吴恩达深度学习课程作业:Class 4 Week 1 Convolution model - Application 避坑指南
先看代码,如果tensorflow版本不是1.2.0,在执行foward propagation那部分的代码时,有可能你的代码都是正确的,但是你的运行结果却与notebook上的expected output的结果不一样。有一个解决办法:那就是换成老版本的tensorflow。
在1.2.0以上的版本怎么能让迭代收敛呢?
把第208行注释掉就行了。
用1.8版本的tensorflow也很难收敛,迭代100次cost只到1.0左右。
但只要#掉for epoch in range(num_epochs):中的seed = seed + 1即可得到良好的效果:
Cost after epoch 95: 0.253908
Train Accuracy: 0.93796295
Test Accuracy: 0.825
原因在于:
函数random_mini_batches(X_train, Y_train, minibatch_size, seed)在cnn_utiles.py里,
它是根搅屎棍,每迭代1次seed+1,mini_batches要打乱重新排列,
如果固定顺序,迭代收敛速度会加快很多。
下面是我的代码,加上了我自己的注释:import math
import numpy as np
import h5py
import matplotlib.pyplot as plt
import scipy
from PIL import Image
from scipy import ndimage
import tensorflow as tf
from tensorflow.python.framework import ops
from cnn_utils import *
#matplotlib inline
np.random.seed(1)
X_train_orig, Y_train_orig, X_test_orig, Y_test_orig, classes = load_dataset()
'''
index = 11
plt.imshow(X_train_orig[index])
plt.show()
print ("y = " + str(np.squeeze(Y_train_orig[:, index])))
'''
X_train = X_train_orig/255.
X_test = X_test_orig/255.
Y_train = convert_to_one_hot(Y_train_orig, 6).T
Y_test = convert_to_one_hot(Y_test_orig, 6).T
'''
print ("number of training examples = " + str(X_train.shape[0]))
print ("number of test examples = " + str(X_test.shape[0]))
print ("X_train shape: " + str(X_train.shape))
print ("Y_train shape: " + str(Y_train.shape))
print ("X_test shape: " + str(X_test.shape))
print ("Y_test shape: " + str(Y_test.shape))
conv_layers = {}
'''
def create_placeholders(n_H0, n_W0, n_C0, n_y):
X = tf.placeholder(tf.float32, shape=[None, n_H0, n_W0, n_C0])
Y = tf.placeholder(tf.float32, shape=[None, n_y])
return X, Y
'''
X, Y = create_placeholders(64, 64, 3, 6)
print ("X = " + str(X))
print ("Y = " + str(Y))
'''
def initialize_parameters():
"""
Initializes weight parameters to build a neural network with tensorflow. The shapes are:
W1 : [4, 4, 3, 8]
W2 : [2, 2, 8, 16]
Returns:
parameters -- a dictionary of tensors containing W1, W2
"""
tf.set_random_seed(1) # so that your "random" numbers match ours
### START CODE HERE ### (approx. 2 lines of code)
W1 = tf.get_variable(name='W1', dtype=tf.float32, shape=(4, 4, 3, 8), initializer=tf.contrib.layers.xavier_initializer(seed = 0))
W2 = tf.get_variable(name='W2', dtype=tf.float32, shape=(2, 2, 8, 16), initializer=tf.contrib.layers.xavier_initializer(seed = 0))
### END CODE HERE ###
parameters = {"W1": W1,
"W2": W2} #第1、2个卷积网络,第1个为3层对应RGB,第2个为8层对应第1个卷积层网络的个数
return parameters
'''
tf.reset_default_graph() #用于清除默认图形堆栈并重置全局默认图形
with tf.Session() as sess_test: #首先对所有变量进行初始化,防止带有之前执行过程中的残留值
parameters = initialize_parameters()
init = tf.global_variables_initializer() #开始训练前对变量进行初始化
sess_test.run(init) #在Sess中启用模型并初始化变量
print("W1 = " + str(parameters["W1"].eval()[1,1,1]))
print("W2 = " + str(parameters["W2"].eval()[1,1,1]))
'''
# GRADED FUNCTION: forward_propagation
def forward_propagation(X, parameters):
"""
Implements the forward propagation for the model:
CONV2D -> RELU -> MAXPOOL -> CONV2D -> RELU -> MAXPOOL -> FLATTEN -> FULLYCONNECTED
Arguments:
X -- input dataset placeholder, of shape (input size, number of examples)
parameters -- python dictionary containing your parameters "W1", "W2"
the shapes are given in initialize_parameters
Returns:
Z3 -- the output of the last LINEAR unit
"""
# Retrieve the parameters from the dictionary "parameters"
W1 = parameters['W1']
W2 = parameters['W2']
Z1 = tf.nn.conv2d(input=X, filter=W1, strides=[1, 1, 1, 1], padding='SAME')
# RELU
A1 = tf.nn.relu(Z1)
# MAXPOOL: window 8x8, sride 8, padding 'SAME'
P1 = tf.nn.max_pool(value=A1, ksize=[1, 8, 8, 1], strides=[1, 8, 8, 1], padding='SAME')
# CONV2D: filters W2, stride 1, padding 'SAME'
Z2 = tf.nn.conv2d(input=P1, filter=W2, strides=[1, 1, 1, 1], padding='SAME')
# RELU
A2 = tf.nn.relu(Z2)
# MAXPOOL: window 4x4, stride 4, padding 'SAME'
P2 = tf.nn.max_pool(value=A2, ksize=[1, 4, 4, 1], strides=[1, 4, 4, 1], padding='SAME')
# FLATTEN
P = tf.contrib.layers.flatten(P2)
# FULLY-CONNECTED without non-linear activation function (not not call softmax).
# 6 neurons in output layer. Hint: one of the arguments should be "activation_fn=None"
Z3 = tf.contrib.layers.fully_connected(P, 6, activation_fn=None)#没有激活函数
### END CODE HERE ###
return Z3
'''
#前向传播的测试代码
tf.reset_default_graph()
with tf.Session() as sess:
np.random.seed(1)
X, Y = create_placeholders(64, 64, 3, 6)#n_H0, n_W0,initialize_parameters n_C0, n_y
parameters = initialize_parameters()#初始化W参数
Z3 = forward_propagation(X, parameters)
init = tf.global_variables_initializer()
sess.run(init) #这里已经初始化参数W了
a = sess.run(Z3, {X: np.random.randn(2,64,64,3)}) #, Y: np.random.randn(2,6)}) 这里需要fetch参数X,Y并不需要用到
print("Z3 = " + str(a))
'''
def compute_cost(Z3, Y):
"""
Computes the cost
Arguments:
Z3 -- output of forward propagation (output of the last LINEAR unit), of shape (6, number of examples)
Y -- "true" labels vector placeholder, same shape as Z3
Returns:
cost - Tensor of the cost function
"""
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=Z3, labels=Y))#计算总的lost
return cost
'''
tf.reset_default_graph()
with tf.Session() as sess:
np.random.seed(1)
X, Y = create_placeholders(64, 64, 3, 6)
parameters = initialize_parameters()
Z3 = forward_propagation(X, parameters)
cost = compute_cost(Z3, Y)
init = tf.global_variables_initializer()
sess.run(init)
a = sess.run(cost, {X: np.random.randn(4,64,64,3), Y: np.random.randn(4,6)})
print("cost = " + str(a))
'''
def model(X_train, Y_train, X_test, Y_test, learning_rate = 0.009,
num_epochs = 100, minibatch_size = 64, print_cost = True):
"""
Implements a three-layer ConvNet in Tensorflow:
CONV2D -> RELU -> MAXPOOL -> CONV2D -> RELU -> MAXPOOL -> FLATTEN -> FULLYCONNECTED
Arguments:
X_train -- training set, of shape (None, 64, 64, 3)
Y_train -- test set, of shape (None, n_y = 6)
X_test -- training set, of shape (None, 64, 64, 3)
Y_test -- test set, of shape (None, n_y = 6)
learning_rate -- learning rate of the optimization
num_epochs -- number of epochs of the optimization loop
minibatch_size -- size of a minibatch
print_cost -- True to print the cost every 100 epochs
Returns:
train_accuracy -- real number, accuracy on the train set (X_train)
test_accuracy -- real number, testing accuracy on the test set (X_test)
parameters -- parameters learnt by the model. They can then be used to predict.
"""
ops.reset_default_graph() # to be able to rerun the model without overwriting tf variables
tf.set_random_seed(1) # to keep results consistent (tensorflow seed)
seed = 3 # to keep results consistent (numpy seed)
(m, n_H0, n_W0, n_C0) = X_train.shape
n_y = Y_train.shape[1]
costs = [] # To keep track of the cost
X, Y = create_placeholders(n_H0, n_W0, n_C0, n_y)
parameters = initialize_parameters()
Z3 = forward_propagation(X, parameters) #占位
cost = compute_cost(Z3, Y)
optimizer = tf.train.AdamOptimizer(learning_rate).minimize(cost)
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
for epoch in range(num_epochs):
minibatch_cost = 0.
num_minibatches = int(m / minibatch_size) # number of minibatches of size minibatch_size in the train set
#seed = seed + 1
minibatches = random_mini_batches(X_train, Y_train, minibatch_size, seed) #每迭代一次搅一次
for minibatch in minibatches: #舍弃最后不足64个样本的mini_batch
(minibatch_X, minibatch_Y) = minibatch
# IMPORTANT: The line that runs the graph on a minibatch.
# Run the session to execute the optimizer and the cost, the feedict should contain a minibatch for (X,Y).
_ , temp_cost = sess.run([optimizer, cost], feed_dict={X: minibatch_X, Y: minibatch_Y})
minibatch_cost += temp_cost / num_minibatches #取均值
# Print the cost every epoch
if print_cost == True and epoch % 5 == 0:
print ("Cost after epoch %i: %f" % (epoch, minibatch_cost))
if print_cost == True and epoch % 1 == 0: #每一个minibatch_cost都记录
costs.append(minibatch_cost)
# plot the cost
plt.plot(np.squeeze(costs)) #costs由for而来,因此x轴默认为epoch
plt.ylabel('cost')
plt.xlabel('iterations (per tens)')
plt.title("Learning rate =" + str(learning_rate))
plt.show()
# Calculate the correct predictions
predict_op = tf.argmax(Z3, 1)
# 返回的是Z3中的最大值的索引号,如果vector是一个向量,那就返回一个值,如果是一个矩阵,那就返回一个向量,这个向量的每一个维度都是相对应矩阵行的最大值元素的索引号。
correct_prediction = tf.equal(predict_op, tf.argmax(Y, 1))
# Calculate accuracy on the test set
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float")) #转换为浮点数后求均值
print(accuracy)
train_accuracy = accuracy.eval({X: X_train, Y: Y_train})
test_accuracy = accuracy.eval({X: X_test, Y: Y_test})
# 如果你有一个Tensor t,在使用t.eval()时,等价于:tf.get_default_session().run(t).
# 和最主要的区别就在于你可以使用sess.run()在同一步获取多个tensor中的值
print("Train Accuracy:", train_accuracy)
print("Test Accuracy:", test_accuracy)
return train_accuracy, test_accuracy, parameters
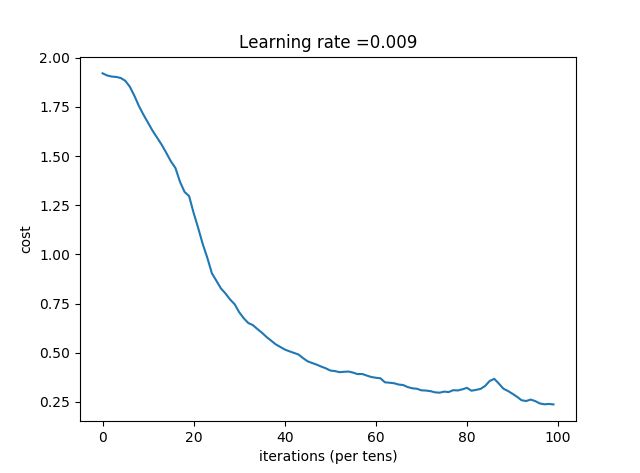
_, _, parameters = model(X_train, Y_train, X_test, Y_test)最终结果:
Cost after epoch 0: 1.920738
Cost after epoch 5: 1.882676
Cost after epoch 10: 1.668813
Cost after epoch 15: 1.473285
Cost after epoch 20: 1.210640
Cost after epoch 25: 0.865555
Cost after epoch 30: 0.705989
Cost after epoch 35: 0.601506
Cost after epoch 40: 0.516260
Cost after epoch 45: 0.456525
Cost after epoch 50: 0.409384
Cost after epoch 55: 0.398814
Cost after epoch 60: 0.372631
Cost after epoch 65: 0.338126
Cost after epoch 70: 0.308678
Cost after epoch 75: 0.302118
Cost after epoch 80: 0.321490
Cost after epoch 85: 0.356276
Cost after epoch 90: 0.291327
Cost after epoch 95: 0.253908
Tensor("Mean_1:0", shape=(), dtype=float32)Train Accuracy: 0.93796295
Test Accuracy: 0.825
测试精度要高于原expected output。
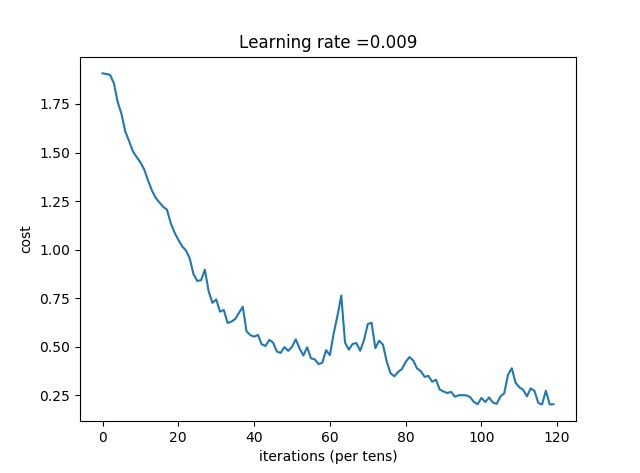
在原代码基础上加了2层卷积层,迭代120次,如下:
W1 = tf.get_variable(name='W1', dtype=tf.float32, shape=(4, 4, 3, 12), initializer=tf.contrib.layers.xavier_initializer(seed = 0))
W2 = tf.get_variable(name='W2', dtype=tf.float32, shape=(2, 2, 12, 18), initializer=tf.contrib.layers.xavier_initializer(seed = 0))
W3 = tf.get_variable(name='W3', dtype=tf.float32, shape=(2, 2, 18, 24), initializer=tf.contrib.layers.xavier_initializer(seed=0))
W4 = tf.get_variable(name='W4', dtype=tf.float32, shape=(2, 2, 24, 28),initializer=tf.contrib.layers.xavier_initializer(seed=0))效果如下,测试精度比上面又有较大提高。
Cost after epoch 0: 1.907746
Cost after epoch 5: 1.698216
Cost after epoch 10: 1.449311
Cost after epoch 15: 1.243343
Cost after epoch 20: 1.050992
Cost after epoch 25: 0.839239
Cost after epoch 30: 0.744019
Cost after epoch 35: 0.643134
Cost after epoch 40: 0.552430
Cost after epoch 45: 0.522427
Cost after epoch 50: 0.500758
Cost after epoch 55: 0.441110
Cost after epoch 60: 0.456845
Cost after epoch 65: 0.485794
Cost after epoch 70: 0.617060
Cost after epoch 75: 0.424403
Cost after epoch 80: 0.422788
Cost after epoch 85: 0.345599
Cost after epoch 90: 0.270114
Cost after epoch 95: 0.251089
Cost after epoch 100: 0.237303
Cost after epoch 105: 0.244143
Cost after epoch 110: 0.291859
Cost after epoch 115: 0.210787
Train Accuracy: 0.9351852Test Accuracy: 0.875