mapreduce中的join
mapreduce常见的join:reduce端的join、map端的join、semi join??
【1】reduce端的join
核心思想:
在map端将来源不同的数据或者有不同用处的数据打标机输出,以便reduce端能
够识别并进行连接关系查找。
适合场景:所有的表都是大表时(几乎所有业务都满足)
优点:解决业务范围较广
缺点:从map端传到reduce端的数据量较大。且有很多的无效数据
大大的增加了传输时间,大大的增加了shuffle过程的耗时(数据多了,分区排序时间也就变长了)。
和连接关系的查询时间。
【2】map端的join:
核心思想:
将小标进行分布式缓存,然后在map端取出缓存的数据来进行连接查询
使用场景:大表和小表同时存在(至少有一个小表存在)
优点:从缓存中读取数据,然后在map端进行关联查找,从而减少map到reduce的数据传输
缺点:只适合有小表的业务需求
【3】reduce端的join案例
child parent
张三 王阿姨
张三 张大叔
张张 王阿姨
张张 张大叔
王阿姨 王奶奶
王阿姨 王大爷
张大叔 张奶奶
张大叔 张大爷
需求:
求出祖孙关系
child grantparent
张三 王奶奶
张三 王大爷
张三 张奶奶
张三 张大爷
张张 王奶奶
张张 王大爷
张张 张奶奶
张张 张大爷

所以mysql可以这样写:
select a.child,b.parent as grantparent
from a,b
where a.parent = b.child
这是一个表,是一整个文件
思路:一个人既有孩子,又有老人,则老人和孩子之间是孙辈关系
找出这个人有的孩子和老人做一个笛卡尔乘积,就得到通过这个人所有孩子的所有孙辈关系
首先从这个人的角度找他的孩子和父母
如何找?
这个人作为父母要有孩子,孩子用1标记 key:parent value:1-child
这个人作为孩子要有父母,父母用2标记 key:child value:2-parent
综上,这个人既有1又有2则这个人的孩子和父母是孙辈关系。
map端的输出:
key:
value:
对a表来说:
key:parent
value:1-child
对b表来说:
key:child
value:2-parent
map端的输出:
王阿姨 1-张三
张大叔 1-张三
王阿姨 1-张张
张大叔 1-张张
王奶奶 1-王阿姨
王大爷 1-王阿姨
张奶奶 1-张大叔
张大爷 1-张大叔
张三 2-王阿姨
张三 2-张大叔
张张 2-王阿姨
张张 2-张大叔
王阿姨 2-王奶奶
王阿姨 2-王大爷
张大叔 2-张奶奶
张大叔 2-张大爷
shuffle之后的结果:
王阿姨 1-张三
王阿姨 1-张张
王阿姨 2-王奶奶
王阿姨 2-王大爷
王大爷 1-王阿姨
王奶奶 1-王阿姨
张大叔 1-张三
张大叔 1-张张
张大叔 2-张奶奶
张大叔 2-张大爷
张大爷 1-张大叔
张奶奶 1-张大叔
张三 2-王阿姨
张三 2-张大叔
张张 2-王阿姨
张张 2-张大叔
reduce端的输入:
王阿姨 1-张三
王阿姨 1-张张
王阿姨 2-王奶奶
王阿姨 2-王大爷
张大叔 1-张三
张大叔 1-张张
张大叔 2-张奶奶
张大叔 2-张大爷
reduce端的输出:
张三 王奶奶
张三 王大爷
张三 张奶奶
张三 张大爷
张张 王奶奶
张张 王大爷
张张 张奶奶
张张 张大爷
不知道为啥,输出为乱码..
package day12_3;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.ArrayList;
public class ReduceJoin {
public static class MyMapper extends Mapper
{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line=value.toString();
line=line.replaceAll("\\s+","\t");
String[] fields=line.split("\t");
String child=fields[0];
String parent=fields[1];
//这个人作为父母要有孩子-1
context.write(new Text(parent),new Text("1-"+child));
//这个人作为孩子要有父母-2
context.write(new Text(child),new Text("2-"+parent));
}
}
public static class MyReducer extends Reducer
{
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
//定义集合存放这个人的孩子和父母,方便做笛卡尔积
//这个人的孩子是孙子辈,这个父母是爷奶辈
ArrayList grandChildren=new ArrayList<>();
ArrayList grandParents=new ArrayList<>();
//遍历迭代器
for(Text value:values)
{
String[] fields=value.toString().split("-");
String relation=fields[0];//1表示这个人的孩子,2表示这个人父母
if(relation.equals("1"))//是孩子
grandChildren.add(fields[1]);//添加到孙子列表
else
grandParents.add(fields[1]);
}
//笛卡尔积
//若孙子,老人列表中有一个是空的,则不会进行这个循环
for(int i=0;i<=grandChildren.size()-1;i++)
{
for(int j=0;j<=grandParents.size()-1;j++)
{
context.write(new Text(grandChildren.get(i)),new Text(grandParents.get(j)));
}
}
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf=new Configuration();
System.setProperty("HADOOP_USER_NAME", "root");
conf.set("fs.defaultFS","file:///");//在本地运行
conf.set("mapreduce.framework.name","local");
Job job=Job.getInstance(conf,"reducejoin");
job.setJarByClass(ReduceJoin.class);
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job,new Path("D:\\mrText\\reduceJoin\\input"));
FileOutputFormat.setOutputPath(job,new Path("D:\\mrText\\reduceJoin\\output"));
boolean b=job.waitForCompletion(true);
System.exit(b?0:1);
}
}
输入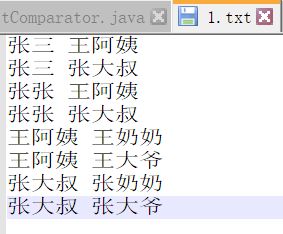
输出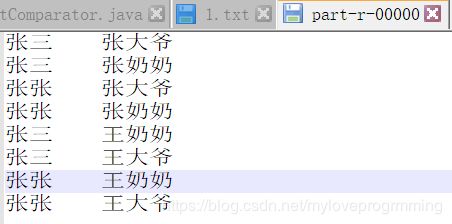
注:查看文件的编码方式
打开记事本---文件--另存为

map端的join案例:
表:login
姓名编号 性别编号 登陆时间
1 1 2017-04-17 08:16:20
2 2 2017-04-15 06:18:20
3 1 2017-04-16 05:16:24
4 2 2017-04-14 03:18:20
5 1 2017-04-13 02:16:25
6 2 2017-04-13 01:15:20
7 1 2017-04-12 08:16:34
8 2 2017-04-11 09:16:20
9 0 2017-04-10 05:16:50
users
1 小红
2 小行
3 小通
4 小闪
5 小镇
6 小振
7 小秀
8 小微
9 小懂
10 小明
11 小刚
12 小举
13 小黑
14 小白
15 小鹏
16 小习
sex
0 不知道
1 男
2 女
输出:
姓名编号 姓名 性别 登陆日期
1 名字 性别 2017-04-17 08:16:20
2 名字 性别 2017-04-15 06:18:20
3 名字 性别 2017-04-16 05:16:24
4 名字 性别 2017-04-14 03:18:20
5 名字 性别 2017-04-13 02:16:25
6 名字 性别 2017-04-13 01:15:20
7 名字 性别 2017-04-12 08:16:34
8 名字 性别 2017-04-11 09:16:20
9 名字 性别 2017-04-10 05:16:50