Spark:Shuffle原理剖析与源码分析
spark中的Shuffle是非常重要的,shuffle不管在Hadoop中还是Spark中都是重重之重,特别是在Spark shuffle优化的时间。更是非常的重要。
普通shuffle操作的原理剖析(spark 2.x弃用)
每一个Job提交后都会生成一个ResultStage和若干个ShuffleMapStage,其中ResultStage表示生成作业的最终结果所在的Stage;ResultStage的task分别对应着ResultTask,ShuffleMapStage的task分别对应着ShuffleMapTask。

- 每一个ShufflleMapTask会为每一个ReduceTask创建一个bucket缓存,并且会为每一个bucket创建一个文件。这个bucket存放的数据就是经过Partitioner操作(默认是HashPartitioner)之后找到对应的bucket然后放进去,最后将数据刷新bucket缓存的数据到磁盘上,即对应的block file。
- ShuffleMapTask刷新到磁盘中的数据信息会封装在MapStatus中,发送到Driver的DAGScheduler的MapOutputTracker中,每一个MapStatus包含了每一个ResultTask要拉取的数据的位置和大小。
- 而每一个ResultTask会用BlockStoreShuffleFetcher向MapOutputTrackerMaster获取MapStatus,看哪一份数据是属于自己的,然后底层通过BlockManager将数据拉取过来。
- 将数据拉取过来之后,会将这些数据组成一个RDD,即ShuffleRDD,优先存入内存当中,其次再写入磁盘中。然后每一个ResultTask针对这些RDD数据执行自己的聚合操作或者算子函数生成MapPartitionRDD。
以上就是普通Shuffle操作的执行原理,从上图我们可以发现一个问题,每一个ShuffleMapTask都需要为每一个ResultTask生成一个文件和bucket缓存,假设有100个ShuffleMapTask,100个ResultTask,那么就需要总共生成10000个文件,此时会有大量的磁盘IO操作,严重的影响shuffle的性能。
第一个特点:
在Spark早期版本中,那个bucket缓存是非常非常重要的,因为需要将一个ShuffleMapTask所有的数据都写入内存缓存之后,才会刷新到磁盘。但是这就有一个问题,如果map side数据过多,那么很容易造成内存溢出。所以spark在新版本中,优化了,默认那个内存缓存是100kb,然后呢,写入一点数据达到了刷新到磁盘的阈值之后,就会将数据一点一点地刷新到磁盘。
这种操作的优点,是不容易发生内存溢出。缺点在于,如果内存缓存过小的话,那么可能发生过多的磁盘写io操作。所以,这里的内存缓存大小,是可以根据实际的业务情况进行优化的。
第二个特点:
与MapReduce完全不一样的是,MapReduce它必须将所有的数据都写入本地磁盘文件以后,才能启动reduce操作,来拉取数据。为什么?因为mapreduce要实现默认的根据key的排序!所以要排序,肯定得写完所有数据,才能排序,然后reduce来拉取。
但是Spark不需要,spark默认情况下,是不会对数据进行排序的。因此ShuffleMapTask每写入一点数据,ResultTask就可以拉取一点数据,然后在本地执行我们定义的聚合函数和算子,进行计算。
spark这种机制的好处在于,速度比mapreduce快多了。但是也有一个问题,mapreduce提供的reduce,是可以处理每个key对应的value上的,很方便。但是spark中,由于这种实时拉取的机制,因此提供不了,直接处理key对应的values的算子,只能通过groupByKey,先shuffle,有一个MapPartitionsRDD,然后用map算子,来处理每个key对应的values。就没有mapreduce的计算模型那么方便。
优化后的shuffle操作原理剖析
在Spark新版本中,引入了consolidation机制,也就说,提出了ShuffleGroup概念。假设我们的服务器上有两个CPU cores,运行着4个ShuffleMapTask,优化后的Shuffle操作原理如下图:

在之前的版本中,当前并行执行的一批ShuffleMapTask执行完毕之后执行下一批时会重新生成bucket缓存,而且在刷新到磁盘上的时候也会重新生成ShuffleBlockFile。但是在优化后的Shuffle操作中它不会重新生成缓存和磁盘文件,而是将数据写入之前的缓存和磁盘文件中,即合并了多个ShuffleMpaTask产生的文件,这也叫做consolidation机制。在多个ShuffleMapTask合并产生的文件称为一组ShuffleGroup,里面存储了多个ShuffleMapTask的数据,每个ShuffleMapTask的数据称为一个segment,此外还会通过一些索引来标识每个ShuffleMapTask在ShuffleBlockFile中的位置以及偏移量,来进行区分不同的ShuffleMapTask产生的数据。
优化参数的设置只需在SparkConf中设置即可,即设置spark.shuffle.consolidateFiles参数为true即可,可以看出来,在优化后的shuffle操作,它产生的磁盘文件是cpu core数量*ResultTask的数量,比如这里假设了2个cpu core,有100个ResultTask,因此会产生200个磁盘文件,相比之前没有优化的Shuffle操作,减少了20倍的磁盘文件,对系统的性能有很大的提升。
SortShuffleManager原理剖析
SortShuffleManager的运行机制主要分成两种,一种是普通运行机制,另一种是bypass运行机制。当shuffle read task的数量小于等于spark.shuffle.sort.bypassMergeThreshold参数的值时(默认为200),就会启用bypass机制。
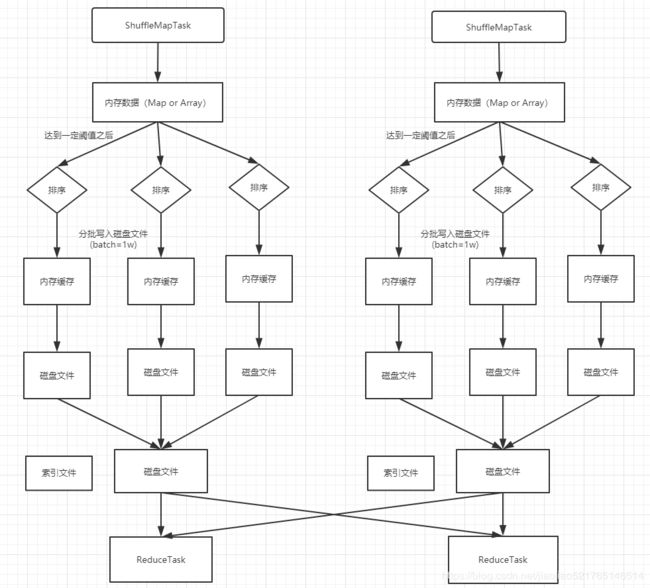
上图说明了普通的SortShuffleManager的原理。在该模式下,数据会先写入一个内存数据结构中,此时根据不同的shuffle算子,可能选用不同的数据结构。如果是reduceByKey这种聚合类的shuffle算子,那么会选用Map数据结构,一边通过Map进行聚合,一边写入内存;如果是join这种普通的shuffle算子,那么会选用Array数据结构,直接写入内存。接着,每写一条数据进入内存数据结构之后,就会判断一下,是否达到了某个临界阈值。如果达到临界阈值的话,那么就会尝试将内存数据结构中的数据溢写到磁盘,然后清空内存数据结构。
在溢写到磁盘文件之前,会先根据key对内存数据结构中已有的数据进行排序。排序过后,会分批将数据写入磁盘文件。默认的batch数量是10000条,也就是说,排序好的数据,会以每批1万条数据的形式分批写入磁盘文件。写入磁盘文件是通过Java的BufferedOutputStream实现的。BufferedOutputStream是Java的缓冲输出流,首先会将数据缓冲在内存中,当内存缓冲满溢之后再一次写入磁盘文件中,这样可以减少磁盘IO次数,提升性能。
一个task将所有数据写入内存数据结构的过程中,会发生多次磁盘溢写操作,也就会产生多个临时文件。最后会将之前所有的临时磁盘文件都进行合并,这就是merge过程,此时会将之前所有临时磁盘文件中的数据读取出来,然后依次写入最终的磁盘文件之中。此外,由于一个task就只对应一个磁盘文件,也就意味着该task为下游stage的task准备的数据都在这一个文件中,因此还会单独写一份索引文件,其中标识了下游各个task的数据在文件中的start offset与end offset。
SortShuffleManager由于有一个磁盘文件merge的过程,因此大大减少了文件数量。比如第一个stage有50个task,总共有10个Executor,每个Executor执行5个task,而第二个stage有100个task。由于每个task最终只有一个磁盘文件,因此此时每个Executor上只有5个磁盘文件,所有Executor只有50个磁盘文件(磁盘文件数量 = 上游stage的task数量)。
bypass运行机制
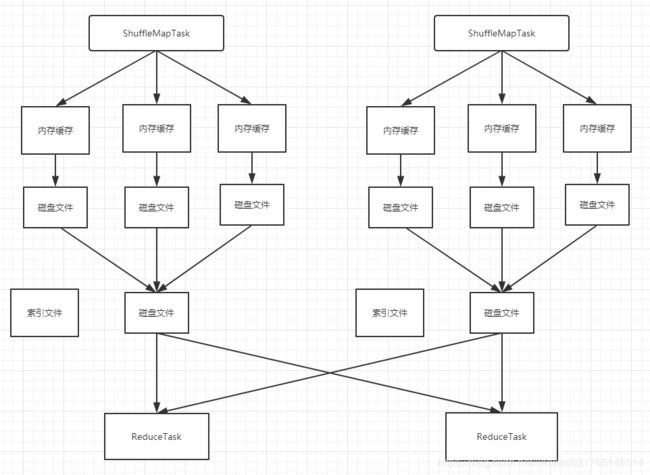
上图说明了bypass SortShuffleManager的原理。bypass运行机制的触发条件如下:
- shuffle map task数量小于spark.shuffle.sort.bypassMergeThreshold参数的值。
- 不是聚合类的shuffle算子(比如reduceByKey)。
此时task会为每个下游task都创建一个临时磁盘文件,并将数据按key进行hash然后根据key的hash值,将key写入对应的磁盘文件之中。当然,写入磁盘文件时也是先写入内存缓冲,缓冲写满之后再溢写到磁盘文件的。最后,同样会将所有临时磁盘文件都合并成一个磁盘文件,并创建一个单独的索引文件。
该过程的磁盘写机制其实跟未经优化的HashShuffleManager是一模一样的,因为都要创建数量惊人的磁盘文件,只是在最后会做一个磁盘文件的合并而已。因此少量的最终磁盘文件,也让该机制相对未经优化的HashShuffleManager来说,shuffle read的性能会更好。
而该机制与普通SortShuffleManager运行机制的不同在于:第一,磁盘写机制不同;第二,不会进行排序。也就是说,启用该机制的最大好处在于,shuffle write过程中,不需要进行数据的排序操作,也就节省掉了这部分的性能开销。
Sort-BasedShuffle写机制源码分析:
第一步:ShuffleMapTask 的 runTask方法
源码地址:org.apache.spark.scheduler.ShuffleMapTask.scala
/**
* ShuffleMapTask的 runTask 有 MapStatus返回值
*/
override def runTask(context: TaskContext): MapStatus = {
// Deserialize the RDD using the broadcast variable.
val threadMXBean = ManagementFactory.getThreadMXBean
val deserializeStartTime = System.currentTimeMillis()
val deserializeStartCpuTime = if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime
} else 0L
//对task要处理的数据,做反序列化操作
/**
* 多个task在executor中并发运行,数据可能都不在一台机器上,一个stage处理的rdd都是一样的task怎么拿到自己要处理的数据的?
* 答案:通过broadcast value 广播变量获取
*/
val ser = SparkEnv.get.closureSerializer.newInstance()
val (rdd, dep) = ser.deserialize[(RDD[_], ShuffleDependency[_, _, _])](
ByteBuffer.wrap(taskBinary.value), Thread.currentThread.getContextClassLoader)
_executorDeserializeTime = System.currentTimeMillis() - deserializeStartTime
_executorDeserializeCpuTime = if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime - deserializeStartCpuTime
} else 0L
var writer: ShuffleWriter[Any, Any] = null
try {
// 获取ShuffleManager
val manager = SparkEnv.get.shuffleManager
// 从ShuffleManager中获取ShuffleWriter
//启动的partitionId表示的是当前RDD的某个partition,也就是说write操作作用于partition之上
writer = manager.getWriter[Any, Any](dep.shuffleHandle, partitionId, context)
/**
* 首先调用了,rdd的iterator()方法,并且传入了,当前task要处理哪个partition
* 所以核心的逻辑,就在rdd的iterator()方法中,在这里,实现了针对rdd的某个partition,执行我们自己定义的算子,或者是函数
* 执行完了我们自己定义的算子、或者函数,就相当于是,针对rdd的partition执行了处理,会有返回的数据
* 返回的数据,都是通过ShuffleWriter,经过HashPartitioner进行分区之后,写入自己对应的分区bucket
*/
writer.write(rdd.iterator(partition, context).asInstanceOf[Iterator[_ <: Product2[Any, Any]]])
/**
* 最后,返回结果MapStatus,MapStatus里面封装了ShuffleMapTask计算后的数据,数据存储在哪里,其实就是BlockManager的相关信息
* BlockManager是Spark底层的内存,数据,磁盘数据管理的组件
*/
writer.stop(success = true).get
} catch {
case e: Exception =>
try {
if (writer != null) {
writer.stop(success = false)
}
} catch {
case e: Exception =>
log.debug("Could not stop writer", e)
}
throw e
}
}
第二步:SparkEnv.get.shuffleManager获取SortSuffleManager实例
// Let the user specify short names for shuffle managers
//在Spark2.X版本中只有 SortShuffleManager,已经没有了 Hash-Based Shuffle Manager 了
// Shuffle的配置信息,默认使用的是SortShuffleManager
val shortShuffleMgrNames = Map(
"sort" -> classOf[org.apache.spark.shuffle.sort.SortShuffleManager].getName,
"tungsten-sort" -> classOf[org.apache.spark.shuffle.sort.SortShuffleManager].getName)
val shuffleMgrName = conf.get("spark.shuffle.manager", "sort")
val shuffleMgrClass =
shortShuffleMgrNames.getOrElse(shuffleMgrName.toLowerCase(Locale.ROOT), shuffleMgrName)
//通过反射的获取的shuffleManager,就是SortShuffleManager
val shuffleManager = instantiateClass[ShuffleManager](shuffleMgrClass)
第三步: 根据ShuffleManager获取writer,dep.shuffleHandle方法
val shuffleHandle: ShuffleHandle = _rdd.context.env.shuffleManager.registerShuffle(
shuffleId, _rdd.partitions.length, this)
第四步: shuffleManager.registerShuffle方法(SortShuffleManager.registerShuffle方法)
/**
* Obtains a [[ShuffleHandle]] to pass to tasks.
* ShuffleManager会根据注册的handle来决定实例化哪一个writer。
* 如果注册的是SerializedShuffleHandle,就获取UnsafeShuffleWriter;
* 如果注册的是BypassMergeSortShuffleHandle,就获取BypassMergeSortShuffleWriter;
* 如果注册的是BaseShuffleHandle,就获取SortShuffleWriter
*/
override def registerShuffle[K, V, C](
shuffleId: Int,
numMaps: Int,
dependency: ShuffleDependency[K, V, C]): ShuffleHandle = {
// 如果满足使用BypassMergeSort,就优先使用BypassMergeSortShuffleHandle
if (SortShuffleWriter.shouldBypassMergeSort(conf, dependency)) {
// If there are fewer than spark.shuffle.sort.bypassMergeThreshold partitions and we don't
// need map-side aggregation, then write numPartitions files directly and just concatenate
// them at the end. This avoids doing serialization and deserialization twice to merge
// together the spilled files, which would happen with the normal code path. The downside is
// having multiple files open at a time and thus more memory allocated to buffers.
new BypassMergeSortShuffleHandle[K, V](
shuffleId, numMaps, dependency.asInstanceOf[ShuffleDependency[K, V, V]])
} else if (SortShuffleManager.canUseSerializedShuffle(dependency)) {
// Otherwise, try to buffer map outputs in a serialized form, since this is more efficient:
// 如果支持序列化模式,则使用SerializedShuffleHandle
new SerializedShuffleHandle[K, V](
shuffleId, numMaps, dependency.asInstanceOf[ShuffleDependency[K, V, V]])
} else {
// Otherwise, buffer map outputs in a deserialized form:
// 否则使用BaseShuffleHandle
new BaseShuffleHandle(shuffleId, numMaps, dependency)
}
}
第五步:shouldBypassMergeSort这个方法,判断是否应该使用BypassMergeSort
private[spark] object SortShuffleWriter {
/**
* 1.不能指定aggregator,即不能聚合
* 2.不能指定ordering,即分区内数据不能排序
* 3.分区的数目 <= spark.shuffle.sort.bypassMergeThrshold指定的阀值
*/
def shouldBypassMergeSort(conf: SparkConf, dep: ShuffleDependency[_, _, _]): Boolean = {
// We cannot bypass sorting if we need to do map-side aggregation.
if (dep.mapSideCombine) {
false
} else {
val bypassMergeThreshold: Int = conf.getInt("spark.shuffle.sort.bypassMergeThreshold", 200)
dep.partitioner.numPartitions <= bypassMergeThreshold
}
}
}
第六步: canUseSerializedShuffle函数,来确定是否使用Tungsten-Sort支持的序列化模式SerializedShuffleHandle
/**
* Helper method for determining whether a shuffle should use an optimized serialized shuffle
* path or whether it should fall back to the original path that operates on deserialized objects.
*
* 1.shuffle依赖不带有聚合操作
* 2.支持序列化值的重新定位
* 3.分区数量少于16777216个
*
*/
def canUseSerializedShuffle(dependency: ShuffleDependency[_, _, _]): Boolean = {
val shufId = dependency.shuffleId
// 获取分区数
val numPartitions = dependency.partitioner.numPartitions
// 如果不支持序列化值的重新定位
if (!dependency.serializer.supportsRelocationOfSerializedObjects) {
log.debug(s"Can't use serialized shuffle for shuffle $shufId because the serializer, " +
s"${dependency.serializer.getClass.getName}, does not support object relocation")
false
// 如果定义聚合器
} else if (dependency.mapSideCombine) {
log.debug(s"Can't use serialized shuffle for shuffle $shufId because we need to do " +
s"map-side aggregation")
false
// 如果分区数量大于16777216个
} else if (numPartitions > MAX_SHUFFLE_OUTPUT_PARTITIONS_FOR_SERIALIZED_MODE) {
log.debug(s"Can't use serialized shuffle for shuffle $shufId because it has more than " +
s"$MAX_SHUFFLE_OUTPUT_PARTITIONS_FOR_SERIALIZED_MODE partitions")
false
} else {
log.debug(s"Can use serialized shuffle for shuffle $shufId")
true
}
}
}
第七步:SortShuffleManager类中getWriter()方法
override def getWriter[K, V](
handle: ShuffleHandle,
mapId: Int,
context: TaskContext): ShuffleWriter[K, V] = {
numMapsForShuffle.putIfAbsent(
handle.shuffleId, handle.asInstanceOf[BaseShuffleHandle[_, _, _]].numMaps)
val env = SparkEnv.get
handle match {
// 如果使用SerializedShuffleHandle则获取UnsafeShuffleWriter
case unsafeShuffleHandle: SerializedShuffleHandle[K @unchecked, V @unchecked] =>
new UnsafeShuffleWriter(
env.blockManager,
shuffleBlockResolver.asInstanceOf[IndexShuffleBlockResolver],
context.taskMemoryManager(),
unsafeShuffleHandle,
mapId,
context,
env.conf)
// 如果使用BypassMergeSortShuffleHandle则获取BypassMergeSortShuffleWriter
case bypassMergeSortHandle: BypassMergeSortShuffleHandle[K @unchecked, V @unchecked] =>
new BypassMergeSortShuffleWriter(
env.blockManager,
shuffleBlockResolver.asInstanceOf[IndexShuffleBlockResolver],
bypassMergeSortHandle,
mapId,
context,
env.conf)
// 如果使用BaseShuffleHandle则获取SortShuffleWriter
case other: BaseShuffleHandle[K @unchecked, V @unchecked, _] =>
new SortShuffleWriter(shuffleBlockResolver, other, mapId, context)
}
}
第七步:BypassMergeSortShuffleWrite的写机制分析
实现带Hash风格的基于Sort的Shuffle机制。在Reducer端任务数比较少的情况下,基于Hash的Shuffle实现机制明显比Sort的Shuffle实现快。所以基于Sort的Shuffle实现机制提供一个方案,当Reducer任务数少于配置的属性spark.shuffle.sort.bypassMergeThreshold设置的个数的时候,则使用此种方案。

特点:
- 主要用于处理不需要排序和聚合的Shuffle操作,所以数据是直接写入文件,数据量较大的时候,网络I/O和内存负担较重
- 主要适合处理Reducer任务数量比较少的情况下
- 将每一个分区写入一个单独的文件,最后将这些文件合并,减少文件数量;但是这种方式需要并发打开多个文件,对内存消耗比较大
源码分析:org.apache.spark.shuffle.sort.BypassMergeSortShuffleWriter.java
/**
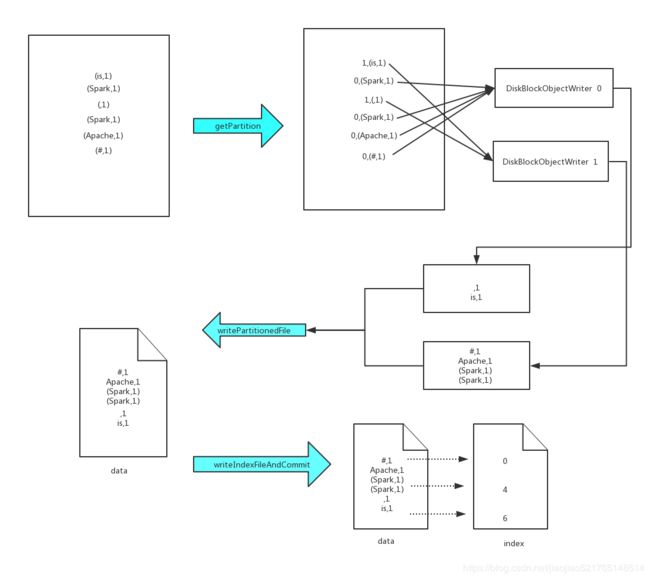
* 基于BypassMergeSortShuffleWriter的机制:
* 1.首先确定ShuffleMapTask的结果应该分为几个分区,并且为每一个分区创建一个DiskBlockObjectWriter和临时文件
* 2.将每一个ShuffleMapTask的结果通过Partitioner进行分区,写入对应分区的临时文件。
* 3.将分区刷到磁盘文件,并且创建每一个分区文件对应的FileSegment数组
* 4.根据shuffleId和mapId,构建ShuffleDataBlockId,创建合并文件data和合并文件的临时文件,文件格式为:shuffle_{shuffleId}_{mapId}_{reduceId}.data
* 5.将每一个分区对应的文件的数据合并到合并文件的临时文件,并且返回一个每一个分区对应的文件长度的数组
* 6.创建索引文件index和索引临时文件,每一个分区的长度和offset写入索引文件等;并且重命名临时data文件和临时index文件
* 7.将一些信息封装到MapStatus返回
*/
@Override
public void write(Iterator> records) throws IOException {
assert (partitionWriters == null);
if (!records.hasNext()) {
partitionLengths = new long[numPartitions];
shuffleBlockResolver.writeIndexFileAndCommit(shuffleId, mapId, partitionLengths, null);
mapStatus = MapStatus$.MODULE$.apply(blockManager.shuffleServerId(), partitionLengths);
return;
}
final SerializerInstance serInstance = serializer.newInstance();
final long openStartTime = System.nanoTime();
/**
* 构建一个对于task结果进行分区的数量的writer数组,即每一个分区对应着一个write
* 这种写入方式,会同时打开numPartition个writer,所以分区数不宜设置过大
* 避免带来过重的内存开销。现在默认writer的缓存大小是32k,比起以前100k小太多了
*/
partitionWriters = new DiskBlockObjectWriter[numPartitions];
// 构建一个对于task结果进行分区的数量的FileSegment数组,寄一个分区的writer对应着一组FileSegment
partitionWriterSegments = new FileSegment[numPartitions];
for (int i = 0; i < numPartitions; i++) {
// 创建临时的shuffle block,返回一个(shuffle blockid,file)的元组
final Tuple2 tempShuffleBlockIdPlusFile = blockManager.diskBlockManager().createTempShuffleBlock();
// 获取该分区对应的文件
final File file = tempShuffleBlockIdPlusFile._2();
// 获取该分区对应的blockId
final BlockId blockId = tempShuffleBlockIdPlusFile._1();
// 构造每一个分区的writer
partitionWriters[i] = blockManager.getDiskWriter(blockId, file, serInstance, fileBufferSize, writeMetrics);
}
// Creating the file to write to and creating a disk writer both involve
// interacting with
// the disk, and can take a long time in aggregate when we open many files, so
// should be
// included in the shuffle write time.
writeMetrics.incWriteTime(System.nanoTime() - openStartTime);
// 如果有数据,获取数据,对key进行分区,然后将写入该分区对应的文件
while (records.hasNext()) {
final Product2 record = records.next();
final K key = record._1();
partitionWriters[partitioner.getPartition(key)].write(key, record._2());
}
// 遍历所有分区的writer列表,刷新数据到文件,构建FileSegment数组
for (int i = 0; i < numPartitions; i++) {
final DiskBlockObjectWriter writer = partitionWriters[i];
// 把数据刷到磁盘,构建一个FileSegment
partitionWriterSegments[i] = writer.commitAndGet();
writer.close();
}
// 根据shuffleId和mapId,构建ShuffleDataBlockId,创建文件,文件格式为:shuffle_{shuffleId}_{mapId}_{reduceId}.data
File output = shuffleBlockResolver.getDataFile(shuffleId, mapId);
// 创建临时文件
File tmp = Utils.tempFileWith(output);
try {
// 合并前面的生成的各个中间临时文件,并获取分区对应的数据大小,然后就可以计算偏移量
partitionLengths = writePartitionedFile(tmp);
// 创建索引文件,将每一个分区的起始位置、结束位置和偏移量写入索引,且将合并的data文件临时文件重命名,索引文件的临时文件重命名
shuffleBlockResolver.writeIndexFileAndCommit(shuffleId, mapId, partitionLengths, tmp);
} finally {
if (tmp.exists() && !tmp.delete()) {
logger.error("Error while deleting temp file {}", tmp.getAbsolutePath());
}
}
// 封装并返回任何结果
mapStatus = MapStatus$.MODULE$.apply(blockManager.shuffleServerId(), partitionLengths);
}
第八步:writePartitionedFile()方法
/**
* Concatenate all of the per-partition files into a single combined file.
* 聚合每一个分区文件为正式的Block文件
*
* @return array of lengths, in bytes, of each partition of the file (used by
* map output tracker).
*/
private long[] writePartitionedFile(File outputFile) throws IOException {
// Track location of the partition starts in the output file
// 构建一个分区数量的数组
final long[] lengths = new long[numPartitions];
if (partitionWriters == null) {
// We were passed an empty iterator
return lengths;
}
// 创建合并文件的临时文件输出流
final FileOutputStream out = new FileOutputStream(outputFile, true);
final long writeStartTime = System.nanoTime();
boolean threwException = true;
try {
// 进行分区文件的合并,返回每一个分区文件长度
for (int i = 0; i < numPartitions; i++) {
// 获取该分区对应的FileSegment对应的文件
final File file = partitionWriterSegments[i].file();
// 如果文件存在
if (file.exists()) {
final FileInputStream in = new FileInputStream(file);
boolean copyThrewException = true;
try {
// 把该文件拷贝到合并文件的临时文件,并返回文件长度
lengths[i] = Utils.copyStream(in, out, false, transferToEnabled);
copyThrewException = false;
} finally {
Closeables.close(in, copyThrewException);
}
if (!file.delete()) {
logger.error("Unable to delete file for partition {}", i);
}
}
}
threwException = false;
} finally {
Closeables.close(out, threwException);
writeMetrics.incWriteTime(System.nanoTime() - writeStartTime);
}
partitionWriters = null;
return lengths;
}
第九步:shuffleBlockResolver.writeIndexFileAndCommit()方法
源码地址:org.apache.spark.shuffle.IndexShuffleBlockResolver.scala
/**
* 用于在Block的索引文件中记录每个block的偏移量,其中getBlockData方法可以根据ShuffleId和mapId读取索引文件,
* 获得前面partition计算之后,将结果写入文件中的偏移量和结果的大小。
*/
def writeIndexFileAndCommit(
shuffleId: Int,
mapId: Int,
lengths: Array[Long],
dataTmp: File): Unit = {
// 获取索引文件
val indexFile = getIndexFile(shuffleId, mapId)
// 生成临时的索引文件
val indexTmp = Utils.tempFileWith(indexFile)
try {
// 获取数据文件
val dataFile = getDataFile(shuffleId, mapId)
// There is only one IndexShuffleBlockResolver per executor, this synchronization make sure
// the following check and rename are atomic.
synchronized {
// 传递进去的索引、数据文件以及每一个分区的文件的长度
val existingLengths = checkIndexAndDataFile(indexFile, dataFile, lengths.length)
if (existingLengths != null) {
// Another attempt for the same task has already written our map outputs successfully,
// so just use the existing partition lengths and delete our temporary map outputs.
System.arraycopy(existingLengths, 0, lengths, 0, lengths.length)
if (dataTmp != null && dataTmp.exists()) {
dataTmp.delete()
}
} else {
// This is the first successful attempt in writing the map outputs for this task,
// so override any existing index and data files with the ones we wrote.
val out = new DataOutputStream(new BufferedOutputStream(new FileOutputStream(indexTmp)))
Utils.tryWithSafeFinally {
// We take in lengths of each block, need to convert it to offsets.
// 将offset写入索引文件写入临时的索引文件
var offset = 0L
out.writeLong(offset)
for (length <- lengths) {
offset += length
out.writeLong(offset)
}
} {
out.close()
}
if (indexFile.exists()) {
indexFile.delete()
}
if (dataFile.exists()) {
dataFile.delete()
}
if (!indexTmp.renameTo(indexFile)) {
throw new IOException("fail to rename file " + indexTmp + " to " + indexFile)
}
if (dataTmp != null && dataTmp.exists() && !dataTmp.renameTo(dataFile)) {
throw new IOException("fail to rename file " + dataTmp + " to " + dataFile)
}
}
}
} finally {
if (indexTmp.exists() && !indexTmp.delete()) {
logError(s"Failed to delete temporary index file at ${indexTmp.getAbsolutePath}")
}
}
}
核心流程:
- 根据分区ID,为每一个分区创建DiskBlockObjectWriter
- 按照分区ID升序写入正式的Shuffle数据文件
- 通过writeIndexFileAndCommit建立MapTask输出的数据索引
第十步:SortShuffleWriter的写机制分析
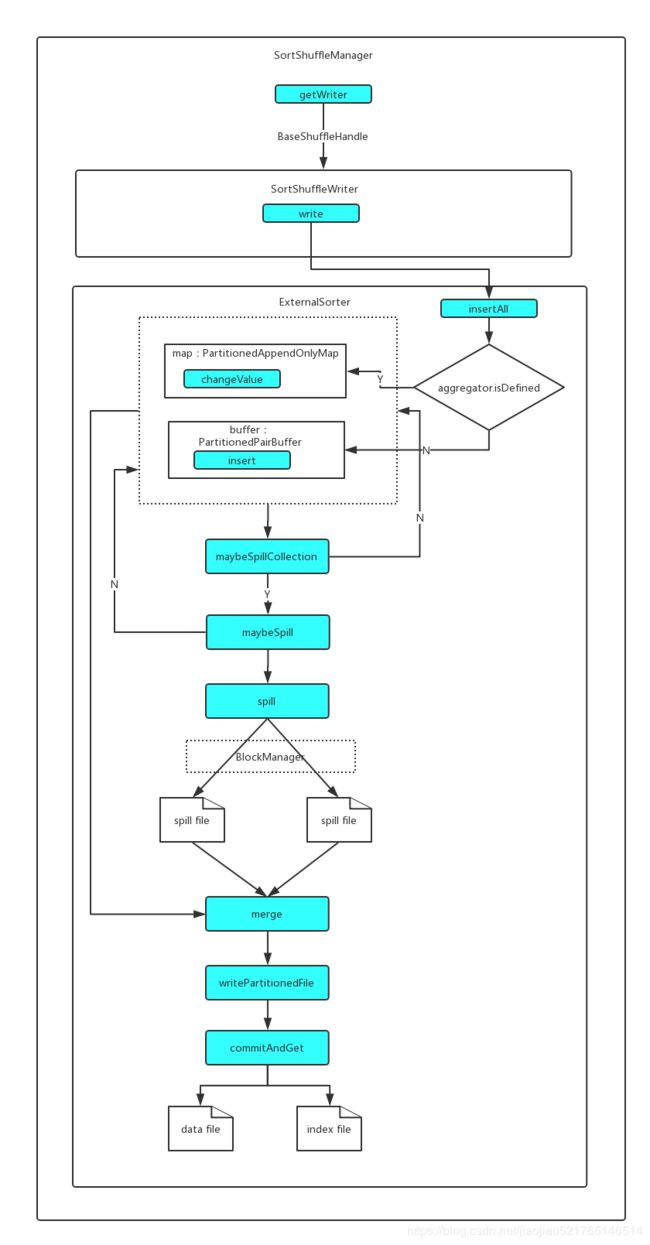
SortShuffleWriter它主要是判断在Map端是否需要本地进行combine操作。如果需要聚合,则使用PartitionedAppendOnlyMap;如果不进行combine操作,则使用PartitionedPairBuffer添加数据存放于内存中。然后无论哪一种情况都需要判断内存是否足够,如果内存不够而且又申请不到内存,则需要进行本地磁盘溢写操作,把相关的数据写入溢写到临时文件。最后把内存里的数据和磁盘溢写的临时文件的数据进行合并,如果需要则进行一次归并排序,如果没有发生溢写则是不需要归并排序,因为都在内存里。最后生成合并后的data文件和index文件。
源码分析:org.apache.spark.shuffle.sort.SortShuffleWriter.scala
/**
* 基于SortShuffleWriter的机制:
* 1.创建外部排序器ExternalSorter, 只是根据是否需要本地combine与否从而决定是否传入aggregator和keyOrdering参数
* 2.将写入数据全部放入外部排序器ExternalSorter,并且根据是否需要spill进行spill操作
* 3.创建data文件和临时的data文件,文件格式为'shuffle_{shuffleId}_{mapId}_{reducerId}.data' 先将数据写入临时data文件
* 4.创建index索引文件和临时index文件,写入每一个分区的offset以及length信息等,并且重命名data临时文件和index临时文件
* 5. 把部分信息封装到MapStatus返回
*/
override def write(records: Iterator[Product2[K, V]]): Unit = {
//是否map端需要在本地进行combine操作,如果需要,则需要传入aggregator和keyOrdering,创建ExternalSorter
//aggregator用于指示进行combiner的操作( keyOrdering用于传递key的排序规则);
sorter = if (dep.mapSideCombine) {
//当计算结果需要combine,则外部排序进行聚合
new ExternalSorter[K, V, C](
context, dep.aggregator, Some(dep.partitioner), dep.keyOrdering, dep.serializer)
} else {
// In this case we pass neither an aggregator nor an ordering to the sorter, because we don't
// care whether the keys get sorted in each partition; that will be done on the reduce side
// if the operation being run is sortByKey.
//如果不需要在本地进行combine操作, 就不需要aggregator和keyOrdering,那么本地每个分区的数据不会做聚合和排序
new ExternalSorter[K, V, V](
context, aggregator = None, Some(dep.partitioner), ordering = None, dep.serializer)
}
/**
* 根据排序方式,对数据进行排序并写入内存缓冲区。
* 若排序中计算结果超出的阈值,则将其溢写到磁盘数据文件
*/
sorter.insertAll(records)
// Don't bother including the time to open the merged output file in the shuffle write time,
// because it just opens a single file, so is typically too fast to measure accurately
// (see SPARK-3570).
// 创建data文件,文件格式为'shuffle_{shuffleId}_{mapId}_{reducerId}.data'
val output = shuffleBlockResolver.getDataFile(dep.shuffleId, mapId)
// 为data文件创建临时的文件
val tmp = Utils.tempFileWith(output)
try {
// 通过shuffle编号和map编号来获取 ShuffleBlock 编号 Shuffle Block Id:shuffle_{shuffleId}_{mapId}_{reducerId}
val blockId = ShuffleBlockId(dep.shuffleId, mapId, IndexShuffleBlockResolver.NOOP_REDUCE_ID)
/**
* 在外部排序中,有部分结果可能在内存中,另外部分结果在一个或多个文件中, 需要将它们merge成一个大文件
*/
val partitionLengths = sorter.writePartitionedFile(blockId, tmp)
//创建索引文件,将每个partition在数据文件中的起始与结束位置写入到索引文件
shuffleBlockResolver.writeIndexFileAndCommit(dep.shuffleId, mapId, partitionLengths, tmp)
// 将元数据写入mapStatus,后续任务通过该mapStatus得到处理结果信息
mapStatus = MapStatus(blockManager.shuffleServerId, partitionLengths)
} finally {
if (tmp.exists() && !tmp.delete()) {
logError(s"Error while deleting temp file ${tmp.getAbsolutePath}")
}
}
}
第十一步:insertAll()方法
/**
* 将写入数据全部放入外部排序器ExternalSorter,并且根据是否需要spill进行spill操作
*
* 1.判断aggregator是否为空,如果不为空,表示需要在本地combine
* 2.如果需要本地combine,则使用PartitionedAppendOnlyMap,先在内存进行聚合,如果需要一些磁盘,则开始溢写磁盘
* 3.如果不进行combine操作,则使用PartitionedPairBuffer添加数据存放于内存中,如果需要一些磁盘,则开始溢写磁盘
*/
def insertAll(records: Iterator[Product2[K, V]]): Unit = {
// TODO: stop combining if we find that the reduction factor isn't high
// 判断aggregator是否为空,如果不为空,表示需要在本地combine
//若定义了聚合函数,则shouldCombine为true
val shouldCombine = aggregator.isDefined
if (shouldCombine) {
// Combine values in-memory first using our AppendOnlyMap
/**
* 使用AppendOnlyMap优先在内存中进行combine
* 获取aggregator的merge函数,用于merge新的值到聚合记录
* mergeValue是个函数定义,指的就是val rdd3 = rdd2.reduceByKey(_ + _);中的_ + _运算
*/
val mergeValue = aggregator.get.mergeValue
// 获取aggregator的createCombiner函数,用于创建聚合的初始值
val createCombiner = aggregator.get.createCombiner
//kv就是records每次遍历得到的中的(K V)值
var kv: Product2[K, V] = null
//update方法是个关键,它接受两个参数,1.是否在Map中包含了值hasValue,2.旧值是多少,如果还不存在,那是null,在scala中,null也是一个对象
val update = (hadValue: Boolean, oldValue: C) => {
//如果已经存在,则进行merge,根据Key进行merge(所谓的merge,就是调用mergeValue方法),否则调用createCombiner获取值
//createCombiner方法是(v:V)=>v就是原样输出值
if (hadValue) mergeValue(oldValue, kv._2) else createCombiner(kv._2)
}
while (records.hasNext) {
// 处理一个元素,就更新一次结果,每遍历一次增1
addElementsRead()
// 取出一个(key,value)
kv = records.next()
// 关键代码,对key计算分区,然后开始进行merge
map.changeValue((getPartition(kv._1), kv._1), update)
// 如果需要溢写内存数据到磁盘
maybeSpillCollection(usingMap = true)
}
} else {
// Stick values into our buffer
// 不需要进行本地combine
while (records.hasNext) {
// 处理一个元素,就更新一次结果
addElementsRead()
// 取出一个(key,value)
val kv = records.next()
// 往PartitionedPairBuffer添加数据
buffer.insert(getPartition(kv._1), kv._1, kv._2.asInstanceOf[C])
// 如果需要溢写内存数据到磁盘
maybeSpillCollection(usingMap = false)
}
}
}
第十二步:getPartition()方法
//partitioner是个HashPartitioner,如果不进行Partition,则返回0,表示仅有1个Partition
private def getPartition(key: K): Int = {
if (shouldPartition) partitioner.get.getPartition(key) else 0
}
第十三步:map.changeValue()方法
/**
* SizeTrackingAppendOnlyMap的changeValue调用父类AppendOnlyMap的changeValue方法
*/
override def changeValue(key: K, updateFunc: (Boolean, V) => V): V = {
val newValue = super.changeValue(key, updateFunc)
super.afterUpdate()
newValue
}
def changeValue(key: K, updateFunc: (Boolean, V) => V): V = {
assert(!destroyed, destructionMessage)
val k = key.asInstanceOf[AnyRef]
if (k.eq(null)) {//如果key是null,表示什么含义?
if (!haveNullValue) {
incrementSize()
}
//nullValue是个val类型,定义于AppendOnlyMap类中
nullValue = updateFunc(haveNullValue, nullValue)
haveNullValue = true
return nullValue
}
//对于Key进行rehash,计算出这个key在SizeTrackingAppendOnlyMap这个数据结构中的位置
var pos = rehash(k.hashCode) & mask
var i = 1
while (true) {
//data是个数组,应该是AppendOnlyMap底层的数据结构,它使用两倍数据的容量,这是为何?原因是2*pos表示key,2*pos+1表示key对应的value
val curKey = data(2 * pos)
//如果当前Map中,data(2*pos)处是null对象
if (curKey.eq(null)) {
val newValue = updateFunc(false, null.asInstanceOf[V]) //调用_ + _操作获取kv的value值
data(2 * pos) = k //Key
data(2 * pos + 1) = newValue.asInstanceOf[AnyRef] //Value
incrementSize() //因为是Map中新增的K/V,做容量扩容检查
return newValue
//当前key已经存在于Map中,则需要做combine操作
} else if (k.eq(curKey) || k.equals(curKey)) {
//对Map中缓存的Key的Value进行_ + _操作,updateFunc即是在ExternalSorter.insertAll方法中创建的update函数
val newValue = updateFunc(true, data(2 * pos + 1).asInstanceOf[V])
//将新值回写到data(2*pos+1)处,不管data(2*pos + 1)处是否有值
data(2 * pos + 1) = newValue.asInstanceOf[AnyRef]
return newValue
} else {
//如果当前Map中,data(2*pos)处是空
val delta = i
pos = (pos + delta) & mask
i += 1
}
}
null.asInstanceOf[V] // Never reached but needed to keep compiler happy
}
第十四步:maybeSpillCollection()方法
private def maybeSpillCollection(usingMap: Boolean): Unit = {
var estimatedSize = 0L
// 如果使用PartitionedAppendOnlyMap存放数据,主要方便进行聚合
if (usingMap) {
// 首先估计一下该map的大小
estimatedSize = map.estimateSize()
// 然后会根据预估的map大小决定是否需要进行spill
if (maybeSpill(map, estimatedSize)) {
map = new PartitionedAppendOnlyMap[K, C]
}
} else {
//否则使用PartitionedPairBuffer,以用于本地不需要进行聚合的情况
estimatedSize = buffer.estimateSize()
// 然后会根据预估的map大小决定是否需要进行spill
if (maybeSpill(buffer, estimatedSize)) {
buffer = new PartitionedPairBuffer[K, C]
}
}
if (estimatedSize > _peakMemoryUsedBytes) {
_peakMemoryUsedBytes = estimatedSize
}
}
ExternalSorter内部维护了两个集合PartitionedAppendOnlyMap、PartitionedPairBuffer
两者底层均使用数组,两者的区别在于功能上,如下
| 是否支持aggregation | 实现 | |
|---|---|---|
| PartitionedAppendOnlyMap | 支持 | 基于Array实现的HashMap结构,支持lookup,并在此基础上实现aggregation,使用线性探查法处理Hash冲突 |
| PartitionedPairBuffer | 不支持 | 就是Array结构,K-V Pair依次写入数组中,因此不支持aggregation操作 |
第十五步:maybeSpill()方法,判断是否需要溢写磁盘,如果需要则开始溢写
/**
* 如果已经读取的数据是32的倍数且预计的当前需要的内存大于阀值的时候,准备申请内存
* 申请不成功或者申请完毕之后还是当前需要的内存还是不够,则表示需要进行spill
* 如果需要spill,则调用spill方法开始溢写磁盘,溢写完毕之后释放内存
*/
protected def maybeSpill(collection: C, currentMemory: Long): Boolean = {
var shouldSpill = false
/**
* 如果读取的数据是32的倍数,而且当前内存大于内存阀值,默认是5M
* 会先尝试向MemoryManager申请(2 * currentMemory - myMemoryThreshold)大小的内存
* 如果能够申请到,则不进行Spill操作,而是继续向Buffer中存储数据,
* 否则就会调用spill()方法将Buffer中数据输出到磁盘文件
*/
if (elementsRead % 32 == 0 && currentMemory >= myMemoryThreshold) {
// Claim up to double our current memory from the shuffle memory pool
// 向MemoryManager申请内存的大小
val amountToRequest = 2 * currentMemory - myMemoryThreshold
// 分配内存,并更新已经使用的内存
val granted = acquireMemory(amountToRequest)
// 更新现在内存阀值
myMemoryThreshold += granted
// If we were granted too little memory to grow further (either tryToAcquire returned 0,
// or we already had more memory than myMemoryThreshold), spill the current collection
// 再次判断当前内存是否大于阀值,如果还是大于阀值则继续spill
shouldSpill = currentMemory >= myMemoryThreshold
}
//强制溢写阈值可以通过在SparkConf中设置spark.shuffle.spill.batchSize来控制
shouldSpill = shouldSpill || _elementsRead > numElementsForceSpillThreshold
// Actually spill
// 如果需要进行spill,则开始进行spill操作
if (shouldSpill) {
_spillCount += 1
logSpillage(currentMemory)
// 开始spill
spill(collection)
_elementsRead = 0 //已读数清0
_memoryBytesSpilled += currentMemory //已经释放的内存总量
// 释放内存
releaseMemory()
}
shouldSpill
}
第十六步:spill()方法,溢写磁盘
源码地址:org.apache.spark.util.collection.ExternalSorter.scala
/**
* Spill our in-memory collection to a sorted file that we can merge later.
* We add this file into `spilledFiles` to find it later.
*
* @param collection whichever collection we're using (map or buffer)
* 溢写磁盘
* 1.返回一个根据指定的比较器排序的迭代器
* 2.溢写内存里的数据到磁盘一个临时文件
* 3.更新溢写的临时磁盘文件
*
*/
override protected[this] def spill(collection: WritablePartitionedPairCollection[K, C]): Unit = {
// 返回一个根据指定的比较器排序的迭代器
val inMemoryIterator = collection.destructiveSortedWritablePartitionedIterator(comparator)
// 溢写内存里的数据到磁盘一个临时文件
val spillFile = spillMemoryIteratorToDisk(inMemoryIterator)
// 更新溢写的临时磁盘文件
spills += spillFile
}
/**
* 溢写内存里的数据到磁盘一个临时文件
*
* 1.创建临时的blockId(temp_shuffle_" + uuid)和文件
* 2.针对临时文件创建DiskBlockObjectWriter
* 3.循环读取内存里的数据
* 4.内存里的数据数据写入文件
* 5.将数据刷到磁盘
* 6.创建SpilledFile然后返回
*/
private[this] def spillMemoryIteratorToDisk(inMemoryIterator: WritablePartitionedIterator): SpilledFile = {
// Because these files may be read during shuffle, their compression must be controlled by
// spark.shuffle.compress instead of spark.shuffle.spill.compress, so we need to use
// createTempShuffleBlock here; see SPARK-3426 for more context.
//因为这些文件在shuffle期间可能被读取,他们压缩应该被spark.shuffle.spill.compress控制
//而不是spark.shuffle.compress,所以我们需要创建临时的shuffle block
val (blockId, file) = diskBlockManager.createTempShuffleBlock()
// These variables are reset after each flush
var objectsWritten: Long = 0
val spillMetrics: ShuffleWriteMetrics = new ShuffleWriteMetrics
// 创建针对临时文件的writer
val writer: DiskBlockObjectWriter =
blockManager.getDiskWriter(blockId, file, serInstance, fileBufferSize, spillMetrics)
// List of batch sizes (bytes) in the order they are written to disk
// 批量写入磁盘的列表
val batchSizes = new ArrayBuffer[Long]
// How many elements we have in each partition
// 每一个分区有多少数据
val elementsPerPartition = new Array[Long](numPartitions)
// Flush the disk writer's contents to disk, and update relevant variables.
// The writer is committed at the end of this process.
// 刷新数据到磁盘
def flush(): Unit = {
// 每一个分区对应文件刷新到磁盘,并返回对应的FileSegment
val segment = writer.commitAndGet()
// 获取该FileSegment对应的文件的长度,并且更新batchSizes
batchSizes += segment.length
_diskBytesSpilled += segment.length
objectsWritten = 0
}
var success = false
try {
// 循环读取内存里的数据
while (inMemoryIterator.hasNext) {
// 获取partitionId
val partitionId = inMemoryIterator.nextPartition()
require(
partitionId >= 0 && partitionId < numPartitions,
s"partition Id: ${partitionId} should be in the range [0, ${numPartitions})")
// 内存里的数据数据写入文件
inMemoryIterator.writeNext(writer)
elementsPerPartition(partitionId) += 1
objectsWritten += 1
// 将数据刷到磁盘
if (objectsWritten == serializerBatchSize) {
flush()
}
}
// 遍历完了之后,刷新到磁盘
if (objectsWritten > 0) {
flush()
} else {
writer.revertPartialWritesAndClose()
}
success = true
} finally {
if (success) {
writer.close()
} else {
// This code path only happens if an exception was thrown above before we set success;
// close our stuff and let the exception be thrown further
writer.revertPartialWritesAndClose()
if (file.exists()) {
if (!file.delete()) {
logWarning(s"Error deleting ${file}")
}
}
}
}
// 创建SpilledFile然后返回
SpilledFile(file, blockId, batchSizes.toArray, elementsPerPartition)
}
第十七步: collection.destructiveSortedWritablePartitionedIterator(comparator)方法
def destructiveSortedWritablePartitionedIterator(keyComparator: Option[Comparator[K]])
: WritablePartitionedIterator = {
// 这里的partitionedDestructiveSortedIterator会根据是map或者buffer有不同的实现
val it = partitionedDestructiveSortedIterator(keyComparator)
// 最后返回的是WritablePartitionedIterator,上面进行写操作的时候就是调用该迭代器中的writeNext方法
new WritablePartitionedIterator {
private[this] var cur = if (it.hasNext) it.next() else null
def writeNext(writer: DiskBlockObjectWriter): Unit = {
writer.write(cur._1._2, cur._2)
cur = if (it.hasNext) it.next() else null
}
def hasNext(): Boolean = cur != null
def nextPartition(): Int = cur._1._1
}
}
}
第十八步:partitionedDestructiveSortedIterator(keyComparator)是map,具体的实现为(PartitionedAppendOnlyMap)
源码地址:org.apache.spark.util.collection.PartitionedAppendOnlyMap.scala
def partitionedDestructiveSortedIterator(keyComparator: Option[Comparator[K]])
: Iterator[((Int, K), V)] = {
val comparator = keyComparator.map(partitionKeyComparator).getOrElse(partitionComparator)
destructiveSortedIterator(comparator)
}
def destructiveSortedIterator(keyComparator: Comparator[K]): Iterator[(K, V)] = {
destroyed = true
// Pack KV pairs into the front of the underlying array
var keyIndex, newIndex = 0
while (keyIndex < capacity) {
if (data(2 * keyIndex) != null) {
data(2 * newIndex) = data(2 * keyIndex)
data(2 * newIndex + 1) = data(2 * keyIndex + 1)
newIndex += 1
}
keyIndex += 1
}
assert(curSize == newIndex + (if (haveNullValue) 1 else 0))
//timSort.sort(a, lo, hi, c)
//排序的逻辑是,先根据PartitionId,再根据K的hashCode进行排序
new Sorter(new KVArraySortDataFormat[K, AnyRef]).sort(data, 0, newIndex, keyComparator)
new Iterator[(K, V)] {
var i = 0
var nullValueReady = haveNullValue
def hasNext: Boolean = (i < newIndex || nullValueReady)
def next(): (K, V) = {
if (nullValueReady) {
nullValueReady = false
(null.asInstanceOf[K], nullValue)
} else {
val item = (data(2 * i).asInstanceOf[K], data(2 * i + 1).asInstanceOf[V])
i += 1
item
}
}
}
}
def partitionKeyComparator[K](keyComparator: Comparator[K]): Comparator[(Int, K)] = {
new Comparator[(Int, K)] {
override def compare(a: (Int, K), b: (Int, K)): Int = {
val partitionDiff = a._1 - b._1
if (partitionDiff != 0) {
partitionDiff
} else {
keyComparator.compare(a._2, b._2)
}
}
}
}
}
private val keyComparator: Comparator[K] = ordering.getOrElse(new Comparator[K] {
override def compare(a: K, b: K): Int = {
val h1 = if (a == null) 0 else a.hashCode()
val h2 = if (b == null) 0 else b.hashCode()
if (h1 < h2) -1 else if (h1 == h2) 0 else 1
}
})
处理后Partition内K是有序的,顺序由K的hashCode决定,但是和Mapreduce实现不同,这个Partition内的顺序并不会被reduce端直接使用,reduce端不会进行merge-sort,而是当做无序进行处理
第十九步:partitionedDestructiveSortedIterator(keyComparator)是buffer,具体的实现为(PartitionedPairBuffer):
/** Iterate through the data in a given order. For this class this is not really destructive. */
override def partitionedDestructiveSortedIterator(keyComparator: Option[Comparator[K]])
: Iterator[((Int, K), V)] = {
val comparator = keyComparator.map(partitionKeyComparator).getOrElse(partitionComparator)
//timSort.sort(a, lo, hi, c)
new Sorter(new KVArraySortDataFormat[(Int, K), AnyRef]).sort(data, 0, curSize, comparator)
iterator
}
第二十步:writePartitionedFile方法(对结果排序,合并文件)
/**
* Write all the data added into this ExternalSorter into a file in the disk store. This is
* called by the SortShuffleWriter.
*
* @param blockId block ID to write to. The index file will be blockId.name + ".index".
* @return array of lengths, in bytes, of each partition of the file (used by map output tracker)
*
* 溢写文件为空,则内存足够,不需要溢写结果到磁盘, 返回一个对结果排序的迭代器, 遍历数据写入data临时文件;
* 再将数据刷到磁盘文件,返回FileSegment对象;构造一个分区文件长度的数组
*
* 溢写文件不为空,则需要将溢写的文件和内存数据合并,合并之后则需要进行归并排序(merge-sort);
* 数据写入data临时文件,再将数据刷到磁盘文件,返回FileSegment对象;构造一个分区文件长度的数组
*
* 返回分区文件长度的数组
*/
def writePartitionedFile(
blockId: BlockId,
outputFile: File): Array[Long] = {
// Track location of each range in the output file
//临时的data文件跟踪每一个分区的位置
//创建每一个分区对应的文件长度的数组
val lengths = new Array[Long](numPartitions)
// 创建DiskBlockObjectWriter对象
val writer = blockManager.getDiskWriter(blockId, outputFile, serInstance, fileBufferSize,
context.taskMetrics().shuffleWriteMetrics)
// 判断是否有进行spill的文件
if (spills.isEmpty) {
// Case where we only have in-memory data
/**
* 如果是空的表示我们只有内存数据,内存足够,不需要溢写结果到磁盘
* 如果指定aggregator,就返回PartitionedAppendOnlyMap里的数据,否则返回PartitionedPairBuffer里的数据
*/
val collection = if (aggregator.isDefined) map else buffer
// 返回一个对结果排序的迭代器
val it = collection.destructiveSortedWritablePartitionedIterator(comparator)
while (it.hasNext) {
// 获取partitionId
val partitionId = it.nextPartition()
// 通过writer将内存数据写入临时文件
while (it.hasNext && it.nextPartition() == partitionId) {
it.writeNext(writer)
}
// 数据刷到磁盘,并且创建FileSegment数组
val segment = writer.commitAndGet()
// 构造一个分区文件长度的数组
lengths(partitionId) = segment.length
}
} else {
// We must perform merge-sort; get an iterator by partition and write everything directly.
/**
* 表示有溢写文件,则需要进行归并排序(merge-sort)
* 每一个分区的数据都写入到data文件的临时文件
*/
for ((id, elements) <- this.partitionedIterator) {
if (elements.hasNext) {
for (elem <- elements) {
writer.write(elem._1, elem._2)
}
// 数据刷到磁盘,并且创建FileSegment数组
val segment = writer.commitAndGet()
// 构造一个分区文件长度的数组
lengths(id) = segment.length
}
}
}
writer.close()
context.taskMetrics().incMemoryBytesSpilled(memoryBytesSpilled)
context.taskMetrics().incDiskBytesSpilled(diskBytesSpilled)
context.taskMetrics().incPeakExecutionMemory(peakMemoryUsedBytes)
lengths
}
/**
* Return an iterator over all the data written to this object, grouped by partition and
* aggregated by the requested aggregator. For each partition we then have an iterator over its
* contents, and these are expected to be accessed in order (you can't "skip ahead" to one
* partition without reading the previous one). Guaranteed to return a key-value pair for each
* partition, in order of partition ID.
*
* For now, we just merge all the spilled files in once pass, but this can be modified to
* support hierarchical merging.
* Exposed for testing.
*
* 没有溢写,则判断是否需要对key排序,如果不需要则只是将数据按照partitionId排序,
* 否则首先按照partitionId排序,然后partition内部再按照key排序
*
* 如果发生溢写,则需要将磁盘上溢写文件和内存里的数据进行合并
*
*/
def partitionedIterator: Iterator[(Int, Iterator[Product2[K, C]])] = {
// 是否需要本地combine
val usingMap = aggregator.isDefined
val collection: WritablePartitionedPairCollection[K, C] = if (usingMap) map else buffer
// 如果没有发生磁盘溢写
if (spills.isEmpty) {
// Special case: if we have only in-memory data, we don't need to merge streams, and perhaps
// we don't even need to sort by anything other than partition ID
// 而且不需要排序
if (!ordering.isDefined) {
// The user hasn't requested sorted keys, so only sort by partition ID, not key
// 数据只是按照partitionId排序,并不会对key进行排序
groupByPartition(destructiveIterator(collection.partitionedDestructiveSortedIterator(None)))
} else {
// We do need to sort by both partition ID and key
// 否则我们需要先按照partitionId排序,然后分区内部对key进行排序
groupByPartition(destructiveIterator(
collection.partitionedDestructiveSortedIterator(Some(keyComparator))))
}
} else {
// 如果发生了溢写操作,则需要将磁盘上溢写文件和内存里的数据进行合并
// Merge spilled and in-memory data
merge(spills, destructiveIterator(
collection.partitionedDestructiveSortedIterator(comparator)))
}
}
private def merge(spills: Seq[SpilledFile], inMemory: Iterator[((Int, K), C)]): Iterator[(Int, Iterator[Product2[K, C]])] = {
// 根据每个SpilledFile实例化一个SpillReader,这些SpillReader组成一个Seq
val readers = spills.map(new SpillReader(_))
// 获得内存BufferedIterator
val inMemBuffered = inMemory.buffered
// 根据partition的个数进行迭代
(0 until numPartitions).iterator.map { p =>
// 实例化IteratorForPartition,即当前partition下的Iterator
val inMemIterator = new IteratorForPartition(p, inMemBuffered)
// 这里就是合并操作
val iterators = readers.map(_.readNextPartition()) ++ Seq(inMemIterator)
if (aggregator.isDefined) {
// Perform partial aggregation across partitions
// 如果需要map端的combine操作则需要根据key进行聚合操作
(p, mergeWithAggregation(
iterators, aggregator.get.mergeCombiners, keyComparator, ordering.isDefined))
} else if (ordering.isDefined) {
// No aggregator given, but we have an ordering (e.g. used by reduce tasks in sortByKey);
// sort the elements without trying to merge them
// 排序合并,例如sortByKey
(p, mergeSort(iterators, ordering.get))
} else {
(p, iterators.iterator.flatten)
}
}
}
示意图
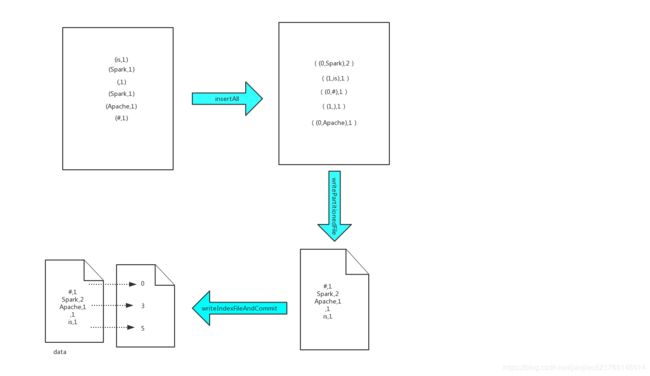
Sort-Based Shuffle读机制源码分析:
假设我们执行了reduceByKey算子,那么生成的RDD的就是ShuffledRDD,下游在运行任务的时候,则需要获取上游ShuffledRDD的数据,所以ShuffledRDD的compute方法是Shuffle读的起点。
下游的ReducerTask,可能是ShuffleMapTask也有可能是ResultTask,首先会去Driver获取parent stage中ShuffleMapTask输出的位置信息,根据位置信息获取index文件,然后解析index文件,从index文件中获取相关的位置等信息,然后读data文件获取属于自己那部分内容。
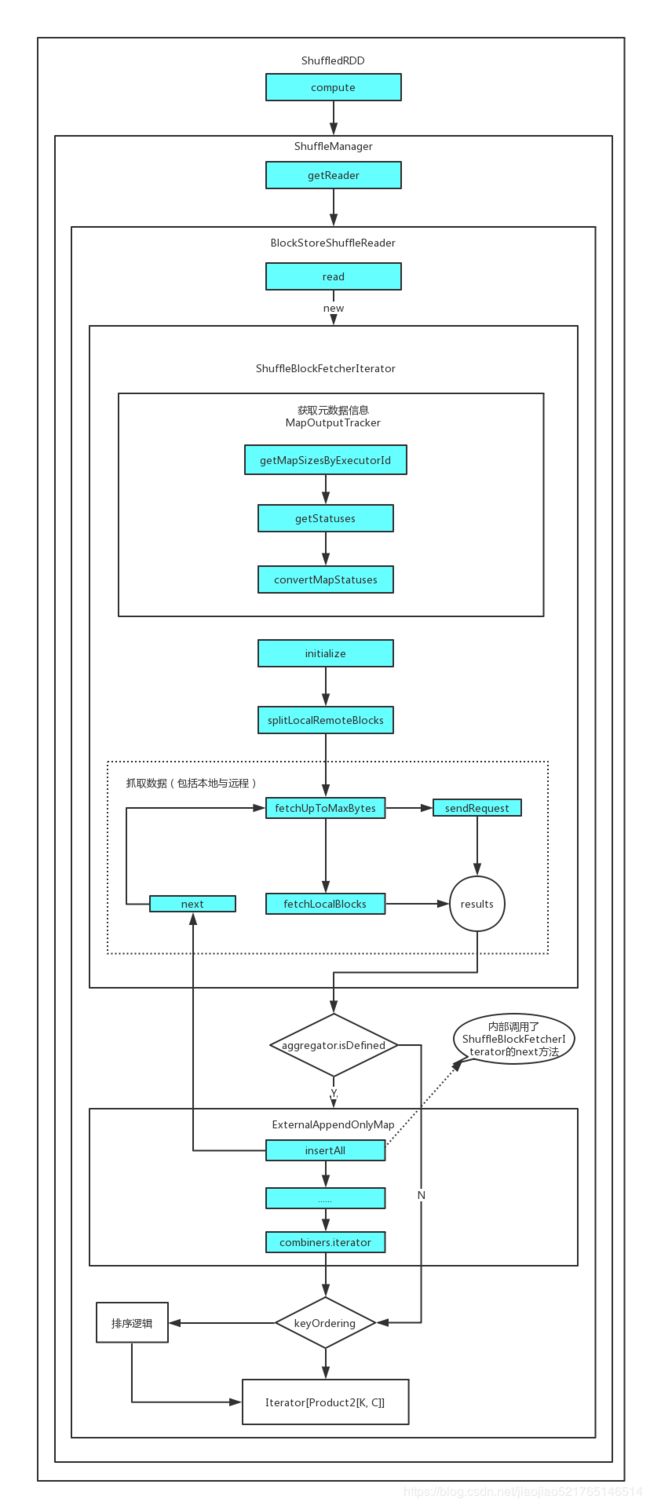
第一步:ShuffledRDD的compute方法
源码地址:org.apache.spark.rdd.ShuffledRDD.scala
// ResultTask或者ShuffleMapTask在执行到ShuffledRDD时,肯定会调用ShuffledRDD的compute方法
override def compute(split: Partition, context: TaskContext): Iterator[(K, C)] = {
val dep = dependencies.head.asInstanceOf[ShuffleDependency[K, V, C]]
// 获取ShuffleManager的reader去拉取ShuffleMapTask,需要聚合的数据
SparkEnv.get.shuffleManager.getReader(dep.shuffleHandle, split.index, split.index + 1, context)
.read()
.asInstanceOf[Iterator[(K, C)]]
}
第二步: 调用BlockStoreShuffleReader的read方法开始读取数据
/**
* 创建ShuffleBlockFetcherIterator,一个迭代器,它获取多个块,对于本地块,从本地读取对于远程块,通过远程方法读取
*
* 如果reduce端需要聚合:如果map端已经聚合过了,则对读取到的聚合结果进行聚合; 如果map端没有聚合,则针对未合并的进行聚合
*
* 如果需要对key排序,则进行排序。基于sort的shuffle实现过程中,默认只是按照partitionId排序。
* 在每一个partition内部并没有排序,因此添加了keyOrdering变量,提供是否需要对分区内部的key排序
*/
override def read(): Iterator[Product2[K, C]] = {
// 构造ShuffleBlockFetcherIterator,一个迭代器,它获取多个块,对于本地块,从本地读取
// 对于远程块,通过远程方法读取
val wrappedStreams = new ShuffleBlockFetcherIterator(
context,
blockManager.shuffleClient,//获取远程数据块
blockManager,//获取本地数据块
//通过消息发送获取 ShuffleMapTask 存储数据位置的元数据,MapOutputTracker在SparkEnv启动的时候实例化
mapOutputTracker.getMapSizesByExecutorId(handle.shuffleId, startPartition, endPartition),
serializerManager.wrapStream, //对数据流进行压缩和加密的相关处理
// Note: we use getSizeAsMb when no suffix is provided for backwards compatibility
//正在获取的最大远程数据量48M
SparkEnv.get.conf.getSizeAsMb("spark.reducer.maxSizeInFlight", "48m") * 1024 * 1024,
//最大请求数目
SparkEnv.get.conf.getInt("spark.reducer.maxReqsInFlight", Int.MaxValue),
//每个地址正在获取的数据块数目最大值
SparkEnv.get.conf.get(config.REDUCER_MAX_BLOCKS_IN_FLIGHT_PER_ADDRESS),
//shuffle数据存储到内存的最大字节
SparkEnv.get.conf.get(config.MAX_REMOTE_BLOCK_SIZE_FETCH_TO_MEM),
//检测获取块中的损坏
SparkEnv.get.conf.getBoolean("spark.shuffle.detectCorrupt", true))
// 获取序列化实例
val serializerInstance = dep.serializer.newInstance()
// 对于每一个流创建一个迭代器,然后连接起来
// Create a key/value iterator for each stream
val recordIter = wrappedStreams.flatMap { case (blockId, wrappedStream) =>
// Note: the asKeyValueIterator below wraps a key/value iterator inside of a
// NextIterator. The NextIterator makes sure that close() is called on the
// underlying InputStream when all records have been read.
serializerInstance.deserializeStream(wrappedStream).asKeyValueIterator
}
// Update the context task metrics for each record read.
// 度量每一条记录
val readMetrics = context.taskMetrics.createTempShuffleReadMetrics()
val metricIter = CompletionIterator[(Any, Any), Iterator[(Any, Any)]](
recordIter.map { record =>
readMetrics.incRecordsRead(1)
record
},
context.taskMetrics().mergeShuffleReadMetrics())
// An interruptible iterator must be used here in order to support task cancellation
// 再套一层迭代器,它通过检查TaskContext中的中断标志,提供任务中断功能
val interruptibleIter = new InterruptibleIterator[(Any, Any)](context, metricIter)
// 如果reduce端需要聚合
val aggregatedIter: Iterator[Product2[K, C]] = if (dep.aggregator.isDefined) {
// 如果map端已经聚合过了
if (dep.mapSideCombine) {
// We are reading values that are already combined
//则对读取到的聚合结果进行聚合
val combinedKeyValuesIterator = interruptibleIter.asInstanceOf[Iterator[(K, C)]]
// 针对map端各个partition对key进行聚合后的结果再次聚合
dep.aggregator.get.combineCombinersByKey(combinedKeyValuesIterator, context)
} else {
// We don't know the value type, but also don't care -- the dependency *should*
// have made sure its compatible w/ this aggregator, which will convert the value
// type to the combined type C
// 如果map端没有聚合,则针对未合并的进行聚合
val keyValuesIterator = interruptibleIter.asInstanceOf[Iterator[(K, Nothing)]]
dep.aggregator.get.combineValuesByKey(keyValuesIterator, context)
}
} else {
interruptibleIter.asInstanceOf[Iterator[Product2[K, C]]]
}
// Sort the output if there is a sort ordering defined.
/**
* 如果需要对key排序,则进行排序。基于sort的shuffle实现过程中,默认只是按照partitionId排序
* 在每一个partition内部并没有排序,因此添加了keyOrdering变量,提供是否需要对分区内部的key排序
*/
val resultIter = dep.keyOrdering match {
case Some(keyOrd: Ordering[K]) =>
// Create an ExternalSorter to sort the data.
// 为了减少内存压力和避免GC开销,引入了外部排序器,当内存不足时会根据配置文件spark.shuffle.spill决定是否进行spill操作
val sorter =
new ExternalSorter[K, C, C](context, ordering = Some(keyOrd), serializer = dep.serializer)
sorter.insertAll(aggregatedIter)
context.taskMetrics().incMemoryBytesSpilled(sorter.memoryBytesSpilled)
context.taskMetrics().incDiskBytesSpilled(sorter.diskBytesSpilled)
context.taskMetrics().incPeakExecutionMemory(sorter.peakMemoryUsedBytes)
// Use completion callback to stop sorter if task was finished/cancelled.
context.addTaskCompletionListener[Unit](_ => {
sorter.stop()
})
CompletionIterator[Product2[K, C], Iterator[Product2[K, C]]](sorter.iterator, sorter.stop())
case None =>
// 不需要排序直接返回
aggregatedIter
}
第三步:通过MapOutputTracker的getMapSizesByExecutorId去获取MapStatus
override def getMapSizesByExecutorId(shuffleId: Int, startPartition: Int, endPartition: Int)
: Iterator[(BlockManagerId, Seq[(BlockId, Long)])] = {
logDebug(s"Fetching outputs for shuffle $shuffleId, partitions $startPartition-$endPartition")
// 获得Map阶段输出的中间计算结果的元数据信息
val statuses = getStatuses(shuffleId)
try {
// 将获得的元数据信息转化成形如Seq[(BlockManagerId, Seq[(BlockId, Long)])]格式的位置信息,用来读取指定的Map阶段产生的数据
MapOutputTracker.convertMapStatuses(shuffleId, startPartition, endPartition, statuses)
} catch {
case e: MetadataFetchFailedException =>
// We experienced a fetch failure so our mapStatuses cache is outdated; clear it:
mapStatuses.clear()
throw e
}
}
第四步: getStatuses(shuffleId)来获取元数据信息的
/**
* Get or fetch the array of MapStatuses for a given shuffle ID. NOTE: clients MUST synchronize
* on this array when reading it, because on the driver, we may be changing it in place.
* 获取元数据信息
* (It would be nice to remove this restriction in the future.)
*/
private def getStatuses(shuffleId: Int): Array[MapStatus] = {
// 根据shuffleId获得MapStatus组成的数组:Array[MapStatus]
val statuses = mapStatuses.get(shuffleId).orNull
if (statuses == null) { // 如果没有获取到就进行fetch操作
logInfo("Don't have map outputs for shuffle " + shuffleId + ", fetching them")
val startTime = System.currentTimeMillis
// 用来保存fetch来的MapStatus
var fetchedStatuses: Array[MapStatus] = null
fetching.synchronized { // 有可能有别的任务正在进行fetch,所以这里使用synchronized关键字保证同步
// Someone else is fetching it; wait for them to be done
while (fetching.contains(shuffleId)) {
try {
fetching.wait()
} catch {
case e: InterruptedException =>
}
}
// Either while we waited the fetch happened successfully, or
// someone fetched it in between the get and the fetching.synchronized.
// 等待过后继续尝试获取
fetchedStatuses = mapStatuses.get(shuffleId).orNull
if (fetchedStatuses == null) {
// We have to do the fetch, get others to wait for us.
fetching += shuffleId
}
}
// 如果得到了fetch的权利就进行抓取
if (fetchedStatuses == null) {
// We won the race to fetch the statuses; do so
logInfo("Doing the fetch; tracker endpoint = " + trackerEndpoint)
// This try-finally prevents hangs due to timeouts:
try {
// 调用askTracker方法发送消息,消息的格式为GetMapOutputStatuses(shuffleId)
val fetchedBytes = askTracker[Array[Byte]](GetMapOutputStatuses(shuffleId))
// 将得到的序列化后的数据进行反序列化
fetchedStatuses = MapOutputTracker.deserializeMapStatuses(fetchedBytes)
logInfo("Got the output locations")
// 保存到本地的mapStatuses中
mapStatuses.put(shuffleId, fetchedStatuses)
} finally {
fetching.synchronized {
fetching -= shuffleId
fetching.notifyAll()
}
}
}
logDebug(s"Fetching map output statuses for shuffle $shuffleId took " +
s"${System.currentTimeMillis - startTime} ms")
if (fetchedStatuses != null) {
// 最后将抓取到的元数据信息返回
fetchedStatuses
} else {
logError("Missing all output locations for shuffle " + shuffleId)
throw new MetadataFetchFailedException(
shuffleId, -1, "Missing all output locations for shuffle " + shuffleId)
}
} else {
// 如果获取到了Array[MapStatus]就直接返回
statuses
}
}
第五步:发送消息的askTracker方法,发送的消息是一个GetMapOutputStatuses(shuffleId)
protected def askTracker[T: ClassTag](message: Any): T = {
try {
trackerEndpoint.askSync[T](message)
} catch {
case e: Exception =>
logError("Error communicating with MapOutputTracker", e)
throw new SparkException("Error communicating with MapOutputTracker", e)
}
}
第六步:MapOutputTrackerMasterEndpoint在接收到该消息后的处理:
private[spark] class MapOutputTrackerMasterEndpoint(
override val rpcEnv: RpcEnv, tracker: MapOutputTrackerMaster, conf: SparkConf)
extends RpcEndpoint with Logging {
logDebug("init") // force eager creation of logger
override def receiveAndReply(context: RpcCallContext): PartialFunction[Any, Unit] = {
case GetMapOutputStatuses(shuffleId: Int) =>
val hostPort = context.senderAddress.hostPort
logInfo("Asked to send map output locations for shuffle " + shuffleId + " to " + hostPort)
// 获得Map阶段的输出数据的序列化后的元数据信息
val mapOutputStatuses = tracker.post(new GetMapOutputMessage(shuffleId, context))
case StopMapOutputTracker =>
logInfo("MapOutputTrackerMasterEndpoint stopped!")
context.reply(true)
stop()
}
}
第七步:tracker.post(new GetMapOutputMessage(shuffleId, context))的处理:
private val mapOutputRequests = new LinkedBlockingQueue[GetMapOutputMessage]
......
def post(message: GetMapOutputMessage): Unit = {
//增加队列中
mapOutputRequests.offer(message)
}
private class MessageLoop extends Runnable {
override def run(): Unit = {
try {
while (true) {
try {
val data = mapOutputRequests.take()
if (data == PoisonPill) {
// Put PoisonPill back so that other MessageLoops can see it.
mapOutputRequests.offer(PoisonPill)
return
}
val context = data.context
val shuffleId = data.shuffleId
val hostPort = context.senderAddress.hostPort
logDebug("Handling request to send map output locations for shuffle " + shuffleId +
" to " + hostPort)
val shuffleStatus = shuffleStatuses.get(shuffleId).head
//获得的元数据信息返回
context.reply(
shuffleStatus.serializedMapStatus(broadcastManager, isLocal, minSizeForBroadcast))
} catch {
case NonFatal(e) => logError(e.getMessage, e)
}
}
} catch {
case ie: InterruptedException => // exit
}
}
}
第八步:shuffleStatus.serializedMapStatus(broadcastManager, isLocal, minSizeForBroadcast)
def serializedMapStatus(
broadcastManager: BroadcastManager,
isLocal: Boolean,
minBroadcastSize: Int): Array[Byte] = synchronized {
if (cachedSerializedMapStatus eq null) {
val serResult = MapOutputTracker.serializeMapStatuses(
mapStatuses, broadcastManager, isLocal, minBroadcastSize)
// 缓存操作
cachedSerializedMapStatus = serResult._1
cachedSerializedBroadcast = serResult._2
}
cachedSerializedMapStatus
}
第九步:ShuffleBlockFetcherIterator在初始化时会调用initialize方法
private[this] def initialize(): Unit = {
// Add a task completion callback (called in both success case and failure case) to cleanup.
// 任务完成时回调,用于清空数据
context.addTaskCompletionListener[Unit](_ => cleanup())
// Split local and remote blocks.
// 区分本地和远程数据块
val remoteRequests = splitLocalRemoteBlocks()
// Add the remote requests into our queue in a random order
// 将远程数据块请求乱序添加到请求队列中
fetchRequests ++= Utils.randomize(remoteRequests)
assert ((0 == reqsInFlight) == (0 == bytesInFlight),
"expected reqsInFlight = 0 but found reqsInFlight = " + reqsInFlight +
", expected bytesInFlight = 0 but found bytesInFlight = " + bytesInFlight)
// Send out initial requests for blocks, up to our maxBytesInFlight
//发送请求,确保请求的数据量不超过maxBytesInFlight
fetchUpToMaxBytes()
//部分数据块请求已经开始处理
val numFetches = remoteRequests.size - fetchRequests.size
logInfo("Started " + numFetches + " remote fetches in" + Utils.getUsedTimeMs(startTime))
// Get Local Blocks
//获取本地数据块,内部通过IndexShuffleBlockResolver.getBlockData方法
//然后构造一个SuccessFetchResult添加到结果记录队列results中
fetchLocalBlocks()
logDebug("Got local blocks in " + Utils.getUsedTimeMs(startTime))
}
第十步:splitLocalRemoteBlocks() 区分本地和远程数据块,将远程数据块封装为FetchRequest数组
/**
* 将远程数据块封装为FetchRequest数组
*/
private[this] def splitLocalRemoteBlocks(): ArrayBuffer[FetchRequest] = {
// Make remote requests at most maxBytesInFlight / 5 in length; the reason to keep them
// smaller than maxBytesInFlight is to allow multiple, parallel fetches from up to 5
// nodes, rather than blocking on reading output from one node.
// 实际请求数据时大小为最大值的1/5,可以从5个节点并行的获取数据,避免阻塞到一个节点上
val targetRequestSize = math.max(maxBytesInFlight / 5, 1L)
logDebug("maxBytesInFlight: " + maxBytesInFlight + ", targetRequestSize: " + targetRequestSize
+ ", maxBlocksInFlightPerAddress: " + maxBlocksInFlightPerAddress)
// Split local and remote blocks. Remote blocks are further split into FetchRequests of size
// at most maxBytesInFlight in order to limit the amount of data in flight.
// 远程数据块会被分成过个FetchRequests,避免超过最大正在传输数据量的限制
val remoteRequests = new ArrayBuffer[FetchRequest]
for ((address, blockInfos) <- blocksByAddress) {
//blockManager位于同一个executor,为本地数据块
if (address.executorId == blockManager.blockManagerId.executorId) {
// 过滤掉大小为0的数据块
blockInfos.find(_._2 <= 0) match {
case Some((blockId, size)) if size < 0 =>
throw new BlockException(blockId, "Negative block size " + size)
case Some((blockId, size)) if size == 0 =>
throw new BlockException(blockId, "Zero-sized blocks should be excluded.")
case None => // do nothing.
}
//记录到localBlocks
localBlocks ++= blockInfos.map(_._1)
//记录数据块的总数
numBlocksToFetch += localBlocks.size
} else {
val iterator = blockInfos.iterator
var curRequestSize = 0L
var curBlocks = new ArrayBuffer[(BlockId, Long)]
while (iterator.hasNext) {
val (blockId, size) = iterator.next()
if (size < 0) {
throw new BlockException(blockId, "Negative block size " + size)
} else if (size == 0) {
throw new BlockException(blockId, "Zero-sized blocks should be excluded.")
// 处理非空的数据块
} else {
curBlocks += ((blockId, size))
remoteBlocks += blockId //记录到remoteBlocks
numBlocksToFetch += 1 //记录数据块的总数
curRequestSize += size //记录数据块大小
}
//数据块大小,或者该address下数据块数目达到限定,封装为一个FetchRequest
if (curRequestSize >= targetRequestSize ||
curBlocks.size >= maxBlocksInFlightPerAddress) {
// Add this FetchRequest
remoteRequests += new FetchRequest(address, curBlocks)
logDebug(s"Creating fetch request of $curRequestSize at $address "
+ s"with ${curBlocks.size} blocks")
//重置数据
curBlocks = new ArrayBuffer[(BlockId, Long)]
curRequestSize = 0
}
}
// Add in the final request
// 将剩余的远程数据块封装为一个FetchRequest
if (curBlocks.nonEmpty) {
remoteRequests += new FetchRequest(address, curBlocks)
}
}
}
logInfo(s"Getting $numBlocksToFetch non-empty blocks including ${localBlocks.size}" +
s" local blocks and ${remoteBlocks.size} remote blocks")
remoteRequests
}
注意:此处生成的FetchRequest的可能会发生内存泄漏,因为如果单个block过大,拉取过来占用堆外内存过大,造成OOM
第十一步:fetchUpToMaxBytes()方法
private def fetchUpToMaxBytes(): Unit = {
// Send fetch requests up to maxBytesInFlight. If you cannot fetch from a remote host
// immediately, defer the request until the next time it can be processed.
// Process any outstanding deferred fetch requests if possible.
if (deferredFetchRequests.nonEmpty) {
for ((remoteAddress, defReqQueue) <- deferredFetchRequests) {
while (isRemoteBlockFetchable(defReqQueue) &&
!isRemoteAddressMaxedOut(remoteAddress, defReqQueue.front)) {
val request = defReqQueue.dequeue()
logDebug(s"Processing deferred fetch request for $remoteAddress with "
+ s"${request.blocks.length} blocks")
send(remoteAddress, request)
if (defReqQueue.isEmpty) {
deferredFetchRequests -= remoteAddress
}
}
}
}
// Process any regular fetch requests if possible.
while (isRemoteBlockFetchable(fetchRequests)) {
val request = fetchRequests.dequeue()
val remoteAddress = request.address
if (isRemoteAddressMaxedOut(remoteAddress, request)) {
logDebug(s"Deferring fetch request for $remoteAddress with ${request.blocks.size} blocks")
val defReqQueue = deferredFetchRequests.getOrElse(remoteAddress, new Queue[FetchRequest]())
defReqQueue.enqueue(request)
deferredFetchRequests(remoteAddress) = defReqQueue
} else {
send(remoteAddress, request)
}
}
def send(remoteAddress: BlockManagerId, request: FetchRequest): Unit = {
//发送请求
sendRequest(request)
numBlocksInFlightPerAddress(remoteAddress) =
numBlocksInFlightPerAddress.getOrElse(remoteAddress, 0) + request.blocks.size
}
def isRemoteBlockFetchable(fetchReqQueue: Queue[FetchRequest]): Boolean = {
fetchReqQueue.nonEmpty &&
(bytesInFlight == 0 ||
(reqsInFlight + 1 <= maxReqsInFlight &&
bytesInFlight + fetchReqQueue.front.size <= maxBytesInFlight))
}
// Checks if sending a new fetch request will exceed the max no. of blocks being fetched from a
// given remote address.
def isRemoteAddressMaxedOut(remoteAddress: BlockManagerId, request: FetchRequest): Boolean = {
numBlocksInFlightPerAddress.getOrElse(remoteAddress, 0) + request.blocks.size >
maxBlocksInFlightPerAddress
}
}
第十二步: sendRequest(request)方法
private[this] def sendRequest(req: FetchRequest) {
logDebug("Sending request for %d blocks (%s) from %s".format(
req.blocks.size, Utils.bytesToString(req.size), req.address.hostPort))
bytesInFlight += req.size
reqsInFlight += 1
// so we can look up the size of each blockID
// 1、首先获得要fetch的blocks的信息
val sizeMap = req.blocks.map { case (blockId, size) => (blockId.toString, size) }.toMap
val remainingBlocks = new HashSet[String]() ++= sizeMap.keys
val blockIds = req.blocks.map(_._1.toString)
val address = req.address
// 2、获取对应远程节点上的数据
val blockFetchingListener = new BlockFetchingListener {
//3、最后,不管成功还是失败,都将结果保存在results中
override def onBlockFetchSuccess(blockId: String, buf: ManagedBuffer): Unit = {
// Only add the buffer to results queue if the iterator is not zombie,
// i.e. cleanup() has not been called yet.
ShuffleBlockFetcherIterator.this.synchronized {
if (!isZombie) {
// Increment the ref count because we need to pass this to a different thread.
// This needs to be released after use.
buf.retain()
remainingBlocks -= blockId
//将结果保存在results中
results.put(new SuccessFetchResult(BlockId(blockId), address, sizeMap(blockId), buf,
remainingBlocks.isEmpty))
logDebug("remainingBlocks: " + remainingBlocks)
}
}
logTrace("Got remote block " + blockId + " after " + Utils.getUsedTimeMs(startTime))
}
override def onBlockFetchFailure(blockId: String, e: Throwable): Unit = {
logError(s"Failed to get block(s) from ${req.address.host}:${req.address.port}", e)
results.put(new FailureFetchResult(BlockId(blockId), address, e))
}
}
第十三步:BlockStoreShuffleReader的read方法中的combineCombinersByKey(combinedKeyValuesIterator, context)
def combineCombinersByKey(
iter: Iterator[_ <: Product2[K, C]],
context: TaskContext): Iterator[(K, C)] = {
val combiners = new ExternalAppendOnlyMap[K, C, C](identity, mergeCombiners, mergeCombiners)
combiners.insertAll(iter)
updateMetrics(context, combiners)
combiners.iterator
}
第十四步:BlockStoreShuffleReader的read方法中的combineValuesByKey(keyValuesIterator, context)
def combineValuesByKey(
iter: Iterator[_ <: Product2[K, V]],
context: TaskContext): Iterator[(K, C)] = {
val combiners = new ExternalAppendOnlyMap[K, V, C](createCombiner, mergeValue, mergeCombiners)
combiners.insertAll(iter)
updateMetrics(context, combiners)
combiners.iterator
}
第十五步:combiners.insertAll(iter)方法
/**
* 将key相同的value进行合并,如果某个key有对应的值就执行merge(也可以理解为更新)操作,如果没有对应的值就新建一个combiner,
* 需要注意的是如果内存不够的话就会将数据spill到磁盘。
*/
def insertAll(entries: Iterator[Product2[K, V]]): Unit = {
if (currentMap == null) {
throw new IllegalStateException(
"Cannot insert new elements into a map after calling iterator")
}
// An update function for the map that we reuse across entries to avoid allocating
// a new closure each time
var curEntry: Product2[K, V] = null
// 定义update函数,主要的逻辑是:如果某个key已经存在记录(record)就使用上面获取
// 的聚合函数进行聚合操作,如果还不存在记录就使用createCombiner方法进行初始化操作
val update: (Boolean, C) => C = (hadVal, oldVal) => {
if (hadVal) mergeValue(oldVal, curEntry._2) else createCombiner(curEntry._2)
}
while (entries.hasNext) {
curEntry = entries.next()
val estimatedSize = currentMap.estimateSize()
if (estimatedSize > _peakMemoryUsedBytes) {
_peakMemoryUsedBytes = estimatedSize
}
if (maybeSpill(currentMap, estimatedSize)) {
currentMap = new SizeTrackingAppendOnlyMap[K, C]
}
currentMap.changeValue(curEntry._1, update)
addElementsRead()
}
}
第十六步: curEntry = entries.next()最终调用ShuffleBlockFetcherIterator的next方法
override def next(): (BlockId, InputStream) = {
if (!hasNext) {
throw new NoSuchElementException
}
numBlocksProcessed += 1
var result: FetchResult = null
var input: InputStream = null
// Take the next fetched result and try to decompress it to detect data corruption,
// then fetch it one more time if it's corrupt, throw FailureFetchResult if the second fetch
// is also corrupt, so the previous stage could be retried.
// For local shuffle block, throw FailureFetchResult for the first IOException.
while (result == null) {
val startFetchWait = System.currentTimeMillis()
result = results.take()
val stopFetchWait = System.currentTimeMillis()
shuffleMetrics.incFetchWaitTime(stopFetchWait - startFetchWait)
......
// Send fetch requests up to maxBytesInFlight
/ 这里就是关键的代码,即不断的去抓去数据,直到抓去到所有的数据
fetchUpToMaxBytes()
}
第十七步:combineValuesByKey中的combiners.iterator
override def iterator: Iterator[(K, C)] = {
if (currentMap == null) {
throw new IllegalStateException(
"ExternalAppendOnlyMap.iterator is destructive and should only be called once.")
}
if (spilledMaps.isEmpty) {
destructiveIterator(currentMap.iterator)
} else {
new ExternalIterator()
}
}
第十八步:ExternalIterator()实例化
/**
* An iterator that sort-merges (K, C) pairs from the in-memory map and the spilled maps
*
* 将所有读取的数据都保存在了mergeHeap中
*/
private class ExternalIterator extends Iterator[(K, C)] {
// A queue that maintains a buffer for each stream we are currently merging
// This queue maintains the invariant that it only contains non-empty buffers
private val mergeHeap = new mutable.PriorityQueue[StreamBuffer]
// Input streams are derived both from the in-memory map and spilled maps on disk
// The in-memory map is sorted in place, while the spilled maps are already in sorted order
// 按照key的hashcode进行排序
private val sortedMap = destructiveIterator(
currentMap.destructiveSortedIterator(keyComparator))
// 将map中的数据和spillFile中的数据的iterator组合在一起
private val inputStreams = (Seq(sortedMap) ++ spilledMaps).map(it => it.buffered)
// 不断迭代,直到将所有数据都读出来,最后将所有的数据保存在mergeHeap中
inputStreams.foreach { it =>
val kcPairs = new ArrayBuffer[(K, C)]
readNextHashCode(it, kcPairs)
if (kcPairs.length > 0) {
mergeHeap.enqueue(new StreamBuffer(it, kcPairs))
}
}