使用NodeJS+Cheerio实现网络爬虫
1.安装 node.js
下载网址 https://nodejs.org/en/

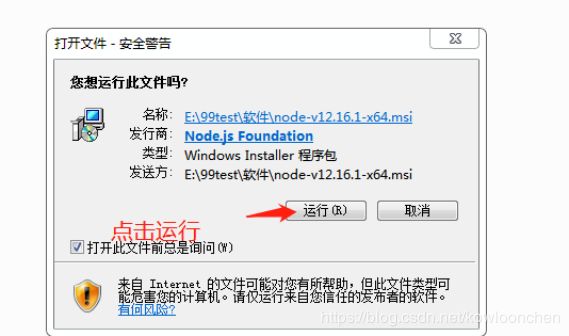
找到下载好的安装文件,双击开始安装



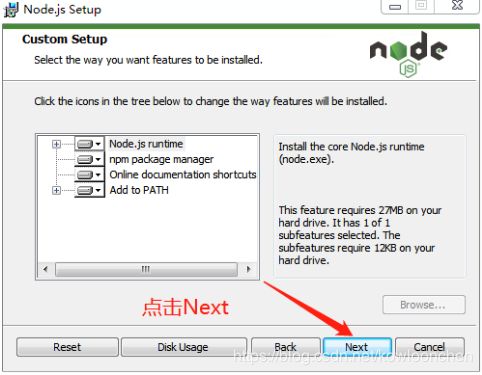
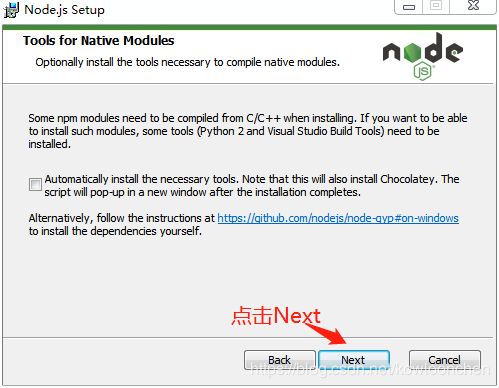
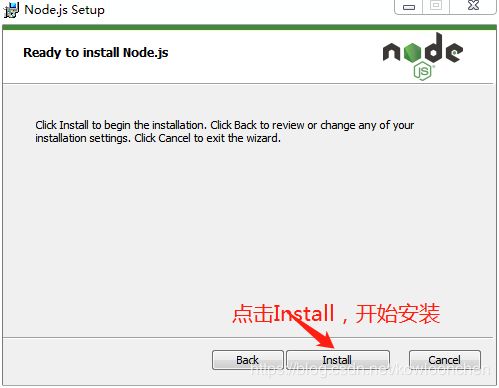


如果安装完成,默认情况下是安装在系统盘的Program Files目录下的:

我们可以打开命令行窗口测试一下能否正常运行node
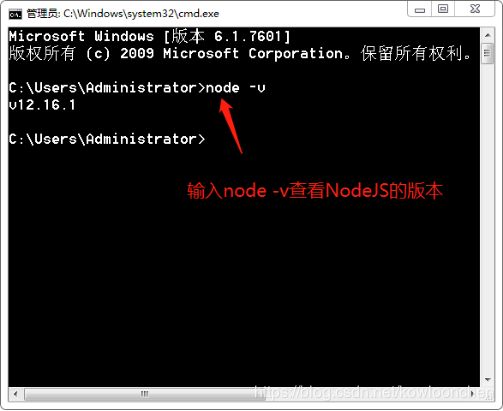
安装Node的同时已经默然安装了我们后面需要的npm工具,我们也可以查看一下npm的版本:

到这里,我们就可以确认已经正常的安装好了NodeJS,下面就可以使用NodeJS来大展身手了。
2.修改 npm 的镜像
因为NodeJS工具在下载安装一些其它工具包的时候,默认是使用的国外的镜像,我们可以修改NodeJS的下载镜像。在命令行执行如下命令:
npm config set -g registry=http://registry.npm.taobao.org/
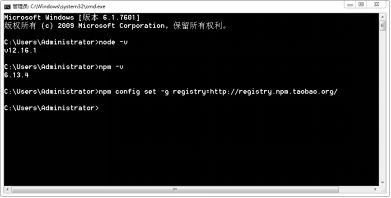
以后在通过NodeJS下载安装资源的时候,就会自动选择国内的taobao镜像。
3.第一个NodeJS程序
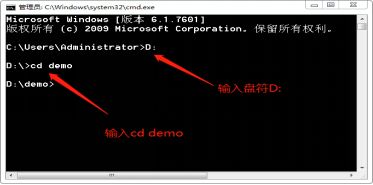
在你喜欢的目录下创建一个文件夹。我在D盘下创建了一个文件夹,名字为demo;

在命令行中将目录切换到你刚才创建的文件夹,我的是D:\demo
初始化Node环境,在命令行执行npm init,此时会要求你填写一些基本信息:

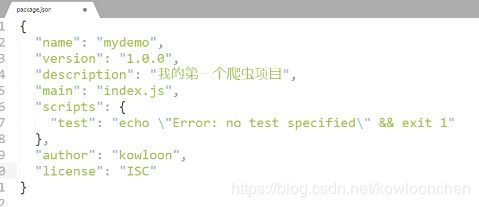
最后输入yes,保存信息。此时会在你的D:\demo文件夹下生成一个package.json的配置文件。
package name: 你的项目名字叫啥
version: 版本号
description: 对项目的描述
entry point: 项目的入口文件(一般你要用那个js文件作为node服务,就填写那个文件)
test command: 项目启动的时候要用什么命令来执行脚本文件(默认为node app.js)
git repository: 如果你要将项目上传到git中的话,那么就需要填写git的仓库地址(这里就不写地址了)
keywords: 项目关键字(我也不知道有啥用,所以我就不写了)
author: 作者的名字(也就是你叫啥名字)
license: 发行项目需要的证书(这里也就自己玩玩,就不写了)
刚才我们填写的数据都被写入到了package.json文件中:
4.在D:\demo目录下创建一个index.js文件
在d:\demo目录下,创建一个index.js文件并开始编写js代码,我们先写一个helloworld程序。
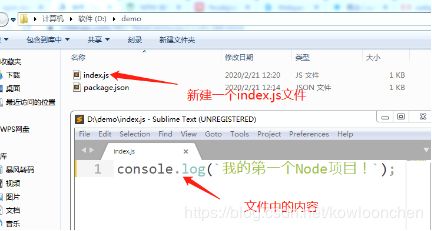
console.log("我的第一个Node项目!");
5.在命令行启动程序
打开命令行,将命令行的目录切换到程序所在的文件夹d:\demo下,执行node index,在node环境下开始执行我们的index.js文件。
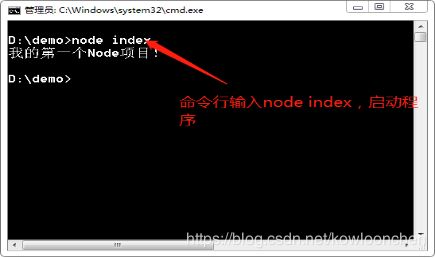
到这里,我们的第一个NodeJS的程序就正常运行了!鼓励一下自己!!
6.开始安装制作爬虫需要的资源:
在命令行中,将目录切换到前面创建的项目目录。安装request,cheerio两个资源包:
![]()
执行结果如下:
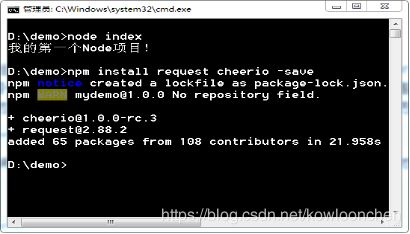
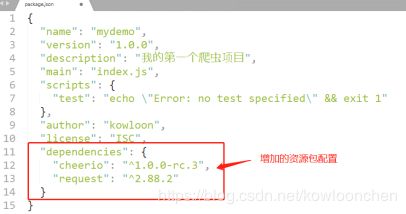
此时,我们的package.json文件中会增加刚才安装的资源包:
7.分析要爬取数据的页面
这里我们已丁香园医生的网站作为要爬取的数据源*[如有侵权,请及时告知,谢谢]*



8.开始在index.js中编写代码
下面我们开始编写爬虫,爬取数据

9.测试结果
写完之后,在命令行执行一下,看看我们爬取的数据结果:

到这里,我们就完成了数据的爬取工作,剩下的事情就是如何来使用这些数据了。