机器学习案例实战:聚类算法
原创文章,如需转载请保留出处
本博客为唐宇迪老师python数据分析与机器学习实战课程学习笔记
一. 多种算法概述
1.1 预测HTTP异常流量的检测
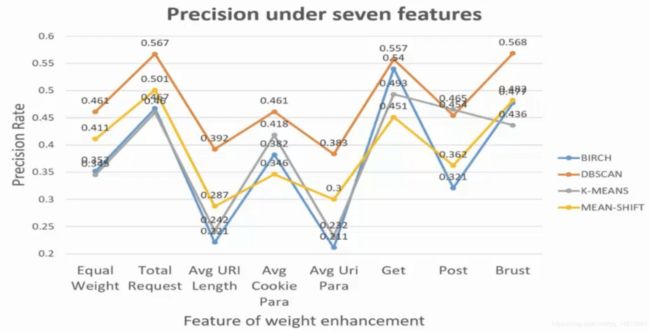
二. 聚类案例实战
2.1 获取数据
#beer dataset
import pandas as pd
#sep=’ ‘: 表示当输入多个打印的值时,各个值之间分割方式, 默认空格,可以自定义
beer = pd.read_csv('data.txt',sep=" ")
beer
name calories sodium alcohol cost
0 Budweiser 144 15 4.7 0.43
1 Schlitz 151 19 4.9 0.43
2 Lowenbrau 157 15 0.9 0.48
3 Kronenbourg 170 7 5.2 0.73
4 Heineken 152 11 5.0 0.77
5 Old_Milwaukee 145 23 4.6 0.28
6 Augsberger 175 24 5.5 0.40
7 Srohs_Bohemian_Style 149 27 4.7 0.42
8 Miller_Lite 99 10 4.3 0.43
9 Budweiser_Light 113 8 3.7 0.40
10 Coors 140 18 4.6 0.44
11 Coors_Light 102 15 4.1 0.46
12 Michelob_Light 135 11 4.2 0.50
13 Becks 150 19 4.7 0.76
14 Kirin 149 6 5.0 0.79
15 Pabst_Extra_Light 68 15 2.3 0.38
16 Hamms 139 19 4.4 0.43
17 Heilemans_Old_Style 144 24 4.9 0.43
18 Olympia_Goled_Light 72 6 2.9 0.46
19 Schlitz_Light 97 7 4.2 0.47
2.2 获取属性
聚类的输入,聚类的特征
X = beer[["calories","sodium","alcohol","cost"]]
X

2.3 K-means clustering
利用K-means聚类
from sklearn.cluster import KMeans
#n_cluster:就是K值,聚成几堆
km = KMeans(n_clusters=3).fit(X)
km2 = KMeans(n_clusters=2).fit(X)
2.4 查看结果
查看前八个属于0类别,
第九个和十个属于1类别…
km.labels_
array([0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 1, 0, 0, 0, 2, 0, 0, 2, 1],
dtype=int32)
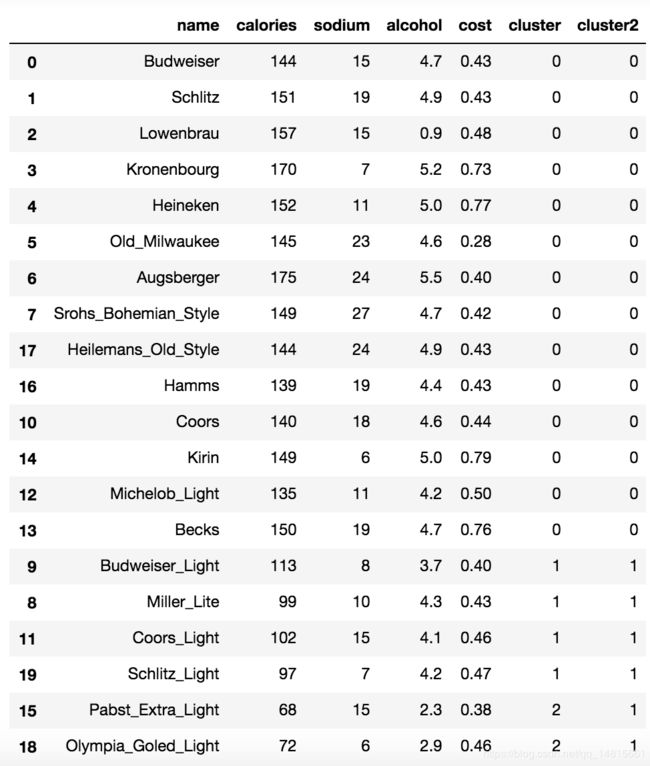
2.5 beer数据以cluster分类
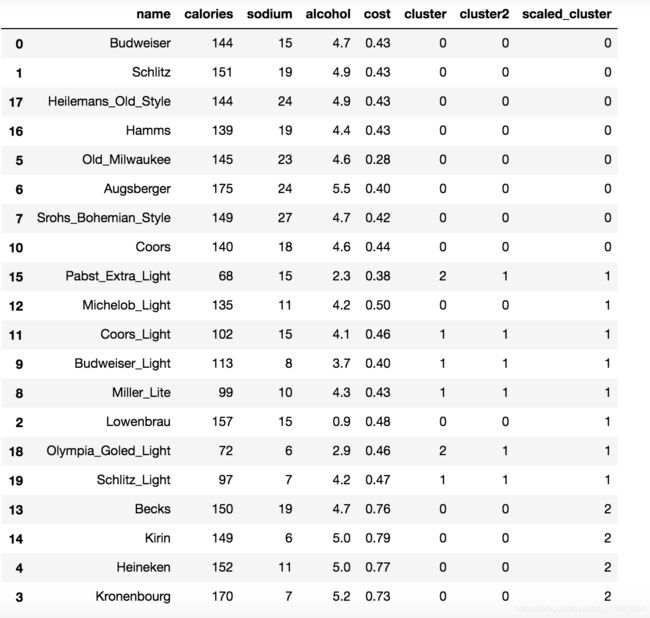
beer['cluster'] = km.labels_
beer['cluster2'] = km2.labels_
beer.sort_values('cluster')
2.6 获取每个簇中心的坐标
from pandas.tools.plotting import scatter_matrix
%matplotlib inline
#cluster_centers_ : 每个簇中心的坐标 array, [n_clusters, n_features]
cluster_centers = km.cluster_centers_
cluster_centers_2 = km2.cluster_centers_
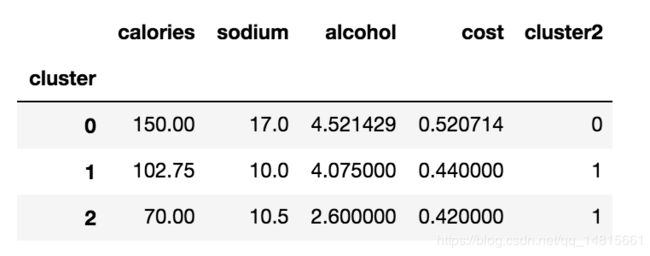
2.7 查看各项均值
#查看cluster各项均值
beer.groupby("cluster").mean()
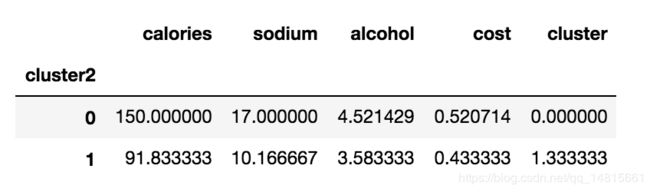
#查看cluster2各项均值
beer.groupby("cluster2").mean()
2.8 重新变为默认的整型索引
#eset_index可以还原索引,重新变为默认的整型索引
centers = beer.groupby("cluster").mean().reset_index()
centers

2.9 画图
%matplotlib inline
import matplotlib.pyplot as plt
plt.rcParams['font.size']=14
import numpy as np
colors = np.array(['red','green','blue','yellow'])
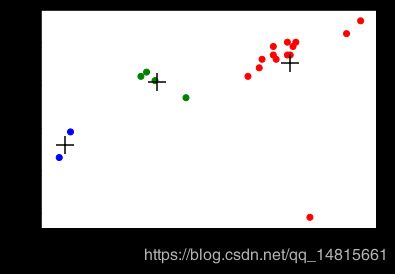
plt.scatter(beer["calories"],beer["alcohol"],c=colors[beer["cluster"]])
plt.scatter(centers.calories,centers.alcohol,linewidths=3,marker='+',s=300,c='black')
plt.xlabel("Calories")
plt.ylabel("Alcohol")
2.10 查看两两之间关系
from pandas.tools.plotting import scatter_matrix
import warnings
warnings.filterwarnings("ignore")
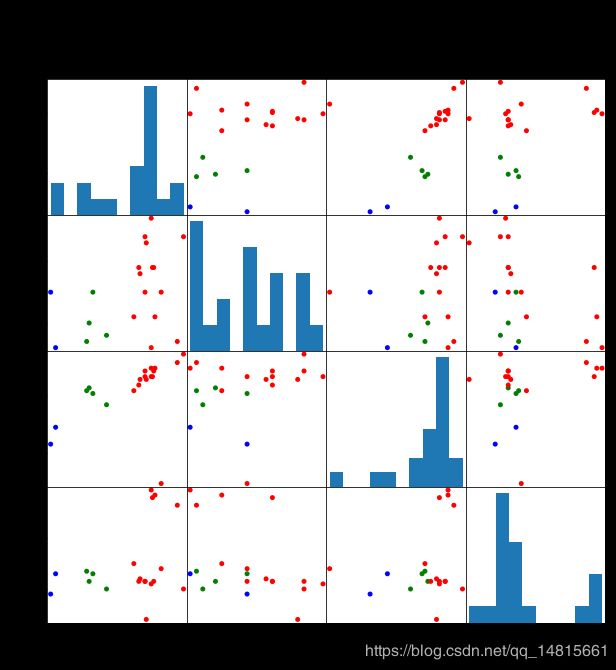
scatter_matrix(beer[["calories","sodium","alcohol","cost"]],s=100,alpha=1,c=colors[beer["cluster"]],figsize=(10,10))
plt.suptitle("With 3 centroids initialized")
Text(0.5, 0.98, ‘With 3 centroids initialized’)
三.另一种方法
3.1 标准化数据
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
X_scaled
array([[ 0.38791334, 0.00779468, 0.43380786, -0.45682969],
[ 0.6250656 , 0.63136906, 0.62241997, -0.45682969],
[ 0.82833896, 0.00779468, -3.14982226, -0.10269815],
[ 1.26876459, -1.23935408, 0.90533814, 1.66795955],
[ 0.65894449, -0.6157797 , 0.71672602, 1.95126478],
[ 0.42179223, 1.25494344, 0.3395018 , -1.5192243 ],
[ 1.43815906, 1.41083704, 1.1882563 , -0.66930861],
[ 0.55730781, 1.87851782, 0.43380786, -0.52765599],
[-1.1366369 , -0.7716733 , 0.05658363, -0.45682969],
[-0.66233238, -1.08346049, -0.5092527 , -0.66930861],
[ 0.25239776, 0.47547547, 0.3395018 , -0.38600338],
[-1.03500022, 0.00779468, -0.13202848, -0.24435076],
[ 0.08300329, -0.6157797 , -0.03772242, 0.03895447],
[ 0.59118671, 0.63136906, 0.43380786, 1.88043848],
[ 0.55730781, -1.39524768, 0.71672602, 2.0929174 ],
[-2.18688263, 0.00779468, -1.82953748, -0.81096123],
[ 0.21851887, 0.63136906, 0.15088969, -0.45682969],
[ 0.38791334, 1.41083704, 0.62241997, -0.45682969],
[-2.05136705, -1.39524768, -1.26370115, -0.24435076],
[-1.20439469, -1.23935408, -0.03772242, -0.17352445]])
3.2 聚类
km = KMeans(n_clusters=3).fit(X_scaled)
beer["scaled_cluster"]=km.labels_
beer.sort_values("scaled_cluster")
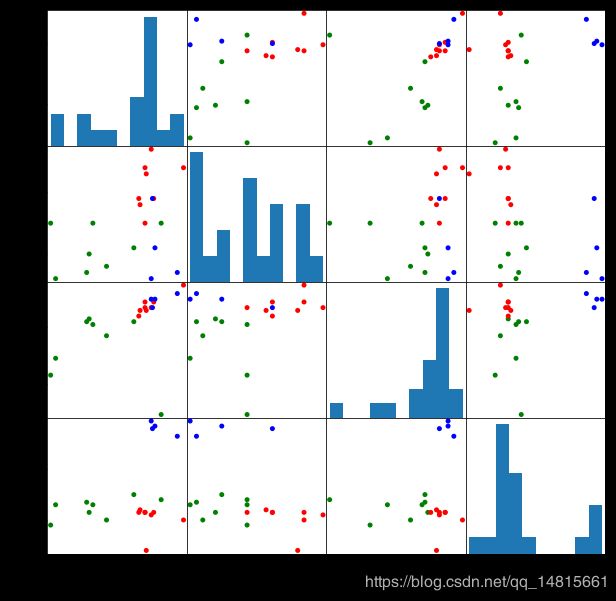
beer.groupby("scaled_cluster").mean()

pd.scatter_matrix(X, c=colors[beer.scaled_cluster],alpha=1,figsize=(10,10),s=100)
四. 聚类评估
4.1 轮廓系数

- 计算样本i到同簇其他样本的平均距离ai。ai越小,说明样本i越应该被聚类到该簇。将ai称为样本的簇内不相似度。
- 计算样本i到其他某簇Cj的所有样本的平均距离bij,称为样本i与簇Cj的不相似度。定义为样本i的簇间不相似度;bi=min{bi1,bi2,…bik}
- si接近1,则说明样本i聚类合理
- si接近-1,则说明样本i更应该分类到另外的簇
- 若si近似为0,则说明样本i在两个簇的边界上
from sklearn import metrics
score_scaled = metrics.silhouette_score(X,beer.scaled_cluster)
score = metrics.silhouette_score(X,beer.cluster)
print (score_scaled, score)
0.1797806808940007 0.6731775046455796
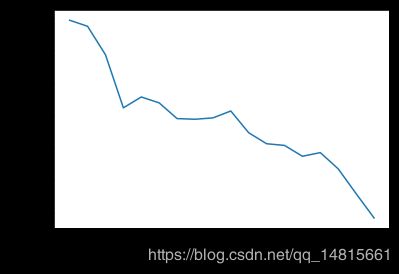
scores = []
for k in range(2,20):
labels = KMeans(n_clusters=k).fit(X).labels_
score = metrics.silhouette_score(X, labels)
scores.append(score)
scores
[0.6917656034079486,
0.6731775046455796,
0.5857040721127795,
0.422548733517202,
0.4559182167013377,
0.43776116697963124,
0.38946337473125997,
0.3874759334160638,
0.3915697409245163,
0.41282646329875183,
0.3459775237127248,
0.31221439248428434,
0.30707782144770296,
0.2736836031737978,
0.2849514001174898,
0.23498077333071996,
0.1588091017496281,
0.08423051380151177]
plt.plot(list(range(2,20)),scores)
plt.xlabel("Number of Clusters Initialized")
plt.ylabel("Sihouette Score")
五.DBSCAN clustering
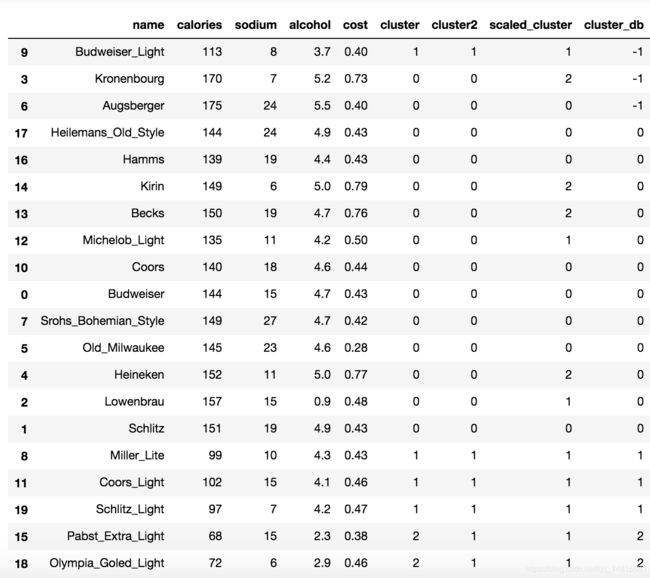
from sklearn.cluster import DBSCAN
db = DBSCAN(eps=10, min_samples=2).fit(X)
labels = db.labels_
beer['cluster_db'] = labels
beer.sort_values('cluster_db')
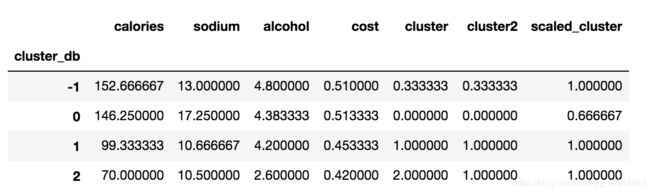
beer.groupby('cluster_db').mean()
pd.scatter_matrix(X, c=colors[beer.cluster_db],figsize=(10,10),s=100)
