总结:详细讲解MapReduce过程(整理补充)
关于整理
此文百分之七十摘自我认为讲的很清楚的博客,我都贴了地址,很感谢这些博主的无私奉献!我再将一些自己的实例代码和知识点的补充加入进去,希望能更好的理解mapreduce的整个过程。
从启动和资源调度来看MapReduce过程
Hadoop 1.x版本
首先-先了解一下必知概念
From:MapReduce工作原理图文详解,JobTracker和TaskTracker概述
- 客户端(Client):编写mapreduce程序,配置作业,提交作业,这就是程序员完成的工作;
- JobTracker:JobTracker是一个后台服务进程,启动之后,会一直监听并接收来自各个TaskTracker发送的心跳信息,包括资源使用情况和任务运行情况等信息。
- 作业控制:在hadoop中每个应用程序被表示成一个作业,每个作业又被分成多个任务,JobTracker的作业控制模块则负责作业的分解和状态监控。
- 状态监控:主要包括TaskTracker状态监控、作业状态监控和任务状态监控。主要作用:容错和为任务调度提供决策依据。
- JobTracker只有一个,他负责了任务的信息采集整理,你就把它当做包工头把,这个和采用Master/Slave结构中的Master保持一致
- JobTracker 对应于 NameNode
- 一般情况应该把JobTracker部署在单独的机器上
- TaskTracker:TaskTracker是JobTracker和Task之间的桥梁。TaskTracker与JobTracker和Task之间采用了RPC协议进行通信。
- 从JobTracker接收并执行各种命令:运行任务、提交任务、杀死任务等
- 将本地节点上各个任务的状态通过心跳周期性汇报给JobTracker,节点健康情况、资源使用情况,任务执行进度、任务运行状态等,比如说map task我做完啦,你什么时候让reduce task过来拉数据啊
- TaskTracker是运行在多个节点上的slaver服务。TaskTracker主动与JobTracker通信,接收作业,并负责直接执行每一个任务。
- TaskTracker都需要运行在HDFS的DataNode上
- HDFS:保存作业的数据、配置信息等等,最后的结果也是保存在hdfs上面
- NameNode: 管理文件目录结构,接受用户的操作请求,管理数据节点(DataNode)
- DataNode:是HDFS中真正存储数据的
- Block:是hdfs读写数据的基本单位,默认64MB大小,就是说如果你有130MB数据,那就要分成三个block,两个存放64MB,最后一个存放2MB数据,虽然最后一个block块是64MB,但实际上占用空间为2MB
- Sencondary NameNode:它的目的是帮助 NameNode 合并编辑日志,减少 NameNode 启动时间,在文件系统中设置一个检查点来帮助NameNode更好的工作。它不是要取代掉NameNode也不是NameNode的备份。可参考Secondary NameNode:它究竟有什么作用?
其次-走一遍流程
规范是:
- 执行的步骤
- 步骤中涉及的知识点
- 知识点的补充
- 步骤中涉及的知识点
按照这样的规范进行讲解

-
在客户端启动一个作业。拿个比方说,我提交了一个hive程序
- 客户端(Client):编写mapreduce程序,配置作业,提交作业,这就是程序员完成的工作;
-
向JobTracker请求一个Job ID,就像你排队买车一样,你不得摇个号啊,没有这个号你就不能买车(执行任务)。
- JobTracker:JobTracker是一个后台服务进程,启动之后,会一直监听并接收来自各个TaskTracker发送的心跳信息,包括资源使用情况和任务运行情况等信息。
- 作业控制:在hadoop中每个应用程序被表示成一个作业,每个作业又被分成多个任务,JobTracker的作业控制模块则负责作业的分解和状态监控。
- 状态监控:主要包括TaskTracker状态监控、作业状态监控和任务状态监控。主要作用:容错和为任务调度提供决策依据。
- JobTracker只有一个,他负责了任务的信息采集整理,你就把它当做包工头把,这个和采用Master/Slave结构中的Master保持一致
- JobTracker 对应于 NameNode
- 一般情况应该把JobTracker部署在单独的机器上
- JobTracker:JobTracker是一个后台服务进程,启动之后,会一直监听并接收来自各个TaskTracker发送的心跳信息,包括资源使用情况和任务运行情况等信息。
-
将运行作业所需要的资源文件复制到HDFS上,包括MapReduce程序打包的JAR文件、配置文件和客户端计算所得的输入划分信息。这些文件都存放在JobTracker专门为该作业创建的文件夹中。文件夹名为该作业的Job ID。JAR文件默认会有10个副本(mapred.submit.replication属性控制);输入划分信息(Split)告诉了JobTracker应该为这个作业启动多少个map任务等信息。
- HDFS:保存作业的数据、配置信息等等,最后的结果也是保存在hdfs上面
- NameNode: 管理文件目录结构,接受用户的操作请求,管理数据节点(DataNode)
- DataNode:是HDFS中真正存储数据的
- Block:是hdfs读写数据的基本单位,默认64MB大小,就是说如果你有130MB数据,那就要分成三个block,两个存放64MB,最后一个存放2MB数据,虽然最后一个block块是64MB,但实际上占用空间为2MB
- Sencondary NameNode:它的目的是帮助 NameNode 合并编辑日志,减少 NameNode 启动时间,在文件系统中设置一个检查点来帮助NameNode更好的工作。它不是要取代掉NameNode也不是NameNode的备份。可参考[Secondary NameNode:它究竟有什么作用?
- HDFS:保存作业的数据、配置信息等等,最后的结果也是保存在hdfs上面
-
JobTracker接收到作业后,将其放在一个作业队列里(一般来说,公司部门都与自己的队列,默认的调度方法是FIFO,也就是first in first out-队列),等待作业调度器对其进行调度,当作业调度器根据自己的调度算法调度到该作业时,会根据输入划分信息(Split)为每个划分创建一个map任务,并将map任务分配给TaskTracker执行。对于map和reduce任务,TaskTracker根据主机核的数量和内存的大小有固定数量的map槽和reduce槽。这里需要强调的是:map任务不是随随便便地分配给某个TaskTracker的,这里有个概念叫:数据本地化(Data-Local)。意思是:将map任务分配给含有该map处理的数据块的TaskTracker上,同时将程序JAR包复制到该TaskTracker上来运行,这叫“运算移动,数据不移动”。而分配reduce任务时并不考虑数据本地化。
- TaskTracker:TaskTracker是JobTracker和Task之间的桥梁。TaskTracker与JobTracker和Task之间采用了RPC协议进行通信。
- 从JobTracker接收并执行各种命令:运行任务、提交任务、杀死任务等
- 将本地节点上各个任务的状态通过心跳周期性汇报给JobTracker,节点健康情况、资源使用情况,任务执行进度、任务运行状态等,比如说map task我做完啦,你什么时候让reduce task过来拉数据啊
- TaskTracker是运行在多个节点上的slaver服务。TaskTracker主动与JobTracker通信,接收作业,并负责直接执行每一个任务。
- TaskTracker都需要运行在HDFS的DataNode上
- TaskTracker:TaskTracker是JobTracker和Task之间的桥梁。TaskTracker与JobTracker和Task之间采用了RPC协议进行通信。
-
TaskTracker每隔一段时间会给JobTracker发送一个心跳,告诉JobTracker它依然在运行,同时心跳中还携带着很多的信息,比如当前map任务完成的进度等信息。当JobTracker收到作业的最后一个任务完成信息时,便把该作业设置成“成功”。当JobClient查询状态时,它将得知任务已完成,便显示一条消息给用户。
Hadoop 2.x版本
相较于1.x的版本,目前绝大多数公司用的都是基于2.x的版本,很大的区别就在于使用了Yarn作为了资源管理器,可以使不同的计算框架运行与同一个资源调度器下,而且也解决了1.x版本中JobTracker压力过大,无法扩展及NameNode单点故障等问题。
首先阐述几个重要概念
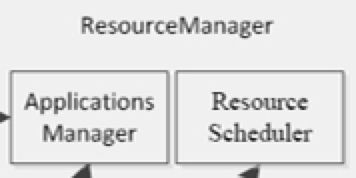
- ResouceManager
包含主要的组件:定时调用器(Scheduler)以及应用管理器(ApplicationManager)。
- 定时调度器(Scheduler):从本质上来说,定时调度器就是一种策略,或者说一种算法。当 Client 提交一个任务的时候,它会根据所需要的资源以及当前集群的资源状况进行分配。注意,它只负责向应用程序分配资源,并不做监控以及应用程序的状态跟踪。
- 应用管理器(ApplicationManager):同样,听名字就能大概知道它是干嘛的。应用管理器就是负责管理 Client 用户提交的应用。上面不是说到定时调度器(Scheduler)不对用户提交的程序监控嘛,其实啊,监控应用的工作正是由应用管理器(ApplicationManager)完成的。
- ApplicationMaster
- 每当 Client 提交一个 Application 时候,就会新建一个 ApplicationMaster 。由这个 ApplicationMaster 去与 ResourceManager 申请容器资源,获得资源后会将要运行的程序发送到容器上启动,然后进行分布式计算。
- NodeManager
- NodeManager 是 ResourceManager 在每台机器的上代理,负责容器的管理,并监控他们的资源使用情况(cpu,内存,磁盘及网络等),以及向 ResourceManager/Scheduler 提供这些资源使用报告。
执行过程如图所示
From:https://blog.csdn.net/lb812913059/article/details/79897863
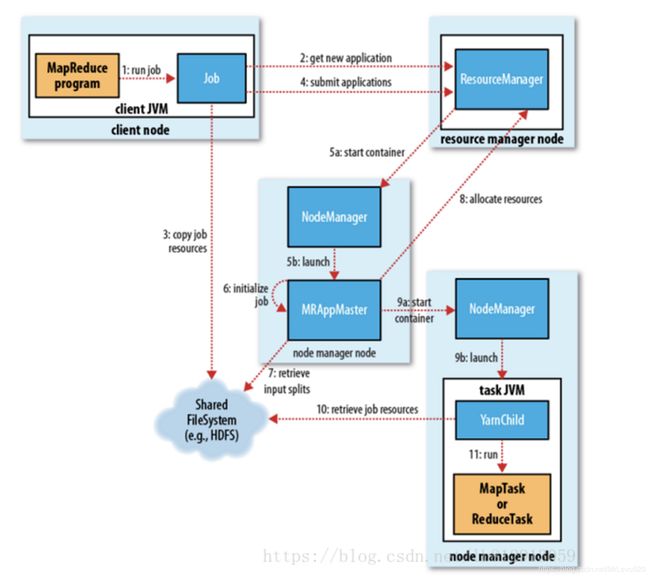
-
通过submit或者waitForCompletion提交作业,waitForCompletion()方法通过每秒循环轮转作业进度如果发现与上次报告有改变,则将进度报告发送到控制台
-
向ResourceManager申请Application ID,RM检查输入输出说明、计算输入分片
-
复制作业的资源文件,将作业信息(jar、配置文件、分片信息)复制到HDFS上用户的应用缓存目录中
-
通过submitApplication()方法提交作业到资源管理器
-
资源管理器在收到submitApplication()消息后,将请求传递给调度器(Scheduler)
调度器为其分配一个容器Container,然后RM在NM的管理下在container中启动程序的ApplicationMaster进程 -
ApplicationMaster对作业进行初始化,创建过个薄记对象以跟踪作业进度
是一个java应用程序,他的主类是MRAppmaster -
ApplicationMaster接受来自HDFS在客户端计算的输入分片
对每一个分片创建一个map任务,任务对象,由mapreduce.job.reduces属性设置reduce个数
- uber模式:当任务小的时候就会启动一个JVM运行MapReduce作业,这在MapReduce1中是不允许的;这样的作业在YARN中成为uber作业,通过设置mapreduce.job.ubertask.enable设置为false使用;那什么是小任务呢?当小于10个mapper且只有1个reducer且输入大小小于一个HDFS块的任务
-
如果作业不适合uber任务运行,ApplicationMaster就会为所有的map任务和reduce任务向资源管理器申请容器
请求为任务指定内存需求,map任务和reduce任务的默认都会申请1024MB的内存 -
资源管理器为任务分配了容器,ApplicationMaster就通过节点管理器启动容器。
该任务由主类YarnChild的java应用程序执行。 -
运行任务之前,首先将资源本地化,包括作业配置、jar文件和所有来自分布式缓存的文件
-
最后执行map任务和reduce任务
用人话描述大致描述一下
首先Client向ResourceManager (RM)提交一个Application,RM找了下下资源比较丰富的NodeManager(NM),要求他开辟一个container来启动ApplicationMaster(AM), AM收集到启动任务需要用到的资源量(如申请的map的个数依赖于Input Split的大小),将所需要的资源量向RM提交,RM通过一个资源列表的方式选择一些资源相对丰富的NM返回,告诉AM哪一些节点NM可用启动任务,AM开始和NM进行通信,告知启动对应的map/reduce任务;NM开辟一些列的container来执行这些任务,和AM保持通信。一旦所有任务执行结束,AM向Client输出结果并向RM注销自己
以提交一个完整的mapreduce任务来演示,这里用hive
hive> set mapred.job.queue.name=root.xxxxxxxxx;
> insert overwrite table query_result
> select * from A join B on A.name=B.name; # 这里是提交一个job,这里提交hive任务
Query ID = xx_20161216130626_40fda9ef-386f-4ef3-9e13-7b08ad69118c # 申请资源
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks not specified. Estimated from input data size: 1 # reduce个数如果没有设置,那就根据split来确定
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1481285758114_429080, Tracking URL = http://bigdata-hdp-apache500.xg01:8088/proxy/application_1481285758114_429080/
Kill Command = /usr/local/hadoop-2.7.2/bin/hadoop job -kill job_1481285758114_429080
Hadoop job information for Stage-1: number of mappers: 2; number of reducers: 1
2016-12-16 13:06:39,518 Stage-1 map = 0%, reduce = 0%
2016-12-16 13:06:50,846 Stage-1 map = 50%, reduce = 0%, Cumulative CPU 3.7 sec
2016-12-16 13:06:55,987 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 11.24 sec
2016-12-16 13:07:13,418 Stage-1 map = 100%, reduce = 67%, Cumulative CPU 12.53 sec
2016-12-16 13:07:28,715 Stage-1 map = 100%, reduce = 82%, Cumulative CPU 16.31 sec
2016-12-16 13:07:58,252 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 17.7 sec
MapReduce Total cumulative CPU time: 17 seconds 700 msec
Ended Job = job_1481285758114_429080
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to: hdfs://mycluster-tj/tmp/hive-staging/hadoop_hive_2016-12-16_13-06-26_309_6781206579090170211-1/-ext-10000
Loading data to table test.query_result
Table test.query_result stats: [numFiles=1, numRows=3, totalSize=69, rawDataSize=66]
MapReduce Jobs Launched:
Stage-Stage-1: Map: 2 Reduce: 1 Cumulative CPU: 17.7 sec HDFS Read: 13657 HDFS Write: 142 SUCCESS
Total MapReduce CPU Time Spent: 17 seconds 700 msec
OK
owntest.name owntest.age owntest2.workplace owntest2.name
Time taken: 96.932 seconds
以上是在客户端、JobTracker、TaskTracker的层次来分析MapReduce的工作原理的,下面我们再细致一点,从map任务和reduce任务的层次来分析分析吧。
从Map,Reduce,Shuffle理解
总体步骤
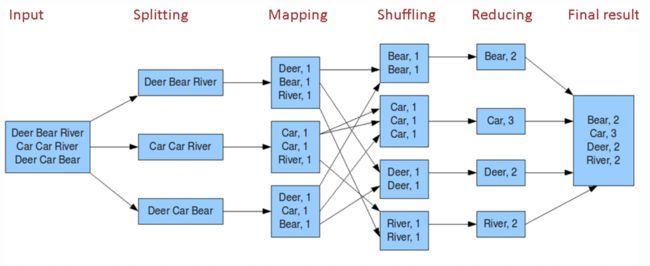
也就分成input,split,map,shuffle,reduce五个步骤,这里我们按照例子来简单说明下,再详细的说明我会放在后面的细分部分,这部分作用是了解下mapreduce的怎么个流程。这里是一个wordcount的过程了
-
input:也就是数据存储位置,这里当然是类似于hdfs这样的分布式存储啦,
-
split:因为map task只读split,而split基本上和hdfs的基本存储块block同样大小注意:split是逻辑分片,一个split对应一个map,你可以把它当做map的单位块来理解,投喂进map的时候必须要这样的格式,打个比方,比如只收硬币的地铁站,你只能投放1元硬币的,你投什么五毛,一角的,都是犯法的!对,警察叔叔就是他!
-
map:这里做的是wordcount,而map程序是由程序原来编写的,如果非要用代码来写,我用python写你别打我
splitdata = 'Deer Bear River' aftermap = map(lambda x:(x,1),splitdata.split(" ")) print aftermap # [('Deer', 1), ('Bear', 1), ('River', 1)]三个map对应三组Split,我这里只取了其中一组,就是这么个意思,组成key/value键值对
-
shuffle:这是一个比较核心的过程,shuffle有洗牌的意思,这里的意思你把她理解成在拉斯维加斯赌场发牌的小姐姐,但是这个小姐姐并不是随机发牌,而是把红桃发给A先生,黑桃都发给B先生,诸如此类。如果非要说有什么套路,那么其中有一个HashPartitioner就帮我们做了hash,你把它想成低配版的聚类,狭义版聚类,因为这里的类特喵的必须是值hash(key)%reduceNum相等的发到同一个reduce里去 啊!
-
reduce:既然都说了似wordcount了,那我,额,额,做戏做全套,我还是用python来写这个过程
shuffledata = [('Deer', 1),('Deer', 1),('River', 1)] afterreduce_dict = {} for i in shuffledata: if i[0] not in afterreduce_dict: afterreduce_dict[i[0]] = 0 afterreduce_dict[i[0]] +=1 print afterreduce_dict # {'River': 1, 'Deer': 2}这个‘reduce’只是对传统意义上的取键值对统计而已,理解这层意思就行,不要纠结形式
总体的步骤就是这么5步,其实最玄妙的shuffle还没有拆开细讲,接下来,见证shuffle的时刻,百分之九十抄的(捂脸)
再细分
shuffle是什么?
除了map,reduce,中间部分就是shuffle,它横跨了map和reduce两端,可以说是核心过程

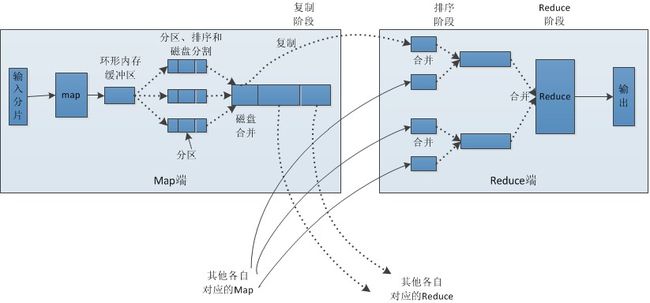
这里你只要清楚Shuffle的大致范围就成-怎样把map task的输出结果有效地传送到reduce端。也可以这样理解, Shuffle描述着数据从map task输出到reduce task输入的这段过程。你说我map task干完活了要输出数据了,然后接下来数据给哪个reduce?不能因为我和那个reduce关系好,我把所有输出结果都给它把,总要考虑下别的reduce的感受啊!那怎么分配?就有了shuffle过程!上面给了两张图,我都是盗来的,一张是官方的解释,一张是中文翻译,Tkanks-MapReduce:详解Shuffle过程、MapReduce工作原理图文详解
shuffle解决什么问题?
在Hadoop这样的集群环境中,大部分map task与reduce task的执行是在不同的节点上。当然很多情况下Reduce执行时需要跨节点去拉取其它节点上的map task结果。如果集群正在运行的job有很多,那么task的正常执行对集群内部的网络资源消耗会很严重。这种网络消耗是正常的,我们不能限制,能做的就是最大化地减少不必要的消耗。还有在节点内,相比于内存,磁盘IO对job完成时间的影响也是可观的。从最基本的要求来说,我们对Shuffle过程的期望可以有:
- 完整地从map task端拉取数据到reduce 端。
- 在跨节点拉取数据时,尽可能地减少对带宽的不必要消耗。
- 减少磁盘IO对task执行的影响。
Map端分析
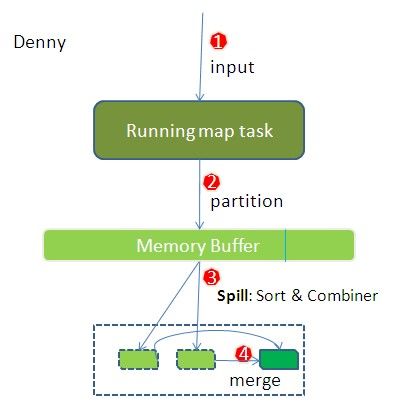
与上图步骤1,2,3,4一一对应来解释
- InputSplit:输入数据来源于HDFS的block,当然在MapReduce概念中,map task只读取Split,也就是是我们所说的分片。在进行map计算之前,mapreduce会根据输入文件计算输入分片(input split),每个输入分片(input split)针对一个map任务。
- Block是HDFS的基本存储单元,上文也有写,Block默认大小是64MB
- Split是map task只读的单位,存储的并非数据本身,而是一个分片长度和一个记录数据的位置的数组
- Split与block的对应关系可能是多对一,默认是一对一
Running map task 就是程序员编写好的map函数了,因此map函数效率相对好控制,而且一般map操作都是本地化操作也就是在数据存储节点上进行,这也就是上问所提到的 数据本地化!
- 数据本地化(Data-Local)。意思是:将map任务分配给含有该map处理的数据块的TaskTracker上,同时将程序JAR包复制到该TaskTracker上来运行,这叫“运算移动,数据不移动”。而分配reduce任务时并不考虑数据本地化。
- partition:partition是分割map每个节点的结果,按照key分别映射给不同的reduce,也是可以自定义的。这里其实可以理解归类。我们对于错综复杂的数据归类。比如在动物园里有牛羊鸡鸭鹅,他们都是混在一起的,但是到了晚上他们就各自牛回牛棚,羊回羊圈,鸡回鸡窝。partition的作用就是把这些数据归类。只不过在写程序的时候,mapreduce使用哈希HashPartitioner帮我们归类了。默认是hash(key)%R(Reduce task的数量)哈希函数分散到各个reducer去
- 简单的hash做分配,就比如说我map task输出键值对(1,1),(2,1),(3,1), 我有三个reducer,假设我写个hash是除3取余的值为分配到的reducer位置(其实是要将key先变hash code再除的,我这里简略),那么(1,1)被分配到第一个reduce,(2,1)被分配到第二个reduce,(3,1)被分配到第三个reduce,同理再来个(4,1)被分配到第一个reduce,HashPartitioner的目的就是合理的分组策略将使得每个Reducer获得的计算负载差距不大,从而整体reduce的性能更加均衡。
- 没理解HashPartitioner的胖友,可以参考下这个MapReduce 编程 系列十 使用HashPartitioner来调节Reducer的计算负载
**Memory Buffer & 3:**这是一个环形的缓冲区。map task输出结果首先会进入一个缓冲区内,这个缓冲区的大小是100MB,如果map task内容太大,是很容易撑爆内存的,所以会有一个守护进程,每当缓冲区到达上限80%的时候,就会启动一个Spill(溢写)进程,它的作用是把内存里的map task的结果写入到磁盘。这里值得注意的是,溢写程序是单独的一个进程,不会影响map task的继续输出(在写磁盘过程中,另外的20%内存可以继续写入数据,两种操作互不干扰,但如果在此期间缓冲区被填满,那么map就会阻塞写入内存的操作,让写入磁盘操作完成后再执行写入内存。)。当溢写线程启动后,需要对这80MB空间内的key做排序(Sort)。排序是MapReduce模型默认的行为,这里的排序也是对序列化的字节做的排序。shuffle排序可以参考这里
- 在这个缓冲区内会有二次排序,先对partition分区排序,然后对同一个partition内的数据进行排序。
- 很多人的误解在Map阶段,如果不使用Combiner便不会排序,这是错误的,不管你用不用Combiner,Map Task均会对产生的数据排序(如果没有Reduce Task,则不会排序, 实际上Map阶段的排序就是为了减轻Reduce端排序负载)
- 数据按照partition值和key两个关键字升序排序,移动的只是索引数据,排序结果是Kvmeta中数据按照partition为单位聚集在一起,同一partition内的按照key有序。
Combiner:如果client设置过Combiner,那么现在就是使用Combiner的时候了。将有相同key的key/value对的value加起来,减少溢写到磁盘的数据量,combiner简单说就是map端的reduce!。Combiner会优化MapReduce的中间结果,所以它在整个模型中会多次使用。那哪些场景才能使用Combiner呢?从这里分析,Combiner的输出是Reducer的输入,Combiner绝不能改变最终的计算结果。所以从我的想法来看,Combiner只应该用于那种Reduce的输入key/value与输出key/value类型完全一致,且不影响最终结果的场景。比如累加,最大值等。但对于均值就会有影响;Combiner的使用一定得慎重,如果用好,它对job执行效率有帮助,反之会影响reduce的最终结果。
- Merge: 每次溢写会在磁盘上生成一个溢写文件,如果map的输出结果真的很大,有多次这样的溢写发生,磁盘上相应的就会有多个溢写文件存在。当map task真正完成时,内存缓冲区中的数据也全部溢写到磁盘中形成一个溢写文件。最终磁盘中会至少有一个这样的溢写文件存在(如果map的输出结果很少,当map执行完成时,只会产生一个溢写文件),因为最终的文件只有一个,所以需要将这些溢写文件归并到一起。
引用:然后为merge过程创建一个叫file.out的文件和一个叫file.out.Index的文件用来存储最终的输出和索引,一个partition一个partition的进行合并输出。对于某个partition来说,从索引列表中查询这个partition对应的所有索引信息,每个对应一个段插入到段列表中。也就是这个partition对应一个段列表,记录所有的Spill文件中对应的这个partition那段数据的文件名、起始位置、长度等等。然后对这个partition对应的所有的segment进行合并,目标是合并成一个segment。当这个partition对应很多个segment时,会分批地进行合并:先从segment列表中把第一批取出来,以key为关键字放置成最小堆,然后从最小堆中每次取出最小的输出到一个临时文件中,这样就把这一批段合并成一个临时的段,把它加回到segment列表中;再从segment列表中把第二批取出来合并输出到一个临时segment,把其加入到列表中;这样往复执行,直到剩下的段是一批,输出到最终的文件中。最终的索引数据仍然输出到Index文件中。
也就是说,上述三个spill.out文件中,同一个颜色的表示计算出的partition的值是一致的,根据每一个spill.out文件都有spill.index文件对应,里面记录了该out文件中某个partition的位置,将同一个partition从三个spill.out文件中都拿出来进行归并操作,搞定后变成了最终文件的头部,然后再采集蓝色部分代表的partition,往复操作,最终每个map都会对应出一个结果文件,等待reduce来拉取自己需要处理的部分,至于怎么拉,拉谁,这个都记录在index中,其实就是partition的值了
- Merge是怎样的?比如“aaa”从某个map task读取过来时值是5,从另外一个map 读取时值是8,因为它们有相同的key,所以得merge成group。什么是group。对于“aaa”就是像这样的:{“aaa”, [5, 8, 2, …]},数组中的值就是从不同溢写文件中读取出来的,然后再把这些值放在一起。
- 合并(Combine)和归并(Merge)的区别:
两个键值对<“a”,1>和<“a”,1>,如果合并,会得到<“a”,2>,如果归并,会得到<“a”,<1,1>>,每个map都会有一个环形缓冲区,merge默认对此溢写文件进行合并,而combine则需要设置,设置后,同个key的value会相加
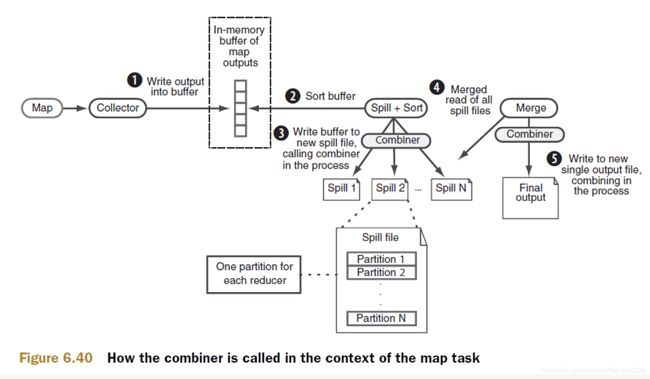
- 补充一下,combine这个如果设置了,会在两个地方被触发;
- 第一次是在溢写磁盘前,缓冲区对key进行排序后,会触发一次;
- 第二次是在merge最终将一堆溢写文件合并成单个文件时,也会触发一次,但在这里触发的时候需在 numSpills>mapreduce.map.combine.minspills(默认3) ,combiner时才执行;如果map输出规模较少,只存在一两个溢写的文件,那么不值得调用combine带来的开销。
- 补充另一点,在shuffle阶段中map端涉及到的排序
在spill的过程中时,会对partition和key进行排序,确保partition内的key是有序的,这里用的是优化后的快排;然后再溢写到小文件之后,针对这些小文件,最终需要merge到一个文件,这里也会出现一次排序,这里用的基本思想就是归并排序,其实是可以理解的,因为在溢写的文件块内,已经保证局部有序了,相当于只需要将局部有序的列表进行合并,形成一个全局有序的,这个让归并来做实在合适,甚至只需要做归并的后半部分!我用代码阐述下
# 假设两个溢写文件且是两个partition的情况,里面的key已经有序了,现在需要全局有序,也就是小文件a,b merge到temp的过程
a = [1,2,4,7,20,23]
b = [3,5,9,11,13,17,19,20]
a_size = len(a)
b_size = len(b)
temp = []
i,j = 0,0
while i != a_size and j != b_size:
if a[i] < b[j]:
temp.append(a[i])
i = i + 1
else:
temp.append(b[j])
j = j + 1
temp.extend(b[j:] if i == a_size else a[i:])
[1, 2, 3, 4, 5, 7, 9, 11, 13, 17, 19, 20, 20, 23]
代码比较简陋,但是阐述了归并的基本思想,就是使用外部排序的方式,开辟一个缓冲区进行排序,这样就不会局限于内存的限制了,其实在大数据排序中经常碰到,指针交替前进,最后刷完整个列表;
至此,map端的所有工作都已结束,最终生成的这个文件也存放在TaskTracker够得着的某个本地目录内。每个reduce task不断地通过RPC从JobTracker那里获取map task是否完成的信息,如果reduce task得到通知,获知某台TaskTracker上的map task执行完成,Shuffle的后半段过程开始启动。
关于这个过程更详细的请见 MapReduce shuffle过程详解
Reduce端分析
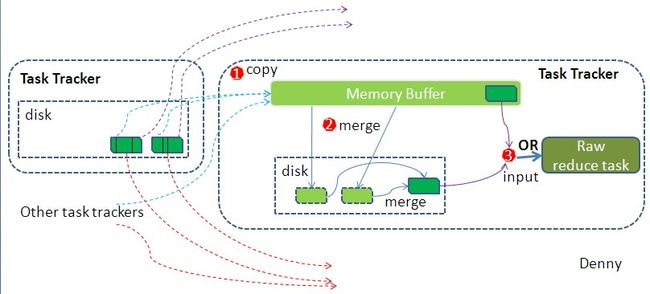
- Copy过程: Reduce会接收到不同map任务传来的数据,并且每个map传来的数据都是有序的。Reduce进程启动一些数据copy线程(Fetcher),通过HTTP方式请求map task所在的TaskTracker获取map task的输出文件。因为map task早已结束,这些文件就归TaskTracker管理在本地磁盘中。
- 默认情况下,当整个MapReduce作业的所有已执行完成的Map Task任务数超过Map Task总数的5%后,JobTracker便会开始调度执行Reduce Task任务。然后Reduce Task任务默认启动mapred.reduce.parallel.copies(默认为5)个MapOutputCopier线程到已完成的Map Task任务节点上分别copy一份属于自己的数据。 这些copy的数据会首先保存的内存缓冲区中,当内冲缓冲区的使用率达到一定阀值后,则写到磁盘上。
- 有人可能会问:分区中的数据怎么知道它对应的reduce是哪个呢?其实map任务一直和其父TaskTracker保持联系,而TaskTracker又一直和JobTracker保持心跳。所以JobTracker中保存了整个集群中的宏观信息。只要reduce任务向JobTracker获取对应的map输出位置就ok了。还有就是map端已经做完了partition,reduce根据partition标识符来拉自己需要的数据
- Merge: 这里的merge如map端的merge动作,只是数组中存放的是不同map端copy来的数值。Copy过来的数据会先放入内存缓冲区中,这里的缓冲区大小要比map端的更为灵活,它基于JVM的heap size设置,因为Shuffle阶段Reducer不运行,所以应该把绝大部分的内存都给Shuffle用。这里需要强调的是,merge有三种形式:1)内存到内存 2)内存到磁盘 3)磁盘到磁盘。默认情况下第一种形式不启用,让人比较困惑,是吧。当内存中的数据量到达一定阈值,就启动内存到磁盘的merge。与map 端类似,这也是溢写的过程,这个过程中如果你设置有Combiner,也是会启用的,然后在磁盘中生成了众多的溢写文件。第二种merge方式一直在运行,直到没有map端的数据时才结束,然后启动第三种磁盘到磁盘的merge方式生成最终的那个文件。
- Reducer的输入文件。不断地merge后,最后会生成一个“最终文件”。为什么加引号?因为这个文件可能存在于磁盘上,也可能存在于内存中。对我们来说,当然希望它存放于内存中,直接作为Reducer的输入,但默认情况下,这个文件是存放于磁盘中的。当Reducer的输入文件已定,整个Shuffle才最终结束。
- reduce阶段:和map函数一样也是程序员编写的,最终结果是存储在hdfs上的。
致谢
@上述所有链接