神经网络理论知识
感知器:

一个感知器有如下组成部分:
输入权值——一个感知器可以接收多个输入(x1,x2,…xn),每个输入上有一个权值wi,此外还有一个偏置项b,就是上图中的w0。
激活函数——感知器的激活函数可以有很多选择
输出——感知器的输出由某个公式来计算
事实上,感知器不仅仅能实现简单的布尔运算。它可以拟合任何的线性函数,任何线性分类或线性回归问题都可以用感知器来解决。前面的布尔运算可以看作是二分类问题,即给定一个输入,输出0(属于分类0)或1(属于分类1)。然而,感知器却不能实现异或运算。
感知器的训练
训练感知器对于多层感知器的监督式训练最常见的深度学习算法是反向传播。基本的过程是 :
1、将训练样本通过神经网络进行前向传播计算。
2、计算输出误差,通常用均方差:
其中 t 是目标值,y是实际的神经网络输出。其它的误差计算方法也可以,但MSE(均方差)通常是一种比较好的选择。
3.网络误差通过随机梯度下降法来最小化。
前面的权重项和偏置项的值是如何获得的呢?
这就要用到感知器训练算法:将权重项和偏置项初始化为0,然后,利用下面的感知器规则迭代的修改wi和b,直到训练完成。

其中:

wi是与输入xi对应的权重项,b是偏置项。事实上,可以把b看作是值永远为1的输入xb所对应的权重。t是训练样本的实际值,一般称之为label。而y是感知器的输出值,它是根据公式(1)计算得出。η是一个称为学习速率的常数,其作用是控制每一步调整权的幅度。
每次从训练数据中取出一个样本的输入向量x,使用感知器计算其输出y,再根据上面的规则来调整权重。每处理一个样本就调整一次权重。经过多轮迭代后(即全部的训练数据被反复处理多轮),就可以训练出感知器的权重,使之实现目标函数。
(简单感知器实现and运算)
**
神经网络实际上就是将感知器进行组合,用不同的方式进行连接并作用在不同的激活函数上
**
激活函数
所谓激活函数(Activation Function),就是在人工神经网络的神经元上运行的函数,负责将神经元的输入映射到输出端。
几种常用激活函数:
1. sigmod函数
函数公式和图表如下图
![]()

在sigmod函数中我们可以看到,其输出是在(0,1)这个开区间内,可以联想到概率,但是严格意义上不要当成概率。sigmod函数可以想象成一个神经元的放电率,在中间斜率比较大的地方是神经元的敏感区,在两边斜率很平缓的地方是神经元的抑制区。函数本身是有一定的缺陷的。
- 当输入稍微远离了坐标原点,函数的梯度就变得很小了,几乎为零。在神经网络反向传播的过程中,都是通过微分的链式法则来计算各个权重w的微分的。当反向传播经过了sigmod函数,这个链条上的微分就很小很小了,况且还可能经过很多个sigmod函数,最后会导致权重w对损失函数几乎没影响,这样不利于权重的优化,这个问题叫做梯度饱和,梯度弥散。
- 函数输出不是以0为中心的,这样会使权重更新效率降低。
- sigmod函数要进行指数运算,这个对于计算机来说是比较慢的。
2.tanh函数
tanh函数公式和曲线如下

tanh是双曲正切函数,tanh函数和sigmod函数的曲线是比较相近的。相同的是,这两个函数在输入很大或是很小的时候,输出都几乎平滑,梯度很小,不利于权重更新;不同的是输出区间,tanh的输出区间是在(-1,1)之间,而且整个函数是以0为中心的,这个特点比sigmod的好。
一般二分类问题中,隐藏层用tanh函数,输出层用sigmod函数。不过这些也都不是一成不变的,具体使用什么激活函数,还是要根据具体的问题来具体分析,还是要靠调试的。
3.ReLU函数
ReLU函数公式和曲线如下

ReLU(Rectified Linear Unit)函数是目前比较火的一个激活函数,相比于sigmod函数和tanh函数,它有以下几个优点:
- 在输入为正数的时候,不存在梯度饱和问题。
- 计算速度要快很多。ReLU函数只有线性关系,不管是前向传播还是反向传播,都比sigmod和tanh要快很多。(sigmod和tanh要计算指数,计算速度会比较慢)
当然,缺点也是有的: - 当输入是负数的时候,ReLU是完全不被激活的,这就表明一旦输入到了负数,ReLU就会死掉。这样在前向传播过程中,还不算什么问题,有的区域是敏感的,有的是不敏感的。但是到了反向传播过程中,输入负数,梯度就会完全到0,这个和sigmod函数、tanh函数有一样的问题。
- 我们发现ReLU函数的输出要么是0,要么是正数,这也就是说,ReLU函数也不是以0为中心的函数。
4.ELU函数
ELU函数公式和曲线如下图

ELU函数是针对ReLU函数的一个改进型,相比于ReLU函数,在输入为负数的情况下,是有一定的输出的,而且这部分输出还具有一定的抗干扰能力。这样可以消除ReLU死掉的问题,不过还是有梯度饱和和指数运算的问题。
5.PReLU函数
PReLU函数公式和曲线如下图
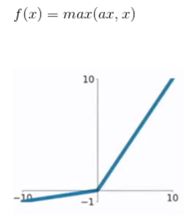
PReLU也是针对ReLU的一个改进型,在负数区域内,PReLU有一个很小的斜率,这样也可以避免ReLU死掉的问题。相比于ELU,PReLU在负数区域内是线性运算,斜率虽然小,但是不会趋于0,这算是一定的优势。
我们看PReLU的公式,里面的参数α一般是取0~1之间的数,而且一般还是比较小的,如零点零几。当α=0.01时,我们叫PReLU为Leaky ReLU,算是PReLU的一种特殊情况。
总体来看,这些激活函数都有自己的优点和缺点,没有一条说法表明哪些就是不行,哪些激活函数就是好的,所有的好坏都要自己去实验中得到。
监督学习和无监督学习
机器学习有一类学习方法叫做监督学习,它是说为了训练一个模型,我们要提供这样一堆训练样本:每个训练样本既包括输入特征x,也包括对应的输出y(y也叫做标记,label)。也就是说,我们要找到很多人,我们既知道他们的特征(工作年限,行业…),也知道他们的收入。我们用这样的样本去训练模型,让模型既看到我们提出的每个问题(输入特征x),也看到对应问题的答案(标记y)。当模型看到足够多的样本之后,它就能总结出其中的一些规律。然后,就可以预测那些它没看过的输入所对应的答案了。
另外一类学习方法叫做无监督学习,这种方法的训练样本中只有x而没有y。模型可以总结出特征的一些规律,但是无法知道其对应的答案y。
很多时候,既有x又有y的训练样本是很少的,大部分样本都只有x。比如在语音到文本(STT)的识别任务中,x是语音,y是这段语音对应的文本。我们很容易获取大量的语音录音,然而把语音一段一段切分好并标注上对应文字则是非常费力气的事情。这种情况下,为了弥补带标注样本的不足,我们可以用无监督学习方法先做一些聚类,让模型总结出哪些音节是相似的,然后再用少量的带标注的训练样本,告诉模型其中一些音节对应的文字。这样模型就可以把相似的音节都对应到相应文字上,完成模型的训练。
模型的训练,实际上就是求取到合适的w,使残差平方和取得最小值。这在数学上称作优化问题,而E(w)就是我们优化的目标,称之为目标函数。
梯度下降优化算法
我们每次都是向函数y=f(x)的梯度的相反方向来修改x。梯度是一个向量,它指向函数值上升最快的方向。显然,梯度的反方向当然就是函数值下降最快的方向了。我们每次沿着梯度相反方向去修改的值,当然就能走到函数的最小值附近。之所以是最小值附近而不是最小值那个点,是因为我们每次移动的步长不会那么恰到好处,有可能最后一次迭代走远了越过了最小值那个点。步长的选择是重点,如果选择小了,那么就会迭代很多轮才能走到最小值附近;如果选择大了,那可能就会越过最小值很远,收敛不到一个好的点上。

梯度下降算法的公式:
![]()
其中,▽是梯度算子,▽f(x)就是指f(x)的梯度。η是步长,η也称作学习速率。
随机梯度下降算法(Stochastic Gradient Descent, SGD)与批梯度下降(BatchGradient Descent)
如果我们训练模型,那么我们每次更新w的迭代,要遍历训练数据中所有的样本进行计算,我们称这种算法叫做批梯度下降(BatchGradient Descent)。如果我们的样本非常大,比如数百万到数亿,那么计算量异常巨大。因此,实用的算法是SGD算法。在SGD算法中,每次更新w的迭代,只计算一个样本。这样对于一个具有数百万样本的训练数据,完成一次遍历就会对w更新数百万次,效率大大提升。由于样本的噪音和随机性,每次更新w并不一定按照减少E的方向。然而,虽然存在一定随机性,大量的更新总体上沿着减少E的方向前进的,因此最后也能收敛到最小值附近。
最后需要说明的是,SGD不仅仅效率高,而且随机性有时候反而是好事。目标函数是一个『凸函数』,沿着梯度反方向就能找到全局唯一的最小值。然而对于非凸函数来说,存在许多局部最小值。随机性有助于我们逃离某些很糟糕的局部最小值,从而获得一个更好的模型。
小结:
事实上,一个机器学习算法其实只有两部分
模型从输入特征x预测输入y的那个函数h(x)目标函数,目标函数取最小(最大)值时所对应的参数值,就是模型的参数的最优值。很多时候我们只能获得目标函数的局部最小(最大)值,因此也只能得到模型参数的局部最优值。
因此,如果你想最简洁的介绍一个算法,列出这两个函数就行了。
接下来,用优化算法去求取目标函数的最小(最大)值。[随机]梯度{下降|上升}算法就是一个优化算法。针对同一个目标函数,不同的优化算法会推导出不同的训练规则。
其实在机器学习中,算法往往并不是关键,真正的关键之处在于选取特征。选取特征需要我们人类对问题的深刻理解,经验、以及思考。而神经网络算法的一个优势,就在于它能够自动学习到应该提取什么特征,从而使算法不再那么依赖人。
神经元
神经元和感知器本质上是一样的,只不过我们说感知器的时候,它的激活函数是阶跃函数;而当我们说神经元时,激活函数往往选择为sigmoid函数或tanh函数。如下图所示:

计算一个神经元的输出的方法和计算一个感知器的输出是一样的。
神经网络
神经网络其实就是按照一定规则连接起来的多个神经元。

它的规则包括:
神经元按照层来布局。最左边的层叫做输入层,负责接收输入数据;最右边的层叫输出层,我们可以从这层获取神经网络输出数据。输入层和输出层之间的层叫做隐藏层,因为它们对于外部来说是不可见的。同一层的神经元之间没有连接。第N层的每个神经元和第N-1层的所有神经元相连(这就是full connected的含义),第N-1层神经元的输出就是第N层神经元的输入。每个连接都有一个权值。
上面这些规则定义了全连接神经网络的结构。事实上还存在很多其它结构的神经网络,比如卷积神经网络(CNN)、循环神经网络(RNN),他们都具有不同的连接规则。
神经网络的训练——BP神经网络
我们需要知道一个神经网络的每个连接上的权值是如何得到的。我们可以说神经网络是一个模型,那么这些权值就是模型的参数,也就是模型要学习的东西。然而,一个神经网络的连接方式、网络的层数、每层的节点数这些参数,则不是学习出来的,而是人为事先设置的。对于这些人为设置的参数,我们称之为超参数(Hyper-Parameters)。
设计神经网络结构
1.使用神经网络训练数据之前,必须确定神经网络层数,以及每层单元个数
2.特征向量在被传入输入层时通常被先标准化(normalize)和0和1之间(为了加强学习过程)-归一化
3.离散型变量可以被编码成每一个输入单元对应一个特征可能赋的值
比如:特征值A可能取三个值(a0,a1,a2),可以使用三个输入单元来代表A
如果A=a0,那么代表a0的单元值就取1,其他取0
如果A=a1,那么代表a1的单元值就取1,其他取0,以此类推
4.神经网络即可以用来做分类(classification)问题,也可以解决回归(regression)问题。对于分类问题,如果是2类,可以用一个输入单元表示(0和1分别代表2类)
如果多于两类,每一个类别用一个输出单元表示
所以输入层的单元数量通常等于类别的数量,没有明确的规则来设计最好有多少个隐藏层,根据实验测试和误差,以及准确度来实验并改进。

反向传播算法(Back Propagation)
以监督学习为例来解释反向传播算法。设神经元的激活函数f为sigmoid函数(不同激活函数的计算公式不同)。
假设每个训练样本为(x,t),其中向量x是训练样本的特征,而t是样本的目标值。

计算一个节点的误差项,需要先计算每个与其相连的下一层节点的误差项。这就要求误差项的计算顺序必须是从输出层开始,然后反向依次计算每个隐藏层的误差项,直到与输入层相连的那个隐藏层。这就是反向传播算法的名字的含义。当所有节点的误差项计算完毕后,我们就可以根据 来更新所有的权重。(其中,wji是节点i到节点j的权重,η是一个成为学习速率的常数,б是节点j的误差项,xji是节点i传递给节点j的输入)
超参数的确定
在实现网络模型训练前,我们首先需要确定网络的层数和每层的节点数。关于第一个问题,实际上并没有什么理论化的方法,大家都是根据经验来。然后,你可以多试几个值,训练不同层数的神经网络,看看哪个效果最好就用哪个。
不过,网络层数越多越好,层数越多训练难度越大。对于全连接网络,隐藏层最好不要超过三层。那么,我们可以先试试仅有一个隐藏层的神经网络效果怎么样。
输入层节点数一般是确定的,它是我们能提供的特征数目。输出层节点数也是确定的,也就是我们所区分的分类数目。输出节点,每个节点对应一个分类。输出最大值的那个节点对应的分类,就是模型的预测结果。
隐藏层节点数量是不好确定的,从1到100万都可以。下面有几个经验公式:
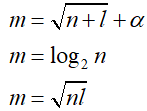
(m是隐藏层节点数,n是输入层节点数,l输出层节点数,α是1到10的常数)
误差的反向传播
误差反向传播:输出误差(某种形式)->隐层(逐层)->输入层 其主要目的是通过将输出误差反传,将误差分摊给各层所有单元,从而获得各层单元的误差信号进而修正各单元的权值(其过程,是一个权值调整的过程)。注:权值调整的过程,也就是网络的学习训练过程(学习也就是这么的由来,权值调整)。
标准BP算法的缺陷:
1)易形成局部极小(属贪婪算法,局部最优)而得不到全局最优;
2)训练次数多使得学习效率低下,收敛速度慢(需做大量运算);
3)隐节点的选取缺乏理论支持;
4)训练时学习新样本有遗忘旧样本趋势。
注:改进算法—增加动量项、自适应调整学习速率及引入陡度因子
线性回归模拟器、神经网络模拟器(XOR)、埃尔曼递归网络(正弦函数)、Q学习模拟器:https://www.mladdict.com/linear-regression-simulator
#归一化:消除不同数据之间的量纲,方便数据比较和共同处理,并维持了数据的稀疏性质
比如在神经网络中,归一化可以加快训练网络的收敛性。
数据预处理(https://blog.csdn.net/cxmscb/article/details/54977740)
1. 缺失值处理
from sklearn.preprocessing import Imputer1
x = np.array([[ 1, 2 , 0],
[0, np.NaN,0],
[0, 0, 1]]);
imputer = Imputer(missing_values=‘NaN’,strategy=‘mean’,axis=0,copy=False)
imputer.fit_transform(x[:,1])
out:
array([[ 1., 2., 0.],
[ 0., 1., 0.],
[ 0., 0., 1.]])
2. 特征值的归一化
归一化的好处:
当特征的数值范围差距较大时,需要对特征的数值进行标准化,防止某些特征的权重过大,让每个特征的地位相对平等,对结果做出的贡献相同。一般对连续性特征值处理。
提升模型的收敛速度(梯度下降)。
from sklearn import preprocessing
import numpy as np
X = np.array([[1., -1., 2.],
[2., 0., 0.],
[0., 1., -1.]])
#对每一列特征的数值归一化(均值为0,方差为1)
print preprocessing.scale(X)
out:
array([[ 0. , -1.22474487, 1.33630621],
[ 1.22474487, 0. , -0.26726124],
[-1.22474487, 1.22474487, -1.06904497]])
使用StandardScaler对象进行归一化
StandardScaler对象可以保存训练集中的参数(均值、方差),之后可以直接使用其对象转换测试集数据。
from sklearn.preprocessing import StandardScaler # 对数据标准
scaler = StandardScaler()
X_std_train = scaler.fit_transform(X_train)
X_std_test = scaler.transform(X_test)
其他预处理:
#区间缩放
from sklearn.preprocessing import MinMaxScaler
#归一化
from sklearn.preprocessing import Normalizer
#二值化(大于阈值的为1,小于等于则为0)
from sklearn.preprocessing import Binarizer
验证归一化的重要性
使用svm模型
如果希望更多地控制 SGD 中的停止标准或学习率,或者想要进行额外的监视,使用 warm_start=True 和 max_iter=1 并且自身迭代可能会有所帮助:
X = [[0., 0.], [1., 1.]]
y = [0, 1]
clf = MLPClassifier(hidden_layer_sizes=(15,), random_state=1, max_iter=1, warm_start=True)
for i in range(10):
… clf.fit(X, y)
… # additional monitoring / inspection
MLPClassifier(…
warm_start:一个布尔值。如果为True,那么使用前一次训练结果继续训练,否则从头开始训练
max_iter:一个整数,指定最大迭代数