词袋模型一些理解
一些定义
- visual word:定义“visual word”为ORB特征,描述子之间的匹配程度可以用汉明距离
- Vocabulary:“visual words”通过kmeans等方法建立一个树形字典“Vocabulary”,每一个叶子节点便是一个word。
- image database:由一棵词树(vocabulary tree)以及正向索引(direct index)和反向索引(inverse index)构成。
- visual word 检索方法:给定某一幅图像中的一个特征点,特征点从树形词典的根节点开始往走,依次与当前所在节点的子节点进行比较,选取汉明距离最小的节点作为中继节点,以此类推,直到所在节点为叶子节点。

建立字典
提取图片数据集的特征,用kmeans等方法建立一个字典树。
每一个节点包括(只列出了部分信息)
struct Node
{
//在所有节点中的标号
NodeId id;
//该节点的权重,该权重为训练的过程中设置的,在得到了树之后,
//将所有的描述子过一遍树,得到每个单词出现的次数,除以总的描述子数目
WordValue weight;
//描述符,为每一类的均值(对于brief描述子,则要对均值进行二值化)
TDescriptor descriptor;
//如果是叶节点,则有词汇的id
WordId word_id;
}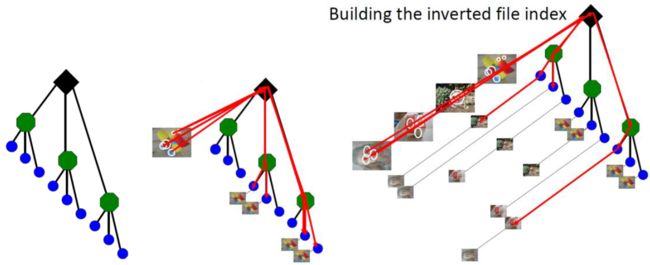
反向索引(inverse index)
叶子节点存储着图像list和权重。建好kmeans树后,对训练集中的每幅图像的每个特征点,根据visual word 的检索方法,检索到最为相似的叶子节点,叶子节点会存下这个特征点的数据(图像id和特征id,权重)。最后每个叶子节点里保存有一个list,包含一系列图像。实际运行时,当新的图像加入到图像数据库中的时候,反向索引就会更新。
反向索引用于提取与给定图像相似的图像,通过投票机制,选取候选者,而不需要计算与所有图像之间的相似度,加速搜索。

正向索引(direct index)
存储了每张图像的特征(如ORB特征)和它们关联的第l层的节点。
视觉字典中的节点是分层存储的,假如树一共有L层,从叶子开始为0层,即l=0,到根结束,l=Lw。
当反向索引得到了候选者(一个叶子节点)时,当前特征分别于候选者的图片list里的特征比较,利用orb特征匹配来选出最为相似的特征点。
正向索引也可以用于几何验证。

几何验证 (geometric verification)
验证几何一致性的关键在于利用RANSAC,通过在两帧图像上的12个点对应,找到一个基本矩阵。
建立点对应就需要寻找特征点的最近邻点,这时候就需要用到我们前面提到的direct index。要查找图像上的一个特征点,只需要在l层上该特征点所对应节点上寻找即可。l的值需要预先设定,l值设为零,那么就只能去叶节点找,找到的对应点很少。如果l值设置为根节点,相当于在所有节点中寻找,没有做任何优化。
权重计算
- 1.词频Term Frequency(TF):某个词在文章中出现的次数。为了归一化,词频也可以定义成,某个词在文章中出现的次数 / 文章的总词数。如果一个词比较少见,那么区分度就大。
- 2.逆向文件频率Inverse document frequency(IDF):需要一个语料库,来模拟语言的使用环境。IDF定义为,log(语料库的文档总数 / 包含该词的文档数 +1 )。如果一个词越常见,那么分母就越大,逆文档频率就越小,越接近0。
- 3.TF-IDF:词频(TF)* 逆向文件频率(IDF)。如果某个词比较少见,但是它在这篇文章中多次出现,那么它很可能就反映了这篇文章的特性,正是我们所需要的关键词。某个词对文章的重要性越高,它的TF-IDF值就越大。
在词典创建之后,可以算出IDF,他们的值不会随图像数据库中图像特征入口数量的变化而变化。在生成BoW向量时,可以计算TF。
DBoW3代码解读
DBoW3主要类
class BowVector //表示图像的单词向量 <Vector of words to represent image>
class FeatureVector //局部特征的向量 <Vector of nodes with indexes of local features>
class Database //图像数据库
class Descmanip //操作特征描述子(计算均值、差分、IO例程)
class QueryResults //检索图像数据库
class ScoringObject //计算两个向量间的值、计分
class Vocabulary //词典
class quicklz //快速数据压缩库用途
可以将一幅图像的特征点的描述算子,转换为DBoW的描述向量,与另外一直图片直接进行比较;也可以一直图片与一个词袋数据库进行比较,可以返回前几张最相似的图片。
回环检测。
ORB-SLAM里的用途
关键帧模型中的特征匹配
- 输入是当前帧和关键帧的特征点和关键帧的特征点
对于一般的匹配思路,是对两幅图像的特征点的描述子,用暴力匹配的方法算“最小距离”,非常耗时。关键帧模型匹配里,用词袋树来缩小匹配范围。
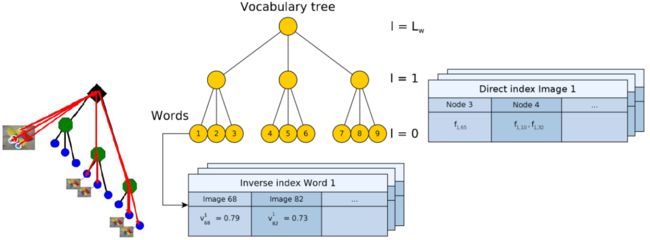
1.首先,将输入特征点的描述子转换为BoW向量。对于每一个特征点,用visual word 检索方法找到最为近似的叶子节点。最后一张图片就可以用BowVector和FeatureVector来描述,BowVector存着TF的值,FeatureVector存着某一指定层(第4层)每个node包含的特征点s。
class Frame
{
std::vectorstd ::vector<unsigned int> >2.FeatureVector相对于将特征点们分成了n(n等于第4层node的个数)个簇,每个簇都有id号,也就是NodeId。匹配时从关键帧中选择一个簇,从当前帧选择NodeId号一样的簇,对这两个簇里的特征点进行匹配,词袋模型就是这样子减少了匹配的范围。如果层数选择了根节点,相对于一幅图像只有一个簇,没有优化。
两个簇的特征点的匹配是暴力的逐个对比,算描述子之间的距离。对于关键帧中的每一个特征点,算出与当前帧特征点的描述子的距离,保存下最小距离和倒数第二小距离。成功匹配的要求是:最小距离小于一个误差阈值;最小距离比倒数第二小距离“明显”要小, 这个“明显”是一个参数。“明显”这个参数可以对一些重复出现的特征点(比如棋盘格这样子的特征点)匹配可以更鲁棒。
两个簇的匹配也有一些trick。每个特征点在提取描述子时的旋转主方向角度,如果图像旋转了,这个角度将发生改变,所有的特征点的角度变化应该是一致的,通过直方图统计(360/30)得到直方图中最大的三个index(一共12个),匹配点在这三个iindex中的会保留,其余匹配点会去掉。
回环检测
图片出处
- http://rpg.ifi.uzh.ch/teaching.html
- 论文 Bags of Binary Words for Fast Place Recognition in Image Sequences
参考
- 【泡泡机器人原创专栏】DBoW3 视觉词袋模型、视觉字典和图像数据库分析https://mp.weixin.qq.com/s?__biz=MzI5MTM1MTQwMw==&mid=2247487947&idx=1&sn=a161d5ba005adabbfef23ee823c3f34b&chksm=ec10afcfdb6726d9460e3992357b93a50fb622a805c785a9322d7cafb6f8d7d0b02494206fbd&mpshare=1&scene=1&srcid=0120tujPrzQBRJvOMRlHZuAr&pass_ticket=DyCv5iDYNGzqu%2FG5eHjGG4I5gZSFV%2B4a6kb08nDUOcc%3D#rd
- 浅谈回环检测中的词袋模型(bag of words)http://blog.csdn.net/qq_24893115/article/details/52629248