Mapreduce实例---连表查询(join)
一:问题介绍
订单详情表 detail
order_id item_id amount
12 sp001 2
12 sp002 4
12 sp003 3
13 sp001 2
13 sp002 4
商品信息表 iteminfo
item_id item_type
sp001 type001
sp002 type002
sp003 type002
结果:
将两张表连起来,输出下面的数据:
order_id item_id amount item_id item_type
二:解题思路
(1)reduce端join实现

缺点:当reduce task1处理的数据量很大,而reduce task2处理的数据量很小的时候(数据倾斜),会降低效率。所以出现的方法(2)map端join实现。
(2)map端join实现
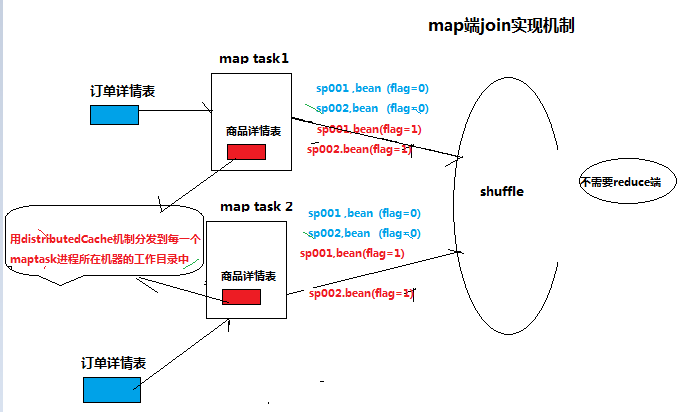
缺点:不会受到数据倾斜的影响,但只适用于大小表join的情况。(detail表很大,iteminfo表很小)
三:代码
(1)reduce端join实现
public class ReduceSideJoin {
static class ReduceSideJoinMapper extends Mapper {
// 从源数据中读取一行后,切分成各个字段,然后将join条件:item_id作为key,其他信息作为整个value输出
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] fields = value.toString().split(",");
String order_id = "";
String item_id = "";
String amount = "";
String item_typ = "";
String flag = "0"; // 如果来自于订单详情表,flag标志置为0,否则为1
// 需要判断正在处理中的这一行数据是来自于哪个文件
FileSplit inputSplit = (FileSplit) context.getInputSplit();
String fileName = inputSplit.getPath().getName();
if ("detail.txt".equals(fileName)) { // 如果这一行数据来自于订单详情表
order_id = fields[0];
item_id = fields[1];
amount = fields[2];
} else { // 如果这一行数据来自于商品信息表
item_id = fields[0];
item_typ = fields[1];
flag = "1";
}
JoinBean bean = new JoinBean(order_id, item_id, amount, item_typ, flag);
context.write(new Text(item_id), bean);
}
}
static class ReduceSideJoinReducer extends Reducer {
/*
* sp001 --->( 12 sp001 2 ) 来自于订单详情
* sp001 --->( 13 sp001 2 )
* sp001 --->( ... )
* sp001 --->( sp001 type001 ) 来自于商品表
*/
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
String type = null;
ArrayList detailBeans = new ArrayList();
for (JoinBean bean : values) {
if ("1".equals(bean.getFlag())) { // 如果这个bean是来自于商品表
type = bean.getItem_typ();
} else {
// detailBeans.add(bean);
// 不能这样写!!!原因是,这种写法,每次往list中添加的都是同一个对象
detailBeans.add(new JoinBean(bean.getOrder_id(), bean.getItem_id(), bean.getAmount(), bean.getItem_typ(), bean.getFlag()));
}
}
for (JoinBean bean : detailBeans) {
// 把商品类别字段join到订单详情记录中
bean.setItem_typ(type);
context.write(NullWritable.get(), bean);
}
}
}
public static void main(String[] args) throws Exception, IOException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(ReduceSideJoin.class);
job.setMapperClass(ReduceSideJoinMapper.class);
job.setReducerClass(ReduceSideJoinReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(JoinBean.class);
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(JoinBean.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
boolean res = job.waitForCompletion(true);
System.exit(res ? 0 : 1);
}
} (2)map端join实现
public class MapSideJoin {
static class MapSideJoinMapper extends Mapper {
private HashMap iteminfo = new HashMap();
/**
* setup()方法是由map task在执行map处理逻辑之前执行的一个初始化方法,仅执行一次
* 所以,我们可以在setup方法中,将“分布式缓存distributedCache”(maptask进程所在的工作目录中)
* 的商品信息文件加载到内存
*/
@Override
protected void setup(Context context) throws IOException, InterruptedException {
// 读取分布式缓存机制分发到进程本地的商品信息表文件,将文件内容加载到内存的hashmap中
BufferedReader br = new BufferedReader(new FileReader("iteminfo.txt"));
String line = null;
while (null != (line = br.readLine())) {
String[] fields = line.split(",");
iteminfo.put(fields[0], fields[1]);
}
br.close();
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 这是map task进程帮我们从输入数据也就是订单详情表中读入的一行
String line = value.toString();
// order_id item_id amount
String[] fields = line.split(",");
String order_id = fields[0];
String item_id = fields[1];
String amount = fields[2];
String item_type = iteminfo.get(item_id); // 需要从商品信息表中去获取,而商品信息表已经在setup方法中加载到了hashmap中了
JoinBean bean = new JoinBean(order_id, item_id, amount, item_type, "");
context.write(NullWritable.get(), bean);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(MapSideJoin.class);
job.setMapperClass(MapSideJoinMapper.class);
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(JoinBean.class);
// 将hdfs上的一个文件添加到mapreduce框架提供的distributedCache中
// distributedCache的本质就是将文件分发到每一个map task进程所在机器的工作目录中
job.addCacheFile(new URI("hdfs://192.168.77.70:9000/tocache/iteminfo.txt"));
//因为mapside-join机制中不需要reduce阶段,所以通过这句代码强制限定reduce task数量为0
job.setNumReduceTasks(0);
// 注意:输入数据中只包含订单详情文件
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
}