基于C语言的DB2数据库开发
作者:super_bert@csdn
基于C语言的DB2数据库开发
本文探讨了C语言环境下DB2数据库系统的开发过程,着重分析了DB2的开发关键过程及不同于其他数据库的特别之处,并提供了解决关键性问题的程序示例。
引言
IBM公司的DB2数据库作为当前三大主流数据库之一,在数据库系统开发中占优很大的市场份额,特别是金融行业中,因往往使用IBM自身的AIX系统以及AS400/RS600等服务器,有关的应用系统开发更是越来越偏重于采用DB2数据库。然而,在开发过程中,由于DB2内部的机制及编程方面的限制,使刚开始从事DB2数据库开发或从其他数据库移植到DB2的开发人员感到迷惑重重,难以从其他数据库的开发习惯中适应过来。另外市面上不像ORACLE/SQL SERVER那样有成排的资料书籍,DB2除了IBM自己提供的英文资料外,对开发有参考价值的技术资料相对很少。因此笔者结合自己最近开发的几套DB2应用系统,着重从基于C语言环境下的DB2开发过程做一探讨,并针对和其他数据库开发的不同之处,以及部分关键性问题的解决作详细分析和应用示例。
1.DB2应用程序开发概述
在进行DB2应用开发之前,了解DB2应用程序的结构,掌握相关概念是很必要的。
1.1嵌入式SQL编程
嵌入式SQL应用程序就是将SQL语句嵌入某个宿主语言中,SQL语句提供数据库接口,存取并处理 DB2 数据库中的数据,宿主语言提供应用程序的其他执行功能。嵌入式SQL语句包括静态 SQL 语句和动态 SQL 语句。
1.2宿主语言
用于创建主程序的程序设计语言称为宿主语言,例如DB2可以用 C/C++、COBOL、FORTRAN、Java (SQLJ) 以及 REXX 程序设计语言来编写嵌入式SQL 应用程序,这些程序设计语言都称为宿主语言。
1.3静态 SQL 语句
在编译前就知道 SQL 语句内容以及以及将要存取的表名和列名。唯一未知的是语句正搜索或更新的特定数据值。可以用宿主语言变量表示那些值。在运行应用程序之前,要预编译、编译和捆绑静态 SQL 语句。
1.4动态 SQL 语句
是应用程序在运行期构建并执行的那些语句。一个提示最终用户输入 SQL 语句的关键部分(如要搜索的表和列的名称)的交互式应用程序是动态 SQL 一个很好的示例。 应用程序在运行时构建 SQL 语句,然后提交这些语句进行处理。
可以编写只有静态 SQL 语句或只有动态 SQL 语句,或者兼有两者的应用程序。
1.5宿主变量(Hostvariables)
在主应用程序中由嵌入式SQL语句引用的变量。宿主变量是该应用程序中的程序设计变量,并且是在数据库中的表与应用程序工作区之间传送数据的主要机制。我们称之为“宿主变量”,是为了与通常方法声明的源语言变量区分开来,通常方法声明的变量不能被SQL语句引用。宿主变量在宿主语言程序模块中以一种特殊的方式声明:必须在BEGIN DECLARE SECTION和END DECLARE SECTION程序节内定义。
2.静态SQL程序开发
2.1静态SQL例程
在程序结构上,DB2和其他数据库非常相似,下面先来看一个静态SQL程序的C语言例子static.sqc:
#include
#include
#include
EXEC SQL INCLUDE SQLCA; /*包含结构SQLCA, 以便获取SQL执行信息*/
#define CHECKERR(CE_STR) if (sqlca.sqlcode != 0)\
{printf("%s. sqlcode = [%s]\n", CE_STR, sqlca.sqlcode); return 1;}
int main(int argc, char *argv[])
{
EXEC SQL BEGIN DECLARE SECTION;
char firstname[12 + 1];
char userid[8 + 1];
char passwd[18 + 1];
EXEC SQL END DECLARE SECTION;
printf("Sample C program: STATIC\n");
if (1 == argc)
{
EXEC SQL CONNECT TO sample;
CHECKERR ("CONNECT TO SAMPLE");
}
else if (3 == argc)
{
strcpy(userid, argv[1]);
strcpy(passwd, argv[2]);
EXEC SQL CONNECT TO sample USER :userid USING :passwd;
CHECKERR ("CONNECT TO SAMPLE");
}
else
{
printf("\nUSAGE: static [userid passwd]\n\n");
return 1;
}
EXEC SQL SELECT FIRSTNME INTO :firstname
FROM employee
WHERE LASTNAME = 'BERT' and ;
CHECKERR ("SELECT statment");
printf("First name = %s\n", firstname);
EXEC SQL CONNECT RESET;
CHECKERR(CONNECT RESET);
return 0;
} 例程1-静态SQL例程
2.2静态SQL程序的结构和特点
从上面的例程可以看到,典型的静态SQL程序结构包含以下关键部分:
1)包括结构SQLCA: INCLUDESQLCA语句定义和声明了SQLCA结构,SQLCA结构中定义了SQLCODE和SQLSTATE域。数据库管理器在执行完每一条SQL语句或者每一个数据库管理器API调用,都要更新SQLCA结构中的SQLCODE域的诊断信息。
2)声明宿主变量:SQL BEGIN DECLARE SECTION和END DECLARE SECTION 语句界定宿主变量的声明。宿主变量用来将数据传递给数据库管理或者接收数据库管理器返回的数据。在SQL语句中引用宿主变量时,必须在宿主变量前加前缀冒号(:)。详细信息看2.4节。
3)连接到数据库:应用程序必须先连接到数据库,才能对数据库进行操作。这个程序连接到SAMPLE数据库,请求以共享方式访问。其他应用程序也可以同时以共享访问方式连接数据库
4)输入宿主变量赋值:在SQL语句执行之前,如果要引用宿主变量作为条件或插入值(称之为输入宿主变量),则要求先进行赋值。
5)提取或处理数据。SELECT INTO语句基于一个查询提取了一行值。这个例子从EMPLOYEE表中,将LASTNAME列的值为JOHNSON的相应行的FISRTNME列的值提取出来,置于宿主变量firstname中。
6)处理错误:CHECKERR 宏/函数是一个执行错误检查的外部函数,判断前面的SQL语句是否执行成功。
7)程序运行结束,断开数据库连接。
2.3DB2预编译及绑定
为了使用包含嵌入式 SQL 的程序,不仅要进行典型的准备步骤(编译、链接和运行),还必须执行 DB2预编译和绑定步骤。这些步骤将为数据库管理器创建执行时需要的程序包其编译过程如(图一)所示:
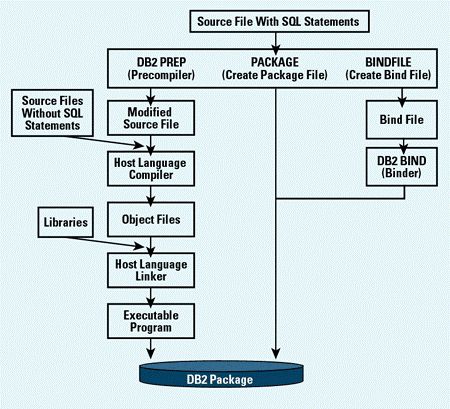
图1-预编译过程
2.3.1预编译
将嵌入式 SQL 源语句转换为数据库管理器可使用的形式。以例程1为例,预编译命令如下:
DB2 PREP static.sqc [PACKAGE[USING mypack]] [BINDFILE [USING mytest.bnd]]
其中PACKAGE、BINDFILE为可选项,当PACKAGE选项(默认的),或者没有指定任何BINDFILE、SYNTAX、SQLFALG选项,预编译后自动在数据库中生成以文件名前8位命名的程序包,USING mypack 指定生成的程序包名为mypack;BINDFILE在预编译时同时产生文件名前8位.bnd,USING mytest.bnd指定生成的绑定文件名为mytest.bnd文件(详细命令请参考IBM提供的《IBM DB2Universal Database Command Reference》)。
该步骤最多可以生成4类文件:
1) 修改后的文件:该文件中SQL语句被屏蔽,转换成可以被宿主语言直接调用的API函数,本例中此文件为static.c。
2) 程序包:程序包存放在对应数据库中,里面包含数据库系统在捆绑时对特定SQL语句所产生的访问策略。
3) 绑定文件:如果使用了BINDFILE选项将产生该文件,每一个独立预编译的源代码文件都将创建一个程序包。
4) 消息文件:如果使用了MESSAGES选项,预编译器将警告和错误信息重定向到指定的文件中,否则被写到标准输出上。
2.3.2 编译和链接
宿主语言自身的编译链接过程,创建必要的目标模块,链接生成执行文件。如C语言采用CC命令生成.o文件,再链接相关库产生执行文件。
2.3.3绑定
如果预编译时使用了BINDFILE选项,并且预编译时和运行在不同的机器环境上,则要求把预编译生成的*.bnd文件拷贝到运行环境,再执行DB2 BIND命令,以便在运行环境数据库中生成数据库管理器将使用的程序包。
2.3.4和其他数据库的区别
从上面的分析可以看到DB2的编译过程不同于其他数据库(如ORACLE,SYBASE,INFORMIX等),预编译时将源文件中的SQL语句注释掉,替换为对应的数据库运行时API调用外,DB2还将产生存取程序包或绑定文件(如果使用的BINDFILE选项,相应的要增加DB2 BIND操作),这是其他数据库所没有的。正因为如此,在预编译或绑定时,如果程序中包括静态SQL语句,编译时必须要求:
1)连接到程序中涉及的数据库。
2)SQL语句中涉及的表和字段要求存在(创建类的语句除外)。
3)当数据库结构修改或数据库统计信息更新后,必须重新编译程序。静态SQL语句的性能决定于应用程序最后一次被捆绑时数据库的统计信息。 然而,如果这些统计信息改变了,那么比较起来,等效的动态SQL语句的性能可能好些。在某个使用静态SQL的应用程序捆绑之后,数据库增加了一个索引,如果这个应用程序不重新捆绑,就不能利用这个索引。
4)DB2INCLUDE变量指向相关头文件。
5)xlC –p –DMYMACRO =1 ->processor-command。
6)EXEC SQL INCLUDE中不能出现双引号。
7)char类型最长为254
2.4DB2宿主变量的定义和引用
2.4.1 宿主变量的声明
在C语言环境下,DB2宿主变量声明表示如下:
EXECSQL BEGIN DECLARE SECTION;
short dept=38, age=26;
double salary;
char CH;
char name1[9], NAME2[9];
/* C 注释 */
short nul_ind;
char *address, *telno[10];
EXEC SQL ENDDECLARE SECTION;
2.4.2 宿主变量的约定和限制
DB2宿主变量的定义和引用遵循以下常规约定:
1)所有被嵌入SQL引用的宿主变量必须在BEGIN和END DECLARE语句界定的代码区里声明;
2)在一个源文件中,可以有多个界定区,可以出现在任何变量声明允许的地方;
3)BEGIN DECLARE SECTION和END DECLARE SECTION语句必须成对出现,并且不能嵌套;
4)宿主变量的数据类型必须与列的数据类型匹配,而且尽量避免数据转换和截取;
5)在同一作用域内,宿主变量和常规变量不能同名;
6)宿主语言标号在SQL语句中引用时前面加冒号。
7)宿主变量声明可以使用SQL INCLUDE语句指定。
另外,DB2宿主变量的定义还有以下限制:
1)宿主变量名不能以EXEC、SQL、sql开头;
2)宿主变量应该被看作是模块程序的全局变量,而不是定义所在函数的局部变量,因此在同一个嵌入式SQL程序文件中,不同函数间申明的宿主变量不能同名!
3)不能引用宏定义,如char buf[LEN_MAX]是非法的,必须将LEN_MAX替换为常量数据。
4)char *方式声明的宿主变量和C语言常规变量有异义:在C语言中,char *address表示一个指向字符串变量的指针,而如果是DB2宿主变量的话,则表示一个指向字符的指针,char *address[60]在DB2中表示一个指向长度为60的字符串变量的指针,而这在C语言中表示60个指向字符串变量的指针数组!
2.4.3针对宿主变量限制的解决办法
上面的限制对刚开始接触DB2开发或从其他数据库移植到DB2时感到非常困惑,通过实践和咨询IBM技术人员,笔者对上面的限制采用下面的办法进行解决,希望能给读者有所帮助。
对于限制2),可以下列方法(要求同名的宿主变量类型相同或兼容):
1)将本文件中所以相同名称的宿主变量在文件开始处统一声明为全局变量,再取消函数内的局部宿主变量声明。
2)或者在第一次出现要引用该宿主变量的地方声明为宿主变量,在其他函数中声明为常规局部变量(此宿主变量在该函数仍可以作为宿主变量引用)
对于限制.
3)在预编译(DB2 PREP命令)可以增加PREPROCESSOR选项,则预编译器会首先处理所有SQL INCLUDE语句引用的文件进行内容替换,预编译再用替换后的文件进行编译。
对于限制.
4)如果采用了char*pVar的方式,则只能修改为charsVar[LEN]的方式了,并需要修改指针方式下的 “pVar=sString” 为 strcpy(sVar,sString)。
3.DB2动态SQL程序开发
为了增加应用程序的灵活性,允许应用程序在运行过程中动态地产生并执行SQL语句,我们称其为动态嵌入式SQL语句,一个提示最终用户输入 SQL 语句的关键部分(如要搜索的表和列的名称)的交互式应用程序是动态 SQL 一个很好的示例。由于动态嵌入式SQL语句的内容(或其中一部分内容)是在程序运行中产生的,在预编译时还无法确定,所以BIND过程无法象对待静态嵌入式SQL语句那样,在程序实际运行之前确定其执行方案并创建相应的程序包。因此,动态嵌入式SQL语句的BIND过程只能是动态的,即在程序实际运行过程中完成的。
3.1动态嵌入式SQL语句的类型
按照动态嵌入式SQL语句是否为查询语句以及是否包含参数标志,可以将其分为以下几种类型:
3.1.1除SELECT之外的动态SQL语句
即除了SELECT之外的其它所有可执行的SQL语句。由于这类语句没有返回结果集,所以其处理也相对最为简单。
3.1.2 输出结果列固定的动态SELECT语句
与处理静态嵌入式SELECT语句的返回结果集一样,在应用程序中也需要使用游标来处理动态嵌入式SELECT语句的返回结果集。而对于输出结果列完全固定的SELECT语句,由于在编程时已事先知道其输出结果列的数据类型,所有可以在程序中预先定义相应的宿主语言变量来接收查询结果集中的数据值。
3.1.3全部内容完全动态的SQL语句
而对于所有内容都不固定的SELECT语句,由于在编程时无法事先知道其会产生哪些输出结果列,所有只能在程序中使用SQLDA(又称SQL描述符区)这种动态数据结构及动态分配的宿主语言变量来接收查询结果集中的数据值。
3.1.4参数化的动态语句
即当中含有参数标记(?)的动态SQL语句。由于参数化的语句在执行之前必须对其中的参数标记进行赋值,所以,相对非参数化的语句,其处理要更加复杂一些。
3.2动态SQL例程
以下是采用SQLDA处理任意动态SQL语句的程序代码片段(例程2):
...
EXEC SQL INCLUDE SQLDA; /*或 #include */
struct sqlda *sqldaptr = NULL; /*①定义SQL描述区*/
EXEC SQL BEGIN DECLARE SECTION;
char sSQLstr[1024];
...
EXEC SQL END DECLARE SECTION;
GetSQL(sSqlstr); /*获取需要执行的动态语句*/
if ((sqldaptr = (struct sqlda * remalloc(SQLDASIZE(sqldaptr->sqld)))) == NULL)
{
LOG("申请动态描述区失败\n");
return -1;
}
/*②对sSqlstr中的语句进行预处理,并得到相应结果集描述信息填入sqldaptr*/
EXEC SQL PREPARE DYNSQL INTO :*sqldaptr FROM :sSQLstr;
if (SQLERR)
{
LOG("预处理[%s]失败sqlcode[%d]", sSQLstr, sqlca.sqlcode);
return -1;
}
if (0 == sqldaptr->sqld) /*non-select 语句*/
{
EXEC SQL EXECUTE DYNSQL; /*③执行动态语句*/
return;
}
if (sqldaptr->sqln < sqldaptr->sqld) /*select 语句*/
{ /*根据实际条目数重新为SQLDA分配空间*/
sqldaptr = (struct sqlda * remalloc(SQLDASIZE(sqldaptr->sqld)));
EXEC SQL DESCRIBE DYNSQL INTO :*sqldaptr; /*④重新获得结果描述信息*/
}
{
/*根据结果集描述信息分配输出主变量和提示符变量,并将其地址填入sqldaptr中*/
... ...
}
EXEC SQL DECLARE C1 CURSOR FOR DYNSQL;/*根据动态语句定义游标*/
EXEC SQL OPEN C1;
... ...
EXEC SQL FETCH C1 USING DESCRIPTOR :*sqldaptr; /*⑤利用描述区提取记录*/
... /*处理每条记录*/
EXEC SQL CLOSE C1;
free(sqldaptr); /*⑥释放SQL描述区空间*/ 我们分析一下例程2中关键的步骤:
①定义SQL描述区,用来在应用程序和数据库系统之间传递有关列(或宿主变量)的数目及数据类型与/或值等方面的信息(描述区将在下文进行详细叙述)。
②调用PREPARE语句对动态语句进行预处理,并将得到的结果集描述信息填入描述区,其语法格式为:
PREPARE 语句名 [INTO 描述符] FROM :宿主变量
其中,语句名可为任何标识符,宿主变量是一个字符串型的变量并且必须含有一条有效的SQL语句,描述符是一个类型为SQLDA的宿主语言变量。该语句的功能是对一条SQL语句(包含在FROM之后的宿主变量中)进行预处理,并用语句名作为处理后的语句的标识(以便在后面的DESCRIBE,EXECUTE或OPEN语句中引用)。PREPARE语句要求被处理SQL语句中不能出现任何宿主变量,但可以包含一个或多个参数标记(用问号“?”表示),表示语句执行时需要从外部得到的值。如果PREPARE语句出现“INTO 描述符”选项,则将被处理语句的结果集中各个列的描述信息填入所给的描述符中。对sSqlstr中的语句进行预处理
③调用EXECUTE语句,该语句的功能是执行一条前面已预处理过的语句(由语句名所标识)。语法格式为:
EXECUTE 语句名 [USING 宿主变量1,…,宿主变量n |
USING DESCRIPTOR描述符]
其中,语句名为一个标识符并且必须标识一条前面已预处理过的语句,描述符是一个类型为SQLDA的宿主语言变量。
④调用DESCRIBE语句,该语句的作用类似于PREPARE语句中的“INTO描述符”子句,其功能是得到语句名所标识的那条语句(已预处理过的)的结果集中各个列的描述信息,并将其填入所给的描述符中。格式为:
DESCRIBE 语句名INTO 描述符
其中,语句名为一个标识符并且必须标识一条前面已预处理过的语句,描述符是一个类型为SQLDA的宿主语言变量。
⑤调用FETCH语句,将当前游标结果提取到描述区,然后进行处理。
⑥处理结束,释放描述区空间。
3.3SQLDA的组成和存储格式
在上面的动态例程中,有一个很关键的结构:struct sqlda*sqldaprt。SQLDA又称SQL描述符区(Descriptor Area),SQLDA是一种功能非常强大且使用非常灵活的动态数据结构。SQLDA的存储空间可在程序运行期间根据需要动态进行分配,并可针对任何动态SQL语句,得到有关列的数目、数据类型、长度、精度等方面的描述信息,或针对动态分配的宿主变量设置变量的数目、数据类型、位置及变量值。因此,SQLDA比程序中的静态宿主变量列表更加灵活,也更加复杂。
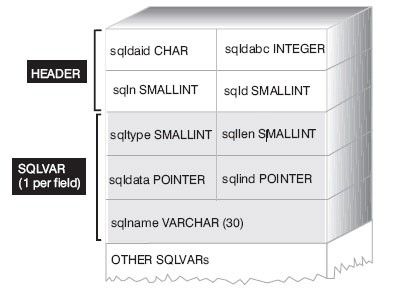
图2- SQLDA的存储格式
如图2所示,SQLDA是由1个头(header)及若干个(可以为0个或多个)需要描述的列或变量(又称为条目(entry))的描述信息组成。其中SQLDA头(header)信息的大小为16字节(Byte);每一个条目信息占44字节(Byte)。因此,一个SQLDA的总的大小是由其中所包含的条目数(sqlvars)决定的,即按字节计算,一个SQLDA的大小应为16+条目数*44 Byte。
SQLDA的头信息包括下列内容:
- sqldaid: 存储块标志,其中固定含有字符串“SQLDA”;
- sqldabc:SQLDA存储块的总长(以字节计);
注:通常,sqldabc的值是由DESCRIBE语句设置的。但如果程序员在使用SQLDA时未调用DESCRIBE语句,则应有程序员自己负责为该域设置适当的值。
- sqln:SQLDA中可以使用的描述区块(44Byte)的数目;(SQLVARs)
- sqld:SQLDA中实际描述的条目数;
注:sqld的值可以程序执行不同的语句而改变,但必须总是小于或等于sqln。
SQLDA中每一个条目的信息包括以下内容:
- sqltype:被描述的列的数据类型(如character,decimal,date等)及该列是否允许空值(NULL);
- sqllen: 被描述的列的外部长度(以字节计)。对于decimal(十进制)类型的列,其第1个字节说明列的精度,第2个字节说明总的位数;
- sqldata:为一个无符号的字符指针,其中包含的是指向相应宿主变量的地址;
- sqlind:为一个指向short(短整型)型的指针,其中包含的是指向相应指示符变量(indicatorvariable)的地址(如果有的话);
- sqlname:包含了被描述的列的名称。如果被描述的列在原SELECT 列表中对应的是一个表达式,则sqlname中包含是该列在原SELECT列表中的相对位置编号。在C语言中,sqlname为一个命名的结构(struct),其中包含一个名为length的整型域表示该列名字的长度以及名为name的字符数组用于存放该列的名字。
SQLDA中条目的内容是由SQLDA的使用方式决定的。
1)如果在PREPARE或DESCRIBE语句中使用SQLDA,则得到的条目是对查询结果集各数据列的描述,包括列的数据类型、长度、精度和名称。
2)如果是在OPEN,FETCH,EXECUTE或CALL语句中使用SQLDA,则其中的条目将被用于描述相应语句中所需宿主变量(其中OPEN和EXECUTE语句中为输入主变量,FETCH语句中为输出主变量,CALL语句中为双向主变量)。描述的内容包括变量的数据类型、由宿主程序分配给该变量的内存地址和长度,此外还可以包含一个指示符变量的地址,用于表示空值。
3)SQLDA中每一个条目的数据类型由该条目中的sqltype域表示。
sqltype存放的是相应数据类型的编码,表X 列出了sqltype中可能出现部分编码及其对应的数据类型。
| Sqltype中的编码值 |
表示的数据类型 |
长 度 |
|
| 448 |
VARCHR,NOT NULL |
MAX |
|
| 452 |
CHAR,NOT NULL |
长度 |
|
| 480 |
FLOAT,NOT NULL |
8 |
|
| 484 |
DECIMAL,NOT NULL |
精度 |
位数 |
| 496 |
INTERGER,NOT NULL |
4 |
|
| 500 |
SMALLINT,NOT NULL |
2 |
|
注1:编码值为偶数时表示相应的列不能为空值,为奇数时则表示相应的列允许为空值;
注2:该表只列出了部分数据类型的编码,完整的编码可查阅《SQL参考手册》;
表X 部分数据类型的编码
3.4SQLDA的使用规则
SQLDA是一种动态数据结构,其作用是在应用程序和数据库系统之间传递有关列(或宿主变量)的数目及数据类型与/或值等方面的信息。SQLDA的使用涉及应用程序和数据库系统两个方面。使用SQLDA应注意以下规则:
1) SQLDA的定义及存储空间的分配和释放都是由应用程序负责的。所以,应用程序首先应保证为SQLDA分配足够大小的存储空间,以便能够容纳需要描述的条目信息,并负责将SQLDA可容纳的最大条目数填入sqln域中。
2) 为了得到一条动态生成的SQL语句的描述信息,应用程序可通过调用含有SQLDA选项的PREPARE语句或DESCRIBE语句将相关的语句及SQLDA交给数据库系统,数据库系统负责对提交的语句进行预处理,将描述该语句实际需要的条目数填入sqld中。并且如果SQLDA的存储空间足够大(即sqln>=sqld),则数据库系统还会将该语句结果集中各个列的描述信息填入SQLDA中;否则(即sqln 3) 应用程序在调用了含有SQLDA选项的PREPARE语句之后,应对sqld的值进行检查,如果sqld=0,则表明要执行的是一条非SELECT语句,这时可直接调用EXECUTE IMMEDIATE执行该语句。如果sqld>0,则表明要执行的是一条SELECT语句,这时,如果SQLDA中已有足够的条目(即sqld <= sqlm)则应按照每一条目的SQLTYPE分配相应的主变量和指示符变量,并将分配的主变量和指示符变量的地址填入SQLDATA和SQLIND中;如果SQLDA中没有足够的条目(即sqld >sqlm),则重新为SQLDA分配足够的条目,并用DESCRIBE语句获得SQL语句的描述信息,然后按照每一条目的SQLTYPE分配相应的主变量和指示符变量,并将分配的主变量和指示符变量的地址填入SQLDATA和SQLIND中。 1) 嵌入在应用程序中的动态SQL语句的绑定(BIND),是在程序运行期间通过调用EXECUTE IMMEDIATE或PREPARE动态完成的。因此应用程序的相应时间应包括绑定动态语句所耗费的时间。而静态绑定是在程序运行之前进行的,并且其结果(即语句的执行策略)已以程序包的形式存储在数据库中。因此,应用程序运行期间只需调用相应的程序包,而不再需要为绑定花费时间。 2)与静态绑定一次将对程序中的全部静态嵌入式语句进行分析和处理不同,一次动态绑定只对单个一条语句进行分析和处理。 3)与静态绑定所产生的结果(即程序包)将被长久保存在数据库中不同,动态绑定所产生的结果(即语句的执行策略),只被临时缓存在内存中,而不再长久保存。 在很多数据库中均有DECIMAL类型,该类型用以存放十进制的整数或浮点数,其格式为M.N表示总长度为M位,其中小数部分为N位。此类数据的优点不受取值范围限制,可以任意位,同时又节省存贮空间。其在数据库中的存储格式为:占用总字节数I=[(M+1)/2]取整,第I字节的低位存放符号,高位存放末位数,依次往低地址的字节的低位,高位存放前面位数的数据,高位数不足前补0。例如格式为7.2,实际数据为1234.56, DECIMAL的存放格式如图3所示。 图3-DECIMAL存储格式 下面例程演示了如何将一个数字型字符串转换为DECIMAL类型的过程,相信大家在进行动态SQL编程时,如果和SQL描述区进行数据交换时会用到。 例程3-DECIMAL类型的存取 在实际开发过程中,我们经常会碰到动态的往指定表中插入数据,数据源可以是文件或程序中的某个结构。下面的例程就演示了此类问题的处理过程。 例程4-动态装载例程 附: IBM公司, 《IBM DB2 UniversalApplication Development Guide》英文版 http://ibm.com/software/ data/db2/udb/ ad/v7/adg.html IBM公司, 《IBM DB2Universal Database Command Reference》英文版 http://ibm.com/software/ data/db2/udb/ ad/v7/adg.html Debra Eaton,《入乡随俗: 为 DB2 进行开发》http://www-128.ibm.com/developerworks/cn/db2/library/techarticles/mag_02q2eaton/eaton.html?ca=dwcn-newsletter-dmdd#author13.5动态绑定与静态绑定的比较
4.DB2程序开发的实用示例
4.1如何存取DECIMAL类型的数据

/**************************************************************
函数名称:fpub_str2deciaml();
函数功能:将数字型字符串转换为DECIMAL类型
函数说明:
序号 参数名称 缺省值 是否可空 参数说明
-----------------------------------------------------------
1. sSrcdata 否 数字型字符串
2. iPrec 否 转换后总位数
3. iScale 否 小数位数
4. sDecimal 否 转换后数据指针
***************************************************************/
int fpub_str2decimal(char *sSrcdata, int iPrec, int iScale, char *sDecimal)
{
short numBytes;
short byteNb;
char sData[128];
int i, iLen, iPrecision;
int iIntLen; /*整数部分长度*/
short iHigh = 0, iLow = 0; /*高地位数值*/
char *ptc;
iPrecision = iPrec;
if ((iPrecision %2) == 0)
{
iPrecision = iPrecision + 1;
}
/*计算目标串字节数*/
numBytes = (short)(iPrecision + 1) / 2;
memset(sDecimal, 0, numBytes);
/*去除前导0*/
for (i = 0; (i < strlen(sSrcdata)) &&
((sSrcdata[i] == '0') ||
(sSrcdata[i] == '-') ||
(sSrcdata[i] == '-')); i++);
memset(sData, 0x00, sizeof(sData));
strcpy(sData, sSrcdata + i);
iLen = strlen(sData);
ptc = strchr(sData, '.');
if (ptc != NULL) /*含小数点*/
{
iIntLen = ptc - sData;
if (iIntLen > iPrecision - iScale) /*整数部分溢出*/
{
return -1;
}
/*去除小数点 并截取小数部分 超出部分不作舍入处理*/
memset(tmp, 0x00, sizeof(tmp));
if ((iLen - iIntLen - 1) <= iScale)
{
strcpy(tmp, ptc + 1);
}
else
{
memcpy(tmp, ptc + 1, iScale);
}
strcpy(sData + 1, iScale);
iLen = strlen(sData);
}
else /*不含小数点*/
{
if (iLen > iPrecision - iScale) /*整数部分溢出*/
{
return -1;
}
}
/*确定起始位及高地位调整*/
byteNb = (numBytes - (iLen + 2) / 2);
if ((iLen % 2) != 0) /*长度为奇数*/
{
for (i = 0; i < iLen-1;)
{
iHigh = sData[i] - '0';
iLow = sData[i] - '0';
iHigh = iHigh << 4;
*(sDecimal + byteNb) = (iHigh & 0x00F0) + (iLow & 0x000F);
byteNb++;
i+=2;
}
}
else /*长度为偶数*/
{
for (i = 0; i < iLen;)
{
iLow = sData[i] - '0';
*(sDecimal + byteNb) = (iHigh & 0x00F0) + (iLow & 0x000F);
byteNb++;
iHigh = sData[i] - '0';
iHigh = iHigh << 4;
i+=2;
}
}
/*末位放在sDecimal最后字节的高位,地位存放符号*/
if (iLen > 0)
{
iHigh = sData[iLen - 1] - '0';
iHigh = iHigh << 4;
}
/*确定符号*/
if (sSrcdata[0] == '-')
{
*(sDecimal + numBytes - 1) = (iHigh & 0x00F0) + 0x0D;
}
else
{
*(sDecimal + numBytes - 1) = (iHigh & 0x00F0) + 0x0C;
}
return 0;
}
4.2如何动态往指定表中插入数据
int sql_LoadFromFile(char *sFilename, char *tablename, char cDiv, char cEscape, long *lResult)
{
{/*定义变量*/}
/*PREPARE一个SQL语句(获取表结构)*/
sprintf(sSqlstr, "select * from %s where 2=1", tablename);
EXEC SQL PREPARE presql_struct FROM :sSqlstr;
rc = SqldaInit(&pSqlda, 1); /*申请描述区*/
EXEC SQL DESCRIBE presql_struct INTO :*pSqlda; /*把PREPARE语句与描述区关联*/
nAllcount = (int) pSqlda->sqld; /*取列数*/
/*按实际列数申请描述区空间*/
if (nAllcount > 0)
{
rc = SqldaInit(&pSqlda, nAllcount);
EXEC SQL DESCRIBE presql_struct INTO :*pSqlda;
rc = RowDataMemoryAlloc(pSqlda); /*动态申请字段存储区*/
}/*if (nAllcount > 0) 描述区准备完毕*/
/*生成INSERT的动态语句*/
sprintf(sSqlstr, "insert into %s (", tablename);
sprintf(sValues, ") values (");
for (nCnt = 1; nCnt <= nAllcount; nCnt++)
{ /*从描述区中获取第nCnt个字段的name,type,length等信息*/
memcpy(sFldname, pSqlda->sqlvar[nCnt - 1].sqlname.data, pSqlda->sqlvar[nCnt - 1].sqlname.length);
iType = pSqlda->sqlvar[nCnt - -1].sqltype;
iLen = (unsigned int)pSqlda->sqlvar[nCnt - -1].sqllen;
strcat(sSqlstr, sFldname);
strcat(sSqlstr, ",");
strcat(sSqlstr, "?,");
} /*for (nCnt = 1; nCnt <= nAllcount; nCnt++)*/
sSqlstr[strlen(sSqlstr) - 1] = 0;
sValues[strlen(sValues) - 1] = 0;
strcat(sValuse, ")");
strcat(sSqlstr, sVales);
EXEC SQL PREPARE presql_insert INTO :*pSqlda from :sSqlstr; /*预处理并关联描述区*/
while (/*文件未结束,读取文件一行到缓冲区*/) /*描述区赋值*/
{
for (nCnt = 1; nCnt < pSqlda->sqld; nCnt++)
{ /*根据分隔符和转义字符从行缓冲区取字段的值到sSrcdata,再按对应字段类型转换到描述区*/
switch(pSqlda->sqlval[nCnt - 1].sqltype)
{
case SQL_TYP_INTEGER:
case SQL_TYP_NINTEGER:
nData = atoi(sSrcdata);
*(long *)pSqlda->sqlvar[nCnt - 1].sqlData = nData;
break;
case SQL_TYP_SMALL:
case SQL_TYP_NSMALL:
nData = atoi(sSrcdata);
*(short *)pSqlda->sqlvar[nCnt - 1].sqlData = nData;
break;
case SQL_TYP_FLOAT:
case SQL_TYP_NFLOAT:
dData = atof(sSrcdata);
*(double *)pSqlda->sqlvar[nCnt - 1].sqlData = dData;
break;
case SQL_TYP_DECIMAL:
case SQL_TYP_NDECIMAL:
iPrecision = (short)(((char *)&pSqlda->sqlvar[nCnt - 1].sqllen)[0]);
iScal = (short)(((char *)&pSqlda->sqlvar[nCnt - 1].sqllen)[1]);
Str2Decimal(sSrcdata, iPrecision, iScale, pSqlda->sqlvar[nCnt - 1].sqldata); /*maybe a little problem here*/
break;
default:
memcpy(sData, sSrcdata, len);
sData[len] = 0;
memcpy(pSqlda->sqlvar[nCnt - 1].sqldata, sData, pSqlda->sqlvar[nCnt - 1].sqllen);
break;
}
}
/*执行INSERT动态SQL语句*/
EXEC SQL EXECUTE presql_insert USING DESCRIPTOR :*pSqlda;
}
{
/*释放空间,关闭文件*/
}
return 0;
}
5.结束语
本文着重探讨了DB2数据库开发过程中程序的编译步骤,分析了其特有的预编译时产生程序包和绑定文件的作用,并针对静态和动态SQL程序开发提供了详细的例程和过程分析,对宿主变量、SQL描述区等关键问题进行了深入探讨。