如何使用Python读写Kafka?

关于Kafka的第三篇文章,我们来讲讲如何使用Python读写Kafka。这一篇文章里面,我们要使用的一个第三方库叫做kafka-python。大家可以使用pip或者pipenv安装它。下面两种安装方案,任选其一即可。
python3 -m pip install kafka-python
pipenv install kafka-python
如下图所示:
这篇文章,我们将会使用最短的代码来实现一个读、写Kafka的示例。
创建配置文件
由于生产者和消费者都需要连接Kafka,所以我单独写了一个配置文件config.py用来保存连接Kafka所需要的各个参数,而不是直接把这些参数Hard Code写在代码里面:
# config.py
SERVER = '123.45.32.11:1234'
USERNAME = 'kingname'
PASSWORD = 'kingnameisgod'
TOPIC = 'howtousekafka'
本文演示所用的Kafka由我司平台组的同事搭建,需要账号密码才能连接,所以我在配置文件中加上了USERNAME和PASSWORD两项。你使用的Kafka如果没有账号和密码,那么你只需要SERVER和TOPIC即可。
创建生产者
代码简单到甚至不需要解释。首先使用KafkaProducer类连接 Kafka,获得一个生产者对象,然后往里面写数据。
import json
import time
import datetime
import config
from kafka import KafkaProducer
producer = KafkaProducer(bootstrap_servers=config.SERVER,
value_serializer=lambda m: json.dumps(m).encode())
for i in range(100):
data = {'num': i, 'ts': datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')}
producer.send(config.TOPIC, data)
time.sleep(1)
参数bootstrap_servers用于指定 Kafka 的服务器连接地址。
参数value_serializer用来指定序列化的方式。这里我使用 json 来序列化数据,从而实现我向 Kafka 传入一个字典,Kafka 自动把它转成 JSON 字符串的效果。
如下图所示:
注意,上图中,我多写了4个参数:
security_protocol="SASL_PLAINTEXT"
sasl_mechanism="PLAIN"
sasl_plain_username=config.USERNAME
sasl_plain_password=config.PASSWORD
这四个参数是因为我这里需要通过密码连接 Kafka 而加上的,如果你的 Kafka 没有账号密码,就不需要这四个参数。
创建消费者
Kafka 消费者也需要连接 Kafka,首先使用KafkaConsumer类初始化一个消费者对象,然后循环读取数据。代码如下:
import config
from kafka import KafkaConsumer
consumer = KafkaConsumer(config.TOPIC,
bootstrap_servers=config.SERVER,
group_id='test',
auto_offset_reset='earliest')
for msg in consumer:
print(msg.value)
KafkaConsumer 的第一个参数用于指定 Topic。你可以把这个 Topic 理解成 Redis 的 Key。
bootstrap_servers用于指定 Kafka 服务器连接地址。
group_id这个参数后面的字符串可以任意填写。如果两个程序的Topic与group_id相同,那么他们读取的数据不会重复,两个程序的Topic相同,但是group_id不同,那么他们各自消费全部数据,互不影响。
auto_offset_rest 这个参数有两个值,earliest和latest,如果省略这个参数,那么默认就是latest。这个参数会单独介绍。这里先略过。
连接好 Kafka 以后,直接对消费者对象使用 for 循环迭代,就能持续不断获取里面的数据了。
运行演示
运行两个消费者程序和一个生产者程序,效果如下图所示。
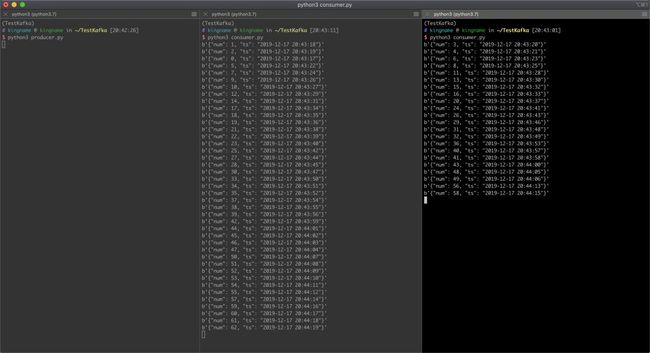
我们可以看到,两个消费者程序读取数据不重复,不遗漏。
当所有数据都消费完成以后,如果你把两个消费者程序关闭,再运行其中一个,你会发现已经没有数据会被打印出来了。
但如果你修改一下 group_id,程序又能正常从头开始消费了,如下图所示:
很多人都会搞混的几个地方
earliest 与 latest
在我们创建消费者对象的时候,有一个参数叫做auto_offset_reset='earliest'。有人看到earliest与latest,想当然地认为设置为earliest,就是从 Topic 的头往后读,设置为latest就是忽略之前的数据,从程序运行以后,新来的数据开始读。
这种看法是不正确的。
auto_offset_reset这个参数,只有在一个group第一次运行的时候才有作用,从第二次运行开始,这个参数就失效了。
假设现在你的 Topic 里面有100个数据,你设置了一个全新的 group_id 为test2。auto_offset_reset设置为 earliest。那么当你的消费者运行的时候,Kafka 会先把你的 offset 设置为0,然后让你从头开始消费的。
假设现在你的 Topic 里面有100个数据,你设置了一个全新的 group_id 为test3。auto_offset_reset设置为 latest。那么当你的消费者运行的时候,Kafka 不会给你返回任何数据,消费者看起来就像卡住了一样,但是 Kafka 会直接强制把前100条数据的状态设置为已经被你消费的状态。所以当前你的 offset 就直接是99了。直到生产者插入了一条新的数据,此时消费者才能读取到。这条新的数据对应的 offset 就变成了100。
假设现在你的 Topic 里面有100个数据,你设置了一个全新的 group_id 为test4。auto_offset_reset设置为 earliest。那么当你的消费者运行的时候,Kafka 会先把你的 offset 设置为0,然后让你从头开始消费的。等消费到第50条数据时,你把消费者程序关了,把auto_offset_reset设置为latest,再重新运行。此时消费者依然会接着从第51条数据开始读取。不会跳过剩下的50条数据。
所以,auto_offset_reset的作用,是在你的 group 第一次运行,还没有 offset 的时候,给你设定初始的 offset。而一旦你这个 group 已经有 offset 了,那么auto_offset_reset这个参数就不会再起作用了。
partition 是如何分配的?
对于同一个 Topic 的同一个 Group:
假设你的 Topic 有10个 Partition,一开始你只启动了1个消费者。那么这个消费者会轮换着从这10个Partition 中读取数据。
当你启动第二个消费者时,Kafka 会从第一个消费者手上抢走5个Partition,分给第二个消费者。于是两个消费者各自读5个 Partition。互不影响。
当第三个消费者又出现时,Kafka 从第一个消费者手上再抢走1个 Partition,从第二个消费者手上抢走2个 Partition 给第三个消费者。于是,消费者1有4个 Partition,消费者2有3个 Partition,消费者3有3个 Partiton,互不影响。
当你有10个消费者一起消费时,每个消费者读取一个 Partition,互不影响。
当第11个消费者出现时,它由于分配不到 Partition,所以它什么都读不到。
所以在上一篇文章中,我说,在同一个 Topic,同一个 Group 中,你有多少个 Partiton,就能起多少个进程同时消费。
Kafka 是不是完全不重复不遗漏?
在极端情况下,Kafka 会重复,也会遗漏,但是这种极端情况并不常见。如果你的 Kafka 频繁漏数据,或者总是出现重复数据,那么肯定是你环境没有搭建正确,或者代码有问题。
忠告
再次提醒:专业的人做专业的事情,不要轻易自建Kafka 集群。让专门的同事复制搭建和维护,你只管使用。这才是最高效省事的做法。
推荐阅读
Python 爬虫面试题 170 道:2019 版
Kafka 里面的信息是如何被消费的?
为什么每一个爬虫工程师都应该学习 Kafka
添加微信[gopython3].回复:回复Go或者Python加对应技术群。