kettle集群部署
Kettle集群部署
1) Kettle集群简介
集群技术可以用来水平扩展转换,使得他们能够同时运行在多台服务器上。它将转换的工作量均分到不同的服务器上。这一部分,我们将介绍怎样配置和执行一个转换,让其运行在多台机器上。
一个集群schema由一台主服务器,和一些子服务器组成,主服务器作为一个集群的控制器。简单的说,我们提到的Carte控制服务器就是主服务器,其他的Carte服务器就是子服务器。
2) Kettle集群优劣势
集群的优点
和其它系统的集群一样,有以下优点:
1)多服务器运行,加快处理速度,对于大数据量的操作更明显。
2)防单点失败,一台服务器故障后其它服务器还可以运行。
集群的缺点
1)采用主从结构,不具备自动切换主从的功能。所以一旦主节点宕机,整个系统不可用。
2)对网络要求高,节点之间需要不断的传输数据。
3)需要更多的服务器,而且主节点没有处理能力(在该步骤没有处理能力,在其他的没有使用集群功能的步骤仍具有处理能力)。
适用场景
适合于:
1)需求kettle能时刻保持正常运行的场景。
2)大批量处理数据的场景。
3) linux下解压部署
解压安装包
将下载好的kettledata-integration.zip上传到linux服务器,解压放置目录下,每台节点都需要
命令:Tar zvcf data-integration.zip
解压完后执行sh kitchen.sh

可以看到上面出现 -rep,-user,-pass 这些kettle中的帮助信息,说明kettle部署成功
调出spoon界面
在windows系统上面是执行spoon.bat 同理在linux系统上面执行spoon.sh调出spoon的界面进行开发。
执行./spoon.sh,查看信息

这里说一下,调出spoon界面需要linux客户端支持图形化服务,使用xshell,需进行如下图设置,同时需要本地有安装xmanager

Xmanager各节点需进行如下设置

设置完成后,执行./spoon.sh
xmanager图形界面成功调出,弹出界面如下
查看端口占用情况
命令:netstat -tunlp |grep 8080
![]()
LISTEN代表8080被占用,改为8088端口
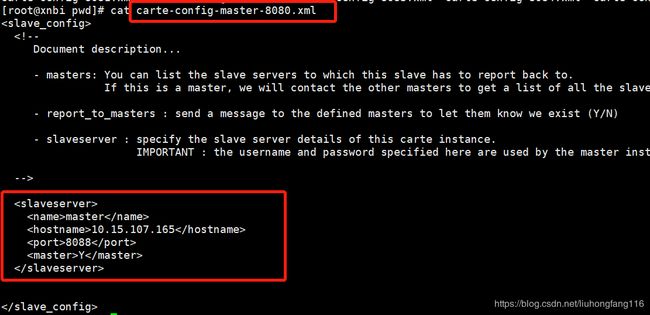
修改carte-config配置文件
各节点修改data-integration/pwd/carte-config-master-8080.xml
各节点修改carte-config-8081.xml
各节点修改carte-config-8082.xml

4) 启动carte服务
启动carte服务
登录主机165
./carte.sh 10.15.107.165 8088

验证节点是否启动
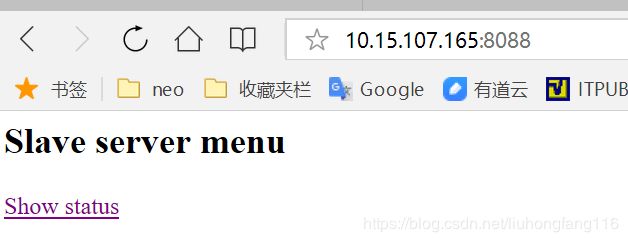
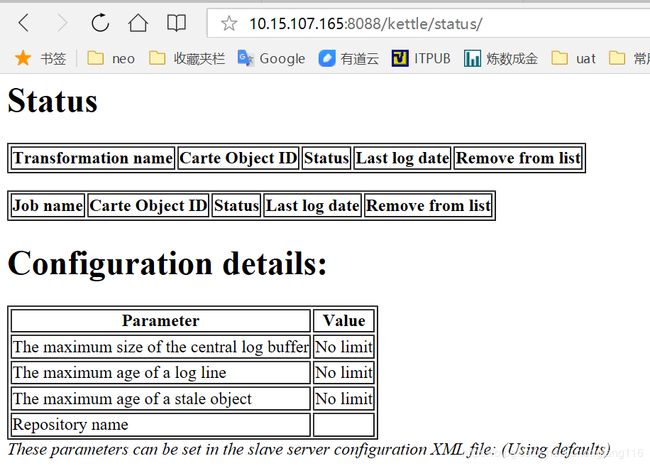
在启动了三台集群服务器之后,在浏览器中输入:10.15.107.165:8088,进入到页面弹出框,输入默认账号密码, cluster/cluster
登录节点171
./carte.sh 10.15.107.171 8081

浏览器地址栏下输入:10.15.107.171:8081


登录节点153
./carte.sh 10.15.107.153 8082
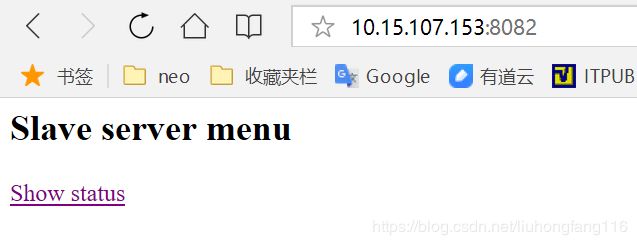
浏览器地址栏下输入:10.15.107.153:8082

5) windows调用linux环境集群组
由于大多数kettle集群开发采用windows本地开发,然后集群环境在linux上。因此,则需要在此环境进行开发,测试及部署。
在spoon中创建子服务器
打开spoon.bat,新建一个转换。选择主对象树-子服务器,右键新键子服务器:
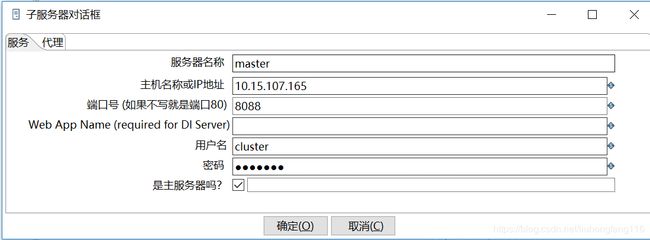
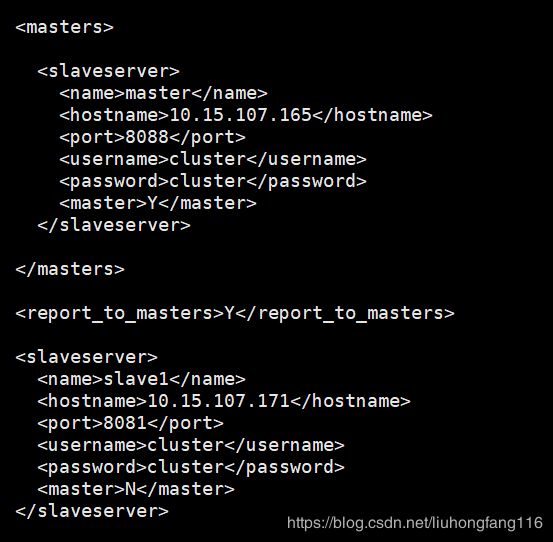
把xml中的信息复制过来,保证与xml中的信息一模一样。按照这种文件配置master slave1-8081 slave2-8082


建立集群
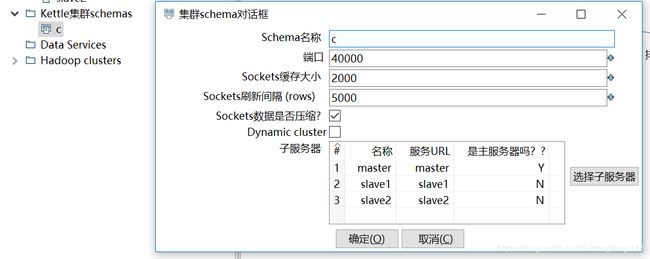
在主对象树中选择kettle集群schemas,填写schema名称,端口、sokects缓存大小、sockets刷新时间间隔、socketts数据是否压缩。在右边点击选择子服务器,选择需要的子服务器。
Schema名称即集群的名称。
端口即集群对外服务的端口.
sockets缓存大小:sockets缓存
Sockets刷新时间间隔:达到多少行记录时刷新到子服务器。
Sockets数据是否压缩:如果网络状况差,则建议选择。网络良好时不用选择。
执行转换
配置完集群后,选择转换中的执步骤”排序记录“,右键该步骤,选择”集群”,选择刚才配置的集群”c”。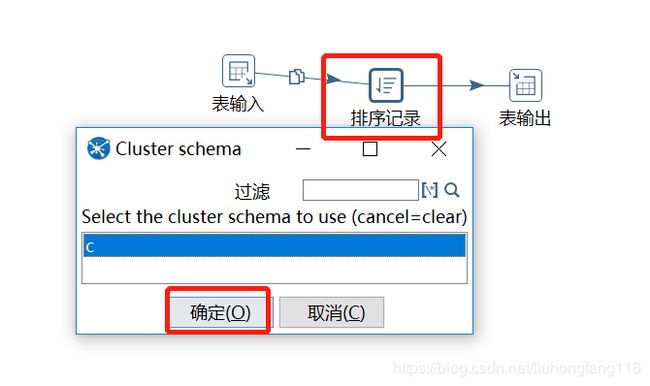
选择然后会发现排序纪录多出”CX2”,表示有2个子服务器来执行。在一个三个子服务器的集群中,主服务器负责任务分发、结果收集,转换任务由从服务器执行,故只有两个节点执行。

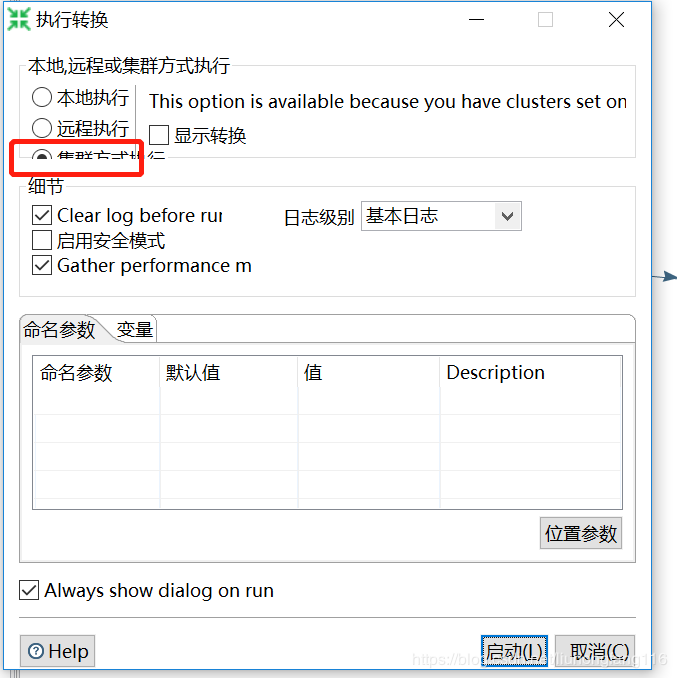
点启动后出现弹出如下多个界面:
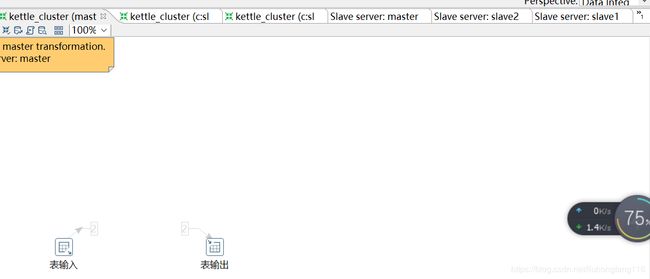
浏览器查看各节点变化

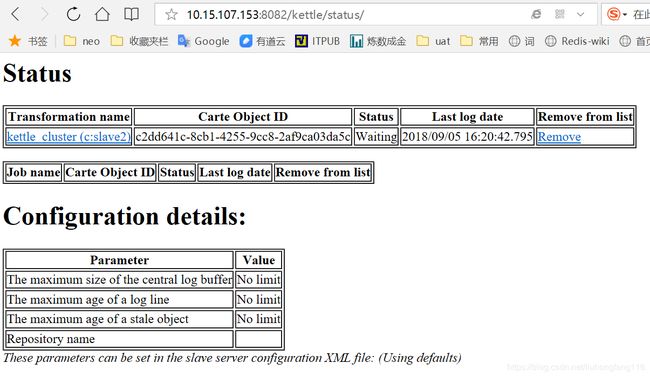
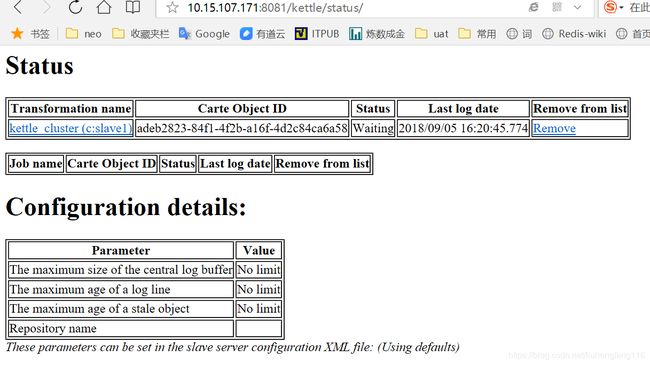
服务器日志,可以看到各个子服务器的执行情况。
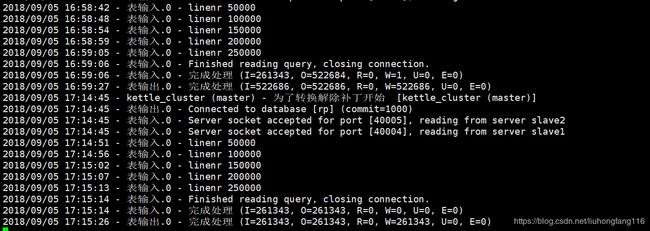


至此,集群搭建成功。
Linux服务器上26万数据量 42s
本地调远程集群45s
./kitchen.sh -file=/root/home/etl/data-integration/job/cluster.kjb -level=basic >>/root/home/etl/data-integration/kettle_log/ceshi_$(date +%Y%m%d).log