Spark从入门到精通二----spark任务的提交方式spark-shell/spark-submit----------各种版本的wordcount
版权声明:本文为博主原创文章,未经博主允许不得转载!!
欢迎访问:https://blog.csdn.net/qq_21439395/article/details/82779266
交流QQ: 824203453
- 执行Spark程序
使用spark-shell命令和spark-submit命令来提交spark任务。
当执行测试程序,使用spark-shell,spark的交互式命令行
提交spark程序到spark集群中运行时,spark-submit
-
- 执行第一个spark示例程序
spark-submit --class org.apache.spark.examples.SparkPi /root/apps/spark/examples/jars/spark-examples_2.11-2.2.0.jar 100
该算法是利用蒙特·卡罗算法求PI(圆周率)
spark任务提交的方式:
spark-submit --master spark://hdp-01:7077 --class xxx.SparkPi /root/xx.jar 输入输出参数
怎么用:
提交正式任务,或者有jar包,使用spark-submit ;本地测试,选用spark-shell
-
- 启动Spark Shell
spark-shell 用命令行的方式提交任务到集群的一个客户端。spark-shell是Spark自带的交互式Shell程序,方便用户进行交互式编程,用户可以在该命令行下用scala编写spark程序。
-
-
- 启动spark shell
-
直接启动spark-shell默认使用的是local模式,和spark集群无关
只要把spark安装包解压了,就可以运行local模式
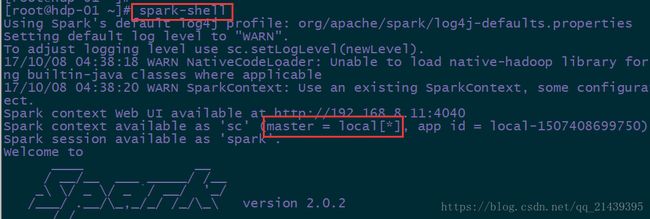
local模式没有指定master地址,仅在本机启动一个进程(SparkSubmit),没有与集群建立联系。但是也可以正常启动spark shell和执行spark shell中的程序
指定集群模式启动:
hdfs://hdp-01:9000
spark的协议URI:spark://hdp-01:7077
# spark-shell --master

在webUI界面,可以查看到正在运行的程序:

Spark Shell中已经默认将SparkContext类初始化为对象sc。用户代码如果需要用到,则直接应用sc即可
-
-
- 在spark shell中编写WordCount程序
-
- 首先启动hdfs
- 向hdfs上传一个文件到hdfs://hdp-01:9000/wordcount/input/a.txt
- 在spark shell中用scala语言编写spark程序
scala> sc.textFile("hdfs://hdp-01:9000/wordcount/input/")
spark是懒加载的,所以这里并没有真正执行任务。可使用collect方法快速查看数据。
lazy执行的,只有调用了action方法,才正式开始运行。
scala>sc.textFile("hdfs://hdp-01:9000/wordcount/input/").flatMap(_.split(" ")).map((_,1)).reduceByKey(_ + _).sortBy(_._2,false).collect
注意:这些flatMap,map等方法是RDD上的方法,要区分于原生的scala方法。
和原生scala的方法名称有的相同,但属于不通的类的方法,底层实现完全不一致。
原生的方法: 对单机的数组或集合进行操作。
RDD上的方法:
RDD是spark的计算模型,RDD上有很多的方法,这些方法通常称为算子,主要有两类算子,一类是transform,一类是action,transform是懒加载的。
scala>sc.textFile("hdfs://hdp-01:9000/wordcount/input/").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).saveAsTextFile("hdfs://hdp-01:9000/wordcount/outspark1")
- 使用hdfs命令查看结果
# hadoop fs -ls /wordcount/outspark1
说明:
sc是SparkContext对象,该对象是提交spark程序的入口
textFile(hdfs://hdp-01:9000/wordcount/intput/a.txt)是hdfs中读取数据
flatMap(_.split(" "))先map再压平
map((_,1))将单词和1构成元组
reduceByKey(_+_)按照key进行reduce,并将value累加
saveAsTextFile("hdfs://hdp-01:9000/outspark1")将结果写入到hdfs中
spark中的方法很多,这些方法统称为算子。一共有两类算子(transform,action)
spark是懒加载的,transform方法并不会立即执行,只有当程序遇到action的时候才会被执行。collect算子是一个action
collect: 收集数据到本地
-
- 在IDEA中编写WordCount程序
spark shell仅在测试和验证我们的程序时使用的较多,在生产环境中,通常会在IDE中开发程序,然后打成jar包,然后提交到集群,最常用的是创建一个Maven项目,利用Maven来管理jar包的依赖。
-
-
- scalaAPI的wordcount
-
1.创建一个项目

2.选择Maven项目,然后点击next
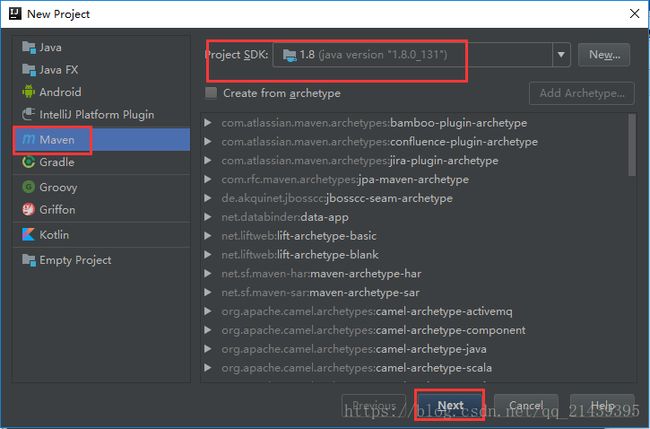
3.填写maven的GAV,然后点击next
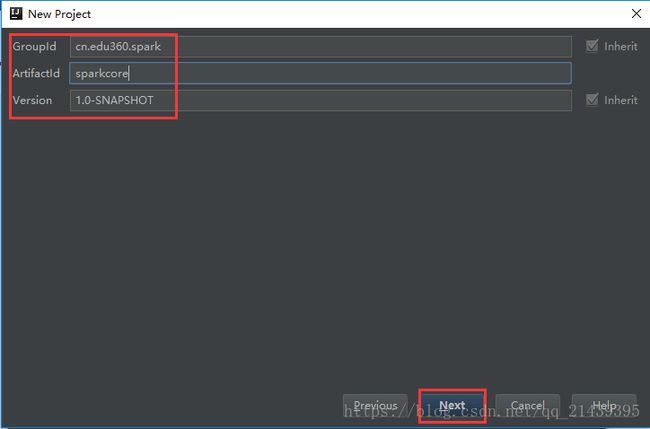
- 填写项目名称,然后点击finish

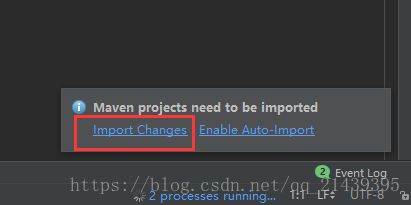
5.创建好maven项目后,点击Import Changes 手动导入,点击Enable Auto-Import 可自动导入
- 配置Maven的pom.xml
详见pom.xml文件
maven的编译jdk版本设置:
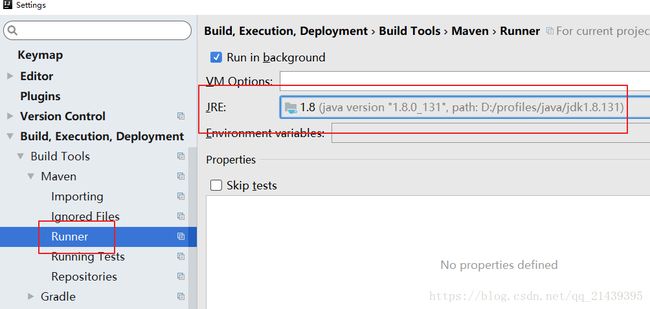
- 新建一个scala object
- 编写spark程序
| object WordCount { // 释放资源 sc.stop() |
-
-
- JAVAAPI的wordcount
-
| public class JavaWordCount { // 释放资源 sc.stop(); |
-
-
- JAVALambda的wordcount
-
| public class JavaLambdaWC { |
-
-
- local模式运行spark程序
-
| // 配置参数 |
-
- 打包并上传到集群
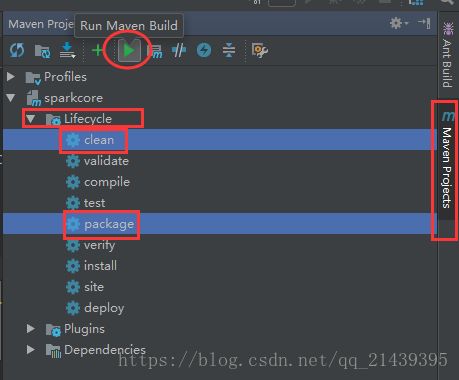
点击idea右侧的Maven Project选项
点击Lifecycle,选择clean和package,然后点击Run Maven Build
- 选择编译成功的jar包,并将该jar上传到Spark集群中的某个节点上(任意节点即可)


确保启动了hdfs集群和spark集群
| # hdfs启动(在namenode节点上) # /root/apps/hadoop/sbin/start-dfs.sh # spark启动(在master节点上) # start-all.sh |
-
- 提交任务
使用spark-submit命令提交Spark应用(注意参数的顺序)
| spark-submit --master spark://hdp-01:7077 --class cn.edu360.spark.WordCount sparkcore-1.0-SNAPSHOT.jar hdfs://hdp-01:9000/wordcount/input hdfs://hdp-01:9000/wordcount/output |
![]()
可以分多行写:
spark-submit \
--class cn.edu360.spark.WordCount \
--master spark://hdp-01:7077 \
/root/sparkcore-1.0-SNAPSHOT.jar \
hdfs://hdp-01:9000/wordcount/input \
hdfs://hdp-01:9000/wordcount/output
任务执行命令的基本套路:
# spark-submit 任务提交参数 --class 程序的main方法 jar包 main的参数列表
查看程序执行过程:
在web页面查看程序运行状态:http://hdp-01:8080
使用jps命令查看进程信息
查看hdfs文件结果
hdfs dfs -cat hdfs://hdp-01:9000/output/part-00000
版权声明:本文为博主原创文章,未经博主允许不得转载!!
欢迎访问:https://blog.csdn.net/qq_21439395/article/details/82779266
交流QQ: 824203453