吴恩达机器学习笔记整理(Week6-Week11)
1. Week 6
1.1 应用机器学习的建议(Advice for Applying Machine Learning)
1.1.1 决定下一步做什么
到目前为止,我们已经介绍了许多不同的学习算法,然而,在懂机器学习的人当中依然存在着很大的差距,一部分人确实掌握了怎样高效有力地运用这些学习算法。而另一些人可能没有完全理解怎样运用这些算法。因此总是把时间浪费在毫无意义的尝试上。本章是确保你在设计机器学习的系统时,你能够明白怎样选择一条最合适、最正确的道路。
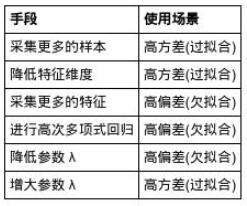
改进这个算法的性能常见的几种方法:
1. 获得更多的训练样本
2. 尝试减少特征的数量
3. 尝试获得更多的特征
4. 尝试增加多项式特征
5. 尝试减少正则化程度 λ \lambda λ
6. 尝试增加正则化程度 λ \lambda λ
注:
- 我们不应该随机选择上面的某种方法来改进我们的算法,而是运用一些机器学习诊断法来帮助我们知道上面哪些方法对我们的算法是有效的。
- 在接下来的两段视频中,我首先介绍怎样评估机器学习算法的性能,然后在之后的几段视频中,我将开始讨论这些方法,它们也被称为"机器学习诊断法"。
- “诊断法”的意思是:这是一种测试法,你通过执行这种测试,能够深入了解某种算法到底是否有用。这通常也能够告诉你,要想改进一种算法的效果,什么样的尝试,才是有意义的。
- 在这一系列的视频中我们将介绍具体的诊断法,但我要提前说明一点的是,这些诊断法的执行和实现,是需要花些时间的,有时候确实需要花很多时间来理解和实现,但这样做的确是把时间用在了刀刃上,因为这些方法让你在开发学习算法时,节省时间。
1.1.2 评估一个假设(评估假设函数)
在本节视频介绍评估假设函数。在之后的课程中,将以此为基础来讨论如何避免过拟合和欠拟合的问题。
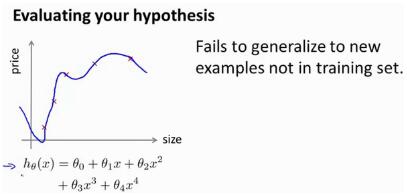
当我们确定学习算法的参数的时候,我们考虑的是选择参量来使训练误差最小化,但仅仅因为假设具有很小的训练误差,并不能说明一定是一个好的假设函数,例如:过拟合假设函数。
-
当特征变量较少时,可以对假设函数 h ( x ) h(x) h(x)进行画图,然后观察图形趋势。
-
当特征变量较多时,把样本均匀的分成测试集和训练集,来评估假设函数过拟合。
- 通常用70%的数据作为训练集,用剩下30%的数据作为测试集。很重要的一点是训练集和测试集均要含有各种类型的数据,通常我们要对数据进行“洗牌”,然后再分成训练集和测试集。
- 在训练集让我们的模型学习得出其参数后,对测试集运用该模型,计算误差:
- 线性回归模型,我们利用测试集数据计算代价函数 J J J
- 逻辑回归模型,我们除了可以利用测试数据集来计算代价函数外:
J t e s t ( θ ) = − 1 m t e s t ∑ i = 1 m t e s t y t e s t ( i ) log h θ ( x t e s t ( i ) ) + ( 1 − y t e s t ( i ) ) log ( 1 − h θ ( x t e s t ( i ) ) ) J_{test}{(\theta)} = -\frac{1}{m_{test}}\sum_{i=1}^{m_{test}}{y^{(i)}_{test}}\log{h_{\theta}(x^{(i)}_{test})}+(1-{y^{(i)}_{test}})\log{(1-h_{\theta}(x^{(i)}_{test})) } Jtest(θ)=−mtest1i=1∑mtestytest(i)loghθ(xtest(i))+(1−ytest(i))log(1−hθ(xtest(i)))
还可以计算误分类的比率,对于每一个测试集样本,计算:
err ( h θ ( x ) , y ) = { 1 if h ( x ) ≥ 0.5 and y = 0 , or if h ( x ) < 0.5 and y = 1 0 Otherwise \operatorname{err}\left(h_{\theta}(x), y\right)=\left\{\begin{array}{c} 1 &\text { if } h(x) \geq 0.5 \text { and } y=0, \text { or if } h(x)<0.5 \text { and } y=1 \\ 0 &\text { Otherwise } \end{array}\right. err(hθ(x),y)={10 if h(x)≥0.5 and y=0, or if h(x)<0.5 and y=1 Otherwise
然后对计算结果求平均。
1.1.3 模型选择和交叉验证集
本节目标:从多个模型中选择最好的模型。
假设我们要在10个不同次数的二项式模型之间进行选择:
1. h θ ( x ) = θ 0 + θ 1 x h_{\theta}(x)=\theta_{0}+\theta_{1} x hθ(x)=θ0+θ1x
2. h θ ( x ) = θ 0 + θ 1 x + θ 2 x 2 h_{\theta}(x)=\theta_{0}+\theta_{1} x+\theta_{2} x^{2} hθ(x)=θ0+θ1x+θ2x2
3. h θ ( x ) = θ 0 + θ 1 x + ⋯ + θ 3 x 3 h_{\theta}(x)=\theta_{0}+\theta_{1} x+\cdots+\theta_{3} x^{3} hθ(x)=θ0+θ1x+⋯+θ3x3
…
10. h θ ( x ) = θ 0 + θ 1 x + ⋯ + θ 10 x 10 h_{\theta}(x)=\theta_{0}+\theta_{1} x+\cdots+\theta_{10} x^{10} hθ(x)=θ0+θ1x+⋯+θ10x10
- 显然越高次数的多项式模型越能够适应我们的训练数据集,但是适应训练数据集并不代表着能推广至一般情况,不具有泛化能力。
- 我们应该选择一个更能有泛化能力的模型。我们需要使用交叉验证集来帮助选择模型。
即:使用60%的数据作为训练集,使用 20%的数据作为交叉验证集,使用20%的数据作为测试集。例如:

模型选择的方法为:
1. 使用训练集训练出 n n n个模型(Training error):
J t r a i n ( θ ) = 1 2 m t r a i n ∑ i = 1 m t r a i n ( h θ ( x t r a i n ( i ) ) − y t r a i n ( i ) ) 2 J_{train}(\theta) = \frac{1}{2m_{train}}\sum_{i=1}^{m_{train}}(h_{\theta}(x_{train}^{(i)})-y_{train}^{(i)})^2 Jtrain(θ)=2mtrain1i=1∑mtrain(hθ(xtrain(i))−ytrain(i))2
2. 用 n n n个模型分别对交叉验证集计算得出交叉验证误差(代价函数的值 Cross Validation error):
J c v ( θ ) = 1 2 m c v ∑ i = 1 m c v ( h θ ( x c v ( i ) ) − y c v ( i ) ) 2 J_{cv}(\theta) = \frac{1}{2m_{cv}}\sum_{i=1}^{m_{cv}}(h_{\theta}(x^{(i)}_{cv})-y^{(i)}_{cv})^2 Jcv(θ)=2mcv1i=1∑mcv(hθ(xcv(i))−ycv(i))2
3. 选取代价函数值(交叉验证误差)最小的模型;
4. 用步骤3中选出的模型对测试集计算得出推广误差(代价函数的值Test error):
J t e s t ( θ ) = 1 2 m t e s t ∑ i = 1 m t e s t ( h θ ( x t e s t ( i ) ) − y t e s t ( i ) ) 2 J_{test}(\theta)=\frac{1}{2m_{test}}\sum_{i=1}^{m_{test}}(h_{\theta}(x^{(i)}_{test})-y^{(i)}_{test})^2 Jtest(θ)=2mtest1i=1∑mtest(hθ(xtest(i))−ytest(i))2
1.1.4 诊断偏差和方差
-
对于拟合的表现,可以分为三类情况:
- 欠拟合(Underfitting)
无法很好的拟合训练集中的数据,预测值和实际值的误差很大,这类情况被称为欠拟合。拟合模型比较简单(特征选少了)时易出现这类情况。类似于,你上课不好好听,啥都不会,下课也差不多啥都不会。 - 优良的拟合(Just right)
不论是训练集数据还是不在训练集中的预测数据,都能给出较为正确的结果。类似于,学霸学神! - 过拟合(Overfitting)
能很好甚至完美拟合训练集中的数据,即 J ( θ ) → 0 J(\theta) \to 0 J(θ)→0,但是对于不在训练集中的新数据,预测值和实际值的误差会很大,泛化能力弱,这类情况被称为过拟合。拟合模型过于复杂(特征选多了)时易出现这类情况。类似于,你上课跟着老师做题都会都听懂了,下课遇到新题就懵了不会拓展。
- 欠拟合(Underfitting)
-
为了度量拟合表现,引入:
- 偏差(bias)
偏差指模型的预测值与真实值的偏离程度,反映了模型无法正确的描述数据规律。偏差越大,预测值偏离真实值越厉害。偏差低,意味着能较好地反应训练集中的数据情况。 - 方差(Variance)
方差指模型预测值的离散程度或者变化范围,反映了模型对训练数据过度敏感。方差越大,数据的分布越分散,函数波动越大,泛化能力越差。方差低,意味着拟合曲线的稳定性高,波动小。
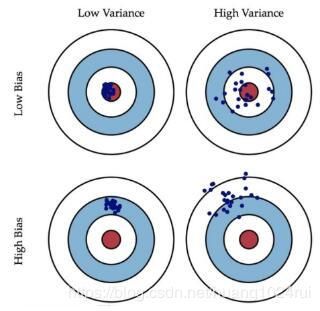
据上图,高偏差意味着欠拟合,高方差意味着过拟合。
- 偏差(bias)
-
如图所示,是多项式次数与验证误差和训练误差的关系图:
 Training error: J train ( θ ) = 1 2 m t r a i n ∑ i = 1 m t r a i n ( h θ ( x t r a i n ( i ) ) − y t r a i n ( i ) ) 2 Cross Validation error: J c v ( θ ) = 1 2 m c v ∑ i = 1 m c v ( h θ ( x c v ( i ) ) − y c v ( i ) ) 2 \begin{aligned} &\text { Training error: } J_{\text {train}}(\theta)=\frac{1}{2 m_{train}} \sum_{i=1}^{m_{train}}\left(h_{\theta}\left(x_{train}^{(i)}\right)-y_{train}^{(i)}\right)^{2}\\ &\text { Cross Validation error: } J_{c v}(\theta)=\frac{1}{2 m_{c v}} \sum_{i=1}^{m_{cv}}\left(h_{\theta}\left(x_{c v}^{(i)}\right)-y_{c v}^{(i)}\right)^{2} \end{aligned} Training error: Jtrain(θ)=2mtrain1i=1∑mtrain(hθ(xtrain(i))−ytrain(i))2 Cross Validation error: Jcv(θ)=2mcv1i=1∑mcv(hθ(xcv(i))−ycv(i))2
Training error: J train ( θ ) = 1 2 m t r a i n ∑ i = 1 m t r a i n ( h θ ( x t r a i n ( i ) ) − y t r a i n ( i ) ) 2 Cross Validation error: J c v ( θ ) = 1 2 m c v ∑ i = 1 m c v ( h θ ( x c v ( i ) ) − y c v ( i ) ) 2 \begin{aligned} &\text { Training error: } J_{\text {train}}(\theta)=\frac{1}{2 m_{train}} \sum_{i=1}^{m_{train}}\left(h_{\theta}\left(x_{train}^{(i)}\right)-y_{train}^{(i)}\right)^{2}\\ &\text { Cross Validation error: } J_{c v}(\theta)=\frac{1}{2 m_{c v}} \sum_{i=1}^{m_{cv}}\left(h_{\theta}\left(x_{c v}^{(i)}\right)-y_{c v}^{(i)}\right)^{2} \end{aligned} Training error: Jtrain(θ)=2mtrain1i=1∑mtrain(hθ(xtrain(i))−ytrain(i))2 Cross Validation error: Jcv(θ)=2mcv1i=1∑mcv(hθ(xcv(i))−ycv(i))2
可以看到:- 当多项式次数很小时,比如一条直线很难对数据进行拟合,因此偏差很大, J train ( θ ) J_{\text {train}}(\theta) Jtrain(θ)和 J c v ( θ ) J_{c v}(\theta) Jcv(θ)都很大,这时处于欠拟合状态。
- 当多项式次数很大合适的时候, J train ( θ ) J_{\text {train}}(\theta) Jtrain(θ)由于对训练数据拟合很好,因此会越来越小, J c v ( θ ) J_{c v}(\theta) Jcv(θ)由于模型过度敏感导致越来越大,方差很大,这时处于过拟合状态。
- 因此,选择 J c v ( θ ) J_{c v}(\theta) Jcv(θ)最低的那个点,才是最佳多项式次数。
-
交叉验证集误差较大,判断是方差还是偏差:
- 高偏差(欠拟合):
J train ( θ ) , J c v ( θ ) is high J c v ( θ ) ≈ J test ( θ ) \begin{array}{c}&{J_{\text {train}}(\theta), J_{c v}(\theta) \quad \text { is high }} \\ & {J_{c v}(\theta) \approx J_{\text {test}}(\theta)}\end{array} Jtrain(θ),Jcv(θ) is high Jcv(θ)≈Jtest(θ) - 高方差(过拟合):
J train ( θ ) is low J c v > > ( θ ) J t e s t ( θ ) \begin{array}{l}{J_{\operatorname{train}}(\theta) \text { is } \operatorname{low}} \\ {J_{c v}>>(\theta)J_{t e s t}(\theta)}\end{array} Jtrain(θ) is lowJcv>>(θ)Jtest(θ)
- 高偏差(欠拟合):
1.1.5 正则化项与偏差/方差
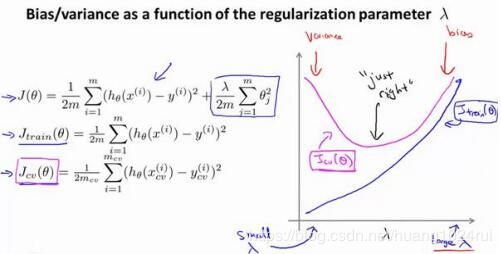
如下图所示,是正则项 λ \lambda λ的大小与 J train ( θ ) J_{\text {train}}(\theta) Jtrain(θ)和 J c v ( θ ) J_{c v}(\theta) Jcv(θ)的关系图。
-
λ \lambda λ与error的曲线图。可以看到这张图的趋势和多项式次数很像,就是正好反过来了。诚然,其描述也是类似的。
- 当 λ \lambda λ 很大的时候,就会使得后面的每一个 θ i \theta_i θi 都被惩罚了,所以只剩下 θ 0 \theta_0 θ0,那么其假设函数就会变成一条直线,出现欠拟合的现象。
- 当 λ \lambda λ很小的话,一个极端例子就是 λ = 0 \lambda=0 λ=0 ,也就是相当于没有加正则化那项,这就会导致过拟合的现象。
- 因此, λ \lambda λ的取值不能过大也不能过小,取在 J c v ( θ ) J_{c v}(\theta) Jcv(θ)最低的那个点。
-
一般正则化项选择的方法:
- λ \lambda λ在 [ 0 , 0.01 , 0.02 , 0.04 , 0.08 , 0.16 , 0.32 , 0.64 , 1.28 , 2.56 , 5.12 , 10.24 ] \color{red}{\left[0,0.01,0.02,0.04,0.08,0.16,0.32,0.64,1.28,2.56,5.12,10.24\right]} [0,0.01,0.02,0.04,0.08,0.16,0.32,0.64,1.28,2.56,5.12,10.24] 依次尝试,在12个不同的模型中针对每一个 λ \lambda λ 的值,都去计算出一个最小代价函数 J t r a i n ( Θ ( i ) ) J_{train}(\Theta^{(i)}) Jtrain(Θ(i)),从而得到 Θ ( i ) \Theta^{(i)} Θ(i)
- 得到了12个 Θ ( i ) \Theta^{(i)} Θ(i)以后,就再用交叉验证集去评价它们。即计算每个 Θ \Theta Θ 在交叉验证集上的平均误差平方和 J c v ( Θ ( i ) ) J_{cv}(\Theta^{(i)}) Jcv(Θ(i))
- 选择一个交叉验证集误差最小的 λ \lambda λ 最能拟合数据的作为正则化参数。
- 拿这个正则化参数去测试集里面验证 J t e s t ( Θ ( i ) ) J_{test}(\Theta^{(i)}) Jtest(Θ(i)) 预测效果如何。
-
我们应尽量使得拟合模型处于低方差(较好地拟合数据)状态且同时处于低偏差(较好地预测新值)的状态。最后我们回顾避免过拟合的方法有:
- 减少特征的数量
- 手动选取需保留的特征
- 使用模型选择算法来选取合适的特征(如 PCA 算法)
- 减少特征的方式易丢失有用的特征信息
- 正则化(Regularization)
- 可保留所有参数(许多有用的特征都能轻微影响结果)
- 减少/惩罚各参数大小(magnitude),以减轻各参数对模型的影响程度
- 当有很多参数对于模型只有轻微影响时,正则化方法的表现很好
- 减少特征的数量
1.1.6 学习曲线
学习曲线就是一种很好的工具,我经常使用学习曲线来判断某一个学习算法是否处于偏差、方差问题。学习曲线是学习算法的一个很好的合理检验(sanity check)。学习曲线是将训练集误差和交叉验证集误差作为训练集实例数量( m m m)的函数绘制的图表。
即,如果我们有 1 0 4 10^4 104行数据,我们从1行数据开始,逐渐学习更多行的数据。思想是:当训练较少行数据的时候,训练的模型将能够非常完美地适应较少的训练数据,但是训练出来的模型却不能很好地适应交叉验证集数据或测试集数据。
Learning Curves
Training error: J train ( θ ) = 1 2 m ∑ i = 1 m ( h θ ( x t r a i n ( i ) ) − y t r a i n ( i ) ) 2 Cross Validation error: J c v ( θ ) = 1 2 m c v ∑ i = 1 m ( h θ ( x c v ( i ) ) − y c v ( i ) ) 2 \begin{aligned} &\text { Training error: } J_{\text {train}}(\theta)=\frac{1}{2 m} \sum_{i=1}^{m}\left(h_{\theta}\left(x_{train}^{(i)}\right)-y_{train}^{(i)}\right)^{2}\\ &\text { Cross Validation error: } J_{c v}(\theta)=\frac{1}{2 m_{c v}} \sum_{i=1}^{m}\left(h_{\theta}\left(x_{c v}^{(i)}\right)-y_{c v}^{(i)}\right)^{2} \end{aligned} Training error: Jtrain(θ)=2m1i=1∑m(hθ(xtrain(i))−ytrain(i))2 Cross Validation error: Jcv(θ)=2mcv1i=1∑m(hθ(xcv(i))−ycv(i))2
-
优良的拟合

-
利用学习曲线识别高偏差/欠拟合:作为例子,我们尝试用一条直线来适应下面的数据,可以看出,无论训练集有多么大误差都不会有太大改观:

也就是说在高偏差/欠拟合的情况下,增加数据到训练集不一定能有帮助。 -
利用学习曲线识别高方差/过拟合:假设我们使用一个非常高次的多项式模型,并且正则化非常小,可以看出,当交叉验证集误差远大于训练集误差时,往训练集增加更多数据可以提高模型的效果。
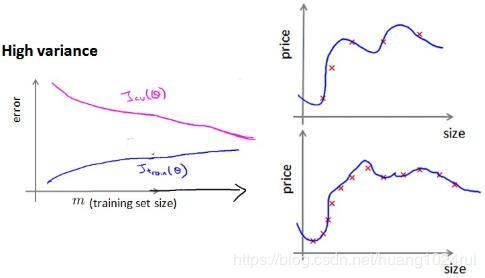
也就是说在高方差/过拟合的情况下,增加更多数据到训练集可能可以提高算法效果。
1.1.7 决定下一步做什么
-
对于不同优化手段,适用于不同的情况,如下图所示:
应用机器学习,千万不要一上来就试图做到完美,先撸一个baseline的model出来,再进行后续的分析步骤,一步步提高,所谓后续步骤可能包括『分析model现在的状态(欠/过拟合),分析我们使用的feature的作用大小,进行feature selection,以及我们模型下的bad case和产生的原因』等等。 -
神经网络的方差和偏差:
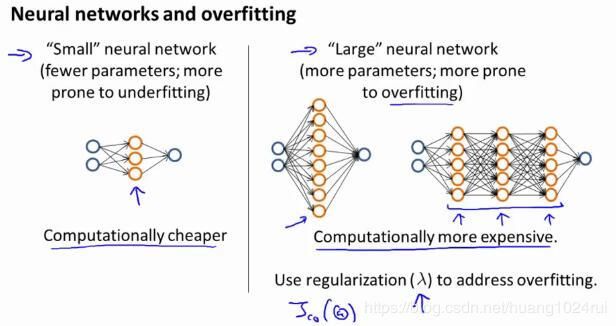
- 使用较小的神经网络,类似于参数较少的情况,容易导致高偏差和欠拟合,但计算代价较小使用较大的神经网络,类似于参数较多的情况,容易导致高方差和过拟合,虽然计算代价比较大,但是可以通过正则化手段来调整而更加适应数据。
- 通常选择较大的神经网络并采用正则化处理会比采用较小的神经网络效果要好。
- 对于神经网络中的隐藏层的层数的选择,通常从一层开始逐渐增加层数,为了更好地作选择,可以把数据分为训练集、交叉验证集和测试集,针对不同隐藏层层数的神经网络训练神经网络,然后选择交叉验证集代价最小的神经网络。
好的,以上就是我们介绍的偏差和方差问题,以及诊断该问题的学习曲线方法。在改进学习算法的表现时,你可以充分运用以上这些内容来判断哪些途径可能是有帮助的。
本 章 总 结 \color{red}{本章总结} 本章总结:
1.前三节:使用60%的数据作为训练集,使用 20%的数据作为交叉验证集,使用20%的数据作为测试集;
2. 1.1.4-1.1.5:调节 Θ \Theta Θ和 λ \lambda λ,选择好的模型;
3. 1.1.6:学习曲线选择好的模型;
4.总结如何调参数
1.2. 机器学习系统的设计(Machine Learning System Design)
1.2.1 首先要做什么
- 本章讨论机器学习系统的设计。本章会试着给出一些关于如何巧妙构建一个复杂的机器学习系统的建议。
- 本章课程的的数学性可能不是那么强,但是将要讲到的这些东西是非常有用的,可在构建大型的机器学习系统时,节省大量的时间。
本周以一个垃圾邮件分类器算法为例进行讨论。为了构建垃圾邮箱分类器算法,我们可以做很多事,例如:
1. 收集更多的数据,让我们有更多的垃圾邮件和非垃圾邮件的样本;
2. 基于邮件的路由信息开发一系列复杂的特征;
3. 基于邮件的正文信息开发一系列复杂的特征,包括考虑截词的处理;
4. 为探测刻意的拼写错误(把watch 写成w4tch)开发复杂的算法。在上面这些选项中,我们到底选择哪一个?在随后的课程中讲误差分析,会告诉你怎样用一个更加系统性的方法,从一堆不同的方法中,选取合适的那一个。
1.2.2 误差分析
误差分析(Error Analysis)会帮助你更系统地做出决定。如果你准备研究机器学习的东西,或者构造机器学习应用程序,最好的实践方法不是建立一个非常复杂的系统,拥有多么复杂的变量;而是构建一个简单的算法,逐步优化。
误差分析(Error Analysis)基本步骤:
- 用一个简单、快速实现的算法,实现该算法,采用交叉验证集数据测试这个算法;
- 绘制学习曲线,根据偏差和误差,利用上一章的知识,改变模型;
- 进行误差分析:人工检查交叉验证集,分析产生预测误差的样本,看看这些样本是否有某种系统化的趋势。
- 以我们的垃圾邮件过滤器为例,误差分析要做的既是检验交叉验证集中我们的算法产生错误预测的所有邮件,看看是否能将这些邮件按照类分组。例如:医药品垃圾邮件,仿冒品垃圾邮件或者密码窃取邮件等。然后看分类器对哪一组邮件的预测误差最大,并着手优化。
- 思考怎样能改进分类器。a) 例如:发现是否缺少某些特征,记下这些特征出现的次数。b) 例如:记录下错误拼写出现了多少次,异常的邮件路由情况出现了多少次等等,然后从出现次数最多的情况开始着手优化。
误差分析并不总能帮助我们判断应该采取怎样的行动。有时我们需要尝试不同的模型,然后进行比较,在模型比较时,用数值来判断哪一个模型更好更有效,通常我们是看交叉验证集的误差。
1.2.3 偏斜类的误差度量
在前面的课程中,我提到了误差分析,以及 设 定 误 差 度 量 值 的 重 要 性 \color{red}{设定误差度量值的重要性} 设定误差度量值的重要性。使用一个合适的误差度量值,这有时会对于你的学习算法造成非常微妙的影响,这件重要的事情就是偏斜类(skewed classes) 的问题。类偏斜情况表现为我们的训练集中有非常多的同一种类的实例,只有很少或没有其他类的实例。
例如我们希望用算法来预测癌症是否是恶性的,在我们的训练集中,只有0.5%的实例是恶性肿瘤。假设我们编写一个非学习而来的算法,在所有情况下都预测肿瘤是良性的,那么误差只有0.5%。然而我们通过训练而得到的却有1%的误差。这时,误差的大小是不能视为评判算法效果的依据的。
我们将算法预测的结果分成四种情况:
1. 正确肯定(True Positive,TP):预测为真,实际为真
2.正确否定(True Negative,TN):预测为假,实际为假
3.错误肯定(False Positive,FP):预测为真,实际为假
4.错误否定(False Negative,FN):预测为假,实际为真
如下图:
| 预测值 | 预测值 | ||
|---|---|---|---|
| Positive | Negtive | ||
| 实际值 | Positive | TP | FN |
| 实际值 | Negtive | FP | TN |
则:
准确率(Precision) = T P ( T P + F P ) \color{red}{\text{准确率(Precision)}=\frac{TP}{(TP+FP)}} 准确率(Precision)=(TP+FP)TP
例,在所有我们预测有恶性肿瘤的病人中,实际上有恶性肿瘤的病人的百分比,越高越好。
查全率(Recall) = T P ( T P + F N ) \color{red}{\text{查全率(Recall)}=\frac{TP}{(TP+FN)}} 查全率(Recall)=(TP+FN)TP
例,在所有实际上有恶性肿瘤的病人中,成功预测有恶性肿瘤的病人的百分比,越高越好。
A c c u r a c y = T P + T N T P + F N + F P + T N \color{red}{Accuracy = \frac{TP+TN} {TP+FN+FP+TN}} Accuracy=TP+FN+FP+TNTP+TN
1.2.4 准确率和查全率之间的权衡
我们还是肿瘤的例子,用逻辑回归,初始阈值是0.5:
- 如果希望只在非常确信的情况下预测为真(肿瘤为恶性),即希望更高的准确率,我们可以使用比0.5更大的阀值,如0.7,0.9。这样做我们会减少错误预测病人为恶性肿瘤的情况,同时却会增加未能成功预测肿瘤为恶性的情况。 高 准 确 率 伴 随 着 往 往 是 低 查 全 率 \color{red}{高准确率伴随着往往是低查全率} 高准确率伴随着往往是低查全率。
- 如果希望提高查全率,尽可能地让所有有可能是恶性肿瘤的病人都得到进一步地检查、诊断,我们可以使用比0.5更小的阀值,如0.3。 高 查 全 率 伴 随 着 往 往 是 低 准 确 率 \color{red}{高查全率伴随着往往是低准确率} 高查全率伴随着往往是低准确率。
我们可以将不同阀值情况下,查全率与查准率的关系绘制成图表,曲线的形状根据数据的不同而不同:
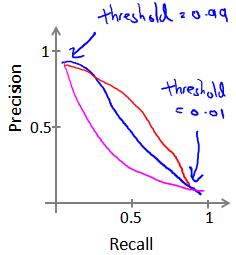
因此用 调 和 平 均 数 \color{red}{调和平均数} 调和平均数作为权衡查全率和准确率 的方法,选择更高的 F 1 S o r e F_1\;Sore F1Sore:
F 1 S c o r e = 2 ∗ P ∗ R P + R \color{red}F_1\; Score = 2*\frac{P*R}{P+R} F1Score=2∗P+RP∗R
1.2.5 机器学习的数据
我们总是怕训练集过拟合,那么我们怎样能避免过拟合呢?这里给了一个特定情境:
-
尽管我们希望拟合模型有很多参数,但是如果训练集比参数的数量还大,甚至是更多,那么这些算法就不太可能会过度拟合。也就是说训练误差有希望接近测试误差。
-
另一角度考虑:为了有一个高性能的学习算法,我们希望拟合模型不要有高的偏差和方差。
因此偏差问题,我么将通过确保有一个具有很多参数的学习算法来解决,以便我们能够得到一个较低偏差的算法,并且通过用非常大的训练集来保证。即:
- 当 模 型 是 低 偏 差 , 高 方 差 时 ; 增 加 训 练 数 据 集 的 大 小 , 能 提 高 算 法 的 准 确 率 。 \color{red}{当模型是低偏差,高方差时;增加训练数据集的大小,能提高算法的准确率。} 当模型是低偏差,高方差时;增加训练数据集的大小,能提高算法的准确率。
- 使用大量的训练数据优化模型的性能,其要点包括:
- 模型必须足够复杂,可以表示复杂函数,以至于数据大了之后,模型不会因为无法表示复杂函数而欠拟合。
- 数据的有效性,数据本身有一定规律可循。
本章总结:
- 误差分析(P、R、Accuracy);
- 数据增加的前提条件。
2.Week 7(支持向量机(Support Vector Machines))

2.1 优化目标(Optimization Objective)
-
逻 辑 回 归 \color{red}逻辑回归 逻辑回归
- 在逻辑回归中,我们的预测函数为:
h θ ( x ) = g ( z ) = 1 1 + e − θ T x h_\theta(x)= g(z)=\frac{1}{1+e^{-\theta^Tx}} hθ(x)=g(z)=1+e−θTx1
- 对于每一个样本 (x,y) 而言(注意是每一个),其代价函数为:
J ( θ ) = − ( y log h θ ( x ) + ( 1 − y ) log ( 1 − h θ ( ( x ) ) ) = − y log 1 1 + e − θ T X − ( 1 − y ) log ( 1 − 1 1 + e − θ T X ) \begin{aligned} J(\theta) &=-\left(y \log h_{\theta}(x)+(1-y) \log \left(1-h_{\theta}((x))\right)\right.\\ &=-y \log \frac{1}{1+e^{-\theta T_{X}}}-(1-y) \log \left(1-\frac{1}{1+e^{-\theta T_{X}}}\right) \end{aligned} J(θ)=−(yloghθ(x)+(1−y)log(1−hθ((x)))=−ylog1+e−θTX1−(1−y)log(1−1+e−θTX1) - 逻辑回归的作用:
- 如果样本中 y = 1 y=1 y=1,我们希望 h ( x ) ≈ 1 h(x)\approx1 h(x)≈1,那么 θ T x > > 0 \theta^Tx>>0 θTx>>0。
- 如果样本中 y = 0 y=0 y=0,我们希望 h ( x ) ≈ 0 h(x)\approx0 h(x)≈0,那么 θ T x < < 0 \theta^Tx<<0 θTx<<0。
- 在逻辑回归中,我们的预测函数为:
-
S V M \color{red}SVM SVM
为了描述支持向量机(support vector machine),我们先从逻辑回归开始,然后做一些小小的改动,来得到一个支持向量机。-
对于支持向量机而言:
y = 1 y=1 y=1 的时候: c o s t 1 ( θ T x ( i ) ) = ( − l o g h θ ( x ( i ) ) ) cost_1(\theta^Tx^{(i)})=(-logh_\theta(x^{(i)})) cost1(θTx(i))=(−loghθ(x(i)))
y = 0 y=0 y=0 的时候: c o s t 0 ( ( θ T x ( i ) ) = ( ( − l o g ( 1 − h θ ( x ( i ) ) ) ) cost_0((\theta^Tx^{(i)})=((-log(1-h_\theta(x^{(i)}))) cost0((θTx(i))=((−log(1−hθ(x(i))))
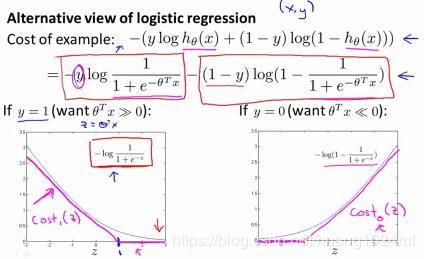
-
代价函数
支持向量机的代价函数为:
m i n θ C [ ∑ i = 1 m y ( i ) c o s t 1 ( θ T x ( i ) ) + ( 1 − y ( i ) ) c o s t 0 ( θ T x ( i ) ) ] + 1 2 ∑ j = 1 n θ j 2 min_{\theta} C[\sum_{i=1}^{m}{y^{(i)}}cost_1(\theta^Tx^{(i)})+(1- y^{(i)})cost_0(\theta^Tx^{(i)})]+\frac{1}{2}\sum_{j=1}^{n}{\theta_j^2} minθC[i=1∑my(i)cost1(θTx(i))+(1−y(i))cost0(θTx(i))]+21j=1∑nθj2
对于逻辑回归而言,其代价函数是有两项决定的,第一项是来自训练样本的代价函数,第二项是则化项,这就相当于我们用最小化 A 加上正则化参数 λ \lambda λ 乘以参数平方项 B,其形式大概是: A + λ B A+\lambda B A+λB 。这里我们是通过设置不同的正则参数 λ \lambda λ 来达到优化的目的。
但是在支持量机这里,把参数提到前面,用参数 C 作为 A 的参数,以 A 作为权重。所以其形式是这样的: C A + B CA+B CA+B 。- 在逻辑回归中,我们通过正规化参数 λ \lambda λ 调节 A、B 所占的权重,且 A 的权重与 λ \lambda λ 取值成反比。而在 SVM 中,则通过参数 C 调节 A、B 所占的权重,且 A 的权重与 C 的取值成反比。亦即,参数 C 可以被认为是扮演了 1 λ \frac{1}{\lambda} λ1 的角色。
- 所以 1 m \frac{1}{ m} m1 这一项仅仅是相当于一个常量,对于最小化参数 θ \theta θ 是完全没有任何影响的,所以这里我们将其去掉。
-
有别于逻辑回归假设函数输出的是概率,支持向量机它是直接预测 y 的值是0还是1。也就是说其假设函数是这样子的:
h θ ( x ) = { 1 , i f θ T x ⩾ 0 0 , o t h e r w i s e h_{\theta}(x)=\left\{\begin{matrix} 1,\;\;if\; \theta^{T}x\geqslant 0\\ 0,\;\;otherwise \end{matrix}\right. hθ(x)={1,ifθTx⩾00,otherwise
-
2.2 Large Margin Intuition 大边界的直观理解
支持向量机是最后一个监督学习算法,与前面我们所学的逻辑回归和神经网络相比,支持向量机在学习复杂的非线性方程时,提供了一种更为清晰、更加强大的方式。
-
支持向量机也叫做大间距分类器(large margin classifiers)。

- 当 y = 1 y=1 y=1时,那么仅当 z ≥ 1 z\geq1 z≥1时,有 c o s t 1 ( z ) = 0 cost_1(z)=0 cost1(z)=0。
- 当 y = 0 y=0 y=0时,那么仅当 z ≤ − 1 z\leq-1 z≤−1时,有 c o s t 1 ( z ) = 0 cost_1(z)=0 cost1(z)=0。
相比于逻辑回归,支持向量机的要求更高,不仅仅要能正确分开输入的样本,即不仅仅要求 θ T x > 0 \theta^Tx>0 θTx>0,我们需要的是比0值大很多,比如大于等于1,我也想这个比0小很多,比如我希望它小于等于-1,这就相当于在支持向量机中嵌入了一个额外的安全因子,或者说安全的间距因子。
-
支持向量机的决策边界
如果在上图支持向量机的损失函数中,我们将C的值设置的非常大,那么最小化优化目标的时候,我们将迫切希望找到一个值,能让第一项等于0。- 无论何时 y ( i ) = 1 y^{(i)}=1 y(i)=1: θ T x ( i ) ≥ 1 \theta^Tx^{(i)}\geq1 θTx(i)≥1。
- 无论何时 y ( i ) = 0 y^{(i)}=0 y(i)=0: θ T x ( i ) ≤ − 1 \theta^Tx^{(i)}\leq-1 θTx(i)≤−1。
现在我们要把优化问题看作是通过参数选择来使第一项等于0,那么优化问题就会变成最小化: C × 0 + 1 2 ∑ i = 1 n θ j 2 C\times0+\frac{1}{2}\sum_{i=1}^{n}\theta_j^2 C×0+21i=1∑nθj2
这个式子受以下条件限制:
min 1 2 ∑ j = 1 n θ j 2 s.t { θ T x ( i ) ≥ 1 if y ( i ) = 1 θ T x ( i ) ≤ − 1 if y ( i ) = 0 \min \frac{1}{2} \sum_{j=1}^{n} \theta_{j}^{2}\;\; \text { s.t }\left\{\begin{array}{c} \theta^{T} x^{(i)} \geq 1 \text { if } y^{(i)}=1 \\ \theta^{T} x^{(i)} \leq-1 \text { if } y^{(i)}=0 \end{array}\right. min21j=1∑nθj2 s.t {θTx(i)≥1 if y(i)=1θTx(i)≤−1 if y(i)=0
这也就是说,当我们解决这个优化问题的时候,会得到一个很有趣得决策边界。
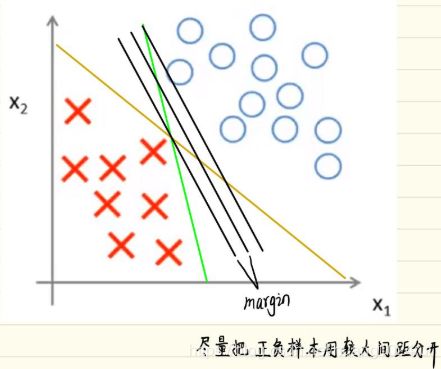
我们可以用绿色的线和紫色的线将数据分开,但是效果不好。支持向量机会选择黑色的线。观察黑色的线和蓝色的线可知,其决策边界和训练样本的最小距离要更大一些,在分离样本时表现也会更好一些。这个距离叫做支持向量机的间距(margin),这使得支持向量机具有鲁棒性,因为它在分离数据时,会尽量用大的距离去分开,这也是为什么有时候把支持向量机叫做大间距分类器。
-
参数C的设置
参数 C 其实是支持向量机对异常点的敏感程度,C 越大就越敏感,任何异常点都会影响最终结果。 C 越小,对异常点就越不敏感,普通的一两个异常点都会被忽略。

如果你将C设置的不要太大,则你最终会得到这条黑线,当 C C C不是非常非常大的时候,它可以忽略掉一些异常点的影响,得到更好的决策界。 甚至当你的数据不是线性可分的时候,支持向量机也可以给出好的结果。- 回顾 C = 1 / λ C=1/λ C=1/λ,因此:
- C C C 较大时,相当于 λ λ λ 较小,可能会导致过拟合,高方差。
- C C C 较小时,相当于 λ λ λ 较大,可能会导致低拟合,高偏差。
- 回顾 C = 1 / λ C=1/λ C=1/λ,因此:
2.3 Mathematics Behind Large Margin Classification (Optional) 数学背后的大边界分类(可选)
-
由向量定义进行推导
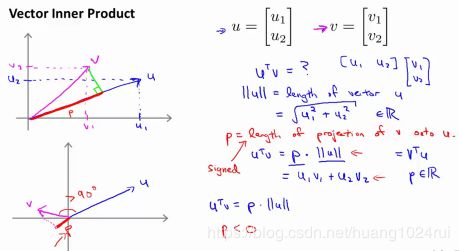
上图是以两个二维向量为例,我们把向量 v v v投影到向量 u u u上,其投影的长度为 p p p, ∥ u ∥ \left \| u \right \| ∥u∥ 为向量 u 的模,那么向量的内积就等于 p ∗ ∥ u ∥ p*\left \| u \right \| p∗∥u∥。在代数定义向量内积可表示为: u 1 v 1 + u 2 v 2 u_1v_1+u_2v_2 u1v1+u2v2 ,根据此定义可以得出: u T v = u 1 v 1 + u 2 v 2 u^Tv=u_1v_1+u_2v_2 uTv=u1v1+u2v2 。
-
∥ u ∥ \left \| u \right \| ∥u∥为 u → \overrightarrow{u} u 的范数,也就是向量 u → \overrightarrow{u} u 的欧几里得长度。
-
最小化代价函数为: m i n θ 1 2 ∑ i = 1 n θ j 2 min_{\theta}\frac{1}{2}\sum_{i=1}^{n}{\theta_j^2} minθ21i=1∑nθj2
这里以简单的二维为例,可以写成:
m i n θ 1 2 ∑ i = 1 n θ j 2 = 1 2 ( θ 1 2 + θ 2 2 ) = 1 2 ( θ 1 2 + θ 2 2 ) 2 = 1 2 ∥ θ ∥ 2 min_{\theta} \frac{1}{2}\sum_{i=1}^{n}{\theta_j^2}=\frac{1}{2}(\theta_1^2+\theta_2^2)=\frac{1}{2}(\sqrt{\theta_1^2+\theta_2^2})^2=\frac{1}{2}\left \| \theta \right \|^2 minθ21i=1∑nθj2=21(θ12+θ22)=21(θ12+θ22)2=21∥θ∥2 -
毕达哥拉斯定理:
∥ u ∥ = u 1 2 + u 2 2 \left \| u \right \| = \sqrt{u_{1}^{2} + u_{2}^{2}} ∥u∥=u12+u22
只要 θ \theta θ 能最小,最小化函数就能取到最小。
-
-
由向量定义进行边界选择

-
如图所示,当垂直的时候 θ \theta θ 取最小值(垂直的时候,两个向量夹角的余弦 c o s cos cos 值最小,向量夹角的余弦可以表示为: c o s < u , v > cos
u T v = ∥ u ∥ ∥ v ∥ c o s < u , v > = p ∗ ∥ u ∥ u^Tv=\left \| u \right \|\left \| v \right \| cos -
这就解释了为什么支持向量机的决策边界不会选择左图绿色那条。(因为方便理解所以 θ 0 = 0 \theta_0=0 θ0=0 ,这就意味着决策边界要经过原点。) 然后我们可以看到在垂直于决策边界的 θ \theta θ和 x ( i ) x^{(i)} x(i) 的关系(红色投影和粉红色投影),可以看到其投影 p ( i ) p^{(i)} p(i) 的值都比较小,这也就意味着要 ∣ ∣ θ ∣ ∣ 2 ||\theta||^2 ∣∣θ∣∣2 的值很大。这显然是与最小化公式 1 2 ∣ ∣ θ ∣ ∣ 2 \frac{1}{2}||\theta||^2 21∣∣θ∣∣2 矛盾的。所以支持向量机的决策边界会使 p ( i ) p^{(i)} p(i) 在 θ \theta θ 的投影尽量大。
-
这就是为什么决策边界会是右图的原因,也就是为什么支持向量机能有效地产生最大间距分类的原因。因为:支持向量机可以最小化参数 θ \theta θ,使 ∣ ∣ θ ∣ ∣ ||\theta|| ∣∣θ∣∣变小,那么投影长度变长,即间距变长,得到一个比较好的决策边界。(只有最大间距才能使 p ( i ) p^{(i)} p(i) 大,从而 ∣ ∣ θ ∣ ∣ 2 ||\theta||^2 ∣∣θ∣∣2 值小)
-
2.4 核函数定义(Kernels I)
在我们之前拟合一个非线性的判断边界来区别正负样本,是构造多项式特征变量。

-
我们先用一种新的写法来表示决策边界: θ 0 + θ 1 f 1 + θ 2 f 2 + θ 3 f 3 + ⋯ \theta_0+\theta_1f_1+\theta_2f_2+\theta_3f_3+\cdots θ0+θ1f1+θ2f2+θ3f3+⋯。我们这里用 f i f_i fi 表达新的特征变量。
假如是之前我们所学的决策边界,那么就是: f 1 = x 1 , f 2 = x 2 , f 3 = x 1 x 2 , f 4 = x 1 2 , f 5 = x 2 2 f_1=x_1 , f_2=x_2 , f_3=x_1x_2 , f_4=x_1^2 , f_5=x_2^2 f1=x1,f2=x2,f3=x1x2,f4=x12,f5=x22 ,等等。但是这样的高阶项作为特征变量并不是我们确定所需要的,而且运算量非常巨大,那么有没有其他更高的特征变量呢?
-
下面是构造新特征量的一种想法:

-
为了简单理解,我们这里只建立三个特征变量。首先我们在 x 1 , x 2 x_1,x_2 x1,x2 坐标轴上手动选择3个不同的点: l ( 1 ) , l ( 2 ) , l ( 3 ) l^{(1)},l^{(2)},l^{(3)} l(1),l(2),l(3) 。
-
然后我们将第一个特征量定义为: f 1 = s i m i l a r i t y ( x , l ( 1 ) ) f_1=similarity(x,l^{(1)}) f1=similarity(x,l(1)) ,可以看做是样本 x 和第一个标记 l ( 1 ) l^{(1)} l(1) 的相似度。其中可以用这个公式表达这种关系( exp:自然常数e为底的指数函数 ): f 1 = s i m i l a r i t y ( x , l ( 1 ) ) = e x p ( − ∣ ∣ x − l ( 1 ) ∣ ∣ 2 2 σ 2 ) f_1=similarity(x,l^{(1)})=exp(-\frac{||x-l^{(1)}||^2}{2\sigma^2}) f1=similarity(x,l(1))=exp(−2σ2∣∣x−l(1)∣∣2)
-
类似的有: f 2 = s i m i l a r i t y ( x , l ( 2 ) ) = e x p ( − ∣ ∣ x − l ( 2 ) ∣ ∣ 2 2 σ 2 ) f_2=similarity(x,l^{(2)})=exp(-\frac{||x-l^{(2)}||^2}{2\sigma^2}) f2=similarity(x,l(2))=exp(−2σ2∣∣x−l(2)∣∣2),
f 3 = s i m i l a r i t y ( x , l ( 3 ) ) = e x p ( − ∣ ∣ x − l ( 3 ) ∣ ∣ 2 2 σ 2 ) f_3=similarity(x,l^{(3)})=exp(-\frac{||x-l^{(3)}||^2}{2\sigma^2}) f3=similarity(x,l(3))=exp(−2σ2∣∣x−l(3)∣∣2) 。
这个表达式我们称之为 核 函 数 ( K e r n e l s ) \color{red}核函数(Kernels) 核函数(Kernels),在这里我们选用的核函数是高斯核函数(Gaussian Kernels)。
-
-
那么高斯核函数与相似性又有什么关系呢?
-
先来看第一个特征量 f 1 f_1 f1 ,
f 1 = s i m i l a r i t y ( x , l ( 1 ) ) = e x p ( − ∣ ∣ x − l ( 1 ) ∣ ∣ 2 2 σ 2 ) = e x p ( ∑ j = 1 n ( x j − l j ( 1 ) ) 2 2 σ 2 ) f_1=similarity(x,l^{(1)})=exp(-\frac{||x-l^{(1)}||^2}{2\sigma^2})=exp(\frac{\sum_{j=1}^{n}{(x_j-l_j^{(1)})^2}}{2\sigma^2}) f1=similarity(x,l(1))=exp(−2σ2∣∣x−l(1)∣∣2)=exp(2σ2∑j=1n(xj−lj(1))2)- 假如样本 x 非常接近 l ( 1 ) l^{(1)} l(1) ,即 x ≈ l ( 1 ) x\approx l^{(1)} x≈l(1) ,那么: f 1 ≈ e x p ( − 0 2 2 σ 2 ) ≈ 1 f_1\approx exp(-\frac{0^2}{2\sigma^2})\approx 1 f1≈exp(−2σ202)≈1 。
- 假如样本 x 离 l ( 1 ) l^{(1)} l(1) 非常远,即 x ≫ l ( 1 ) x\gg l^{(1)} x≫l(1) ,那么: f 1 ≈ e x p ( − ∞ 2 2 σ 2 ) ≈ 0 f_1\approx exp(-\frac{\infty^2}{2\sigma^2})\approx 0 f1≈exp(−2σ2∞2)≈0 。
-
可视化如下:
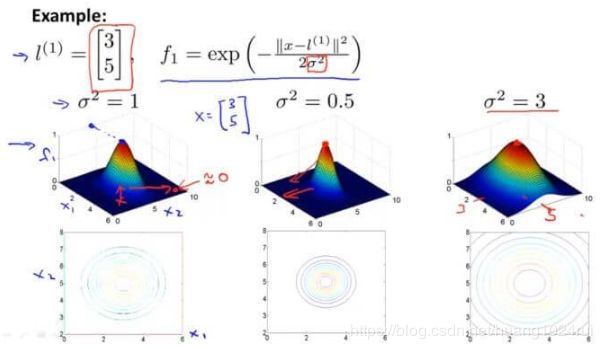
从图中可以看到越接近 l ( 1 ) , f 1 l^{(1)} , f_1 l(1),f1 的值越大。σ 2 \color{red}{\sigma^2} σ2 这个高斯核函数的参数对函数的影响。从图中可以看到,减小或者增加只会对图像的肥瘦产生影响,也就是影响增加或者减小的速度。
-
在下图中,当实例处于洋红色的点位置处,因为其离 l ( 1 ) l^{(1)} l(1)更近,但是离 l ( 2 ) l^{(2)} l(2)和 l ( 3 ) l^{(3)} l(3)较远,因此 f 1 f_1 f1接近1,而 f 2 f_2 f2, f 3 f_3 f3接近0。因此 h θ ( x ) = θ 0 + θ 1 f 1 + θ 2 f 2 + θ 1 f 3 > 0 h_θ(x)=θ_0+θ_1f_1+θ_2f_2+θ_1f_3>0 hθ(x)=θ0+θ1f1+θ2f2+θ1f3>0,因此预测 y = 1 y=1 y=1。同理可以求出,对于离 l ( 2 ) l^{(2)} l(2)较近的绿色点,也预测 y = 1 y=1 y=1,但是对于蓝绿色的点,因为其离三个地标都较远,预测 y = 0 y=0 y=0。
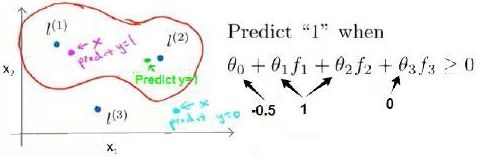
这样,图中红色的封闭曲线所表示的范围,便是我们依据一个单一的训练实例和我们选取的地标所得出的判定边界,在预测时,我们采用的特征不是训练实例本身的特征,而是通过核函数计算出的新特征 f 1 , f 2 , f 3 f_1,f_2,f_3 f1,f2,f3。
-
2.5 核函数标记点选取(Kernels II )
通过标记点以及核函数,训练出非常复杂的非线性判别边界。那标记点 l ( 1 ) , l ( 2 ) , l ( 3 ) l^{(1)},l^{(2)},l^{(3)} l(1),l(2),l(3) 这些点是怎么来的?
-
假定我们有如下的数据集:
( x ( 1 ) , y ( 1 ) ) , ( x ( 2 ) , y ( 2 ) ) , ( x ( 3 ) , y ( 3 ) ) ⋯ ( x ( m ) , y ( m ) ) (x^{(1)},y^{(1)}),(x^{(2)},y^{(2)}),(x^{(3)},y^{(3)})\cdots(x^{(m)},y^{(m)}) (x(1),y(1)),(x(2),y(2)),(x(3),y(3))⋯(x(m),y(m))
我们就将每个样本作为一个标记点:
l ( 1 ) = x ( 1 ) , l ( 2 ) = x ( 2 ) , l ( 3 ) = x ( 3 ) ⋯ l ( m ) = x ( m ) l^{(1)}=x^{(1)},l^{(2)}=x^{(2)},l^{(3)}=x^{(3)}\cdots l^{(m)}=x^{(m)} l(1)=x(1),l(2)=x(2),l(3)=x(3)⋯l(m)=x(m)
则对于样本 ( x ( i ) , y ( i ) ) (x^{(i)},y^{(i)}) (x(i),y(i)) ,我们计算其与各个标记点的距离:
f 1 ( i ) = s i m ( x ( i ) , l ( 1 ) ) f 2 ( i ) = s i m ( x ( i ) , l ( 2 ) ) ⋮ f m ( i ) = s i m ( x ( i ) , l ( 3 ) ) \begin{matrix} f^{(i)}_1=sim(x^{(i)},l^{(1)})\\ f^{(i)}_2=sim(x^{(i)},l^{(2)})\\ \vdots \\ f^{(i)}_m=sim(x^{(i)},l^{(3)})\\ \end{matrix} f1(i)=sim(x(i),l(1))f2(i)=sim(x(i),l(2))⋮fm(i)=sim(x(i),l(3))
得到新的特征向量: f ∈ R m + 1 f \in \mathbb{R}^{m+1} f∈Rm+1
f = [ f 0 f 1 f 2 ⋮ f m ] f = \begin{bmatrix} f_0\\ f_1\\ f_2\\ \vdots \\ f_m \end{bmatrix} f=⎣⎢⎢⎢⎢⎢⎡f0f1f2⋮fm⎦⎥⎥⎥⎥⎥⎤
其中 f 0 = 1 f_0=1 f0=1
则具备核函数的 SVM 的训练过程如下:
m i n θ C [ ∑ i = 1 m y ( i ) c o s t 1 ( θ T f ( i ) ) + ( 1 − y ( i ) ) c o s t 0 ( θ T f ( i ) ) ] + 1 2 ∑ j = 1 n θ j 2 min_{\theta} C[\sum_{i=1}^{m}{y^{(i)}}cost_1(\theta^Tf^{(i)})+(1-y^{(i)})cost_0(\theta^Tf^{(i)})]+\frac{1}{2}\sum_{j=1}^{n}{\theta_j^2} minθC[i=1∑my(i)cost1(θTf(i))+(1−y(i))cost0(θTf(i))]+21j=1∑nθj2 -
在具体实施过程中,我们还需要对最后的正则化项进行些微调整,在计算 1 2 ∑ j = 1 n θ j 2 \frac{1}{2}\sum_{j=1}^{n}{\theta_j^2} 21∑j=1nθj2时,我们用 θ T M θ \color{red}θ^TMθ θTMθ代替 θ T θ \color{red}θ^Tθ θTθ,其中M是根据我们选择的核函数而不同的一个矩阵。这样做的原因是为了简化计算。
理论上讲,我们也可以在逻辑回归中使用核函数,但是上面使用 M来简化计算的方法不适用与逻辑回归,因此计算将非常耗费时间。
在此,我们不介绍最小化支持向量机的代价函数的方法,你可以使用现有的软件包(如liblinear,libsvm等)。在使用这些软件包最小化我们的代价函数之前,我们通常需要编写核函数,并且如果我们使用高斯核函数,那么在使用之前进行特征缩放是非常必要的。
另外,支持向量机也可以不使用核函数,不使用核函数又称为线性核函数(linear kernel),
当我们不采用非常复杂的函数,或者我们的训练集特征非常多而实例非常少的时候,可以采用这种不带核函数的支持向量机。 -
下面是支持向量机的两个参数 C ( C( C(C=1/λ ) ) )和 σ \sigma σ的影响:
- C C C 较大时,相当于 λ λ λ较小,可能会导致过拟合,高方差;
- C C C 较小时,相当于 λ λ λ较大,可能会导致低拟合,高偏差;
- σ \sigma σ较大时,可能会导致低方差,高偏差;
- σ \sigma σ较小时,可能会导致低偏差,高方差。
2.6 SVMs in Practice(Using An SVM)
-
使用流行库
作为当今最为流行的分类算法之一,SVM 已经拥有了不少优秀的实现库,如 libsvm 等,因此,我们不再需要自己手动实现 SVM(要知道,一个能用于生产环境的 SVM 模型并非课程中介绍的那么简单)。在使用这些库时,我们通常需要声明 SVM 需要的两个关键部分:
- 参 数 C \color{red}参数 C 参数C
- 核 函 数 ( K e r n e l ) \color{red}核函数(Kernel) 核函数(Kernel)- 由于 C 可以看做与正规化参数 λ \lambda λ 作用相反,则对于 C 的调节:
- 低偏差,高方差,即遇到了过拟合时:减小 C 值。
- 高偏差,低方差,即遇到了欠拟合时:增大 C 值。 - 而对于核函数的选择有这么一些 tips(n为特征维度,m为样本规模):
a). 当 n 较高,而 m 较小时,不宜使用核函数(或者线性核函数),否则容易引起过拟合。
b). 当 n 较低,而 m 足够大时,考虑使用高斯核函数。不过在使用高斯核函数前,需要进行 特 征 缩 放 ( f e a t u r e s c a l i n g ) \color{red}特征缩放(feature\; scaling) 特征缩放(featurescaling)。
c). 当核函数的参数 σ 2 \sigma^2 σ2 较大时,特征 f i f_i fi 较为平缓,即各个样本的特征差异变小,此时会造成欠拟合(高偏差,低方差),如下图上边的图,
d). 当 σ 2 \sigma^2 σ2 较小时,特征 f i f_i fi 曲线变化剧烈,即各个样本的特征差异变大,此时会造成过拟合(低偏差,高方差),如下图下边的图:

- 在高斯核函数之外我们还有其他一些选择,如:
- 多项式核函数(Polynomial Kernel)
- 字符串核函数(String kernel)
- 卡方核函数( chi-square kernel)
- 直方图交集核函数(histogram intersection kernel)
- 等等…
这些核函数的目标也都是根据训练集和地标之间的距离来构建新特征,这些核函数需要满足 M e r c e r ′ s 定 理 \color{red}Mercer's定理 Mercer′s定理,才能被支持向量机的优化软件正确处理。
- 由于 C 可以看做与正规化参数 λ \lambda λ 作用相反,则对于 C 的调节:
-
多分类问题
通常,流行的SVM库已经内置了多分类(KSVM)相关的 api,如果其不支持多分类,则与逻辑回归一样,使用 One-vs-All 策略来进行多分类:轮流选中某一类型 i ,将其视为正样本,即 “1” 分类,剩下样本都看做是负样本,即 “0” 分类。
训练 SVM 得到参数 θ ( 1 ) , θ ( 2 ) , ⋯ , θ ( K ) \theta^{(1)},\theta^{(2)},\cdots,\theta^{(K)} θ(1),θ(2),⋯,θ(K) ,即总共获得了 K−1 个决策边界。
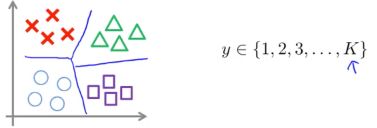
-
分类模型的选择
目前,我们学到的分类模型有:
(1)逻辑回归;
(2)神经网络;
(3)SVM怎么选择在这三者中做出选择呢?我们考虑特征维度 n 及样本规模 m :
1. 如果 n 相对于 m 非常大,例如 n=10000 ,而 m ∈ ( 10 , 1000 ) m\in(10,1000) m∈(10,1000) :此时选用逻辑回归或者无核的 SVM。
2. 如果 n 较小,m 适中,如 n ∈ ( 1 , 1000 ) n\in(1,1000) n∈(1,1000) ,而 m ∈ ( 10 , 10000 ) m\in(10,10000) m∈(10,10000) :此时选用核函数为高斯核函数的 SVM。
3. 如果 n 较小,m 较大,如 n ∈ ( 1 , 1000 ) n\in(1,1000) n∈(1,1000) ,而 m>50000 :此时,需要创建更多的特征(比如通过多项式扩展),再使用逻辑回归或者无核的 SVM。 神经网络对于上述情形都有不错的适应性,但是计算性能上较慢。
3. Week 8
3.1 聚类(Clustering)
3.1.1 非监督学习(Unsupervised Learning)
- 定义
从本节开始,将正式进入到无监督学习(Unsupervised Learning)部分。无监督学习,顾名思义,就是不受监督的学习,一种自由的学习方式。该学习方式不需要先验知识进行指导,而是不断地自我认知,自我巩固,最后进行自我归纳,在机器学习中,无监督学习可以被简单理解为不为训练集提供对应的类别标识(label),其与有监督学习的对比如下:
- 有监督学习(Supervised Learning) 下的训练集:
{ ( x ( 1 ) , y ( 1 ) ) , ( x ( 2 ) , y ( 2 ) ) , ⋯ , ( x ( m ) , y ( m ) ) } \left\{ (x^{(1)},y^{(1)}),(x^{(2)},y^{(2)}),\cdots,(x^{(m)},y^{(m)}) \right\} {(x(1),y(1)),(x(2),y(2)),⋯,(x(m),y(m))}
- 无监督学习(Unsupervised Learning) 下的训练集:
{ ( x ( 1 ) ) , ( x ( 2 ) ) , ( x ( 3 ) ) , ⋯ , ( x ( m ) ) } \left\{ (x^{(1)}),(x^{(2)}),(x^{(3)}),\cdots,(x^{(m)}) \right\} {(x(1)),(x(2)),(x(3)),⋯,(x(m))}
在有监督学习中,我们把对样本进行分类的过程称之为分类(Classification),而在无监督学习中,我们将物体被划分到不同集合的过程称之为聚类(Clustering)。聚这个动词十分精确,他传神地描绘了各个物体自主地想属于自己的集合靠拢的过程。在聚类中,我们把物体所在的集合称之为 簇 ( c l u s t e r ) \color{red}{簇(cluster)} 簇(cluster)。
- 应用
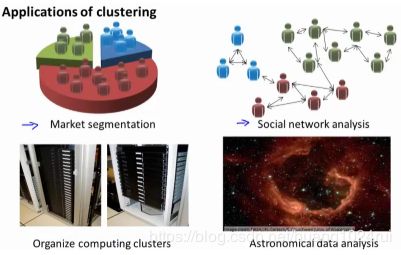
- 市场分割:也许你在数据库中存储了许多客户的信息,而你希望将他们分成不同的客户群,这样你可以对不同类型的客户分别销售产品或者分别提供更适合的服务。
- 社交网络分析:比如说:你经常跟哪些人联系,而这些人又经常给哪些人发邮件,由此找到关系密切的人群。
3.1.2 K-Means
在聚类问题中,我们需要将未加标签的数据通过算法自动分成有紧密关系的子集。那么K均值聚类算法(K-mean)是现在最为广泛使用的聚类方法。
- 基本步骤
- 簇分配(cluster assignment):
- 随机生成 n n n点,叫做聚类中心(cluster centroids)。随机生成 n n n个点的原因是我们想把数据聚成 n n n类。
- 然后进行簇分配。其中,我们要遍历每个样本,将每个数据点分配给 n n n个聚类中心之一。
- 移动聚类中心(move centroid):
- 将两个聚类中心移动到同色的点的均值处。
- 进行迭代,继续执行簇分配和移动聚类中心的步骤,直到聚类中心不再改变。此时,我们说K均值已经聚合(converged)。
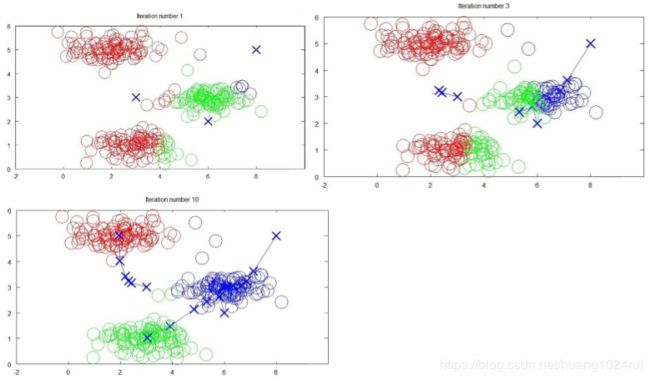
第一个for循环是赋值步骤,即:对于每一个样例i,计算其应该属于的类。第二个for循环是聚类中心的移动,即:对于每一个类k,重新计算该类的质心。Repeat { for i = 1 to m c(i) := index (form 1 to K) of cluster centroid closest to x(i) for k = 1 to K μk := average (mean) of points assigned to cluster k } - 例子
3.1.3 优化目标(Optimization Objective)
-
代价函数(失真代价函数(distortion cost function))
和其他机器学习算法一样,K-Means 也要评估并且最小化聚类代价,引入代价函数:
J ( c ( 1 ) , c ( 2 ) , ⋯ , c ( m ) ; μ 1 , μ 2 , ⋯ , μ k ) = 1 m ∑ i = 1 m ∥ x ( i ) − μ c ( i ) ∥ 2 J(c^{(1)},c^{(2)},\cdots,c^{(m)};\mu_1,\mu_2,\cdots,\mu_k)=\frac{1}{m}\sum_{i=1}^m\left \| x^{(i)}-\mu_c(i) \right \|^2 J(c(1),c(2),⋯,c(m);μ1,μ2,⋯,μk)=m1i=1∑m∥∥∥x(i)−μc(i)∥∥∥2- c ( i ) c^{(i)} c(i),它表示的是当前样本 x ( i ) x^{(i)} x(i)所属的那个簇的索引或是序号。
- μ k \mu_k μk,它表示第 k k k个聚类中心的位置。
- μ c ( i ) \mu_c^{(i)} μc(i),它表示 x ( i ) x^{(i)} x(i)所属的那个簇的聚类中心。
可以在调试K均值聚类计算的时候可以看其是否收敛来判断算法是否正常工作。
-
代价函数的求解步骤
实际上,K-Means 其实就是把以上两个系列的变量分成两半然后分别最小化代价函数关于这两组变量,然后保持迭代。- 样本分配时(簇分配):
我们固定住了 ( μ 1 , μ 2 , ⋯ , μ k ) (\mu_1,\mu_2,\cdots,\mu_k) (μ1,μ2,⋯,μk) ,而关于 ( c ( 1 ) , c ( 2 ) , ⋯ , c ( m ) ) (c^{(1)},c^{(2)},\cdots,c^{(m)}) (c(1),c(2),⋯,c(m)) 最小化了 J 。 - 中心移动时(移动类聚中心):
我们再关于聚类中心的位置 ( μ 1 , μ 2 , ⋯ , μ k ) (\mu_1,\mu_2,\cdots,\mu_k) (μ1,μ2,⋯,μk) 最小化了 J 。
- 样本分配时(簇分配):
由于 K-Means 每次迭代过程都在最小化 J ,所以下面的代价函数变化曲线不会出现:

3.1.4 随机初始化(Random Initialization)
在运行K-均值算法的之前,我们首先要随机初始化所有的聚类中心点,下面介绍怎样做:
1. 我们应该选择 K < m KK<m ,即聚类中心点的个数要小于所有训练集实例的数量。
2. 随机选择 K K K个训练实例,然后令 K K K个聚类中心分别与这 K K K个训练实例相等。
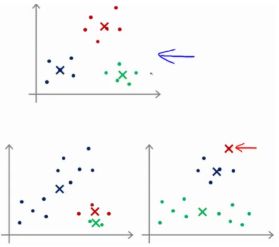
1.存在问题
K-均值的一个问题在于,它有可能会停留在一个局部最小值处,而这取决于初始化的情况,如下图:
2. 解决局部最小值问题
现在,想要提前避免不好的聚类结果仍是困难的,我们只能尝试不同的初始化:
1. for i=1 to 100 (一般循环选择在 50 - 1000 之间):
- 随机初始化,执行 K-Means,得到每个所属的簇 c ( i ) c^{(i)} c(i) ,以及各聚类的中心位置 μ \mu μ :
c ( 1 ) , c ( 2 ) , ⋯ , c ( m ) ; μ 1 , μ 2 , ⋯ , μ k c^{(1)},c^{(2)},\cdots,c^{(m)};\mu_1,\mu_2,\cdots,\mu_k c(1),c(2),⋯,c(m);μ1,μ2,⋯,μk
2. 计算失真函数 J
- 选择这 100 次中, J 最小的作为最终的聚类结果。
- 一般 K 的经验值在 2 − 10 \color{red}2 - 10 2−10 之间。
- 随机选取 K 值,但是要循环不重复取100次,取其 J ( c ( 1 ) , c ( 2 ) , ⋯ , c ( m ) ; μ 1 , μ 2 , ⋯ , μ k ) J(c^{(1)},c^{(2)},\cdots,c^{(m)};\mu_1,\mu_2,\cdots,\mu_k) J(c(1),c(2),⋯,c(m);μ1,μ2,⋯,μk) 最低的那个结果。
3.1.5 选择聚类数(Choosing the Number of Clusters)
- 肘部法则(Elbow Method):
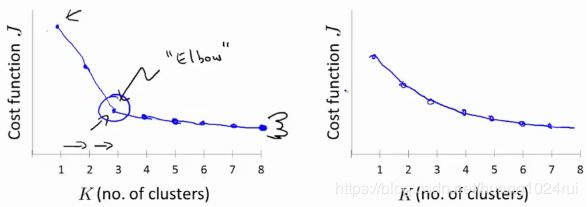
我们通过观察增加聚类中心的个数,其代价函数是如何变化的。有时候我们可以得到如左边的图像,可以看到在K=3的时候,有一个肘点(Elbow)。因为从 1 → 3 1\to 3 1→3,代价函数迅速下降,但是随后下降比较缓慢,所以K=3,也就是分为3个类是一个好的选择。然而,现实往往是残酷的,我们也会得到右边的代价函数,根本没有肘点,这就让我们难以选则了。
- 根据需求
例如,我们的 T-恤制造例子中,我们要将用户按照身材聚类,我们可以分成3个尺寸: S , M , L S,M,L S,M,L,也可以分成5个尺寸 X S , S , M , L , X L XS,S,M,L,XL XS,S,M,L,XL,这样的选择是建立在回答“聚类后我们制造的T-恤是否能较好地适合我们的客户”这个问题的基础上作出的。
3.2 降维(Dimensionality Reduction)
3.2.1 动机(Motivation)
我们很希望有足够多的特征(知识)来保准学习模型的训练效果,尤其在图像处理这类的任务中,高维特征是在所难免的,但是,高维的特征也有几个如下不好的地方:
- 学习性能下降,知识越多,吸收知识(输入),并且精通知识(学习)的速度就越慢。
- 过多的特征难于分辨,你很难第一时间认识某个特征代表的意义。
- 特征冗余,如下图所示,厘米和英尺就是一对冗余特征,他们本身代表的意义是一样的,并且能够相互转换。
- 数据压缩(Motivation I- Data Compression)
我们要将一个三维的特征向量降至一个二维的特征向量。我们将三维向量投射到一个二维的平面上,强迫使得所有的数据都在同一个平面上,降至二维的特征向量。
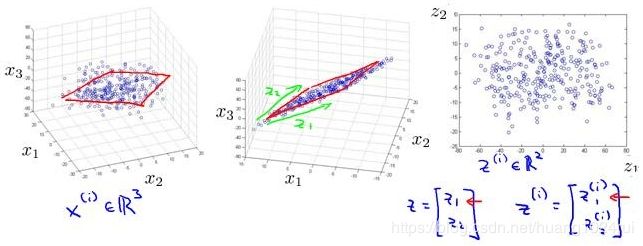
这样的处理过程可以被用于把任何维度的数据降到任何想要的维度,例如将1000维的特征降至100维。 - 数据可视化(Visualization)
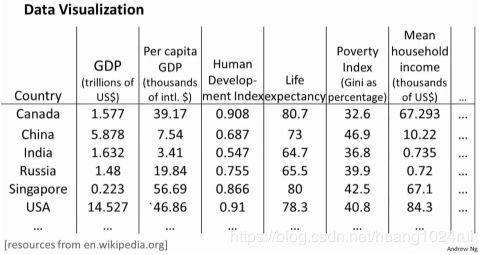
假使我们有有关于许多不同国家的数据,每一个特征向量都有50个特征(如,GDP,人均GDP,平均寿命等)。如果要将这个50维的数据可视化是不可能的。使用降维的方法将其降至2维,我们便可以将其可视化了。新产生的特征的意义就必须由我们自己去发现了。
3.2.2 Principal Component Analysis 主成分分析
PCA,Principle Component Analysis,即主成分分析法,是特征降维的最常用手段。顾名思义,PCA 能从冗余特征中提取主要成分,在不太损失模型质量的情况下,提升了模型训练速度。

如上图所示,我们将样本到红色向量的距离称作是投影误差(Projection Error)。以二维投影到一维为例,PCA 就是要找寻一条直线,使得各个特征的投影误差足够小,这样才能尽可能的保留原特征具有的信息。
-
PCA 和 线性回归的区别是:
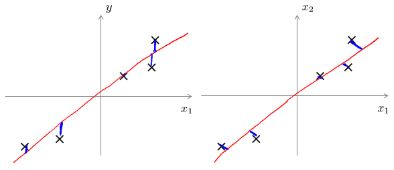
线性回归找的是垂直于 X 轴距离最小值,PCA 找的是投影垂直距离最小值。线性回归目的是想通过 x 预测 y,但是 PCA 的目的是为了找一个降维的面,没有什么特殊的 y,代表降维的面的向量 x 1 x_1 x1、 x 2 x_2 x2、 x 3 x_3 x3、 x n x_n xn 都是 同 等 地 位 的 \color{red}同等地位的 同等地位的。
优势和劣势:
- PCA将 n n n个特征降维到 k k k个,可以用来进行数据压缩,如果100维的向量最后可以用10维来表示,那么压缩率为90%。同样图像处理领域的KL变换使用PCA做图像压缩。但PCA 要保证降维后,还要保证数据的特性损失最小。
- PCA技术的一大好处是对数据进行降维的处理。我们可以对新求出的“主元”向量的重要性进行排序,根据需要取前面最重要的部分,将后面的维数省去,可以达到降维从而简化模型或是对数据进行压缩的效果。同时最大程度的保持了原有数据的信息。
- PCA技术的一个很大的优点是,它是完全无参数限制的。在PCA的计算过程中完全不需要人为的设定参数或是根据任何经验模型对计算进行干预,最后的结果只与数据相关,与用户是独立的。
- 但是,这一点同时也可以看作是缺点。如果用户对观测对象有一定的先验知识,掌握了数据的一些特征,却无法通过参数化等方法对处理过程进行干预,可能会得不到预期的效果,效率也不高。
-
算法流程
假定我们需要将特征维度从 m m m维降到 k k k维。则 PCA 的执行流程如下:- 第一步: 特征标准化(feature scaling / mean normalization),平衡各个特征尺度:
x j ( i ) = x j ( i ) − μ j s j x^{(i)}_j=\frac{x^{(i)}_j-\mu_j}{s_j} xj(i)=sjxj(i)−μj
μ j \mu_j μj 为特征 j 的均值, s j s_j sj 为特征 j 的标准差, x j ( i ) x^{(i)}_j xj(i)表示第 i i i个点的第 j j j个特征。 - 第二步: 计算协方差矩阵 Σ \Sigma Σ ,其中 m m m表示有 m m m个点, X T X ∈ R m ∗ m X^TX \in R^{m*m} XTX∈Rm∗m:
Σ = 1 m ∑ i = 1 m ( x ( i ) ) ( x ( i ) ) T = 1 m ⋅ X T X \Sigma =\frac{1}{m}\sum_{i=1}^{m}(x^{(i)})(x^{(i)})^T=\frac{1}{m} \cdot X^TX Σ=m1i=1∑m(x(i))(x(i))T=m1⋅XTX - 第三步: 通过奇异值分解(SVD),求取 Σ \Sigma Σ 的特征向量(eigenvectors):
( U , S , V T ) = S V D ( Σ ) (U,S,V^T)=SVD(\Sigma ) (U,S,VT)=SVD(Σ)
从 U U U中取出前 k \color{red}k k个左奇异向量(从 m m m选择 k k k),构成一个约减矩阵 U r e d u c e ( μ ( i ) ∈ R m , U r e d u c e ∈ R m ∗ k ) U_{reduce}(\mu^{(i)}\in R^m,U_{reduce}\in R^{m*k}) Ureduce(μ(i)∈Rm,Ureduce∈Rm∗k) :
U r e d u c e = ( μ ( 1 ) , μ ( 2 ) , ⋯ , μ ( k ) ) U_{reduce}=(\mu^{(1)},\mu^{(2)},\cdots,\mu^{(k)}) Ureduce=(μ(1),μ(2),⋯,μ(k))
计算新的特征向量: z ( i ) ( z ( i ) ∈ R k ∗ 1 ) z^{(i)}(z^{(i)}\in R^{k*1}) z(i)(z(i)∈Rk∗1)
z ( i ) = U r e d u c e T ⋅ x ( i ) z^{(i)}=U^{T}_{reduce} \cdot x^{(i)} z(i)=UreduceT⋅x(i)
- 第一步: 特征标准化(feature scaling / mean normalization),平衡各个特征尺度:
-
特征还原
因为 PCA 仅保留了特征的主成分,所以 PCA 是一种有损的压缩方式,假定我们获得新特征向量为:
z = U r e d u c e T x z=U^T_{reduce}x z=UreduceTx
那么,还原后的特征 x a p p r o x ( x a p p r o x ∈ R m ∗ 1 ) x_{approx}(x_{approx} \in R^{m*1}) xapprox(xapprox∈Rm∗1) 为:
x a p p r o x = U r e d u c e z x_{approx}=U_{reduce}z xapprox=Ureducez

3.2.3 选择主成分的数量(Choosing The Number Of Principal Components)
从 PCA 的执行流程中,我们知道,需要为 PCA 指定目的维度 k 。如果降维不多,则性能提升不大;如果目标维度太小,则又丢失了许多信息。
-
方法1
通常,使用如下的流程的来评估 k 值选取优异:- 求各样本的投影均方误差:
min 1 m ∑ j = 1 m ∥ x ( i ) − x a p p r o x ( i ) ∥ 2 \min \frac{1}{m}\sum_{j=1}^{m}\left \| x^{(i)}-x^{(i)}_{approx} \right \|^2 minm1j=1∑m∥∥∥x(i)−xapprox(i)∥∥∥2 - 求数据的总变差:
1 m ∑ j = 1 m ∥ x ( i ) ∥ 2 \frac{1}{m}\sum_{j=1}^{m}\left \| x^{(i)} \right \|^2 m1j=1∑m∥∥∥x(i)∥∥∥2 - 评估下式是否成立:
min 1 m ∑ j = 1 m ∥ x ( i ) − x a p p r o x ( i ) ∥ 2 1 m ∑ j = 1 m ∥ x ( i ) ∥ 2 ⩽ ϵ \frac{\min \frac{1}{m}\sum_{j=1}^{m}\left \| x^{(i)}-x^{(i)}_{approx} \right \|^2}{\frac{1}{m}\sum_{j=1}^{m}\left \| x^{(i)} \right \|^2} \leqslant \epsilon m1∑j=1m∥∥x(i)∥∥2minm1∑j=1m∥∥∥x(i)−xapprox(i)∥∥∥2⩽ϵ
其中, ϵ \epsilon ϵ 的取值可以为 0.01 , 0.05 , 0.10 , ⋯ 0.01,0.05,0.10,⋯ 0.01,0.05,0.10,⋯,假设 ϵ = 0.01 \epsilon = 0.01 ϵ=0.01 ,我们就说“特征间 99% 的差异性得到保留”。
- 求各样本的投影均方误差:
-
方法2
还有一些更好的方式来选择 k k k,当我们在Octave中调用“svd”函数的时候,我们获得三个参数:[U, S, V] = svd(sigma)。其中的 S 是一个 m × m 的对角矩阵 \color{red}S\text{是一个}m×m\text{的对角矩阵} S是一个m×m的对角矩阵,我们可以使用这个矩阵来计算平均均方误差与训练集方差的比例:
1 m ∑ i = 1 m ∥ x ( i ) − x a p p r o x ( i ) ∥ 2 1 m ∑ i = 1 m ∥ x ( i ) ∥ 2 = 1 − Σ i = 1 m S i i Σ i = 1 k S i i ≤ ϵ \dfrac {\dfrac {1}{m}\sum^{m}_{i=1}\left\| x^{\left( i\right) }-x^{\left( i\right) }_{approx}\right\| ^{2}}{\dfrac {1}{m}\sum^{m}_{i=1}\left\| x^{(i)}\right\| ^{2}}=1-\dfrac {\Sigma^{m}_{i=1}S_{ii}}{\Sigma^{k}_{i=1}S_{ii}}\leq \epsilon m1∑i=1m∥∥x(i)∥∥2m1∑i=1m∥∥∥x(i)−xapprox(i)∥∥∥2=1−Σi=1kSiiΣi=1mSii≤ϵ
也就是: Σ i = 1 k s i i Σ i = 1 n s i i ≥ ϵ \frac {\Sigma^{k}_{i=1}s_{ii}}{\Sigma^{n}_{i=1}s_{ii}}\geq\epsilon Σi=1nsiiΣi=1ksii≥ϵ
3.2.4 主成分分析法的应用建议(Advice for Applying PCA)
-
真实运算时的注意事项
假使我们正在针对一张 100×100像素的图片进行某个计算机视觉的机器学习,即总共有10000 个特征。- 第一步是运用主要成分分析将数据压缩至1000个特征
- 然后对训练集运行学习算法
- 在预测时, 采 用 之 前 在 训 练 集 学 习 而 来 的 U r e d u c e 采用之前在\color{red}{训练集学习而来的U_{reduce}} 采用之前在训练集学习而来的Ureduce 将输入的特征 x x x转换成特征向量 z z z,然后再进行预测
注:如果我们有交叉验证集合测试集,也采用对训练集学习而来的 U r e d u c e U_{reduce} Ureduce。
-
错误使用PCA的情况
- 不 能 将 其 用 于 减 少 过 拟 合 \color{red}不能将其用于减少过拟合 不能将其用于减少过拟合
这样做非常不好,不如尝试正则化处理。原因在于主要成分分析只是近似地丢弃掉一些特征,它并不考虑任何与结果变量有关的信息,因此可能会丢失非常重要的特征。然而当我们进行正则化处理时,会考虑到结果变量,不会丢掉重要的数据。 - 不 能 默 认 地 将 主 要 成 分 分 析 作 为 学 习 过 程 中 的 一 部 分 \color{red}不能默认地将主要成分分析作为学习过程中的一部分 不能默认地将主要成分分析作为学习过程中的一部分
这虽然很多时候有效果,最好还是从所有原始特征开始,只在有必要的时候(算法运行太慢或者占用太多内存)才考虑采用主要成分分析。
- 不 能 将 其 用 于 减 少 过 拟 合 \color{red}不能将其用于减少过拟合 不能将其用于减少过拟合
当你的学习算法收敛地非常缓慢,占用内存或者硬盘空间非常大 所以你想来压缩数据。只有当你的 x ( i ) x^{(i)} x(i) 效果不好,只有当你有证据或者,充足的理由来确定 x ( i ) x^{(i)} x(i) 效果不好的时候,那么就考虑用 PCA 来进行压缩数据。
PCA 通常都是被用来压缩数据的,以减少内存使用或硬盘空间占用,或者用来可视化数据。
4. Week 9

4.1 异常检测(Anomaly Detection)
4.1.1 问题的动机(Problem Motivation)
异常检测(Anomaly detection)问题是机器学习算法的一个常见应用。这种算法的一个有趣之处在于:它虽然主要用于非监督学习问题,但从某些角度看,它又类似于一些监督学习问题。
-
例子
假想你是一个飞机引擎制造商,当你生产的飞机引擎从生产线上流出时,你需要进行QA(质量控制测试),而作为这个测试的一部分,你测量了飞机引擎的一些特征变量,比如引擎运转时产生的热量,或者引擎的振动等等。
数学表示为:有一组从 x ( 1 ) x^{(1)} x(1) 到 x ( m ) x^{(m)} x(m) 个样本,从这 m m m个数据中判断这个引擎是否需要进一步测试。我们将这些样本数据建立一个模型 p ( x ) p(x) p(x), p ( x ) p(x) p(x)表示为 x x x的分布概率。
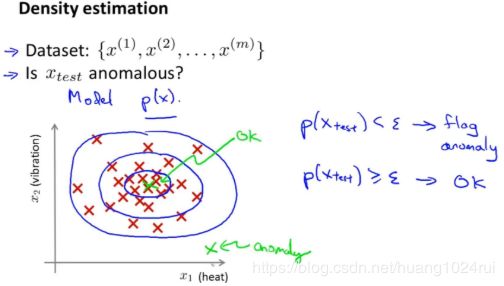
那么假如我们的测试集 x t e s t x_{test} xtest 概率 p p p 低于阈值 ε \varepsilon ε ,那么则将其标记为异常。
i f p ( x ) { ≤ ε a n o m a l y > ε n o r m a l if \quad p(x)\begin{cases}\leq \varepsilon & anomaly \\\\> \varepsilon & normal\end{cases} ifp(x)⎩⎪⎨⎪⎧≤ε>εanomalynormal异常检测的 核 心 \color{red}核心 核心就在于找到一个概率模型 p ( x ) p(x) p(x),帮助我们知道一个样本落入正常样本中的概率,从而帮助我们区分正常和异常样本。 高 斯 分 布 ( G a u s s i a n D i s t r i b u t i o n ) \color{red}高斯分布(Gaussian Distribution) 高斯分布(GaussianDistribution)模型就是异常检测算法最常使用的概率分布模型。
4.1.2 高斯分布(Gaussian Distribution)
-
定义
假如 x 服从高斯分布,那么我们将表示为: x ∼ N ( μ , σ 2 ) x\sim N(\mu,\sigma^2) x∼N(μ,σ2) 。其分布概率为:
p ( x ; μ , σ 2 ) = 1 2 π σ e x p ( − ( x − μ ) 2 2 σ 2 ) p(x;\mu,\sigma^2)=\frac{1}{\sqrt{2\pi}\sigma}exp(-\frac{(x-\mu)^2}{2\sigma^2}) p(x;μ,σ2)=2πσ1exp(−2σ2(x−μ)2)- 其中 μ \mu μ 为期望值(均值), σ 2 \sigma^2 σ2 为方差。
- 其中,期望值 μ \mu μ 决定了其轴的位置,标准差 σ \sigma σ 决定了分布的幅度宽窄。当 μ = 0 , σ = 1 \mu=0,\sigma=1 μ=0,σ=1 时的正态分布是标准正态分布。
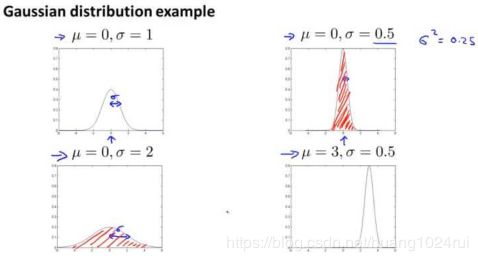
由概率分布的性质,曲线下方的面积等于1,即积分为1,所以图形越宽,高度越矮;图像越高,宽度越窄。 - 期望值: μ = 1 m ∑ i = 1 m x ( i ) \mu=\frac{1}{m}\sum_{i=1}^{m}{x^{(i)}} μ=m1∑i=1mx(i)
方差: σ 2 = 1 m ∑ i = 1 m ( x ( i ) − μ ) 2 \sigma^2=\frac{1}{m}\sum_{i=1}^{m}{(x^{(i)}-\mu)}^2 σ2=m1∑i=1m(x(i)−μ)2 - 上面计算期望值、方差和基本思路,就是统计学里面的极大似然估计。
-
实际计算
假如我们有一组 m 个无标签训练集,其中每个训练数据又有 n 个特征,那么这个训练集应该是 m 个 n 维向量构成的样本矩阵。
在概率论中,对有限个样本进行参数估计
μ j = 1 m ∑ i = 1 m x j ( i ) , δ j 2 = 1 m ∑ i = 1 m ( x j ( i ) − μ j ) 2 ( 也 可 写 成 : δ j 2 = 1 m − 1 ∑ i = 1 m ( x j ( i ) − μ j ) 2 ) \mu_j = \frac{1}{m} \sum_{i=1}^{m}x_j^{(i)}\;\;\;,\;\;\; \delta^2_j = \frac{1}{m} \sum_{i=1}^{m}(x_j^{(i)}-\mu_j)^2(也可写成:\delta^2_j = \frac{1}{m-1} \sum_{i=1}^{m}(x_j^{(i)}-\mu_j)^2) μj=m1i=1∑mxj(i),δj2=m1i=1∑m(xj(i)−μj)2(也可写成:δj2=m−11i=1∑m(xj(i)−μj)2)
这里对参数 μ \mu μ 和参数 δ 2 \delta^2 δ2 的估计就是二者的极大似然估计。假定训练集有 n n n维特征,每一个特征 x 1 x_{1} x1 到 x n x_{n} xn 均服从正态分布,则其模型的概率为:
p ( x ) = p ( x 1 ; μ 1 , σ 1 2 ) p ( x 2 ; μ 2 , σ 2 2 ) ⋯ p ( x n ; μ n , σ n 2 ) = ∏ j = 1 n p ( x j ; μ j , σ j 2 ) = ∏ j = 1 n 1 2 π σ j exp ( − ( x j − μ j ) 2 2 σ j 2 ) \begin{aligned} p(x) &=p\left(x_{1} ; \mu_{1}, \sigma_{1}^{2}\right) p\left(x_{2} ; \mu_{2}, \sigma_{2}^{2}\right) \cdots p\left(x_{n} ; \mu_{n}, \sigma_{n}^{2}\right) \\ &=\prod_{j=1}^{n} p\left(x_{j} ; \mu_{j}, \sigma_{j}^{2}\right) \\ &=\prod_{j=1}^{n} \frac{1}{\sqrt{2 \pi} \sigma_{j}} \exp \left(-\frac{\left(x_{j}-\mu_{j}\right)^{2}}{2 \sigma_{j}^{2}}\right) \end{aligned} p(x)=p(x1;μ1,σ12)p(x2;μ2,σ22)⋯p(xn;μn,σn2)=j=1∏np(xj;μj,σj2)=j=1∏n2πσj1exp(−2σj2(xj−μj)2)
当 p ( x ) < ε p(x)<\varepsilon p(x)<ε时, x x x 为异常样本。
4.1.3 算法(Algorithm)
下图是一个由两个特征的训练集,以及特征的分布情况:
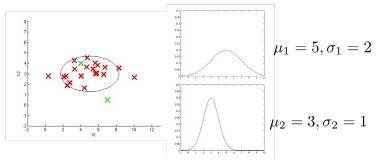
下面的三维图表表示的是密度估计函数,z轴为根据两个特征的值所估计 p ( x ) p(x) p(x)值:

模型 p ( x ) p(x) p(x) 能由热力图反映,热力图越热的地方,是正常样本的概率越高,参数 ε \varepsilon ε 描述了一个截断高度,当概率落到了截断高度以下。我们选择一个 ε \varepsilon ε,将 p ( x ) = ε p(x) = \varepsilon p(x)=ε作为我们的判定边界,当 p ( x ) > ε p(x) > \varepsilon p(x)>ε时预测数据为正常数据,否则则为异常。
4.1.4 开发和评价一个异常检测系统(Developing and Evaluating an Anomaly Detection System)
异常检测算法是一个非监督学习算法,意味着我们无法根据结果变量 y y y 的值来告诉我们数据是否真的是异常的。我们需要另一种方法来帮助检验算法是否有效。当我们开发一个异常检测系统时,我们从带标记(异常或正常)的数据着手,我们从其中选择一部分正常数据用于构建训练集,然后用剩下的正常数据和异常数据混合的数据构成交叉检验集和测试集。
例如:我们有10000台正常引擎的数据,有20台异常引擎的数据。 我们这样分配数据:
- 6000台正常引擎的数据作为训练集
- 2000台正常引擎和10台异常引擎的数据作为交叉检验集
- 2000台正常引擎和10台异常引擎的数据作为测试集
具体的评价方法如下:
- 根据测试集数据,我们估计特征的平均值和方差并构建 p ( x ) p(x) p(x)函数
- 对交叉检验集,我们尝试使用不同的 ε \varepsilon ε值作为阀值,并预测数据是否异常,根据 调 和 平 均 数 F 1 \color{red}调和平均数F_1 调和平均数F1、 查 准 率 与 查 全 率 的 比 例 \color{red}查准率与查全率的比例 查准率与查全率的比例或者 真 阳 性 、 假 阳 性 、 真 阴 性 、 假 阴 性 \color{red}真阳性、假阳性、真阴性、假阴性 真阳性、假阳性、真阴性、假阴性等来选择 ε \varepsilon ε
- 选出 ε \varepsilon ε 后,针对测试集进行预测,计算异常检验系统的 调 和 平 均 数 \color{red}调和平均数 调和平均数、 查 准 率 与 查 全 率 的 比 例 \color{red}查准率与查全率的比例 查准率与查全率的比例或者 真 阳 性 、 假 阳 性 、 真 阴 性 、 假 阴 性 \color{red}真阳性、假阳性、真阴性、假阴性 真阳性、假阳性、真阴性、假阴性。
4.1.5 异常检测与监督学习对比(Anomaly Detection vs. Supervised Learning)
| 异常检测 | 监督学习 |
|---|---|
| 非常少量的正向类(异常数据 y = 1 y=1 y=1), 大量的负向类( y = 0 y=0 y=0) | 同时有大量的正向类和负向类 |
| 异常样本所产生的原因很多,但是样本量很少;且未来遇到的异常可能与已掌握的异常非常不同。利用多数的正类数据来异常检测。 | 有足够多的正类实例,足够用于训练算法,未来遇到的正类实例与训练集中的非常近似。 |
| 例如: 欺诈行为检测 生产(例如飞机引擎)检测数据中心的计算机运行状况 | 例如:邮件过滤器 天气预报 肿瘤分类 |
- 如果异常样本非常少,特征也不一样完全一样(比如今天飞机引擎异常是因为原因一,明天飞机引擎异常是因为原因二,谁也不知道哪天出现异常是什么原因),这种情况下就应该采用异常检测。
- 如果异常样本多,特征比较稳当,这种情况就应该采用监督学习。
4.1.6 选择特征(Choosing What Features to Use)
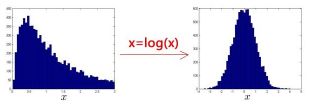
- 特征选取
异常检测假设特征符合高斯分布,如果数据的分布不是高斯分布,异常检测算法也能够工作,但是最好还是将数据转换成高斯分布:- 使用对数函数: x = log ( x + c ) x= \log(x+c) x=log(x+c),其中 c c c 为非负常数;
- x = x c x=x^c x=xc, c c c为 0-1 之间的一个分数。
- 误差分析
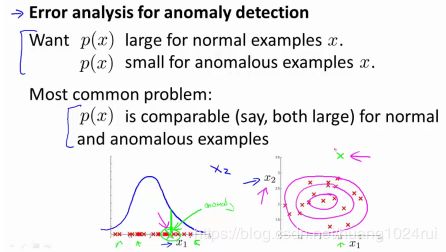
我们通常可以通过将一些相关的特征进行组合,来获得一些新的更好的特征(异常数据的该特征值异常地大或小),例如,在检测数据中心的计算机状况的例子中,我们可以用CPU负载与网络通信量的比例作为一个新的特征,如果该值异常地大,便有可能意味着该服务器是陷入了一些问题中。
4.1.7 多元高斯分布(Multivariate Gaussian Distribution)
与原始的高斯分布相比,多元高斯分布(一般的高斯分布)是增加了每个特征之间的相关系数。即:在一般的高斯分布模型中,计算 p ( x ) p(x) p(x) 是通过分别计算每个特征对应的几率然后将其累乘起来;在多元高斯分布模型中,我们将构建特征的协方差矩阵,用所有的特征一起来计算 p ( x ) p(x) p(x)。
-
一般的高斯分布计算
p ( x ) = ∏ j = 1 n p ( x j ; μ , σ j 2 ) = ∏ j = 1 n 1 2 π σ j e x p ( − ( x j − μ j ) 2 2 σ j 2 ) p(x)=\prod_{j=1}^np(x_j;\mu,\sigma_j^2)=\prod_{j=1}^n\frac{1}{\sqrt{2\pi}\sigma_j}exp(-\frac{(x_j-\mu_j)^2}{2\sigma_j^2}) p(x)=j=1∏np(xj;μ,σj2)=j=1∏n2πσj1exp(−2σj2(xj−μj)2) -
多元高斯分布模型
- 首先计算所有特征的平均值,然后再计算协方差矩阵:
μ = 1 m ∑ i = 1 m x ( i ) \mu=\frac{1}{m}\sum_{i=1}^mx^{(i)} μ=m1i=1∑mx(i)
Σ = 1 m ∑ i = 1 m ( x ( i ) − μ ) ( x ( i ) − μ ) T = 1 m ( X − μ ) T ( X − μ ) \Sigma = \frac{1}{m}\sum_{i=1}^m(x^{(i)}-\mu)(x^{(i)}-\mu)^T=\frac{1}{m}(X-\mu)^T(X-\mu) Σ=m1i=1∑m(x(i)−μ)(x(i)−μ)T=m1(X−μ)T(X−μ)
注:a) 其中 μ \mu μ 是一个向量,其每一个单元都是原特征矩阵中一行数据的均值。b) Σ \Sigma Σ 表示样本协方差矩阵。 - 最后计算多元高斯分布的 p ( x ) p\left( x \right) p(x):
p ( x ) = 1 ( 2 π ) n 2 ∣ Σ ∣ 1 2 e x p ( − 1 2 ( x − μ ) T Σ − 1 ( x − μ ) ) p(x)=\frac{1}{(2\pi)^{\frac{n}{2}}|\Sigma|^{\frac{1}{2}}}exp\left(-\frac{1}{2}(x-\mu)^T\Sigma^{-1}(x-\mu)\right) p(x)=(2π)2n∣Σ∣211exp(−21(x−μ)TΣ−1(x−μ))
其中:- ∣ Σ ∣ |\Sigma| ∣Σ∣是 Σ \Sigma Σ 的行列式,在 Matlab 中用
det(sigma)计算 - Σ − 1 \Sigma^{-1} Σ−1 是协方差矩阵的逆矩阵
- ∣ Σ ∣ |\Sigma| ∣Σ∣是 Σ \Sigma Σ 的行列式,在 Matlab 中用
- 首先计算所有特征的平均值,然后再计算协方差矩阵:
-
协方差矩阵
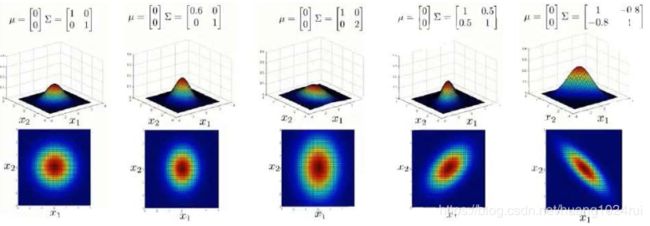
上图是5个不同的模型,从左往右依次分析:- 是一个一般的高斯分布模型
- 通过协方差矩阵,令特征1拥有较小的偏差,同时保持特征2的偏差
- 通过协方差矩阵,令特征2拥有较大的偏差,同时保持特征1的偏差
- 通过协方差矩阵,在不改变两个特征的原有偏差的基础上,增加两者之间的正相关性
- 通过协方差矩阵,在不改变两个特征的原有偏差的基础上,增加两者之间的负相关性
多 元 高 斯 分 布 模 型 与 原 高 斯 分 布 模 型 的 关 系 \color{red}多元高斯分布模型与原高斯分布模型的关系 多元高斯分布模型与原高斯分布模型的关系:
可以证明的是,原本的高斯分布模型是多元高斯分布模型的一个子集,即像上图中的第1、2、3,3个例子所示,如果协方差矩阵只在对角线的单位上有非零的值时,即为原本的高斯分布模型了。 -
原高斯分布模型和多元高斯分布模型的比较( m m m为数据大小, n n n为特征数):
原高斯分布模型 多元高斯分布模型 不能捕捉特征间的相关性,但可以通过将特征进行组合的方法来解决 能自动捕捉特征间的相关性 计算代价低,适应大规模的特征 计算代价较高,训练集较小时也同样适用 无 必须要有 m > n m>n m>n,不然协方差矩阵 不可逆;通常需要 m > 10 n m>10n m>10n 另外特征冗余也会导致协方差矩阵不可逆 注:
- 原高斯分布模型因为不要算矩阵的逆,被广泛使用;如果特征之间存在相互关联的情况,可以构造新新特征的方法来捕捉这些相关性。
- 冗余问题可以参考:RAD和低秩矩阵
4.2 推荐系统(Recommender Systems)
4.2.1 问题形式化(Problem Formulation)
上图的一些标记:
1. n u n_u nu 代表用户的数量
2. n m n_m nm 代表电影的数量
3. r ( i , j ) r(i, j) r(i,j) 如果用户j给电影 i i i 评过分则 r ( i , j ) = 1 r(i,j)=1 r(i,j)=1
4. y ( i , j ) y^{(i, j)} y(i,j) 代表用户 j j j 给电影 i i i的评分
5. m j m_j mj代表用户 j j j 评过分的电影的总数
6. θ ( j ) \theta^{(j)} θ(j)用户 j j j 的参数向量
7. x ( i ) x^{(i)} x(i)电影 i i i 的特征向量
4.2.2 基于内容的推荐系统(Content Based Recommendations)
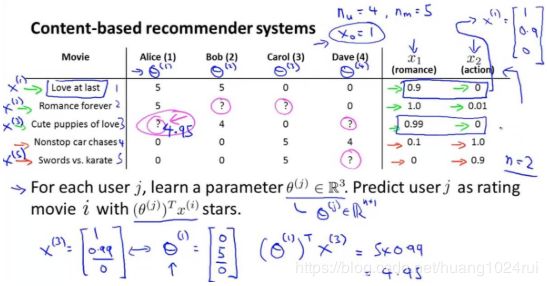
以预测第3部电影、第1个用户可能评的分数为例子。
首先我们用 x 1 x_1 x1 表示爱情浪漫电影类型, x 2 x_2 x2 表示动作片类型。上图左表右侧则为每部电影对于这两个分类的相关程度。我们默认 x 0 = 1 x_0=1 x0=1 。则第一部电影与两个类型的相关程度可以这样表示: x ( 3 ) = [ 1 0.99 0 ] x^{(3)}=\left[ \begin{array}{ccc}1 \\0.99 \\0 \end{array} \right] x(3)=⎣⎡10.990⎦⎤ 。然后用 θ ( j ) \theta^{(j)} θ(j) 表示第 j 个用户对于该种类电影的评分。这里我们假设已经知道(详情下面再讲) θ ( 1 ) = [ 0 5 0 ] \theta^{(1)}=\left[ \begin{array}{ccc}0 \\5 \\0 \end{array} \right] θ(1)=⎣⎡050⎦⎤ ,那么我们用 ( θ ( j ) ) T x ( i ) (\theta^{(j)})^Tx^{(i)} (θ(j))Tx(i) 即可计算出测第3部电影第1个用户可能评的分数。这里计算出是4.95。
-
数学化表示(目标优化)
已知各个电影在每一类的评分 x ( i ) x^{(i)} x(i),求用户对每部电影的打分 θ ( j ) \theta^{(j)} θ(j);为了对用户 j j j打分状况作出最精确的预测,我们需要:
min θ ( j ) = 1 2 ∑ i : r ( i , j ) = 1 ( ( θ ( j ) ) T ( x ( i ) ) − y ( i , j ) ) 2 + λ 2 ∑ k = 1 n ( θ k ( j ) ) 2 \min_{\theta^{(j)}}=\frac{1}{2}\sum_{i:r(i,j)=1}^{}{((\theta^{(j)})^T(x^{(i)})-y^{(i,j)})^2}+\frac{\lambda}{2}\sum_{k=1}^{n}{(\theta_k^{(j)})^2} θ(j)min=21i:r(i,j)=1∑((θ(j))T(x(i))−y(i,j))2+2λk=1∑n(θk(j))2在一般的线性回归模型中,误差项和正则项应该都是乘以 1 2 m \frac{1}{2m} 2m1,在这里我们将m去掉。并且我们不对方差项 θ 0 \theta_0 θ0进行正则化处理。
计算出所有的 θ \theta θ 为:
J ( θ ( 1 ) , ⋯ , θ ( n u ) ) = min ( θ ( 1 ) , ⋯ , θ ( n u ) ) = 1 2 ∑ j = 1 n u ∑ i : r ( i , j ) = 1 ( ( θ ( j ) ) T ( x ( i ) ) − y ( i , j ) ) 2 + λ 2 ∑ j = 1 n u ∑ k = 1 n ( θ k