从网络IO看高性能框架
- 讨论一个高性能框架甚至语言的时候,我们在讨论什么?
- 三大网络模型阻塞IO+多进程阻塞IO+多线程非阻塞IO+IO多路复用
- 五种网络IO简介
- 网络IO的本质
- 如何区分阻塞IO和非阻塞IO
- 如何区分同步和异步
- 个人整理的网络IO思维导图
1.讨论一个高性能框架甚至语言的时候,我们在讨论什么
我相信大家肯定听过什么阻塞/非阻塞IO,同步/异步调用,我也尝试过死记概念,结果大家应该都有体会,过一阵子就忘记了。知其然而不知其所以然~然并卵。
大家在选择一门语言或者一个框架的时候肯定优先看它的性能,也就是并发量,例如常用的测试手段,就是用该语言或者框架写个http server服务器,对于http请求返回一个“hello,world!”,利用wrk进行压测,看看每分钟请求量最高能到多少,在4核8G的Ubuntu服务器上跑该http服务,利用wrk压测,gin框架每分钟能处理的请求量接近300W!这是相当优秀的!
前一阵子在go meet up深圳讨论语言性能的时候,有位老哥说同等业务与机器,PHP每秒请求量大概在300多,处理三万并发量的服务程序, go需要一台服务器,而PHP需要一百台。我当时非常震惊,为什么语言之间的差别这么大,是什么原因造成这个巨大的差别呢?我问Boss Lee(meet up讲师,一位技术大佬),他跟我说因为PHP是一个请求开一个进程处理,注意是进程而不是线程!
那为什么用进程处理请求会造成性能差别这么大,甚至到了一百台服务器的差别呢?(一百台服务器一年得上百万吧~)
经过我查阅资料,得出了是 网络IO模型造成了性能根本上的差别 这一结论!
这里直接说结论:PHP是阻塞IO+多进程模型,大名鼎鼎的Netty(JAVA)框架是主从reactor+worker threads 模式。
为什么?因为CPU切换进程或线程所带来的性能损耗是巨大的,主从reactor模式解决了IO分发的高效率问题!
这里先记住结论,后文看解析
2.三大网络模型
2.1阻塞IO+多进程
服务器初始监听在lisnted_fd到接字上,此时一个客户端发起连接请求,连接成功后产生连接套接字,此时父进程fork出一个子进程,子进程拿到连接套接字,并以此与客户端通信。在这种网络模型下,父进程关心的是监听套接字,子进程关心的是连接套接字。
连接分配第一个客户端.png
连接分配第二个客户端.png
这种网络模型编程简单,但是效率不高。
2.2阻塞IO+多线程
进程切换上下文代价是相当高的,有一种类似进程,但是切换开销比进程小的东西,那就是线程。
为什么说线程切换比进程切换开销要小呢?
因为线程由操作系统内核管理,在同一个进程中,所有的线程共享该进程的整个虚拟地址空间,包括代码、数据、堆、共享库等。
我们的代码被CPU执行需要一些数据支撑的,这就是所谓的上下文,包括但不限于程序计数器需要告诉CPU代码执行到哪里了,寄存器中存放了一些计算中间值,内从中存放了当前一些变量等。 从一个计算场景切换到另一个计算场景,这些值都需要重新载入,这就是上下文切换。
2.2非阻塞IO+IO多路复用
使用poll和epoll可以设计出基于套接字满足高性能,高并发的事件驱动程序。
事件驱动模型,叫做 reactor模型,或者Even loop模型。 是不是很熟悉?这个模型的核心有两点:
- 存在一个无限循环的事件分发线程,叫reactor线程,或者Even loop线程。这个分发线程背后的技术就是poll与epoll这类的IO多路复用技术。
- 所有的IO操作都可抽象为事件,每个事件必须有回调函数来处理。acceptor上有连接建立,已连接套接字的发送缓冲区可以写,通信管道pipe上有数据可以读,这些事件通过事件分发,都能被检测并调用回调函数处理。
- 单reactor模型 + worker threads该模型是将acceptor上连接建立事件,和已连接套接字的IO事件的分发由一个reactor线程去执行,由工作线程去处理耗时操作,例如数据库读取,文件解析,计算等等。单reactor模型 + worker threads.png
- 主从reactor模型 + worker threads当所有acceptor的连接建立事件和已连接套接字的IO事件交由一个reactor线程处理,在并发量较高的情况下,这个reactor线程会 忙不过来 ,表现在客户端连接建立成功率偏低。
那么主从模式的核心思想就在于,主reactor上只监听acceptor上成功建立的连接事件,并将其分发给从reactor线程,从reactor线程只需要负责已连接套接字上的IO事件。
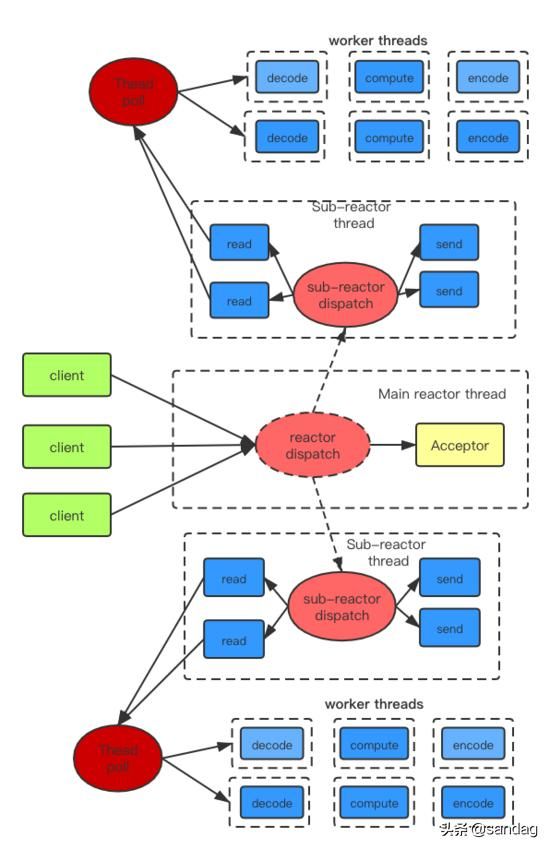
主从reactor模型 + worker threads.png
总结:我们通过主reactor线程来分发成功建立的套接字,通过从reactor线程来分发已连接套接字上的IO事件,通过工作线程来处理耗时操作! 更进一步---通过用户态自己建立的协程机制来调度业务处理程序,用户态自己管理协程间切换,避免了CPU切换线程,又能为程序带来更高的处理效率!
3. 五种网络IO简介
- 阻塞IO
- 非阻塞IO
- IO多路复用
- 异步IO
- 信号驱动IO
阻塞IO:
当应用程序调用阻塞IO完成某个操作时,应用程序会被挂起,感觉上应用程序像是被“阻塞”了一样。实际上,内核所做的事情是将CPU时间切换给了其他有需要的进程,网络应用程序在这种情况下就会得不到CPU时间做该做的事情。
非阻塞IO:
当应用程序调用非阻塞IO完成某个操作时,内核立即返回,不会把CPU时间让出给其他进程,应用程序在返回后可以得到足够的CPU时间做其他的事情。
IO多路复用:
我们可以把标准输入、套接字都看作IO的一路,多路复用的意思,就是在任何一路IO有“事件”发生的情况下,通过应用程序去处理相应的IO事件,这样我们的程序就“好像”在同一时刻处理多个IO事件。
异步IO:
当一个异步过程调用发出后,调用者不能立刻得到结果。实际处理这个调用的部件在完成后,通过状态、通知和回调来通知调用者。
信号驱动IO:
应用进程使用 sigaction 系统调用,内核立即返回,应用进程可以继续执行。当数据报准备好读取时,内核就为该进程产生一个SIGIO信号,我们随后可以在信号处理函数中读取数据报,也可以立即通知主循环,让他读取数据。
4.网络IO的本质
网络IO的本质就是socket流的读取,通常一次IO读操作会涉及到两个对象和两个阶段。
两个对象:
- 用户进程(线程)
- 内核对象
两个阶段:
- 等待数据流准备
- 从内核向进程复制数据
对于socket流而言:
- 第一步通常涉及等待网络上的数据分组到达,然后被复制到内核的某个缓冲区。
- 第二步把数据从内核缓冲区复制到进程缓冲区。
5. 如何区分阻塞IO和非阻塞IO
阻塞IO发起的read请求,线程会被挂起,一直等到内核数据准备好,并把数据从内核区域拷贝到应用程序的缓冲区中,拷贝完成后,read请求调用才返回。

阻塞IO.png
非阻塞IO的read请求在数据为准备的情况下立即返回,应用程序可以不断查询内核,直到数据准备好,内核将数据拷贝到应用程序缓冲区并完成这次read调用。

非阻塞IO.png
6. 如何区分同步和异步
同步调用与 异步调用 是对于获取数据的过程而言的,前面的几种最后获取数据的read操作调用,都是同步的,即在read调用时,内核将数据从内核空间拷贝到应用程序空间,这个过程是在read函数中同步进行的。
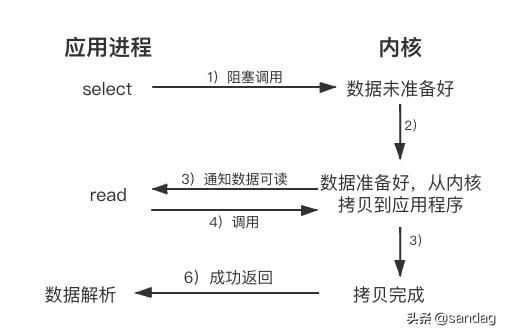
同步调用.png
当我们发起异步读(aio_read)之后,就立即返回,内核自动将数据从内核空间拷贝到应用程序空间,这个拷贝过程是异步的,内核自动完成的,和前面的同步操作不一样,应用程序并不需要主动发起拷贝动作。
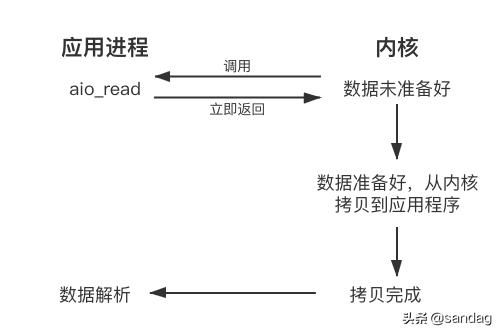
异步调用.png