webp图片格式前端兼容与显示处理以及其图片原始数据的获取
前言
不管是 PC 还是移动端,图片一直是流量大头,以苹果公司 Retina 产品为代表的高 PPI 屏对图片的质量提出了更高的要求,如何保证在图片的精细度不降低的前提下缩小图片体积,成为了一个有价值且值得探索的事情。
但如今对于 JPEG、PNG 和 GIF 这些图片格式的优化几乎已经达到了极致, 若想改变现状开辟新局面,便要有釜底抽薪的胆量和气魄,而 Google 给了我们一个新选择:WebP。
对 WebP 的研究缘起于手机 QQ 原创表情商城,由于表情包体积较大,在 2G/3G 的网络环境下加载较慢。于是催生了其诞生,今年 WebP 图片格式得到越来越多的关注,很多团队也开始布道,前阵子的前端圈“走进腾讯互娱前端技术专场”也有相关专题。
关于更多webp的信息可以参考:WebP 探寻之路
这样一个可以减少图片体积又不影响画质的图片格式,在手机端Android和iOS的App只要引入Google提供的解码库,都可以很轻松的支持WebP格式。不过在Web上,在使用中却有相关问题,最大的问题就是不兼容,火狐完全不支持。谷歌和欧朋等支持较好。
这意味着我们前端又要为该死的兼容考虑了。
解决方法:
本人觉得最佳的解决方法是:使用JS解码WebP图片
既然WebP的解码器是开源的,那么能否用JS来实现呢?当然可以,有人就用JS写出了WebP的解码器。引入这个JS库,就是将所有的WebP图片用JS解码后转换为Base64,然后替换掉原来的URL,这样就可以让原本不支持WebP的浏览器正常显示WebP了。这个库的使用方法非常简单,看网页的说明即可。
这里为大家放上这个库的地址官网地址:webp.js,和github下载地址:webpjs
这种方法的缺点是,因为JS要解码WebP图片,需要在此异步请求SRC中的URL(不过因为图片本身之前被下载了一次,直接使用了缓存);而且JS解码比较慢,对性能有影响,可能需要一段时间才能显示出图片来。但图片体积的缩小可以很好的对这个JS解码时间进行对冲。
我们在github的webpjs 下载地址把webpjs 下载下来,然后引入webpjs.min.js,使用很简单只需要引入即可,代码如下:
<html>
<head>
<meta charset="utf-8">
<title>title>
<script type="text/javascript" src="webpjs-master/webpjs-0.0.2.min.js">script>
<script type="text/javascript" src="exif.js">script>
head>
<body>
<img src="lB3O1WmG5M0JxM0GhA_1668_2500.webp">
body>
html>引入后,他就可以兼容火狐了,其本质是通过使用JS解码WebP图片的,放上截图:
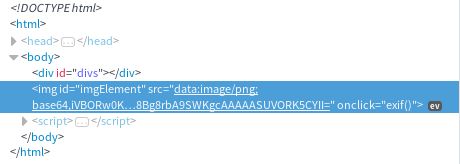
我们可以看到src是base64码。是不是很简单?
webp图片信息的获取
开始前请在github上下载我的项目:webp-ArrayBuffer,然后里面有一个文件是:
lB3O1WmG5M0JxM0GhA_1668_2500.webp,这是我们IOS工程师处理过得webp图片,你们可以拿来做案例。
有时我们需要获取图片的原始数据信息,例如:拍照方向、相机设备型号、拍摄时间、ISO 感光度、GPS 地理位置等数据。
我们一般使用exif.js来获取图片的原始数据信息,github下载exif.js,然后使用引入exif.js,如果你有npm环境可以使用npm install exif-js --save进行安装。而且它的语法也特别简单。
虽然 Exif.js 提供了 JavaScript 读取图像的原始数据的功能扩展,但是图片转换为webp后由于webp自身原因在IOS等手机上写入信息并不现实,太过与繁琐与难缠,这样 Exif.js 无法获取原始数据。
<html>
<head>
<meta charset="utf-8">
<title>title>
<script type="text/javascript" src="webpjs-master/webpjs-0.0.2.min.js">script>
<script type="text/javascript" src="exif.js">script>
head>
<body>
<img src="lB3O1WmG5M0JxM0GhA_1668_2500.webp" onclick="exif()" id="imgElement">
<script>
function exif () {
console.log(EXIF.getAllTags(document.getElementById('imgElement')));
console.log(EXIF.getTag(document.getElementById('imgElement'), 'GPSLongitude'));
}
script>
body>
html>结果如图:

Exif.js 并没有什么乱用
于是把原始数据信息加入二进制信息尾部类似与这样,如图:
起初想起使用fileReader ,后来才恍然记起来它貌似只能用在file的对象中,如果有不明白的可以参考我的博客:web前端-在迷惘中的探索HTML5(三)文件操作FileReader。
如果只能在file对象中使用那么fileReader 将无法在这里运用,但是肯定有别的方法运用fileReader 不然node的文件管理和其他js文件管理插件不都白搭了?终于不负有心人,我在fileReader-MDN上找到了这句话:
FileReader 对象允许Web应用程序异步读取存储在用户计算机上的文件(或原始数据缓冲区)的内容,使用 File 或 Blob 对象指定要读取的文件或数据。
Blob 对象是我们的生机。于是,代码迅速运转:
<html>
<head>
<meta charset="utf-8">
<title>title>
<script type="text/javascript" src="webpjs-master/webpjs-0.0.2.min.js">script>
head>
<body>
<img src="lB3O1WmG5M0JxM0GhA_1668_2500.webp" onclick="exif()" id="imgElement">
<script>
function exif () {
var imgElement = document.getElementById("imgElement");
var blob = new Blob([imgElement], {type: 'image/png'});
var fr = new FileReader();
console.log(blob);
// console.log(fr.readAsDataURL(blob));
// console.log(fr.readAsArrayBuffer(blob));
fr.readAsText(blob);
fr.onload = function(e) {
console.log(e);
}
}
script>
body>
html>可是返回的参数e中并没有任何有用的信息,如图:
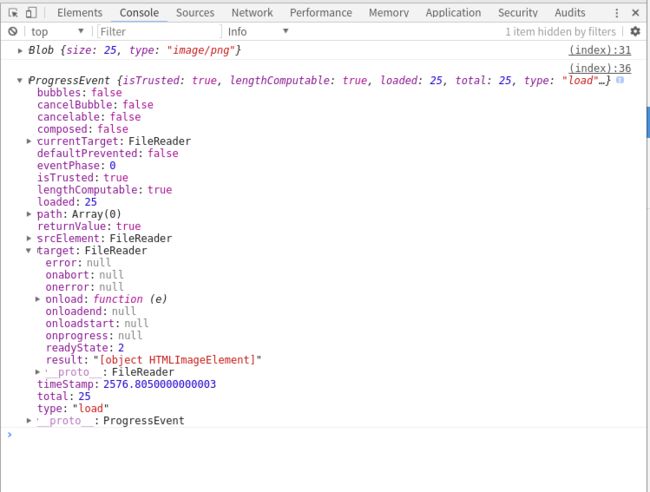
按理来说ProgressEvent下的target的result应该返回结果,fr.readAsText(blob);应该返回二进制文本信息,可是除了[object HTMLImageElement]屁也没有,饱受打击,吐会血…
很郁闷,怎么办?想起了xhr2,XHR2引入了大量的新功能(例如跨源请求、上传进度事件以及对上传/下载二进制数据的支持等),于是进入这里面XMLHttpRequest2 新技巧,陶冶了一番。
既然要用到xhr2那么启一个本地服务是必不可少的,不然无法模拟请求,你们想办法在这个目录里启一个服务即启一个localhost,这里我是用python -m http.server来启动一个http://localhost:8000服务的,这里的案例是以http://localhost:8000来进行实例的,估计很多前端如果不了解是不知道,你们可以选择自己的方式启动自己的服务器。
<html>
<head>
<meta charset="utf-8">
<title>title>
<script type="text/javascript" src="webpjs-master/webpjs-0.0.2.min.js">script>
head>
<body>

<script>
function exif () {
var url = 'http://localhost:8000/lB3O1WmG5M0JxM0GhA_1668_2500.webp'
var xmlhttp = null
if (window.XMLHttpRequest) { // code for IE7+, Firefox, Chrome, Opera, Safari
/* eslint-disable no-new */
xmlhttp = new window.XMLHttpRequest()
} else { // code for IE6, IE5
/* eslint-disable no-new */
xmlhttp = new window.ActiveXObject('Microsoft.XMLHTTP')
}
xmlhttp.open('GET', url, true)
xmlhttp.withCredentials = true
// recent browsers
if ('responseType' in xmlhttp) {
xmlhttp.responseType = 'arraybuffer'
}
// older browser
if (xmlhttp.overrideMimeType) {
xmlhttp.overrideMimeType('text/plain; charset=x-user-defined')
}
xmlhttp.onreadystatechange = function () {
if (xmlhttp.readyState === 4 && xmlhttp.status === 200) {
var file = xmlhttp.response || xmlhttp.responseText
var blob = new Blob([file], {type: 'image/png'})
var fr = new FileReader();
fr.readAsText(blob);
fr.onload = function(e) {
console.log(e.target.result);
}
}
}
xmlhttp.send()
}
script>
body>
html>终于在这里log到我们的需要的数据,结果如图:
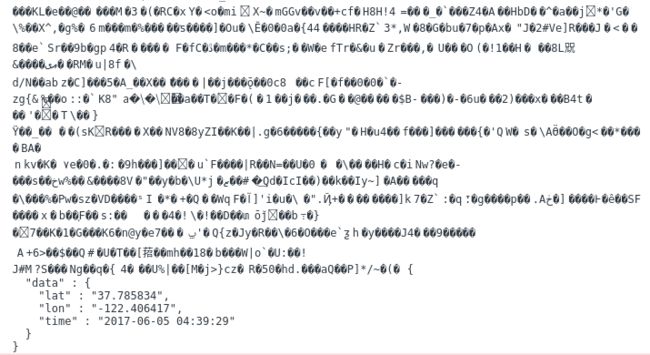
我们下来做的就是把坠在结尾的
{
"data" : {
"lat" : "37.785834",
"lon" : "-122.406417",
"time" : "2017-06-05 04:39:29"
}
}给截取出来有好几种方式,第一种是通过fr.readAsText(blob);输出信息字符串,找倒数第二个位置的{符号,然后截取到最后;第二种方法是通过fr.readAsArrayBuffer(blob);输出二进制信息,按字节顺序找到其在二进制中的位置,然后截取到最后。第一种方法比较简单,第二种方法比较变态,需要你了解很多计算机底层的东西,才能搞的并不是那么的明白,这里决定使用第二种的方法,首先我们得知道整个二进制的长度,然后我们得找到我们需要的东西在二进制当中的位置。
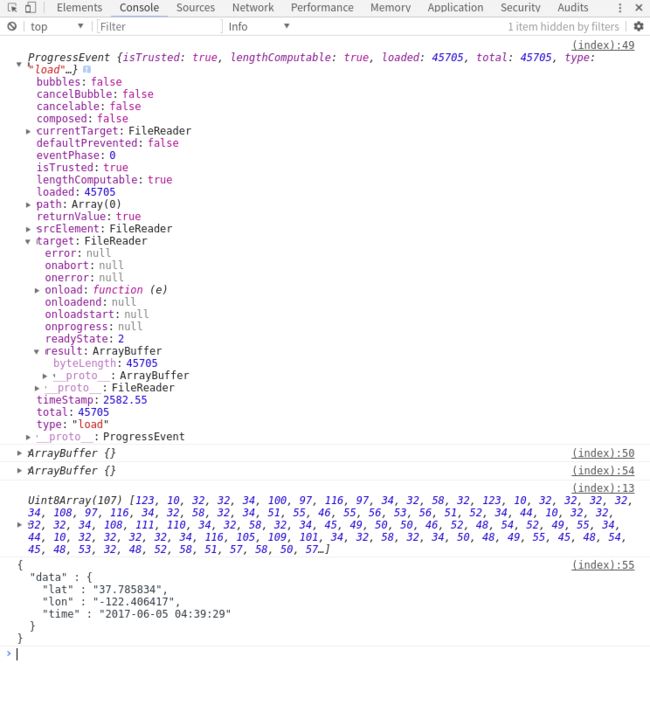
使用readAsArrayBuffer()方法,onload之后,返回的参数e下面的target的result属性中将包含一个ArrayBuffer对象以表示所读取文件的内容。我们把代码里的fr.readAsText(blob);改为fr.readAsArrayBuffer(blob);,然后log输出
fr.onload = function(e) {
console.log(e);
console.log(e.target.result);
}输出结果如图:

我们在fr.onload = function(e) {}中返回的参数e中e.target.result有一个byteLength属性,byteLength+1我们就可以知道整个二进制的长度。
在log中我们可以看到一个ArrayBuffer{},是什么?ArrayBuffer对象是被用来表示一个通用的,固定长度的二进制数据缓冲区。你不能直接操纵ArrayBuffer的内容;相反,你应该创建一个表示特定格式的buffer的类型化数组对象(typed array objects)或数据视图对象DataView 来对buffer的内容进行读取和写入操作。
那么数据视图对象DataView又是什么?数据视图对象DataView实质上是DataView视图提供了一个与平台中字节在内存中的排列顺序(字节序)无关的从ArrayBuffer读写多数字类型的底层接口。
说了这么多大概有点晕呼,其实本质也算不上什么,fr.readAsArrayBuffer(blob);得到一个ArrayBuffer对象,这个对象不能直接操纵,我们需要借助数据视图对象DataView来进行数据的操纵,因为webp它是以riff档案为基础构建的,所以RIFF档案在二进制中占据的大小决定着它的大小,RIFF档案由一个简单的表头(header)跟随着多个区块所组成,其中其表头是12个字节,4字节为”RIFF”,4字节是这个档案的型态字元如”AVI “或”WEBP”,还有4字节是一个无符号的长度是32位整数的小端序,整个档案的大小,会扣掉辨识字元和长度,共8个字节。
因为RIFF档案是一个无符号的长度是32位整数的小端序所以我们可以根据DataView.prototype.getUint32()方法获得从DataView起始位置以byte为计数的指定偏移量即它在整个二进制中的位置,我们的二进制是:webp-RIFF档案+我们需要的JSON,我们获得从DataView起始位置以byte为计数的指定偏移量就等于获得二进制中webp-RIFF档案这部分,因为整个档案的大小会扣掉8个字节的辨识字元和长度,于是我们通过getUint32()+8就可以取到我们需要的JSON的位置。
fr.onload = function(e) {
console.log(e);
console.log(e.target.result);
var buffer = e.target.result;
var dv = new DataView(buffer, 0);
var data = buffer.slice(dv.getUint32(4, true)+8, buffer.byteLength+1);
}最后slice(dv.getUint32(4, true)+8, buffer.byteLength+1);就截取到这一部分二进制,由于我们截取的是ArrayBuffer对象得到的是一个二进制数组,我们需要把我们的数组变成我们需要的JSON,于是建造一个函数来实现:
function arrayBufferToString(buffer){
var arr = new Uint8Array(buffer);
console.log(arr);
var str = String.fromCharCode.apply(String, arr);
if(/[\u0080-\uffff]/.test(str)){
throw new Error("this string seems to contain (still encoded) multibytes");
}
return str;
}函数会返回一个字符串,这个字符串就是我们需要的最终结果:
{
"data" : {
"lat" : "37.785834",
"lon" : "-122.406417",
"time" : "2017-06-05 04:39:29"
}
}于是完整的代码出炉了:
<html>
<head>
<meta charset="utf-8">
<title>title>
<script type="text/javascript" src="webpjs-master/webpjs-0.0.2.min.js">script>
head>
<body>

<script>
function arrayBufferToString(buffer){
var arr = new Uint8Array(buffer);
console.log(arr);
var str = String.fromCharCode.apply(String, arr);
if(/[\u0080-\uffff]/.test(str)){
throw new Error("this string seems to contain (still encoded) multibytes");
}
return str;
}
function exif () {
var url = 'http://localhost:8000/lB3O1WmG5M0JxM0GhA_1668_2500.webp'
var xmlhttp = null
if (window.XMLHttpRequest) { // code for IE7+, Firefox, Chrome, Opera, Safari
/* eslint-disable no-new */
xmlhttp = new window.XMLHttpRequest()
} else { // code for IE6, IE5
/* eslint-disable no-new */
xmlhttp = new window.ActiveXObject('Microsoft.XMLHTTP')
}
xmlhttp.open('GET', url, true)
xmlhttp.withCredentials = true
// recent browsers
if ('responseType' in xmlhttp) {
xmlhttp.responseType = 'arraybuffer'
}
// older browser
if (xmlhttp.overrideMimeType) {
xmlhttp.overrideMimeType('text/plain; charset=x-user-defined')
}
xmlhttp.onreadystatechange = function () {
if (xmlhttp.readyState === 4 && xmlhttp.status === 200) {
var file = xmlhttp.response || xmlhttp.responseText
var blob = new Blob([file], {type: 'image/png'})
var fr = new FileReader();
fr.readAsArrayBuffer(blob);
fr.onload = function(e) {
console.log(e);
console.log(e.target.result);
var buffer = e.target.result;
var dv = new DataView(buffer, 0);
var data = buffer.slice(dv.getUint32(4, true)+8, buffer.byteLength+1);
console.log(data);
console.log(arrayBufferToString(data));
}
}
}
xmlhttp.send()
}
script>
body>
html>点击图片会出现结果如图:
小结
这样就完了,做一个整体性的说明:
为了获取webp的图片的原始数据信息,例如:拍照方向、相机设备型号、拍摄时间、ISO 感光度、GPS 地理位置等数据。在处理图片时,我们为了方便把这些信息加在webp二进制数据信息的末尾,这意味着我们获取的二进制信息是这种结构:二进制webp-RIFF档案+我们需要的JSON。为了取到我们加在二进制信息末尾的JSON,我们有两种方式,第一种是通过fr.readAsText(blob);输出信息字符串,找倒数第二个位置的{符号,然后截取到最后;第二种方法是通过fr.readAsArrayBuffer(blob);输出二进制信息,按字节顺序找到其在二进制中的位置,然后截取到最后。我们使用第二种的方法,首先我们得知道整个二进制的长度,然后我们得找到我们需要的东西在二进制当中的位置。
我们在fr.onload = function(e) {}中返回的参数e中e.target.result有一个byteLength属性,byteLength+1我们就可以知道整个二进制的长度。
找到我们需要的东西在二进制中的位置,我们需要二进制webp-RIFF档案的偏移量,fr.readAsArrayBuffer(blob);得到一个ArrayBuffer对象,这个对象不能直接操纵,我们需要借助数据视图对象DataView来进行数据的操纵,又因为webp它是以riff档案为基础构建的,所以RIFF档案在二进制中占据的大小决定着它的大小,RIFF档案由一个简单的表头(header)跟随着多个区块所组成,其中其表头是12个字节,4字节为”RIFF”,4字节是这个档案的型态字元如”AVI “或”WEBP”,还有4字节是一个无符号的长度是32位整数的小端序,整个档案的大小,会扣掉辨识字元和长度,共8个字节。
因为RIFF档案是一个无符号的长度是32位整数的小端序所以我们可以根据DataView.prototype.getUint32()方法获得从DataView起始位置以byte为计数的指定偏移量即它在整个二进制中的位置,我们的二进制是:二进制webp-RIFF档案+我们需要的JSON,我们获得从DataView起始位置以byte为计数的指定偏移量就等于获得二进制中webp-RIFF档案这部分,因为整个档案的大小会扣掉8个字节的辨识字元和长度,于是我们通过getUint32()+8就可以取到我们需要的JSON的位置。最后slice(dv.getUint32(4, true)+8, buffer.byteLength+1);就截取到这一部分二进制,由于我们截取的是ArrayBuffer对象得到的是一个二进制数组,我们需要把我们的数组变成我们需要的JSON,于是建造一个函数来实现:
function arrayBufferToString(buffer){
var arr = new Uint8Array(buffer);
console.log(arr);
var str = String.fromCharCode.apply(String, arr);
if(/[\u0080-\uffff]/.test(str)){
throw new Error("this string seems to contain (still encoded) multibytes");
}
return str;
}函数会返回一个字符串,这个字符串就是我们需要的最终结果:
{
"data" : {
"lat" : "37.785834",
"lon" : "-122.406417",
"time" : "2017-06-05 04:39:29"
}
}大功告成!!!
提示:后面还有精彩敬请期待,请大家关注我的专题:web前端。如有意见可以进行评论,每一条评论我都会认真对待。