零基础入门NLP之搭建中文分词工具
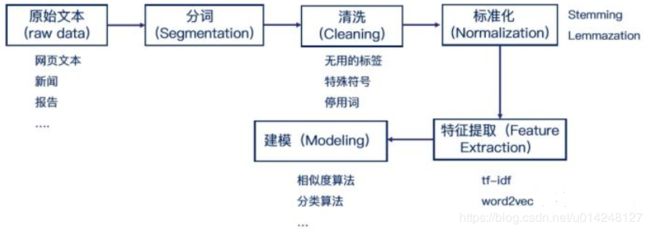
1 文本分析的基本过程
分词就是中学学的断句:
举个例子来说明:假设我们输入一句话:北京欢迎你。则有可能的断句为:
北,京,欢,迎,你
北京,欢,迎,你
北京,欢迎,你 等等如果没有语料库的话就是这样的枚举。
分词我们可以根据语料库里面的次来分,比如语料库里面有[北京,欢迎,你,欢,迎]则上面列出的就是我们可能的分词结果用程序来是实现就是
需要的语料库:
https://github.com/liangqi/chinese-frequency-word-list
给出了每个词出现的概率。相当于建立unigram模型代码如下
from collections import Counter
import random
import numpy as np
with open('./data/现代汉语常用词表.txt') as f:
lines = f.readlines()
sum = 0
word_prob = Counter()
for line in lines:
columns = line.strip().split()
# 重复词频率直接相加,(相同词多次出现是因为发音不同,即语义也不同,这里不做区分)
word_prob[columns[0]] += int(columns[-1])
sum += int(columns[-1])
# 频率转为概率
for word in word_prob:
word_prob[word] /= sum这段代码的功能是读取语料库中的单词,并统计每个词出现的概率,我们可以去测试一下。
print([{word: word_prob[word]} for word in random.sample(word_prob.keys(), 2)])
print("词典大小:%d" % len(word_prob))
print(np.sum(list(word_prob.values())))
成功读取语料库并计算出每个词的概率后,我们可以开始基于每个词的概率开始进行分割。代码如下
def sentence_break(str):
"""
求该句话在当前词典下的全切分。
思路:状态转移,设M[i]是从句子开始到第i个字所组成句的全切分,word是以字i结尾的可在词典中找到的词,则M[i] = M[i-len(word)] + word
str: 字符串,传入的句子
"""
# 存储状态
memory = [[] for _ in range(len(str))]
for i in range(0, len(str)):
for j in range(0, i+1):
# 从开始到当前cursor视为一个词
if j == 0:
if str[j:i+1] in word_prob:
memory[i].append([str[j:i+1]])
continue
# 确定依赖的之前状态存在且(达成转移条件:词存在)
if memory[j-1] and str[j:i+1] in word_prob:
# 状态转移过程
for state in memory[j-1]:
memory[i].append(state + [str[j:i+1]])
return memory[-1]测试
print(sentence_break("北京欢迎你"))计算每一句话出现的概率,并返回最大概率的一句话
## TODO 编写word_segment_naive函数来实现对输入字符串的分词
import math
def word_segment_naive(input_str):
"""
1. 对于输入字符串做分词,并返回所有可行的分词之后的结果。
2. 针对于每一个返回结果,计算句子的概率
3. 返回概率最高的最作为最后结果
input_str: 输入字符串 输入格式:“今天天气好”
best_segment: 最好的分词结果 输出格式:["今天","天气","好"]
"""
# TODO: 第一步: 计算所有可能的分词结果,要保证每个分完的词存在于词典里,这个结果有可能会非常多。
segments = sentence_break(input_str) # 存储所有分词的结果。如果次字符串不可能被完全切分,则返回空列表(list)
# 格式为:segments = [["今天",“天气”,“好”],["今天",“天“,”气”,“好”],["今“,”天",“天气”,“好”],...]
# TODO: 第二步:循环所有的分词结果,并计算出概率最高的分词结果,并返回
best_segment = list()
best_score = 0
for seg in segments:
# TODO ...
if seg:
score = 0
for word in seg:
# 防止下溢,取log
score += math.log(word_prob[word])
if best_score == 0:
best_segment = seg
best_score = score
else:
if score > best_score:
best_segment = seg
best_score = score
return best_segment因为上面的分词和计算概率分开进行,我们可以通过建立一个有向无环图来实现同时进行(维特比算法)
## TODO 编写word_segment_viterbi函数来实现对输入字符串的分词
import math
def word_segment_viterbi(input_str):
"""
1. 基于输入字符串,词典,以及给定的unigram概率来创建DAG(有向图)。
2. 编写维特比算法来寻找最优的PATH
3. 返回分词结果
input_str: 输入字符串 输入格式:“今天天气好”
best_segment: 最好的分词结果 输出格式:["今天","天气","好"]
"""
# TODO: 第一步:根据词典,输入的句子,以及给定的unigram概率来创建带权重的有向图(Directed Graph)
# 有向图的每一条边是一个单词的概率(只要存在于词典里的都可以作为一个合法的单词),这些概率在 word_prob,如果不在word_prob里的单词但在
# 词典里存在的,统一用概率值1e-100。
# 图是为了直观起见,边表示字或词及其概率,节点存储状态,图有没有其实无所谓,从本质上讲其实就是个状态转移算法
# 每个节点的状态包含-log(P)和当前最优切分
memory = [[0, []] for _ in range(len(input_str)+1)]
# TODO: 第二步: 利用维特比算法来找出最好的PATH, 这个PATH是P(sentence)最大或者 -log P(sentence)最小的PATH。
# TODO: 第三步: 根据最好的PATH, 返回最好的切分
for i in range(1, len(input_str)+1):
for j in range(i):
# 这里偷个懒,默认没有形成词的单字可以在词典中找到(如果不成立事实上会返回完整句子,因为-log(1e-100)必然小于该值加某个非负数
word = input_str[j:i]
prob = word_prob[word] if word in word_prob else 1e-100
score = memory[j][0] - math.log(prob)
# 状态更新
if memory[i][0] == 0:
memory[i][0] = score
memory[i][1] = memory[j][1] + [word]
else:
if score < memory[i][0]:
memory[i][0] = score
memory[i][1] = memory[j][1] + [word]
return memory[-1][1]
目前比较流行的中文分词工具
jieba:做最好的 Python 中文分词组件https://github.com/fxsjy/jieba
清华大学THULAC:一个高效的中文词法分析工具包
中科院计算所NLPIR
哈工大LTP
FoolNLTK可能不是最快的开源中文分词,但很可能是最准的开源中文分词
参考资料:https://zhuanlan.zhihu.com/p/95599399