VLocNet++: Deep Multitask Learning for Semantic Visual Localization and Odometry 辅助学习 && 2018 论文笔记
作者:Noha Radwan∗Abhinav Valada∗Wolfram Burgard
研究机构:德国弗莱堡大学
本文解决了语义分割+相机重定位+视觉里程计VO三个任务。相机重定位指的是绝对位姿预测,VO则是相对位姿预测。本文还发布了一个用于定位的数据集DEEPLOC dataset.
多任务学习模型的好处是可以提高模型的泛化性,不需要大量的标签数据,且一次计算完成了多个任务,效率高。
本文基于VLocNet,提出了一种自适应的加权方法,能够利用运动特定时间信息(motion-specific temporalinformation)来提高定位精度。这种自适应加权方法,在融合网络的两个特征图时,可以调整加权权值得到更加合适的权值比例,得到的融合入特征图能够更好的描述特征信息。
本文在VLocNet的基础上加以改进:
- 联合前一帧的信息来对运动特定信息(motion specific information)进行累积
- 使用提出的自适应融合层对激活区域的语义特征进行自适应融合
- 提出一种自监督变换层(warping),在语义分段模型中聚合场景级上下文。
模型结构:相对位回归网络(VO模块)、绝对位姿回归网络、语义分割网络
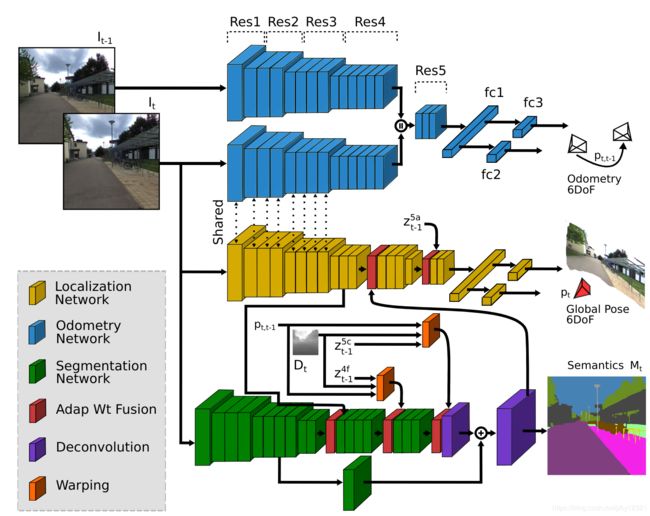
绝对位姿回归网络:
上图中间黄色的部分。中间两层红色的是本文提出的自适应权重融合层。
损失函数:
L l o c ( f ( θ ∣ I t ) ) : = L E u c ( f ( θ ∣ I t ) ) + L R e l ( f ( θ ∣ I t ) ) L_{loc}(f(θ|I_t)):=L_{Euc}(f(θ|I_t))+L_{Rel}(f(θ|I_t)) Lloc(f(θ∣It)):=LEuc(f(θ∣It))+LRel(f(θ∣It))
其中几何一致损失(相对位姿损失):
L R e l ( f ( θ ∣ I t ) ) = L x R e l ( f ( θ ∣ I t ) ) e x p ( − s ^ x R e l ) + s ^ x R e l + L q R e l ( f ( θ ∣ I t ) ) e x p ( − s ^ q R e l ) + s ^ q R e l 平 移 损 失 : L x R e l ( f ( θ ∣ I t ) ) : = ‖ x t , t − 1 − ( x ^ t − x ^ t − 1 ) ‖ 2 旋 转 损 失 : L q R e l ( f ( θ ∣ I t ) ) : = ∣ ∣ q t , t − 1 − ( q ^ t − 1 − 1 q ^ t ) ∣ ∣ 2 L_{Rel}(f(θ|I_t)) =L_{x_{Rel}}(f(θ|I_t))exp(−\hat s_{x_{Rel}})+ \hat s_{x_{Rel}} + L_{q_{Rel}}(f(θ|I_t))exp(−\hat s_{q_{Rel}}) + \hat s_{q_{Rel}}\\ 平移损失:L_{x_{Rel}}(f(θ|I_t)):=‖x_{t,t−1}−(\hat x_t−\hat x_{t−1})‖^2\\ 旋转损失: L_{q_{Rel}}(f(θ|I_t)):=||q_{t,t−1}−(\hat q_{t−1}^{−1}\hat q_t)||^2 LRel(f(θ∣It))=LxRel(f(θ∣It))exp(−s^xRel)+s^xRel+LqRel(f(θ∣It))exp(−s^qRel)+s^qRel平移损失:LxRel(f(θ∣It)):=‖xt,t−1−(x^t−x^t−1)‖2旋转损失:LqRel(f(θ∣It)):=∣∣qt,t−1−(q^t−1−1q^t)∣∣2
欧氏距离损失(绝对位姿损失):
L E u c ( f ( θ ∣ I t ) ) = L x ( f ( θ ∣ I t ) ) e x p ( − s ^ x ) + s ^ x + L q ( f ( θ ∣ I t ) ) e x p ( − s ^ q ) + s ^ q 平 移 损 失 : L x ( f ( θ ∣ I t ) ) : = ‖ x t − x ^ t ‖ 2 旋 转 损 失 : L q ( f ( θ ∣ I t ) ) : = ‖ q t − q ^ t ‖ 2 L_{Euc}(f(θ|I_t)) =L_x(f(θ|I_t))exp(−\hat s_x)+\hat s_x+L_q(f(θ|I_t))exp(−\hat s_q)+\hat s_q\\ 平移损失:L_x(f(θ|I_t)):=‖x_t−\hat x_t‖^2\\ 旋转损失:L_q(f(θ|I_t)):=‖q_t−\hat q_t‖^2 LEuc(f(θ∣It))=Lx(f(θ∣It))exp(−s^x)+s^x+Lq(f(θ∣It))exp(−s^q)+s^q平移损失:Lx(f(θ∣It)):=‖xt−x^t‖2旋转损失:Lq(f(θ∣It)):=‖qt−q^t‖2
VO模块:
上图中蓝色的两支。
注意下面的一支与 绝对位姿回归网络由于都在 I t I_t It上提特征,所以是共享权重的。
损失函数:
L v o ( f ( θ ∣ I t , I t − 1 ) ) : = L x ( f ( θ ∣ I t , I t − 1 ) ) e x p ( − s ^ x v o ) + s ^ x v o + L q ( f ( θ ∣ I t , I t − 1 ) ) e x p ( − s ^ q v o ) + s ^ q v o L x 、 L q 分 别 表 示 平 移 损 失 和 旋 转 损 失 L_{vo}(f(θ|I_t,I_{t−1})):=L_x(f(θ|I_t,I_{t−1}))exp(−\hat s_{x_{vo}})+\hat s_{x_{vo}} + L_q(f(θ|I_t,I_{t−1}))exp(−\hat s_{q_{vo}})+\hat s_{q_{vo}}\\ L_x、L_q分别表示平移损失和旋转损失 Lvo(f(θ∣It,It−1)):=Lx(f(θ∣It,It−1))exp(−s^xvo)+s^xvo+Lq(f(θ∣It,It−1))exp(−s^qvo)+s^qvoLx、Lq分别表示平移损失和旋转损失
语义分割模块:
上图中绿色的部分。
首先计算每个像素的类别:
p j ( u r , θ ∣ I n ) = e x p ( s j ( u r , θ ) ) ∑ k C e x p ( s k ( u r , θ ) ) s j ( u r , θ ) 代 表 像 素 u r 的 得 分 , θ 为 模 型 权 重 p_j(u_r,θ|I_n) =\frac{exp(s_j(u_r,θ))}{\sum ^C_kexp(s_k(u_r,θ))}\\ s_j(u_r,\theta)代表像素u_r的得分,\theta为模型权重 pj(ur,θ∣In)=∑kCexp(sk(ur,θ))exp(sj(ur,θ))sj(ur,θ)代表像素ur的得分,θ为模型权重
损失函数:
L s e g ( T , θ ) = − ∑ n = 1 N ∑ r = 1 ρ ∑ j = 1 C δ m r n , j l o g p j ( u r , θ ∣ I n ) C : c l a s s n u m b e r N : i m a g e s n u m b e r ρ : p i x e l n u m b e r p e r i m a g e L_{seg}(T,θ) =−\sum^N_{n=1}\sum^ρ_{r=1}\sum^C_{j=1}δ_{m^n_r,j}logp_j(u_r,θ|I_n)\\ C : class \ number\\ N: images\ number\\ ρ: pixel\ number\ per\ image Lseg(T,θ)=−n=1∑Nr=1∑ρj=1∑Cδmrn,jlogpj(ur,θ∣In)C:class numberN:images numberρ:pixel number per image
然后介绍自监督的变换层:
self-supervised Warping:
上图中橘色的网络层
根据t-1时刻的特征图生成对应的深度图(用DispNet),然后利用估计的相对位姿将其变换到t时刻的视角下,将其与特时刻的特征图融合。这样多视角、多分辨率的信息使得模型对视角、尺度、畸变等场景下依然有很强的鲁棒性。
数学表达 :
u r : = π ( T ( p t , t − 1 ) π − 1 ( u r , D t ( u r ) ) ) D t 表 示 深 度 图 T ( p t , t − 1 ) 表 示 相 对 位 姿 p t , t − 1 对 应 的 齐 次 旋 转 矩 阵 π 表 示 投 影 函 数 u_r:=π(T(p_{t,t−1})π^{−1}(u_r,D_t(u_r)))\\ D_t表示深度图\\ T(p_{t,t−1})表示相对位姿p_{t,t−1}对应的齐次旋转矩阵\\ \pi 表示投影函数 ur:=π(T(pt,t−1)π−1(ur,Dt(ur)))Dt表示深度图T(pt,t−1)表示相对位姿pt,t−1对应的齐次旋转矩阵π表示投影函数
adaptive weighted fusion layer:
用于组合来自多个层或多个网络的特征的常用做法是:执行张量的级联或逐元素的加法/乘法。 尽管这在两个张量都包含足够的相关信息时可能是有效的,但这种操作通常会累积不相关的特征图,它的有效性在很大程度上取决于进行融合的网络的中间层。
这里作者提出了可以自适应加权的机制:
假设两张特征图为 z a z b z^a\ z^b za zb,则自适应融合女机制可写为:
z ^ f u s e = m a x ( W ∗ ( ( w a ⊙ z a ) ⊕ ( w b ⊙ z b ) ) + b , 0 ) W 、 b : 非 线 性 池 化 的 参 数 ( 即 1 ∗ 1 卷 基 层 + R e L U ) ⊙ : 对 应 通 道 相 乘 ⊕ : 对 应 通 道 相 连 接 ∗ : 卷 积 操 作 \hat z_{fuse}=max(W∗((w^a\odot z^a)\oplus(w^b\odot z^b))+b,0)\\ W、b:非线性池化的参数(即1*1卷基层+ReLU)\\ \odot: 对应通道相乘\\ \oplus: 对应通道相连接\\ *: 卷积操作 z^fuse=max(W∗((wa⊙za)⊕(wb⊙zb))+b,0)W、b:非线性池化的参数(即1∗1卷基层+ReLU)⊙:对应通道相乘⊕:对应通道相连接∗:卷积操作
总的损失函数:
L m u l t i : = L l o c e x p ( − s ^ l o c ) + s ^ l o c + L v o e x p ( − s ^ v o ) + s ^ v o + L s e g e x p ( − s ^ s e g ) + s ^ s e g L_{multi}:=L_{loc}exp(−\hat s_{loc})+\hat s_{loc}+L_{vo}exp(−\hat s_{vo})+\hat s_{vo} +L_{seg}exp(−\hat s_{seg})+\hat s_{seg} Lmulti:=Llocexp(−s^loc)+s^loc+Lvoexp(−s^vo)+s^vo+Lsegexp(−s^seg)+s^seg
其中 s ^ \hat s s^均指可学习的权值参数。
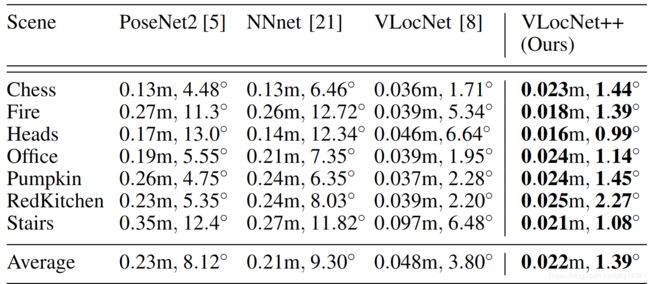
7-SCENES数据集,定位对比:
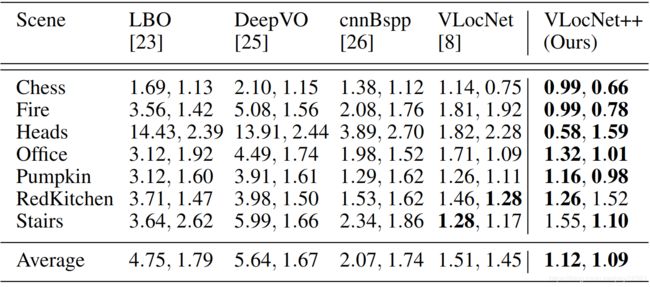
7-SCENES数据集,VO对比:
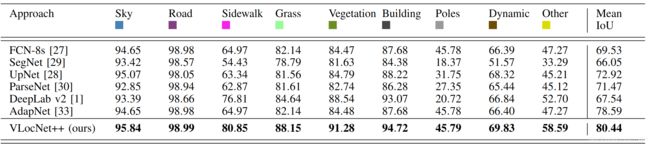
DEEPLOC DATASET,语义分割对比:
VO性能可视化:
在户外、户内、重复文理、无文理、反射等环境下都有较好的鲁棒性