= {
"http":"http://127.0.0.1:9999",
"https":"http://127.0.0.1:8888"
}
response = requests.get("https://www.baidu.com",proxies=proxies)
print(response.text)
超时设置
通过timeout参数可以设置超时的时间
认证设置
如果碰到需要认证的网站可以通过requests.auth模块实现
import requests
from requests.auth import HTTPBasicAuth
response = requests.get("http://120.27.34.24:9001/",auth=HTTPBasicAuth("user","123"))
print(response.status_code)
import requests
response = requests.get("http://120.27.34.24:9001/",auth=("user","123"))
print(response.status_code)
xpath解析Dom树
XPath 是一门在 XML 文档中查找信息的语言。
XPath 是 XSLT 中的主要元素。
XQuery 和 XPointer 均构建于 XPath 表达式之上
XPath总体来说功能很强大,而且查找效率别正则表达式要好很多,这里我们只用到一部分常用功能。
选取节点
XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。 下面列出了最有用的路径表达式:

在下面的表格中,我们已列出了一些路径表达式以及表达式的结果:

谓语(Predicates)
谓语用来查找某个特定的节点或者包含某个指定的值的节点。
谓语被嵌在方括号中。
在下面的表格中,我们列出了带有谓语的一些路径表达式,以及表达式的结果:

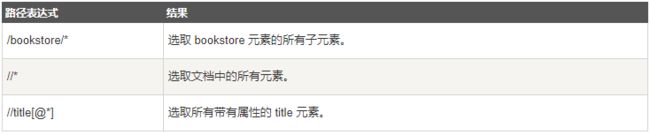
选取未知节点
XPath 通配符可用来选取未知的 XML 元素。
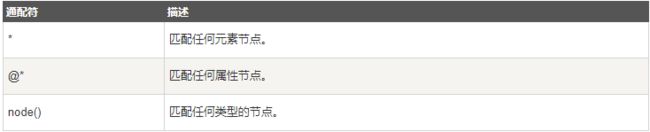
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
选取若干路径
通过在路径表达式中使用"|"运算符,您可以选取若干个路径。
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:

模拟GitHub登录获取个人信息
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# Created by master on 2018/7/2 16:21.
import requests
import re
from lxml import etree
user_headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh,en;q=0.9,zh-CN;q=0.8',
}
# html文档下载模块
def download_html(user, pwd):
login_url = 'https://github.com/login'
# 使用session自动处理cookies
session = requests.Session()
# 获取authenticity_token
response = session.get(login_url, headers=user_headers, verify=False)
pattern = re.compile(r'')
authenticity_token = pattern.findall(response.text)[0]
# 登录参数
login_data = {
'commit': 'Sign in',
'utf8': '✓',
'authenticity_token': authenticity_token, 'login': user,
'password': pwd
}
# 登录
session_url = 'https://github.com/session'
response = session.post(session_url, headers=user_headers, data=login_data, verify=False)
pattern = re.compile(r'Incorrect username or password')
if pattern.findall(response.text): # 密码错误
print("账号或密码错误!")
return
else:
# 获取user_id
pattern = re.compile(r'Signed in as (.*)')
user_id = pattern.findall(response.text)[0]
# 请求个人信息页面
response = session.get("https://github.com/" + user_id, headers=user_headers, verify=False)
return etree.HTML(response.text)
# 信息解析模块
def parse_html(html):
if not html:
return
your_avatar = html.xpath("//img[@class='avatar width-full rounded-2']/@src")[0]
your_nickname = html.xpath("//span[@class='p-name vcard-fullname d-block overflow-hidden']/text()")[0]
your_user_id = html.xpath("//span[@class='p-nickname vcard-username d-block']/text()")[0]
your_repositories = html.xpath("//a[@class='UnderlineNav-item '][@title='Repositories']/span/text()")[0]
your_stars = html.xpath("//a[@class='UnderlineNav-item '][@title='Stars']/span/text()")[0]
your_follows = html.xpath("//a[@class='UnderlineNav-item '][@title='Followers']/span/text()")[0]
your_following = html.xpath("//a[@class='UnderlineNav-item '][@title='Following']/span/text()")[0]
print("your avatar url: %s" % your_avatar)
print("your nick name: %s" % trim(your_nickname))
print("your user id: %s" % trim(your_user_id))
print("your repositories count: %s" % trim(your_repositories))
print("your starts count: %s" % trim(your_stars))
print("your follows count: %s" % trim(your_follows))
print("your fans count: %s" % trim(your_following))
# 去掉空格和换行
def trim(txt):
return txt.strip().replace("\n", "")
if __name__ == '__main__':
username = input("请输入您的GitHub账号:")
password = input("请输入您的GitHub密码:")
html_doc = download_html(username, password)
parse_html(html_doc)
输出
请输入您的GitHub账号:**********
请输入您的GitHub密码:**********
your avatar url: https://avatars2.githubusercontent.com/u/11495586?s=460&v=4
your nick name: lxy
your user id: lxygithub
your repositories count: 29
your starts count: 60
your follows count: 2
your fans count: 6