反反爬技术,破解猫眼网加密数字
From:https://blog.csdn.net/qq_31032181/article/details/79153578
From:http://www.freebuf.com/news/140965.html
利用自定义web-font实现数据防采集:http://blog.csdn.net/fdipzone/article/details/68166388
利用前端字体文件(.ttf)混淆数字来阻止爬虫爬取数据:https://blog.csdn.net/qq_37540004/article/details/78864713
反击爬虫,前端工程师的脑洞可以有多大?:https://baijiahao.baidu.com/s?id=1572788572555517
反爬虫解析-字体替换(天眼查/猫眼电影):https://www.jianshu.com/p/79c4272c0969
猫_眼_电_影 字体文件 @font-face:https://www.cnblogs.com/my8100/p/js_maoyandianying.html
Github 地址:猫眼电影字体加载还原
FontTools 安装与使用简明指南:https://darknode.in/font/font-tools-guide
崔庆才 - 字体反爬:https://cuiqingcai.com/6431.html
**************
2019/8/21 猫眼的字体反爬变了,这篇文章中方法现在破解不了了
原来是: unicode编码 <----------> 字体形状编码(字形编码固定不变) <----------> 对应字符编码
现在是: unicode编码 <----------> 字体形状编码(字形编码变化) <----------> 对应字符编码
可以参考这篇破解猫眼字体反爬:https://blog.csdn.net/weixin_43145520/article/details/89878788
**************
示例
1. 打开 地址:https://maoyan.com/cinema/15280?poi=99389254
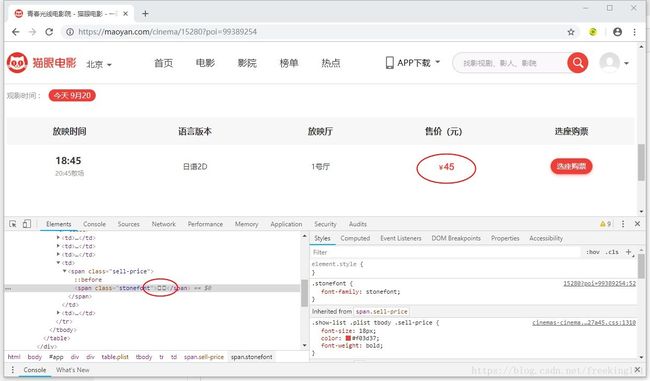
发现数字是乱码。
2. 在网页 上 右键 ——> 查看网页源代码 找到 加密数字
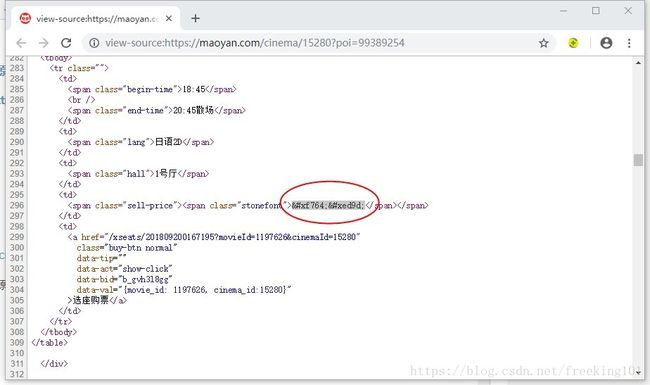
加密数字:
3. 在网页源码搜索 font-face,然后提取 font 的 url。
此处提取的 font url 是 //vfile.meituan.net/colorstone/44d84ad862bdc7074d0909ee5bf108512088.woff ,然后在加上 http 得到完整的 url 地址:http://vfile.meituan.net/colorstone/44d84ad862bdc7074d0909ee5bf108512088.woff

4. 把提取 的 加密字体 赋值 给 程序中 unicode_1 和 unicode_2 ,字体 url 地址 赋值给 web_font_url, 运行程序
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# @Author :
# @File : font_data.py
# @Software : PyCharm
# @description : XXX
import os
import base64
from fontTools.ttLib import TTFont
import requests
file_abs_path = os.path.abspath(__file__)
# file_name = os.path.basename(file_abs_path)
current_dir = os.path.dirname(file_abs_path)
# grader_father = os.path.abspath(os.path.dirname(current_dir) + os.path.sep + "..")
# father_dir = os.path.abspath(os.path.dirname(current_dir))
font_encrypt_data = "d09GRgABAAAAAAgcAAsAAAAAC7gAAQAAAAAAAAAAAAAAAAAAAAAAAAAAAABHU1VCAAABCAAAADMAAABCsP6z7U9TLzIAAAE8AAAARAAAAFZW7ld+Y21hcAAAAYAAAAC6AAACTDNal69nbHlmAAACPAAAA5AAAAQ0l9+jTWhlYWQAAAXMAAAALwAAADYSf7X+aGhlYQAABfwAAAAcAAAAJAeKAzlobXR4AAAGGAAAABIAAAAwGhwAAGxvY2EAAAYsAAAAGgAAABoGLgUubWF4cAAABkgAAAAfAAAAIAEZADxuYW1lAAAGaAAAAVcAAAKFkAhoC3Bvc3QAAAfAAAAAWgAAAI/mSOW8eJxjYGRgYOBikGPQYWB0cfMJYeBgYGGAAJAMY05meiJQDMoDyrGAaQ4gZoOIAgCKIwNPAHicY2Bk0mWcwMDKwMHUyXSGgYGhH0IzvmYwYuRgYGBiYGVmwAoC0lxTGBwYKn6wM+v812GIYdZhuAIUZgTJAQDX7QsReJzFkbENgzAQRb8DgQRSuPQAlFmFfZggDW0mSZUlGMISokBILpAlGkS+OZpI0CZnPUv3bd2d7gM4A4jIncSAekMhxIuqWvUI2arHeDA30FQuqKyxvvVd05fD7LQrxnpKl4U/jl/2QrHi3gkvV06XsVuMFAl7npBTTg4q/SDU/1p/x229n1vGraDa4IjWCNwfrBeCz60Xgp9dIwTv+1II/g+zwI3DaYG7hysEuoCxFugHplRA/gGlP0OcAAB4nD1Tz2/aVhx/z1R26lBCho0LaQEDsQ0kwfEvAjhAcaDNT0YChJCWhqilNFvbLGq6tI22lv2Q2ml/QHuptMMu1Q69d9K0nrZOWw77Aybtutsq9RLBnoHFt/ee/P38/AIIQPcfIAEKYADEZJryUAJAHzp138Fj7A/04gXAocRSUJYYJ+OkKZywwYCf52KUU9LsPOcn8LDL3VrZS56z2622seuFG3q+VnywFhYeBidho72wUtoMZ/Rb6Sa/srZQffvq7j7cSibkLADQBIPvEU4QgHGaRTgWBBXTFC7gxwk+BaUBImGzEPB9hx8mx4Q4lyjQoUU9vQRrpw9+P2AjlCEKEvPBUKnk9biiUdUnLpyfuT6/kCebN/fKk8sSkxbYybPMGfA/5j7CtALABkbRbFUzQWW4X/W1hPmZMWE4joke3V72Sy6R6fuB/jnGfgMkQDNYlVWhPCrTAZoftUCj8yvMX2o0qn+9LMKjjlh8eYzufjzxsYOwfGACTeB4pIsw9dCmoUib6SWnKjGtZy+kPOhaUxXOj8PnVjqohH1hxnrGtymvHyauZW8/XTI+KWuqtfOMz3FasXCvhDkVZpzxxs+vadNT7aZxd/bF66P6qjhV6rydKEdqy/PrlT4PDCAeARBFSZsoSHEKzkKFxwm8xwFR8MA+I57jYS8CmmJQyt8M62I4ydtwArqiE7GNB59vz+3ryXuFsqKRsLU6k6yEwvcLP+jqeEp1a2NDp/Cw2/1o59ZXi9+2n35XnoqWYXJpo76SD0XWQT+D7r+wi/hEBmw0pWdNjOmp74Wv9UzxQJS/ycskybdHLmqpMh/S3UHSFt9Ia/IcWbXHE6WENK1K0+mLT1pXD0//spitHPICuQyTs2I6lR2pRafdZ6tbi86Ry/krX+zWwEkPutgb4EANV1kaNQwnAmb7zDZE4VHAmJMdrqFNOGr3Jj0ZFrtdzgUb9x9mah+Fm/rBnfhlDo2wnHhr7sokmmV6aWbbp43MRGe0LbJk9tqPWyi0R0hx//Tq493XezvZXPvPC5m8mFXEAGs0L5zzj/tDPpkOlT4rwi+FnQ9v3llqCc6r2SuHKb2Rr3+vpH3eupHpPOFzlIOm+EerxYGv77BT2M/m1g587ZvpYGmWGHTOzBsl/DU5r2WqFSNiUGs5eK3zN++bC9Qfx3Ofbs+mht7kstvPKpyXhLuln5zM4xtbl9a1mRr4D3C64MJ4nGNgZGBgAOKQyuTT8fw2Xxm4WRhA4PoGS2UE/f8NCwPTeSCXg4EJJAoAIT0KPAB4nGNgZGBg1vmvwxDDwgACQJKRARXwAAAzYgHNeJxjYQCCFAYGJh3iMAA3jAI1AAAAAAAAAAwAQAB6AJQAsAD0ATwBfgGiAegCGgAAeJxjYGRgYOBhMGBgZgABJiDmAkIGhv9gPgMADoMBVgB4nGWRu27CQBRExzzyAClCiZQmirRN0hDMQ6lQOiQoI1HQG7MGI7+0XpBIlw/Id+UT0qXLJ6TPYK4bxyvvnjszd30lA7jGNxycnnu+J3ZwwerENZzjQbhO/Um4QX4WbqKNF+Ez6jPhFrp4FW7jBm+8wWlcshrjQ9hBB5/CNVzhS7hO/Ue4Qf4VbuLWaQqfoePcCbewcLrCbTw67y2lJkZ7Vq/U8qCCNLE93zMm1IZO6KfJUZrr9S7yTFmW50KbPEwTNXQHpTTTiTblbfl+PbI2UIFJYzWlq6MoVZlJt9q37sbabNzvB6K7fhpzPMU1gYGGB8t9xXqJA/cAKRJqPfj0DFdI30hPSPXol6k5vTV2iIps1a3Wi+KmnPqxVhjCxeBfasZUUiSrs+XY82sjqpbp46yGPTFpKr2ak0RkhazwtlR86i42RVfGn93nCip5t5gh/gPYnXLBAHicbcpLEkAwEATQ6fiEiLskBNkS5i42dqocX8ls9eZVdTcpkhj6j4VCgRIVamg0aGHQwaInPPq+Th7j9nnMac+uQfQ8Zdm7bGLpeQiy+5gN8uPoFqIXKTcXwQAA"
font_decrypt_data = base64.b64decode(font_encrypt_data)
file = open(os.path.join(current_dir, 'base.woff'), 'wb')
file.write(font_decrypt_data)
file.close()
base_num_dict = {
"uniEA4D": "1", "uniE6CD": "2", "uniEF24": "3", "uniE1F5": "4", "uniF807": "5",
"uniEF10": "6", "uniE118": "7", "uniE4F5": "8", "uniECFD": "9", "uniF38B": "0"
}
base_font = TTFont(os.path.join(current_dir, 'base.woff'))
# base_font.saveXML(os.path.join(current_dir, 'base.xml'))
class MaoYanDecryptFont(object):
def __init__(self, web_font_url):
super(MaoYanDecryptFont, self).__init__()
self.unicode_to_glyph_dict = self.get_unicode_to_glyph_dict(web_font_url)
self.glyph_to_character_dict = self.get_glyph_to_character_dict()
pass
@staticmethod
def get_unicode_to_glyph_dict(web_font_url=None):
"""
得到 unicode 到 字形 的映射 字典
:param web_font_url:
web_font_url = 'http://vfile.meituan.net/colorstone/ef2688be76f0a8f2a810ee89adaab71f2084.woff'
:return:
"""
file_name = web_font_url.split('/')[-1].split('.')[0] + '.woff'
file_full_path = os.path.join(current_dir, file_name)
if not os.path.exists(file_full_path):
with open(file_full_path, 'wb') as f:
font_content = requests.get(web_font_url).content
f.write(font_content)
online_fonts = TTFont(file_full_path) # 加载字体文件
unicode_to_glyph_dict = dict()
temp = online_fonts.getGlyphSet()._glyphs.glyphs
for k, v in temp.items():
if 'uni' not in k:
continue
unicode_to_glyph_dict[k] = v.data
return unicode_to_glyph_dict
@staticmethod
def get_glyph_to_character_dict():
"""
得到 字形 到 字符 的映射 字典
:return: python 字典
"""
glyph_to_character_dict = dict()
unicode_to_byte_dict = base_font.getGlyphSet()._glyphs.glyphs
# font_glyph_unicode_set = base_font.getGlyphSet().keys()
for k, v in base_num_dict.items():
# font_dict[base_font.getGlyphSet().get(k)] = v
glyph_to_character_dict[unicode_to_byte_dict[k].data] = v
return glyph_to_character_dict
def get_encrypt_num(self, unicode_str=None):
glyph = self.unicode_to_glyph_dict[unicode_str]
character = self.glyph_to_character_dict[glyph]
return character
if __name__ == "__main__":
# 网页上加密的数字
#
unicode_1 = 'uni' + 'f764'.upper()
unicode_2 = 'uni' + 'ed9d'.upper()
print(unicode_1, unicode_2)
web_font_url = 'http://vfile.meituan.net/colorstone/44d84ad862bdc7074d0909ee5bf108512088.woff'
mdf = MaoYanDecryptFont(web_font_url)
print(mdf.get_encrypt_num(unicode_1))
print(mdf.get_encrypt_num(unicode_2))
pass
运行结果:
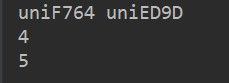
打印 4 和 5 ,刚好和网页上显示 票价 对应
破解猫眼加密数字
一、背景
字体反爬应用还是很普遍。这两天有朋友咨询如何实现猫眼票房数据的爬取,这里其实与上面的文章核心思想是一致的,但是操作更复杂一些,本文做一个更详细的破解实践。
有对字体反爬还比较陌生的,请参考前文。
二、查找字体源
猫眼电影是美团旗下的一家集媒体内容、在线购票、用户互动社交、电影衍生品销售等服务的一站式电影互联网平台。2015年6月,猫眼电影覆盖影院超过4000家,这些影院的票房贡献占比超过90%。目前,猫眼占网络购票70%的市场份额,每三张电影票就有一张出自猫眼电影,是影迷下载量较多、使用率较高的电影应用软件。同时,猫眼电影为合作影院和电影制片发行方提供覆盖海量电影消费者的精准营销方案,助力影片票房。
我们使用Chrome浏览页面,并查看源码,发现售票中涉及数字的,在页面显示正常,在源码中显示一段span包裹的不可见文本。
上面其实就是自定义字体搞的鬼。根据网页源码中,
.
使用了自定义的stonefont字体,我们在网页中查找stonefont,很快有了发现,这就是标准的@font-face定义方法。且每次访问,字体文件访问地址都会随机变化。

我们访问其中woff文件的地址,可将woff字体文件下载到本地。前文中fonttools并不能直接解析woff字体,我们需要将woff字体转换成otf字体。百度可以直接转换字体 ,地址:http://fontstore.baidu.com/static/editor/index.html
字体转换 woff :http://www.sfont.cn/tools/font
把下载好的字体通过地址( http://www.sfont.cn/tools/font )转换成 otf 字体,在线转换完成后,下载 转换完成的字体
把转换完成的字体上传到( http://fontstore.baidu.com/static/editor/index.html ) 即可看到结果
三、字体解析
otf 就是常用的字体文件,可以使用系统自带的字体查看器查看,但是难以看到更多有效的信息,可以使用一个专用工具Font Creator查看。(Font Creator 汉化破解版下载地址:http://www.downcc.com/soft/242914.html)

可以看到,这个字体里有12个字(含一个空白字),每个字显示其字形和其字形编码。这里比之前字体解析更复杂的是,这里不仅字体编码每次都会变,字体顺序每次也会变,很难直接通过编码和顺序获取实际的数字。因此,我们需要预先下载一个字体文件,人工识别其对应数值和字体,然后针对每次获取的新的字体文件,通过比对字体字形数据,得到其真实的数字值。
下面是使用fontTools.ttLib获取的单个字符的字形数据。
使用下面语句可以获取顺序的字符编码值,
# 解析字体库font文件
# 用一个base文件提前解析出文件的编码规律
##############################################################################
# 访问字体的 url ,下载 字体文件 并 保存,这里保存文件名为 base.woff
base_font = TTFont('base.woff') # 解析字体库font文件
# 使用 "FontCreator字体查看软件" 查看字体的对应关系,然后设置对应关系
base_num_list = ['.', '3', '5', '1', '2', '7', '0', '6', '9', '8', '4']
base_unicode_list = [
'x', 'uniE64B', 'uniE183', 'uniED06', 'uniE1AC', 'uniEA2D',
'uniEBF8', 'uniE831', 'uniF654', 'uniF25B', 'uniE3EB'
]
"""
1. 字库对应的字形顺序不变,映射的 unicode 编码改变。
只需要找一次对应关系即可。
2. 字库对应的字形顺序改变,映射的 unicode 编码也改变。
需要找两次对应关系:
第一次可以当基准对应关系,找到 字形 和 unicode 的对应关系
第二次时,因为字形的数据都相同,可以找到字形的数据和第一次做基准的做对比,
因为字形数据相同,可以找到第一次对应的字形所对应的第二次的 unicode 对应关系
"""
##############################################################################
# 猫眼 属于 字形 顺序改变,unicode 编码也改变
mao_yan_font = TTFont('maoyan.woff')
mao_yan_unicode_list = mao_yan_font['cmap'].tables[0].ttFont.getGlyphOrder()
mao_yan_num_list = []
for i in range(1, 12):
mao_yan_glyph = mao_yan_font['glyf'][mao_yan_unicode_list[i]]
for j in range(11):
base_glyph = base_font['glyf'][base_unicode_list[j]]
if mao_yan_glyph == base_glyph:
mao_yan_num_list.append(base_num_list[j])
break
pass
四、内容替换
关键点攻破了,整个工作就好做了。先访问需要爬取的页面,获取字体文件的动态访问地址并下载字体,读取用户帖子文本内容,替换其中的自定义字体编码为实际文本编码,就可复原网页为页面所见内容了。
完整代码如下:
# -*- coding:utf-8 -*-
import requests
from lxml import html
import re
import woff2otf
from fontTools.ttLib import TTFont
from bs4 import BeautifulSoup as bs
#抓取maoyan票房
class MaoyanSpider:
#页面初始化
def __init__(self):
self.headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.8",
"Cache-Control": "max-age=0",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1",
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.86 Safari/537.36"
}
# 获取票房
def getNote(self):
url = "http://maoyan.com/cinema/15887?poi=91871213"
host = {'host':'maoyan.com',
'refer':'http://maoyan.com/news',}
headers = dict(self.headers.items() + host.items())
# 获取页面内容
r = requests.get(url, headers=headers)
#print r.text
response = html.fromstring(r.text)
u = r.text
# 匹配ttf font
cmp = re.compile(",\n url\('(//.*.woff)'\) format\('woff'\)")
rst = cmp.findall(r.text)
ttf = requests.get("http:" + rst[0], stream=True)
with open("maoyan.woff", "wb") as pdf:
for chunk in ttf.iter_content(chunk_size=1024):
if chunk:
pdf.write(chunk)
# 转换woff字体为otf字体
woff2otf.convert('maoyan.woff', 'maoyan.otf')
# 解析字体库font文件
baseFont = TTFont('base.otf')
maoyanFont = TTFont('maoyan.otf')
uniList = maoyanFont['cmap'].tables[0].ttFont.getGlyphOrder()
numList = []
baseNumList = ['.', '3', '5', '1', '2', '7', '0', '6', '9', '8', '4']
baseUniCode = ['x', 'uniE64B', 'uniE183', 'uniED06', 'uniE1AC', 'uniEA2D', 'uniEBF8',
'uniE831', 'uniF654', 'uniF25B', 'uniE3EB']
for i in range(1, 12):
maoyanGlyph = maoyanFont['glyf'][uniList[i]]
for j in range(11):
baseGlyph = baseFont['glyf'][baseUniCode[j]]
if maoyanGlyph == baseGlyph:
numList.append(baseNumList[j])
break
uniList[1] = 'uni0078'
utf8List = [eval("u'\u" + uni[3:] + "'").encode("utf-8") for uni in uniList[1:]]
# 获取发帖内容
soup = bs(u,"html.parser")
index=soup.find_all('div', {'class': 'show-list'})
print '---------------Prices-----------------'
for n in range(len(index)):
mn=soup.find_all('h3', {'class': 'movie-name'})
ting=soup.find_all('span', {'class': 'hall'})
mt=soup.find_all('span', {'class': 'begin-time'})
mw=soup.find_all('span', {'class': 'stonefont'})
for i in range(len(mt)):
moviename=mn[i].get_text()
film_ting = ting[i].get_text()
movietime=mt[i].get_text()
moviewish=mw[i].get_text().encode('utf-8')
for i in range(len(utf8List)):
moviewish = moviewish.replace(utf8List[i], numList[i])
print moviename,film_ting,movietime,moviewish
spider = MaoyanSpider()
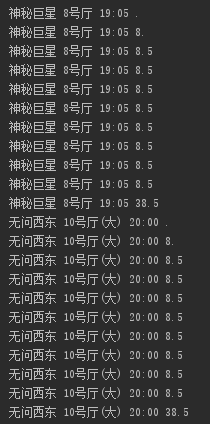
spider.getNote()解析访问,获取数据(最后一列是加密破解后的数据)。
反击“猫眼电影”网站的反爬虫策略
0×01 前言
前两天在百家号上看到一篇名为《反击爬虫,前端工程师的脑洞可以有多大?》的文章,文章从多方面结合实际情况列举了包括猫眼电影、美团、去哪儿等大型电商网站的反爬虫机制。的确,如文章所说,对于一张网页,我们往往希望它是结构良好,内容清晰的,这样搜索引擎才能准确地认知它;而反过来,又有一些情景,我们不希望内容能被轻易获取,比方说电商网站的交易额,高等学校网站的题目等。因为这些内容,往往是一个产品的生命线,必须做到有效地保护。这就是爬虫与反爬虫这一话题的由来。本文就以做的较好的“猫眼电影”网站为例,搞定他的反爬虫机制,轻松爬去我们想要的数据!
0×02 常见反爬虫
从功能上来讲,爬虫一般分为数据采集,处理,储存三个部分。而作为程序员的我们只关心数据采集部分,处理什么的还是交给那些数据分析师去搞吧。
一般来说,大多数网站会从三个方面反爬虫:用户请求的Headers,用户行为,网站目录和数据加载方式。前两种比较容易遇到,大多数网站都从这些角度来反爬虫,而第三种则相对比较特殊,一些应用ajax的网站会采用,这样无疑会增大了爬虫爬取的难度。
然而,这三种反爬虫策略则早已有应对的方法和策略。如果遇到了从用户请求的Headers反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值修改为目标网站域名。对于检测Headers的反爬虫,在爬虫中修改或者添加Headers就能很好的绕过。对于基于用户行为的反爬虫其实就是通过限制同一IP短时间内多次访问同一页面,应对策略也是很粗暴——使用IP代理,可以专门写一个爬虫,爬取网上公开的代理ip,检测后全部保存起来。有了大量代理ip后可以每请求几次更换一个ip,即可绕过这种反爬虫机制。对于最后一种动态页面反爬虫机制来讲, selenium+phantomJS框架能够让你在无界面的浏览器中模拟加载网页的动态请求,毕竟 selenium 可是自动化渗透的神器。
0×03 猫眼反爬虫介绍
介绍完常见的反爬虫机制,我们回过头看看我们今天的主角
先来个简单点的:天眼查
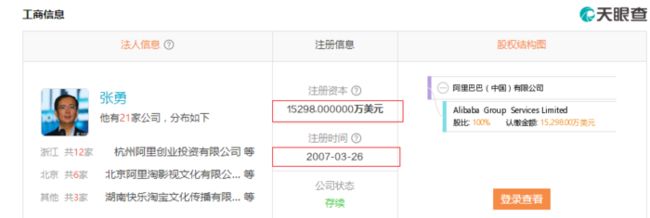
1. 打开天眼查
找到阿里巴巴的页面 https://www.tianyancha.com/company/59837300,可以看到勇哥帅气的照片。。。
(注意:直接打开需要登陆的话通过百度搜索 “天眼查 阿里” 再点击访问,如果是用python请求,headers 带上 "Referer": "https://www.baidu.com/",伪装成百度跳转过来的)
2. 查看源代码
查看源代码后发现,注册资本和注册时间是无法直接在源代码中获取正确的值。
3. 搜索 类 样式
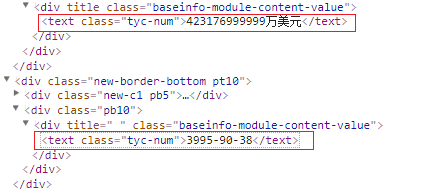
这时需要思考原因,应该是 js 修改过或者替换过 字体文件,发现两个值的类都是 ”tyc-num“ ,可以尝试查看一下 类 的样式。
经过搜索,找到样式如下:
@font-face {
font-family: "tyc-num";
src: url("https://static.tianyancha.com/web-require-js/public/fonts/tyc-num-ad584829a0.eot");
/* IE9*/
src: url("https://static.tianyancha.com/web-require-js/public/fonts/tyc-num-ad584829a0.eot#iefix") format("embedded-opentype"), url("https://static.tianyancha.com/web-require-js/public/fonts/tyc-num-832854095c.woff") format("woff"), url("https://static.tianyancha.com/web-require-js/public/fonts/tyc-num-7f971a8be7.ttf") format("truetype"), url("https://static.tianyancha.com/web-require-js/public/fonts/tyc-num-67f91eabd9.svg#tic") format("svg");
/* iOS 4.1- */
}
.tyc-num {
font-family: "tyc-num" !important;
font-style: normal;
-webkit-font-smoothing: antialiased;
-moz-osx-font-smoothing: grayscale;
}可以看出,这是用 css 更改了加载的字体文件,自定义了字体。
4. 使用开发者工具
在开发者工具中找到这个这个文件,看一下做了什么改变。

字体文件
显然是数字这个地方做了手脚,对比一下正常的字体。

正常的字体
好像比正常的还少了一个 "4",多了一个 "." ,猜想 "4" 对应的就是 "." ,所以这样可以得出数字的对应关系。

对应关系
- 把网页中的数据进行对应一下,果然没错。
423176999999万美元 ---> 15298.000000万美元
3995-90-38 ---> 2007-03-26
- 之后在提取数据时做一个逻辑判断替换即可得到真实数据了。
猫眼电影
1. 打开网页
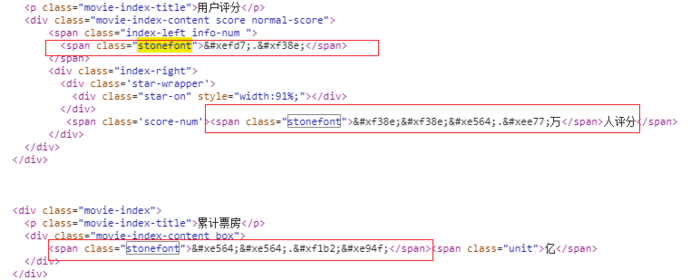
打开猫眼电影详情页 http://maoyan.com/films/1198214,查看用户评分和累计票房,发现源码中是乱码。
猫眼电影的反爬虫是什么样的。

对于每日的电影院票价这一重要数据,源代码中展示的并不是纯粹的数字。而是在页面使用了font-face定义了字符集,并通过unicode去映射展示。简单介绍下这种新型的web-fongt反爬虫机制:使用web-font可以从网络加载字体,因此我们可以自己创建一套字体,设置自定义的字符映射关系表。例如设置0xefab是映射字符1,0xeba2是映射字符2,以此类推。当需要显示字符1时,网页的源码只会是0xefab,被采集的也只会是 0xefab,并不是1:

因此采集者采集不到正确的票价数据:

采集者只能获取到类似的数据,并不能知道””映射的字符是什么,实现了数据防采集。而对于正常访问的用户则没有影响,因为浏览器会加载css中的font字体为我们渲染好,实时显示在网页中。也就是说,除去图像识别,必须同时爬取字符集,才能识别出数字。
查看猫眼的网站源文件正是如此:

2. 提取字体
提取加密的字体
所有的票价信息都是由动态font字体“加密”后得到的。既然知道了原理,我们就继续发掘,通过分析网站HTML结构,我们发现网站每次渲染票价的font字体都可以在网页的script标签中被找到:

字体是由base64加密后存储在网页中的,于是乎,上python:
# 将base64 加密的 font 文件解密转存本地
import requests
import base64
import re
from fontTools.ttLib import TTFont
custom_headers = {
'Host': 'piaofang.maoyan.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:61.0) '
'Gecko/20100101 Firefox/61.0',
'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate',
'Referer': 'https://piaofang.maoyan.com/?ver=normal',
'Connection': 'keep-alive'
}
url = 'https://piaofang.maoyan.com/?ver=normal '
r = requests.get(url, headers=custom_headers)
font = re.findall(r"src:\(data:application/font-woff;charset=utf-8;base64,(.*?)\) format", r.text)[0]
font_data = base64.b64decode(font)
file = open('/home/jason/workspace/1.ttf', 'wb')
file.write(font_data)
file.close()以上就是把 加密后的 字体 解密然后存储在本地为 文件名 是 1.ttf。我们在爬取时将font文件解密后存储在本地存储为ttf文件,留做备用。前文提到过这种web-font定义了字符集,要通过unicode去映射展示,所以,我们要构建ttf字体文件中unicode映射出来的字符字典:

python代码:
import fontforge
def tff2Unicode():#将字体映射为unicode列表
filename = '/home/jason/workspace/1.ttf'
fnt = fontforge.open(filename)
for i in fnt.glyphs():
print i.unicode
我们猜测映射关系如下:

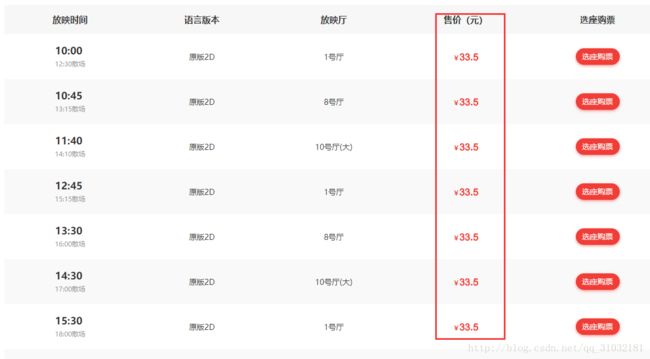
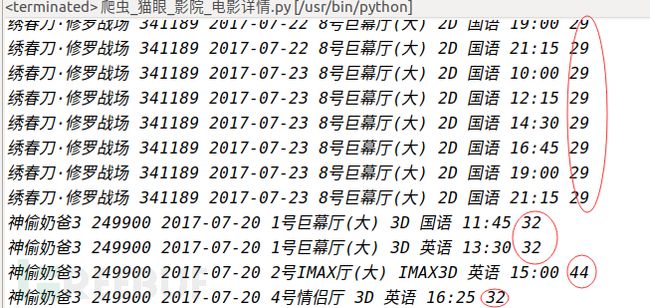
还记得嘛,第三张图我们爬取到的数据是“绣春刀·修罗战场 341189 2017-07-20 6号厅 2D 国语 11:10 ”,我们将“&#”替换成“0”后对应上表得出的票价不是刚好是“29”嘛!
python代码:
tmp_dic={}
ttf_list = []
def creatTmpDic(): # 创建映射字典
tmp_dic={}
ttf_list = []
num_list = [-1,-1,0,1,2,3,4,5,6,7,8,9]
filename = '/home/jason/workspace/1.ttf'
fnt = fontforge.open(filename)
ttf_list = []
for i in fnt.glyphs():
ttf_list.append(i.unicode)
tmp_dic = dict(zip(ttf_list,num_list)) # 构建字典
return tmp_dic,ttf_list
def tff2price(para = ";",tmp_dic={},ttf_list = []): # 将爬取的字符映射为字典中的数字
tmp_return = ""
for j in para.split(";"):
if j != "":
ss = j.replace("&#","0")
for g in ttf_list:
if (hex(g) == ss):
tmp_return+=str(tmp_dic[g])
return tmp_return
到此,我们已经可以说已经完成了对票价“加密”数据的破解啦~还是有点小小的成就感呢!但是,这里面还是有个很坑的地方:开发者已经想到采集者可以通过分析,知道每一个映射代表的意思,从而进行采集后转换处理,所以我们每次访问都是随机得到一种字体,而且开发者还定期更新一批字体文件和映射表用来加大采集的难度,所以我们在采集的过程中不得不每采集一个页面就更新一次本地的该网页的web-font字体,无疑会大大增加爬虫的爬取成本和爬取效率,所以从一定意义上确实实现了反爬虫。
提取没有加密的字体
如果没有加密,他们的 class 都是 长 这样子的。可以直接在 url 里面看到 字体的 url 地址,可以直接提取。
@font-face {
font-family: stonefont;
src: url('//vfile.meituan.net/colorstone/1881db7c788dfdf9d2d00a926734d0973168.eot');
src: url('//vfile.meituan.net/colorstone/1881db7c788dfdf9d2d00a926734d0973168.eot?#iefix') format('embedded-opentype'),
url('//vfile.meituan.net/colorstone/632958fd02509dc28d915375c3a835e02088.woff') format('woff');
}
.stonefont {
font-family: stonefont;
}
重点: 多刷新几次,看到每次 url 是变化的,确定是动态生成字体,不要紧,生成哪个下载哪个。
加载一个页面,把这个字体文件下载下来拿去分析,可能是在文件中数字的地方进行了替换。在网上正好有一片是防止爬虫采集的文章: 利用自定义web-font实现数据防采集,看过后恍然大悟,这不正是我们要的吗,嘿嘿,爬虫是防不住的!
用 python 的 fonttools 库提取字体,fonttools 的用法可以网上查找一下。
pip3 install fonttools # 安装
把提取的字体转换成人可以识别的 xml 格式
把 woff 的文件转换成我们熟悉的 xml 格式
from fontTools.ttLib import TTFont # 导包
font = TTFont('./632958fd02509dc28d915375c3a835e02088.woff') # 打开文件
font.saveXML('./6329.xml') # 转换成 xml 文件并保存
3. 查找字体对应关系
打开 xml 文件,红框内即为我们要的,略微不同,把 uni 改成 &#x ,后面再加一个分号 。

4. 在网页上验证对应关系是否正确
跟源代码中对应验证一下可以得出他们的对应关系如下。

5. 使用程序得到对应关系映射
用 fonttools 可以直接从文件得到这些值
from fontTools.ttLib import TTFont # 导包
font = TTFont('./632958fd02509dc28d915375c3a835e02088.woff') # 打开文件
gly_list = font.getGlyphOrder() # 获取 GlyphOrder 字段的值
for gly in gly_list[2:]: # 前两个值不是我们要的,切片去掉
print(gly) # 打印
最后补充完整代码
思路:
前面知道字体库是随机的,可以提前把一些能刷新到的字体库下载到本地。
抓取页面时,如果已经在本地,直接使用,不在的话再下载下来。
本地目录:字体存在 fonts 目录下

完整代码
import requests
import re
import os
from fontTools.ttLib import TTFont
class MaoYan(object):
def __init__(self):
self.url = 'http://maoyan.com/films/1198214'
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36"
}
# 发送请求获得响应
def get_html(self, url):
response = requests.get(url, headers=self.headers)
return response.content
# 创建 self.font 属性
def create_font(self, font_file):
# 列出已下载文件
file_list = os.listdir('./fonts')
# 判断是否已下载
if font_file not in file_list:
# 未下载则下载新库
print('不在字体库中, 下载:', font_file)
url = 'http://vfile.meituan.net/colorstone/' + font_file
new_file = self.get_html(url)
with open('./fonts/' + font_file, 'wb') as f:
f.write(new_file)
# 打开字体文件,创建 self.font属性
self.font = TTFont('./fonts/' + font_file)
# 把获取到的数据用字体对应起来,得到真实数据
def modify_data(self, data):
# 获取 GlyphOrder 节点
gly_list = self.font.getGlyphOrder()
# 前两个不是需要的值,截掉
gly_list = gly_list[2:]
# 枚举, number是下标,正好对应真实的数字,gly是乱码
for number, gly in enumerate(gly_list):
# 把 gly 改成网页中的格式
gly = gly.replace('uni', '&#x').lower() + ';'
# 如果 gly 在字符串中,用对应数字替换
if gly in data:
data = data.replace(gly, str(number))
# 返回替换后的字符串
return data
def start_crawl(self):
html = self.get_html(self.url).decode('utf-8')
# 正则匹配字体文件
font_file = re.findall(r'vfile\.meituan\.net\/colorstone\/(\w+\.woff)', html)[0]
self.create_font(font_file)
# 正则匹配星级
star = re.findall(r'\s+(.*?)\s+', html)[0]
star = self.modify_data(star)
# 正则匹配评论的人数
people = ''.join(re.findall(r'''(.*?万)(人评分)''', html)[0])
people = self.modify_data(people)
# 正则匹配累计票房
ticket_number = ''.join(re.findall(r'''(.*?)(亿)''', html)[0])
ticket_number = self.modify_data(ticket_number)
print('用户评分: %s 星' % star)
print('评分人数: %s' % people)
print('累计票房: %s' % ticket_number)
if __name__ == '__main__':
maoyan = MaoYan()
maoyan.start_crawl()
作者:谦面客
链接:https://www.jianshu.com/p/79c4272c0969
來源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。效果图
网页浏览效果
