基于WebMagic写的一个csdn博客小爬虫
最近有点无聊,想研究一下爬虫,说到爬虫,很多人第一时间想到的是python。但是这次我选择了室友@antgan推荐的java爬虫框架WebMagic。该框架容易上手,可定制可扩展,非常适合想用java做爬虫的小伙伴们。先看一下官方教程,里面写得很详细,也有不少参考案例。
暂时还想不到有什么数据值得爬取,先拿csdn博客来练练手。
小爬虫能抓取指定用户的所有文章的关键信息,包括文章id,标题,标签,分类,阅读人数,评论人数,是否原创。并且把数据保存到数据库中。
![]()

数据库表的设计及sql

CREATE TABLE `csdnblog` (
`key` int(11) unsigned NOT NULL AUTO_INCREMENT,
`id` int(11) unsigned NOT NULL,
`title` varchar(255) NOT NULL,
`date` varchar(16) DEFAULT NULL,
`tags` varchar(255) DEFAULT NULL,
`category` varchar(255) DEFAULT NULL,
`view` int(11) unsigned DEFAULT NULL,
`comments` int(11) unsigned DEFAULT NULL,
`copyright` int(1) unsigned DEFAULT NULL,
PRIMARY KEY (`key`)
) ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8;
Processor是爬虫逻辑,程序的核心
package csdnblog;
import java.util.List;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
/**
* CSDN博客爬虫
*
* @describe 可以爬取指定用户的csdn博客所有文章,并保存到数据库中。
* @date 2016-4-30
*
* @author steven
* @csdn qq598535550
* @website lyf.soecode.com
*/
public class CsdnBlogPageProcessor implements PageProcessor {
private static String username = "qq598535550";// 设置csdn用户名
private static int size = 0;// 共抓取到的文章数量
// 抓取网站的相关配置,包括:编码、抓取间隔、重试次数等
private Site site = Site.me().setRetryTimes(3).setSleepTime(1000);
@Override
public Site getSite() {
return site;
}
@Override
// process是定制爬虫逻辑的核心接口,在这里编写抽取逻辑
public void process(Page page) {
// 列表页
if (!page.getUrl().regex("http://blog\\.csdn\\.net/" + username + "/article/details/\\d+").match()) {
// 添加所有文章页
page.addTargetRequests(page.getHtml().xpath("//div[@id='article_list']").links()// 限定文章列表获取区域
.regex("/" + username + "/article/details/\\d+")
.replace("/" + username + "/", "http://blog.csdn.net/" + username + "/")// 巧用替换给把相对url转换成绝对url
.all());
// 添加其他列表页
page.addTargetRequests(page.getHtml().xpath("//div[@id='papelist']").links()// 限定其他列表页获取区域
.regex("/" + username + "/article/list/\\d+")
.replace("/" + username + "/", "http://blog.csdn.net/" + username + "/")// 巧用替换给把相对url转换成绝对url
.all());
// 文章页
} else {
size++;// 文章数量加1
// 用CsdnBlog类来存抓取到的数据,方便存入数据库
CsdnBlog csdnBlog = new CsdnBlog();
// 设置编号
csdnBlog.setId(Integer.parseInt(
page.getUrl().regex("http://blog\\.csdn\\.net/" + username + "/article/details/(\\d+)").get()));
// 设置标题
csdnBlog.setTitle(
page.getHtml().xpath("//div[@class='article_title']//span[@class='link_title']/a/text()").get());
// 设置日期
csdnBlog.setDate(
page.getHtml().xpath("//div[@class='article_r']/span[@class='link_postdate']/text()").get());
// 设置标签(可以有多个,用,来分割)
csdnBlog.setTags(listToString(page.getHtml()
.xpath("//div[@class='article_l']/span[@class='link_categories']/a/allText()").all()));
// 设置类别(可以有多个,用,来分割)
csdnBlog.setCategory(
listToString(page.getHtml().xpath("//div[@class='category_r']/label/span/text()").all()));
// 设置阅读人数
csdnBlog.setView(Integer.parseInt(page.getHtml().xpath("//div[@class='article_r']/span[@class='link_view']")
.regex("(\\d+)人阅读").get()));
// 设置评论人数
csdnBlog.setComments(Integer.parseInt(page.getHtml()
.xpath("//div[@class='article_r']/span[@class='link_comments']").regex("\\((\\d+)\\)").get()));
// 设置是否原创
csdnBlog.setCopyright(page.getHtml().regex("bog_copyright").match() ? 1 : 0);
// 把对象存入数据库
new CsdnBlogDao().add(csdnBlog);
// 把对象输出控制台
System.out.println(csdnBlog);
}
}
// 把list转换为string,用,分割
public static String listToString(List<String> stringList) {
if (stringList == null) {
return null;
}
StringBuilder result = new StringBuilder();
boolean flag = false;
for (String string : stringList) {
if (flag) {
result.append(",");
} else {
flag = true;
}
result.append(string);
}
return result.toString();
}
public static void main(String[] args) {
long startTime, endTime;
System.out.println("【爬虫开始】请耐心等待一大波数据到你碗里来...");
startTime = System.currentTimeMillis();
// 从用户博客首页开始抓,开启5个线程,启动爬虫
Spider.create(new CsdnBlogPageProcessor()).addUrl("http://blog.csdn.net/" + username).thread(5).run();
endTime = System.currentTimeMillis();
System.out.println("【爬虫结束】共抓取" + size + "篇文章,耗时约" + ((endTime - startTime) / 1000) + "秒,已保存到数据库,请查收!");
}
}
CsdnBlog实体类对应数据库的表
PS:之前发的那个在实体类上有注解,那种是另外的实现方式,现在已经把注解删掉了,这里是不需要的!
package csdnblog;
public class CsdnBlog {
private int id;// 编号
private String title;// 标题
private String date;// 日期
private String tags;// 标签
private String category;// 分类
private int view;// 阅读人数
private int comments;// 评论人数
private int copyright;// 是否原创
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getDate() {
return date;
}
public void setDate(String date) {
this.date = date;
}
public String getTags() {
return tags;
}
public void setTags(String tags) {
this.tags = tags;
}
public String getCategory() {
return category;
}
public void setCategory(String category) {
this.category = category;
}
public int getView() {
return view;
}
public void setView(int view) {
this.view = view;
}
public int getComments() {
return comments;
}
public void setComments(int comments) {
this.comments = comments;
}
public int getCopyright() {
return copyright;
}
public void setCopyright(int copyright) {
this.copyright = copyright;
}
@Override
public String toString() {
return "CsdnBlog [id=" + id + ", title=" + title + ", date=" + date + ", tags=" + tags + ", category="
+ category + ", view=" + view + ", comments=" + comments + ", copyright=" + copyright + "]";
}
}
dao数据访问层
只有一个添加方法
package csdnblog;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
public class CsdnBlogDao {
private Connection conn = null;
private Statement stmt = null;
public CsdnBlogDao() {
try {
Class.forName("com.mysql.jdbc.Driver");
String url = "jdbc:mysql://localhost:3307/webmagic?user=root&password=";
conn = DriverManager.getConnection(url);
stmt = conn.createStatement();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
}
}
public int add(CsdnBlog csdnBlog) {
try {
String sql = "INSERT INTO `webmagic`.`csdnblog` (`id`, `title`, `date`, `tags`, `category`, `view`, `comments`, `copyright`) VALUES (?, ?, ?, ?, ?, ?, ?, ?);";
PreparedStatement ps = conn.prepareStatement(sql);
ps.setInt(1, csdnBlog.getId());
ps.setString(2, csdnBlog.getTitle());
ps.setString(3, csdnBlog.getDate());
ps.setString(4, csdnBlog.getTags());
ps.setString(5, csdnBlog.getCategory());
ps.setInt(6, csdnBlog.getView());
ps.setInt(7, csdnBlog.getComments());
ps.setInt(8, csdnBlog.getCopyright());
return ps.executeUpdate();
} catch (SQLException e) {
e.printStackTrace();
}
return -1;
}
}
大家看一下我的博客爬到的结果,有点小激动哈大家也可以动手试试~

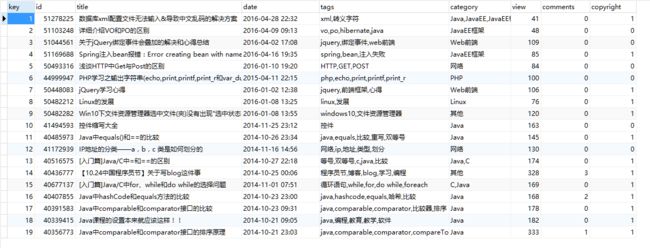
源码在GitHub上,觉得有用给个star吧(捂脸)
https://github.com/liyifeng1994/webmagic-csdnblog
如果对知乎数据感兴趣的同学,可以看一下我室友@antgan写的一个基于webmagic的爬虫小应用–爬取知乎用户信息,也是一个拿来练手的好案例哈!
ps:没想到过了两三天,阅读量上升这么快,对我来说是一种莫大的鼓励。我下一步可能会爬取一定量的知乎用户数据,通过数据分析,做一些实际点的东西。我也会把这一个过程分享给大家,谢谢谢谢~
===============
2016.08.16评论补充:
我的博客最近换了新皮肤,所以html结构发生了变化,上面DEMO的爬取规则中xpath语法需要进行小改动,就当作是作业吧,以前的旧皮肤都可以爬取~
===============
2016.11.01补充:
由于dao实现最基本的把数据插入到数据库,没有考虑到连接池、线程队列等等任何现实中可能会遇到的问题,只是希望把大家带入爬虫的世界~
