快速入门Lucene--只需3步--关键词搜索框架之Lucene
前言
我们团队目前在研究主题搜素引擎,在研究主题搜索引擎的时候就为了有个对比,就去简单了研究了一下lucene这个框架,然后从搭建到实现lucene的功能给大家分享一下
学习之中遇到的问题
-
首先是找不到对比文本,比如一段文字,怎么区分是哪个领域的,想过用json和map进行区分,而且当时找了很多教程都不知道他们用的实例文本是什么样子的。
- 查询的方式,Lucene之模糊、精确、匹配、范围、多条件查询等在实际上怎么运用的,这个文章我是在:https://www.cnblogs.com/fan-yuan/p/9228822.html这上面搞懂的
第一步:导入需要的jar包
- lucen-core-7.1 lucene的核心代码
- lucene-analyzers-common-7.1 lucene的分词工具
- lucene-queryparser-7.1 QueryParser能够根据用户的输入来进行解析
- lucene-highlighter-7.1 lucene查询结果进行高亮显示
- 还可以添加自己需要的,比如我需要对文本进行一个json的解析我就需要添加一个alibaba的用于json解析
com.alibaba
fastjson
1.2.61
第二步:创建索引
创建索引前需要准备你需要进行查询的句子,比如我这边准备了10000个文本进行创建索引,1000个与内容相关的文本和9000多个与内容不相关的文本,然后进行查询,得到查询到的查准率和查全率,与主题搜索进行一个对比。
具体内容就是一个json的字符串,有id和content,id是为了判断是在哪个范围。content当然就是存放文本。

然后我们先创建一个类,来负责创建索引
import org.apache.commons.io.FileUtils;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import sun.reflect.misc.FieldUtil;
import java.io.File;
import java.io.FileReader;
import java.nio.file.Paths;
import java.io.FileInputStream;
public class Indexer {
private IndexWriter writer;
//实例化indexwrite
public Indexer(String indexDir) throws Exception{
Directory dir= FSDirectory.open(Paths.get(indexDir));
Analyzer analyzer=new StandardAnalyzer();
IndexWriterConfig iwc=new IndexWriterConfig(analyzer);
writer=new IndexWriter(dir,iwc);
}
//关闭索引
public void close() throws Exception{
writer.close();
}
//索引目录的所有文件
public int index(String dataDir) throws Exception{
File []files=new File(dataDir).listFiles();
for(File f:files){
indexFile(f);
}
return writer.numDocs();
}
//索引指定文件
private void indexFile(File f) throws Exception{
System.out.println("索引文件:"+f.getCanonicalPath());
Document doc=getDocument(f);
writer.addDocument(doc);
}
//获取文档
private Document getDocument(File f) throws Exception{
Document doc=new Document();
//尝试保存内容
doc.add(new TextField("contents",FileUtils.readFileToString(f), Field.Store.YES));
doc.add(new TextField("fileName",f.getName(), Field.Store.YES));
doc.add(new TextField("fullPath",f.getCanonicalPath(),Field.Store.YES));
return doc;
}
public static void main(String[] args) {
String indexDir="D:\\jc\\Myself\\app\\demo\\kk2";//你索引后文件保存的目录
String dataDir="D:\\jc\\Myself\\app\\demo\\File";//你存放文件的目录
Indexer indexer=null;
int numIndexed=0;
long start =System.currentTimeMillis();
try{
indexer=new Indexer(indexDir);
numIndexed=indexer.index(dataDir);
} catch (Exception e) {
e.printStackTrace();
}finally {
try {
indexer.close();
}catch (Exception e){
e.printStackTrace();
}
}
long end=System.currentTimeMillis();
System.out.println("索引:"+numIndexed+"个文件 花费了"+(end-start)+"毫秒");
}
}
这里没得讲的,看main函数就不难看出,首先就是创建索引,然后让我们的lucene-analyzers分词小助手去进行分词,其实这个过程就像新华字典的工作人员,把每个汉字进行排序,ABCD。。这样分下去,让用的很容易查到自己需要的那个字,你只需要知道这个过程就行了,上面代码只需要你把路径改一下就可以了,运行后索引文件就保存到KK的文件下面了

第二步:创建查询类,实现查询到刚刚创建好的索引文件找到需要的文件
首先代码附上
package cn.cigit.contextquery.servlet;
import cn.cigit.contextquery.beans.lucenes;
import com.alibaba.fastjson.JSONObject;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.*;
import org.apache.lucene.search.highlight.Highlighter;
import org.apache.lucene.search.highlight.QueryScorer;
import org.apache.lucene.search.highlight.SimpleFragmenter;
import org.apache.lucene.search.highlight.SimpleHTMLFormatter;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import java.io.StringReader;
import java.nio.file.Paths;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class Searcher {
public Map search(String indexDir,String q) throws Exception{
Map NumOF=new HashMap<>();
List lucenes=new ArrayList<>();
/// 第一步:创建一个Directory对象,也就是索引库存放的位置。
Directory dir= FSDirectory.open(Paths.get(indexDir));
// 第二步:创建一个indexReader对象,需要指定Directory对象。
IndexReader reader= DirectoryReader.open(dir);
// 第三步:创建一个indexsearcher对象,需要指定IndexReader对象
IndexSearcher is=new IndexSearcher(reader);
//创建标准的分词器
Analyzer analyzer=new StandardAnalyzer();
//Queryparser 万能查询(上面的都可以用这个来查询到)
QueryParser parser=new QueryParser("contents",analyzer);
Query query=parser.parse(q);
long start =System.currentTimeMillis();
//第五步:执行查询。
TopDocs hits=is.search(query,10);
long end =System.currentTimeMillis();
System.out.println("匹配:"+q+",总花费:"+(end-start)+"毫秒,"+"查询到"+hits.totalHits+"个记录");
//查到文件的数量
long docSize=hits.totalHits;
//与内容相关的文件数量
int likeDoc = 0;
//与内容无关的文件数量
int notLikeDoc=0;
// 第六步:返回查询结果。遍历查询结果并输出
for(ScoreDoc scoreDoc:hits.scoreDocs){
lucenes kk=new lucenes();
int docID=scoreDoc.doc;
Document doc=is.doc(scoreDoc.doc);
System.out.println("============="+doc.get("fileName")+"=============");
System.out.println("文件路径:"+doc.get("fullPath"));
kk.setPath(doc.get("fullPath"));
JSONObject jsonObject=JSONObject.parseObject(doc.get("contents"));
kk.setContent((String) jsonObject.get("content"));
System.out.println("文件内容:"+jsonObject.get("content"));
Explanation explanation=is.explain(query,docID);
System.out.println("结果评分:"+explanation.getValue());
kk.setValue(String.valueOf(explanation.getValue()));
String text=doc.get("contents");
SimpleHTMLFormatter simpleHTMLFormatter=new SimpleHTMLFormatter("", "");
Highlighter highlighter=new Highlighter(simpleHTMLFormatter,new QueryScorer(query));
highlighter.setTextFragmenter(new SimpleFragmenter(text.length()));
if(text!=null){
TokenStream tokenStream=analyzer.tokenStream("contents",new StringReader(text));
String high=highlighter.getBestFragment(tokenStream,text);
JSONObject jsonObject2=JSONObject.parseObject(high);
System.out.println("高亮显示"+jsonObject2.get("content"));
kk.setHighContent((String) jsonObject2.get("content"));
}
String[] ids=jsonObject.getString("id").split("other");
if(ids.length>1) {
//与1000疾病文档不相关的文档
notLikeDoc++;
}else{
if(jsonObject.getInteger("id")>=1&&jsonObject.getInteger("id")<=100){
likeDoc++;
}
}
lucenes.add(kk);
}
//创建返回结果的情况
Map num=new HashMap<>();
num.put("likeDoc",String.valueOf(likeDoc));
num.put("docSize",String.valueOf(docSize));
num.put("notLikeDoc",String.valueOf(notLikeDoc));
num.put("recallRate",String.format("%.6f", likeDoc/10612.0));
num.put("Accuracy",String.format("%.6f", likeDoc/(docSize*1.0)));
num.put("text",q);
System.out.println("========================================================");
System.out.println("查到与本病相关的个数:"+likeDoc);
System.out.println("查到总的文件个数:"+docSize);
System.out.println("与1000疾病文件不相关的查到有:"+notLikeDoc+"个");
System.out.println("查全率:"+String.format("%.6f", likeDoc/10612.0));
System.out.println("查准率:"+String.format("%.6f", likeDoc/(docSize*1.0)));
System.out.println("========================================================");
reader.close();
NumOF.put("lucene",lucenes);
NumOF.put("num",num);
return NumOF;
}
}
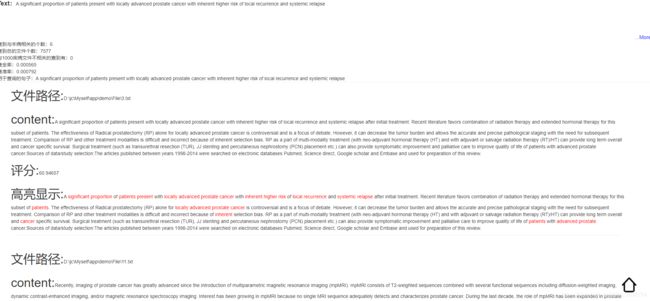
上面的代码就是一个查询,接收一个字符串然后在索引文件去查询结果,只需要取前面十条,然后对这10条进行一个内容的提取,通过json去解析,然后就能得到id和content,通过id是在哪个范围就能知道该查询的内容是哪个病的,然后进行记录,然后在进行一个查全率和查准率的计算,用一个map集合去装就可以得到数据和需要返回的内容。
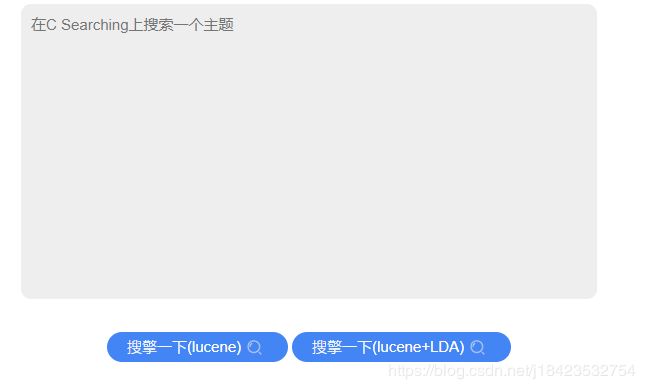
讲到这里我们目前做的是一个web项目,进行一个用户的输入就是可以实现lucene的查询结果返回展示,有两个搜索方式一个是纯Lucene和lucene加IDA的方式,什么是LDA,是一个工具,可以把一个句子拆分几个关键字,然后在进行lucene的查询,如果需要深入了解的小伙伴可以加我微信:y958231955,一起讨论
当然我们做后端只需要把功能写出来,其他的交给美工吧,哈哈,今天就写到这里了
结语
上诉用到jar包,如果不会下的,可以关注微信公众号:程序员PG
回复:lucene
里面还有10个示例文本,可以去体验这个过程,相信你一定会早点完成学习和工作
一切关于程序和生活的问题也可以找我一起交流学习
微信:y958231955
今日头条:超厂长