对抗机器学习:Generating Adversarial Malware Examples for Black-box Attacks Based on GAN
论文url
https://arxiv.org/pdf/1702.05983.pdf
@article{hu2017generating,
title={Generating adversarial malware examples for black-box attacks based on GAN},
author={Hu, Weiwei and Tan, Ying},
journal={arXiv preprint arXiv:1702.05983},
year={2017}
}
论文核心的motivation
之前的模型都是基于梯度的,这个是实际情况中不好。如果能够基于黑盒,只需要知道用了什么特征,而不需要知道模型是什么就可以。而且如果能够把那些常规的机器学习模型,比如随机森林,决策树,攻击成功就好了。
怎么知道究竟使用了什么特征呢? 这里特征是很粗粒度的。作者提出可以设计一系列的待测特征去测试目标分类器。比如恶意程序检测,可能会使用API的特征,那么把程序的导入导出表修改一下,然后拿去分类器分类,如果分类结果前后有差异,说明使用了API特征。
作者的方法
作者提出所谓的MalGAN模型:

MalGAN由三部分组成,第一部分是一个生成器,生成器接收恶意样本 m m m 和噪声 z z z 作为输入,输出一个特征向量 o o o, o o o和 m m m是相同维度的。 m m m 是API的 o n e − h o t one-hot one−hot 向量。考虑到实际应用中,为了保持程序的可运行,只能添加往导入、导出表添加新的API名称,而不能删除,因为删除后程序就很有可能因为找不到API而跑不动了。于是取最后的输出为 G θ g ( m , z ) = m a x ( o , m ) G_{\theta g}(m,z)=max(o,m) Gθg(m,z)=max(o,m) 。对于 m m m 中本来为1的量,不会受影响,而 m m m 中为0的量就去生成器的输出,在梯度反向传播的时候只有来自 o o o 的那些分量才能产生梯度,这种方法很巧妙加上了这种阅读!!
Black-box Detector是被攻击的目标分类器模型,该模型接收输入向量,然后给这个输入向量进行分量,
无需detector输出概率分布,只需要给出一个label即可。攻击者只能把它当做Oracle来使用,而不能取里面的模型参数啥的。Black-box可能是个随机森林,SVM或者神经网络。
Substistute Detector是一个代理分类模型 D θ d ( x ) D_{\theta_d} (x) Dθd(x),它是一个神经网络,它的作用是去拟合那个black-box detector,然后给generator提供梯度信息。既然black-box detector获取不到梯度,那么就只能自己整个代理模型去拟合整个black-box。从导师学习的角度来看,black-box就是一个导师,然后substitute是个学生模型,导师把自己的分类能力教给学生。
我们看到,substistute和generator是使用GAN的交替训练方法训练的。而不是先整体求一个代理模型。
训练方法
为了训练MalGAN,攻击者首先得收集恶意样本库和良性样本库。
代理模型的损失函数为:
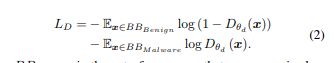
B B B e n i g n BB_{Benign} BBBenign 集合是那些被Black-box detector识别为 B e n i g n Benign Benign的样本库。而 B B M a l w a r e BB_{Malware} BBMalware 是被目标模型识别为恶意的样本集。
生成器的损失函数为:
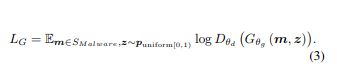
整个训练流程:

实验效果
数据集: 180,000个程序的API 特征向量,这些特征向量是160维的one-hot向量。某个维度的值为1,说明这个样本需要调用这个维度对应的AP.
然后作者还使用不同数据集的划分方法,第一种方法是Black box的训练和MalGAN的训练集一样。第二种方法是Black box和Mal GAN的训练不相交。
Black box detector:作者先用 RF,LR,DT,SVM,MLP,集成模型在上面提到的数据集的某个子集上训练得到一些black-box detector.
攻击结果:
- Black-box 和MalGan相同的训练集:

效果很好,居然可以把RF,DT攻击的那么好,让black box detector 对攻击样本的TPR直接下降到1%一下。
- Black-box和MalGan的训练集不相同

效果一样很不错!DT和RF的 TPR依然可以降到3%一下!
- retrain防御
作者还实验了retrain对malGAN的防御。实验发现,retrain的确特别管用。当black-box的作者收集到足够多的对抗样本后,对black-box模型重新训练一下就能100%的把那些对抗样本识别出来。
虽然如此,black-box的训练者是很难收集全足够的对抗样本,因为GAN可以生成很多很多的对抗样本。
一旦black-box把训练后的模型公开出来以后,MalGan又可以基于这个retrained后的detector自己也重新训练一下。重新训练以后,MalGAN的攻击性能又上去了。而且,MalGan重新训练代价很低,而Black-box收集充足的对抗样本再重新训练却很难。两者的难度不一致,导致retrain在实际应用中作用很有限。
启发
MalGAN 可以视为一种良好的 decision based attack,因为它无需拿到模型参数,也无需拿到模型分类结果的logit或者probability。
不足:
- 作者没有测试这种方法需要产生多少次对black-box的query,才能达到一个良好的攻击效果。猜测这个应该会很大,也没有考虑如何去降低这个query的次数。
- 作者没有交代MalGAN的训练时长。
- 实际情况中,不一定能准确的知道black-box究竟使用了啥具体特征。虽然可以通过测试知道black-box会使用api信息,但是究竟使用什么api?如此测试得到?对于复杂的特征,这是一个很难的工作!