系列文章:
- Java集合系列01之概览
- Java集合系列02之ArrayList源码分析
- Java集合系列03之LinkedList源码分析
- Java集合系列04之fail-fast机制分析
- Java集合系列05之Vector&Stack源码分析及List总结
- Java集合系列06之Map接口概览
- Java集合系列07之HashMap源码分析
- Java集合系列08之WeakHashMap源码分析
- Java集合系列09之TreeMap源码分析
- Java集合系列10之Hashtable源码分析
前言
和HashMap一样,Hashtable也是一个散列表,但是其继承于Dictionary,定义如下:
public class Hashtable
extends Dictionary
implements Map, Cloneable, java.io.Serializable
可以看出,Hashtable继承于Dictionary,实现了Map,Cloneable, java.io.Serializable等接口。
与HashMap不同的是,Hashtable是同步的,即线程安全,其每个方法都加了关键字synchronized。
继承关系
Hashtable继承关系
java.lang.Object
|___ java.util.Dictionary
|___ java.util.Hashtable
所有已实现的接口:
Serializable, Cloneable, Map
关系图
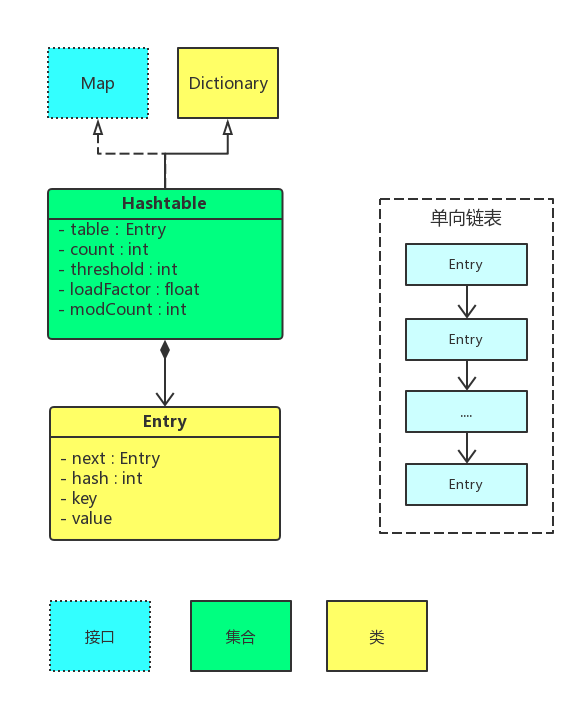
Hashtable关系图
- Hashtable通过拉链法实现的哈希表
构造函数
// 带初始容量和加载因子的构造函数
public Hashtable(int initialCapacity, float loadFactor)
// 带初始容量构造函数
public Hashtable(int initialCapacity)
// 默认构造函数
public Hashtable()
// 包含子Map的构造函数
public Hashtable(Map t)
API
synchronized void clear()
synchronized Object clone()
synchronized boolean contains(Object value)
synchronized boolean containsKey(Object key)
synchronized boolean containsValue(Object value)
synchronized Enumeration elements()
synchronized Set> entrySet()
synchronized boolean equals(Object object)
synchronized V get(Object key)
synchronized int hashCode()
synchronized boolean isEmpty()
synchronized Set keySet()
synchronized Enumeration keys()
synchronized V put(K key, V value)
synchronized void putAll(Map map)
synchronized V remove(Object key)
synchronized int size()
synchronized String toString()
synchronized Collection values()
源码分析
构造函数
// 带初始容量和加载因子的构造函数
public Hashtable(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal Load: "+loadFactor);
if (initialCapacity==0)
initialCapacity = 1;
this.loadFactor = loadFactor;
table = new Entry[initialCapacity];
threshold = (int)Math.min(initialCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
}
// 指定初始容量
public Hashtable(int initialCapacity) {
this(initialCapacity, 0.75f);
}
// 默认构造函数 大小是11
public Hashtable() {
this(11, 0.75f);
}
// 带子Map的构造函数
public Hashtable(Map t) {
this(Math.max(2*t.size(), 11), 0.75f);
// 全部元素加入Hashtable中
putAll(t);
}
成员变量
// 每一个Entry是一个单向链表
private transient Entry[] table;
// 实际容量
private transient int count;
// 阈值
private int threshold;
// 加载因子
private float loadFactor;
// Hashtable被修改的次数
private transient int modCount = 0;
增加元素
public synchronized V put(K key, V value) {
// 确认value不能为空
if (value == null) {
throw new NullPointerException();
}
// 如果key已经存在,则替换旧的value
Entry tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry entry = (Entry)tab[index];
for(; entry != null ; entry = entry.next) {
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
// 如果key不存在,则新添节点
addEntry(hash, key, value, index);
return null;
}
// 新增节点
private void addEntry(int hash, K key, V value, int index) {
// 统计数+1
modCount++;
Entry tab[] = table;
// 实际容量大于阈值,则rehash
if (count >= threshold) {
rehash();
tab = table;
hash = key.hashCode();
index = (hash & 0x7FFFFFFF) % tab.length;
}
@SuppressWarnings("unchecked")
// 将index处的链表保存为e
Entry e = (Entry) tab[index];
// 创建新节点,并将新节点插入index位置,并将e设为其next元素,即将新节点设为链表表头
tab[index] = new Entry<>(hash, key, value, e);
count++;
}
// 将Map中所有元素加入到Hashtable中
public synchronized void putAll(Map t) {
for (Map.Entry e : t.entrySet())
put(e.getKey(), e.getValue());
}
获取元素
// 返回给定key的value值,key不存在则返回null
public synchronized V get(Object key) {
Entry tab[] = table;
int hash = key.hashCode();
// 计算索引值
int index = (hash & 0x7FFFFFFF) % tab.length;
// 查找key对应的value值
for (Entry e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return (V)e.value;
}
}
return null;
}
删除元素
// 删除Hashtable中键为key的元素
public synchronized V remove(Object key) {
Entry tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
// 找到key对应的链表
// 在链表中遍历寻找待删除的节点
Entry e = (Entry)tab[index];
for(Entry prev = null ; e != null ; prev = e, e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
modCount++;
if (prev != null) {
prev.next = e.next;
} else {
tab[index] = e.next;
}
count--;
V oldValue = e.value;
e.value = null;
return oldValue;
}
}
return null;
}
rehash
// 调整Hashtable的长度,变为原来的2倍+1
protected void rehash() {
int oldCapacity = table.length;
// 旧table赋给临时Entry数组
Entry[] oldMap = table;
// 新的长度
int newCapacity = (oldCapacity << 1) + 1;
if (newCapacity - MAX_ARRAY_SIZE > 0) {
if (oldCapacity == MAX_ARRAY_SIZE)
return;
newCapacity = MAX_ARRAY_SIZE;
}
Entry[] newMap = new Entry[newCapacity];
modCount++;
threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
table = newMap;
// 将原数据全部依次加入新的Entry中
for (int i = oldCapacity ; i-- > 0 ;) {
for (Entry old = (Entry)oldMap[i] ; old != null ; ) {
Entry e = old;
old = old.next;
int index = (e.hash & 0x7FFFFFFF) % newCapacity;
e.next = (Entry)newMap[index];
newMap[index] = e;
}
}
}
遍历
Iterator iter = table.entrySet().iterator();
while(iter.hasNext()){
Map.Entry entry = (Map.Entry)iter.next();
key = (String)entry.getKey();
value = (String)entry.getValue();
}
- 根据
keySet()通过Iterator遍历
Iterator iter = table.keySet().iterator();
while(iter.hasNext()){
key = (String)iter.next();
value = (String)table.get(key);
}
- 根据
value()通过Iterator遍历
Iterator iter = table.values().iterator();
while(iter.hasNext()){
value = (String)iter.next;
}
- 根据
Enumeration遍历Hashtable的键
Enumeration enu = table.keys();
while(enu.hasMoreElements()) {
enu.nextElements();
}
- 根据
Enumeration遍历Hashtable的值
Enumeration enu = table.elements();
while(enu.hasMoreElements()) {
enu.nextElement();
}
参考信息
- Java 集合系列11之 Hashtable详细介绍(源码解析)和使用示例