高效的图像加载
文章目录
- 1 安装
- 2 加载图像的方式
- 2.1 Structure
- 2.2 OpenCV
- 2.3 Pillow
- 2.4 Pillow-SIMD
- 2.5 TurboJpeg
- 2.6 LMDB
- 2.7 TFRecords
- 3 加载时间比较
- 4 总结
在编写优化代码时,图像加载在计算机视觉中起着重要作用。此过程可能是许多CV任务的瓶颈,并且通常可能是导致性能不佳的罪魁祸首。我们需要尽可能快地从磁盘获取图像。
这项任务的重要性最明显的例子是在任何CNN训练框架中实现Dataloader类。快速加载图像至关重要。如果不是这样,训练过程将受到CPU的限制,并浪费宝贵的GPU时间。
今天,我们将看一些Python库,这些库使我们能够最高效地读取图像。他们是:
- OpenCV
- Pillow
- Pillow-SIMD
- TurboJpeg
此外,我们还将介绍使用以下从数据库加载图像的替代方法:
- LMDB
- TFRecords
最后,我们将比较每个图片的加载时间,并找出哪个是获胜者!
1 安装
在开始之前,我们需要创建一个虚拟环境:
$ virtualenv -p python3.7 venv
$ source venv/bin/activate
然后,安装所需的库:
$ pip install -r requirements.txt
2 加载图像的方式
2.1 Structure
通常,我们需要加载存储在数据库中或作为文件夹存储的多个图像。在我们的场景中,抽象图像加载器应该能够存储指向这样的数据库或文件夹的路径,并一次从中加载一个图像。此外,我们需要测量代码某些部分的时间。(可选)在加载开始之前可能需要进行一些初始化。我们的ImageLoader类如下所示:
import os
from abc import abstractmethod
class ImageLoader:
extensions: tuple = \
(".png", ".jpg", ".jpeg", ".tiff", ".bmp", ".gif", ".tfrecords")
def __init__(self, path: str, mode: str = "BGR"):
self.path = path
self.mode = mode
self.dataset = self.parse_input(self.path)
self.sample_idx = 0
def parse_input(self, path):
# single image or tfrecords file
if os.path.isfile(path):
assert path.lower().endswith(
self.extensions,
), f"Unsupportable extension, please, use one of
{self.extensions}"
return [path]
if os.path.isdir(path):
# lmdb environment
if any([file.endswith(".mdb") for file in os.listdir(path)]):
return path
else:
# folder with images
paths = \
[os.path.join(path, image) for image in os.listdir(path)]
return paths
def __iter__(self):
self.sample_idx = 0
return self
def __len__(self):
return len(self.dataset)
@abstractmethod
def __next__(self):
pass
不同库中的图像解码函数可以返回不同格式的图像-RGB或BGR。在我们的情况下,我们默认使用BGR色彩模式,但始终可以将其转换为所需的格式。如果您想知道OpenCV使用BGR格式的有趣原因,请单击此链接。
现在,我们可以从基类继承新类,并将其用于我们的任务。
2.2 OpenCV
第一个是OpenCV库。我们可以使用一个简单的函数从磁盘读取图像——cv2.imread。
import cv2
class CV2Loader(ImageLoader):
def __next__(self):
start = timer()
# get image path by index from the dataset
path = self.dataset[self.sample_idx]
# read the image
image = cv2.imread(path)
full_time = timer() - start
if self.mode == "RGB":
start = timer()
# change color mode
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
full_time += timer() - start
self.sample_idx += 1
return image, full_time
在图像可视化之前,我们需要提到OpenCV的cv2.imshow函数需要BGR格式的图像。一些库默认使用RGB图像模式,在这种情况下,我们将图像转换为BGR以实现正确的可视化。
要测试OpenCV库,请使用以下命令:
python3 show_image.py --path images/cat.jpg --method cv2
文本中的此命令和下一个命令将使用不同的库向您显示图像及其加载时间。
如果一切顺利,您将在窗口中看到如下图像:

另外,您可以显示文件夹中的所有图像。除了使用特定的图像,还可以使用包含图像的文件夹的路径:
$ python3 show_image.py --path images/pexels --method cv2
这将一次显示文件夹中的所有图像及其加载时间。要停止演示,可以按ESC按钮。
2.3 Pillow
现在让我们尝试一下PIL库。我们可以使用Image.open函数读取图像。
import numpy as np
from PIL import Image
class PILLoader(ImageLoader):
def __next__(self):
start = timer()
# get image path by index from the dataset
path = self.dataset[self.sample_idx]
# read the image as numpy array
image = np.asarray(Image.open(path))
full_time = timer() - start
if self.mode == "BGR":
start = timer()
# change color mode
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR)
full_time += timer() - start
self.sample_idx += 1
return image, full_time
我们还将Image对象转换为Numpy数组,因为下一步可能需要应用一些增强或预处理,因此Numpy是其默认选择。
要在单个图像上进行检查,可以使用:
$ python3 show_image.py --path images/cat.jpg --method pil
如果要在带有图像的文件夹中使用它:
$ python3 show_image.py --path images/pexels --method pil
2.4 Pillow-SIMD
Pillow库的 fork-follower 具有更高的性能。Pillow-SIMD使用新技术,可以使用与标准Pillow相同的API更快地读取和转换图像。
不能在同一虚拟环境中同时使用Pillow和Pillow-SIMD,默认情况下将使用Pillow-SIMD。
要使用Pillow-SIMD并避免由于Pillow和Pillow-SIMD在一起而导致的错误,您需要创建一个新的虚拟环境并使用:
$ pip install pillow-simd
或者,您可以卸载以前的Pillow版本并安装Pillow-SIMD:
$ pip uninstall pillow
$ pip install pillow-simd
您无需更改代码中的任何内容,前面的示例仍然有效。要检查一切是否正常,可以使用上一个“Pillow”部分中的命令:
$ python3 show_image.py --path images/cat.jpg --method pil
$ python3 show_image.py --path images/pexels --method pil
2.5 TurboJpeg
还有另一个名为TurboJpeg的库。正如标题所示,它只能读取使用JPEG压缩的图像。
让我们使用TurboJpeg创建一个图像加载器。
from turbojpeg import TurboJPEG
class TurboJpegLoader(ImageLoader):
def __init__(self, path, **kwargs):
super(TurboJpegLoader, self).__init__(path, **kwargs)
# create TurboJPEG object for image reading
self.jpeg_reader = TurboJPEG()
def __next__(self):
start = timer()
# open the input file as bytes
file = open(self.dataset[self.sample_idx], "rb")
full_time = timer() - start
if self.mode == "RGB":
mode = 0
elif self.mode == "BGR":
mode = 1
start = timer()
# decode raw image
image = self.jpeg_reader.decode(file.read(), mode)
full_time += timer() - start
self.sample_idx += 1
return image, full_time
TurboJpeg需要对输入图像进行解码,并将其存储为字节字符串。
您可以使用以下命令尝试。但是请记住,TurboJpeg仅允许处理.jpeg图像:
$ python3 show_image.py --path images/cat.jpg --method turbojpeg
$ python3 show_image.py --path images/pexels --method turbojpeg
2.6 LMDB
当优先考虑速度时,通常使用的图像加载方法是事先将数据转换为更好的表示形式(数据库或序列化缓冲区)。这种“数据库”的最大优势之一是,它们每次数据访问的系统调用数为零,而文件系统每次数据访问则需要多个系统调用。我们可以创建一个LMDB数据库,该数据库将以键值格式收集所有图像。
以下函数使我们可以使用图像创建LMDB环境。LMDB的“环境”实质上是一个文件夹,其中包含由LMDB库创建的特殊文件。此函数只需要包含图像路径和保存路径的列表:
import cv2
import lmdb
import numpy as np
def store_many_lmdb(images_list, save_path):
# number of images in our folder
num_images = len(images_list)
# all file sizes
file_sizes = [os.path.getsize(item) for item in images_list]
# the maximum file size index
max_size_index = np.argmax(file_sizes)
# maximum database size in bytes
map_size = num_images * cv2.imread(images_list[max_size_index]).nbytes * 10
# create lmdb environment
env = lmdb.open(save_path, map_size=map_size)
# start writing to environment
with env.begin(write=True) as txn:
for i, image in enumerate(images_list):
with open(image, "rb") as file:
# read image as bytes
data = file.read()
# get image key
key = f"{i:08}"
# put the key-value into database
txn.put(key.encode("ascii"), data)
# close the environment
env.close()
有一个Python脚本可使用图像创建LMDB环境:
--path参数应包含您收集的图像文件夹的路径--output参数是将在其中创建LMDB的目录
$ python3 create_lmdb.py --path images/pexels --output lmdb/images
现在,随着LMDB环境的创建,我们可以从中加载图像。让我们创建一个新的加载程序类。
在从数据库加载图像的情况下,我们需要打开该数据库进行读取。有一个名为open_database的新函数。它返回迭代器以浏览打开的数据库。另外,当此迭代器到达数据末尾时,我们需要使用_iter_函数将其返回到数据库的开头。
LMDB允许我们存储数据,但是没有内置的图像解码器。由于缺少解码器,我们将在此处使用cv2.imdecode函数。
class LmdbLoader(ImageLoader):
def __init__(self, path, **kwargs):
super(LmdbLoader, self).__init__(path, **kwargs)
self.path = path
self._dataset_size = 0
self.dataset = self.open_database()
# we need to open the database to read images from it
def open_database(self):
# open the environment by path
lmdb_env = lmdb.open(self.path)
# start reading
lmdb_txn = lmdb_env.begin()
# create cursor to iterate through the database
lmdb_cursor = lmdb_txn.cursor()
# get number of items in full dataset
self._dataset_size = lmdb_env.stat()["entries"]
return lmdb_cursor
def __iter__(self):
# set the cursor to the first database element
self.dataset.first()
return self
def __next__(self):
start = timer()
# get raw image
raw_image = self.dataset.value()
# convert it to numpy
image = np.frombuffer(raw_image, dtype=np.uint8)
# decode image
image = cv2.imdecode(image, cv2.IMREAD_COLOR)
full_time = timer() - start
if self.mode == "RGB":
start = timer()
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
full_time += timer() - start
start = timer()
# step to the next element in database
self.dataset.next()
full_time += timer() - start
return image, full_time
def __len__(self):
# get dataset length
return self._dataset_size
创建环境和加载程序类之后,我们可以检查其正确性并显示其中的图像。现在,在--path参数中,我们需要提及LMDB环境的路径。请记住,您可以使用ESC按钮停止显示。
$ python3 show_image.py --path lmdb/images --method lmdb
2.7 TFRecords
另一个有用的数据库是TFRecords。为了有效地读取数据,对数据进行序列化并将其存储在一组可以线性读取的文件(每个100-200MB)中会很有帮助(TensorFlow手册)。
在创建tfrecords文件之前,我们需要选择数据库的结构。TFRecords允许保留具有许多其他功能的项目。如果需要,可以保存文件名或图像的宽度和高度。所有这些东西都应该收集在python字典中,即:
image_feature_description = {
"height" :tf.io.FixedLenFeature([], tf.int64),
"width" :tf.io.FixedLenFeature([], tf.int64),
"filename": tf.io.FixedLenFeature([], tf.string),
"label": tf.io.FixedLenFeature([], tf.int64),
"image_raw": tf.io.FixedLenFeature([], tf.string),
}
在我们的示例中,我们将仅使用原始字节格式的图像及其唯一的键,称为“标签”。
import os
import tensorflow as tf
def _byte_feature(value):
"""Convert string / byte into bytes_list."""
if isinstance(value, type(tf.constant(0))):
# BytesList can't unpack string from EagerTensor.
value = value.numpy()
return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value]))
def _int64_feature(value):
"""Convert bool / enum / int / uint into int64_list."""
return tf.train.Feature(int64_list=tf.train.Int64List(value=[value]))
def image_example(image_string, label):
feature = {
"label": _int64_feature(label),
"image_raw": _byte_feature(image_string),
}
return tf.train.Example(features=tf.train.Features(feature=feature))
def store_many_tfrecords(images_list, save_file):
assert save_file.endswith(
".tfrecords"
), 'File path is wrong, it should contain "*myname*.tfrecords"'
directory = os.path.dirname(save_file)
if not os.path.exists(directory):
os.makedirs(directory)
# start writer
with tf.io.TFRecordWriter(save_file) as writer:
# cycle by each image path
for label, filename in enumerate(images_list):
# read the image as bytes string
image_string = open(filename, "rb").read()
# save the data as tf.Example object
tf_example = image_example(image_string, label)
# and write it into database
writer.write(tf_example.SerializeToString())
请注意,因为我们所有的图像都存储为JPEG文件,所以我们使用tf.image.decode_jpeg函数转换图像。您还可以将tf.image.decode_image用作通用解码器。
要检查所创建数据库的正确性,可以显示其中的图像:
$ python3 show_image.py --path tfrecords/images.tfrecords --method tfrecords
3 加载时间比较
我们将使用来自pexels.com的一些具有不同形状和jpeg扩展名的开放图像。并且所有时间测量值将平均进行5000次迭代。此外,平均将减轻OS /硬件特定逻辑(例如数据缓存)的影响。可以预期,正在评估的第一种方法中的第一次迭代将遭受从磁盘到缓存的数据初始加载,而其他方法将没有这种情况。
所有实验都针对BGR和RGB图像模式运行,以涵盖所有潜在需求和不同任务。请记住,Pillow和Pillow-SIMD不能在同一虚拟环境中使用。为了创建最终的比较表,我们对Pillow和Pillow-SIMD做了两个单独的实验。
要运行测量,请使用:
python3 benchmark.py --path images/pexels --method cv2 pil turbojpeg lmdb tfrecords --iters 100 --mode BGR
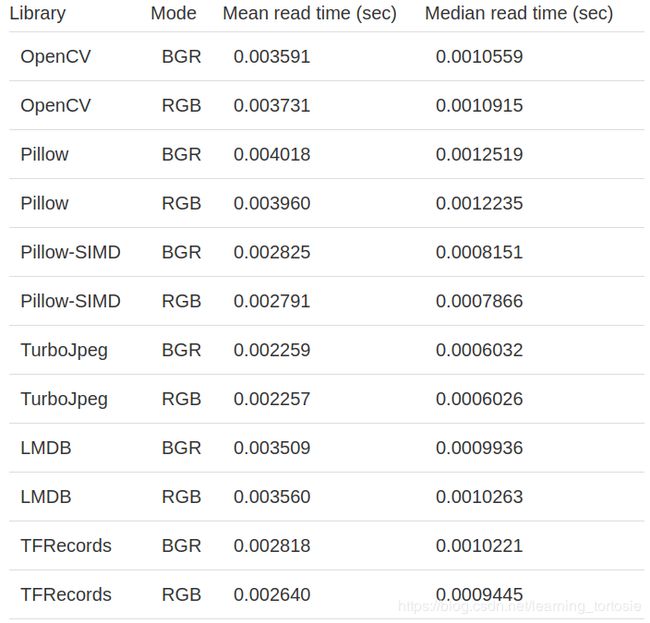


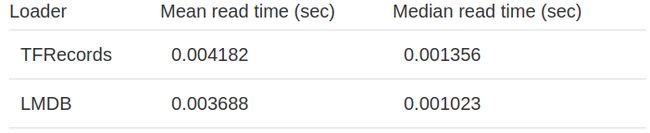
而且,将数据库的读取速度与相同的解码器功能进行比较将很有趣。它可以显示哪个数据库更快地加载其数据。在这种情况下,我们对TFRecords和LMDB使用cv2.imdecode函数。
所有实验的计算依据:
- Intel® Core™ i7-2600 CPU @ 3.40GHz × 8
- Ubuntu 16.04 64-bit
- Python 3.7
4 总结
在此博客中,我们考虑了一些图像加载方法,并将它们相互比较。JPEG图像上的比较结果非常有趣。我们可以看到TurboJpeg是将图像加载为numpy最快的库,但是有一个例外——它只能读取jpeg扩展名的文件。
值得一提的另一件事是,Pillow-SIMD比原始Pillow更快。在我们的任务中,加载速度提高了近40%。
如果您打算使用图像数据库,尤其是由于内置的解码器函数,TFRecords的平均结果要比LMDB更好。另一方面,LMDB使我们可以更快地读取图像。当然,您始终可以将解码器函数和数据库结合在一起,例如,使用TurboJpeg作为解码器,并使用LMDB作为图像存储。